1. 概述
在之前對 Spring Batch 的介紹中,我們介紹了該框架作為批處理工具。我們還探討了單線程、單進程作業執行的配置詳情和實現。
為了實現具有一定並行處理的作業,提供了多種選項。在更高層面,並行處理有兩種模式:
- 單進程,多線程
- 多進程
在本文中,我們將討論 Step 的分片,該分片可用於單進程和多進程作業的實現。
2. 分割一個步驟
Spring Batch 中的分區功能允許我們分割 步驟 的執行:
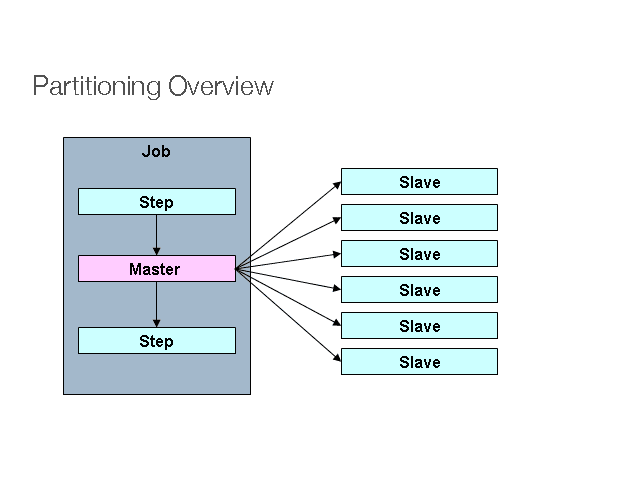
上面的圖片展示了一個帶有分區的 作業 的實現,其中 步驟 被分割了。
有一個名為“Master”的步驟,它的執行被分割成一些“Slave”步驟。這些奴隸可以替代主步驟,並且結果不會改變。Master和Slave都是步驟的實例。Slave可以是遠程服務,也可以是本地執行的線程。
如果需要,我們可以將數據從Master傳遞到Slave。元數據(即作業倉庫)確保在單個作業的執行中,每個Slave只會被執行一次。
以下是展示其工作原理的序列圖:
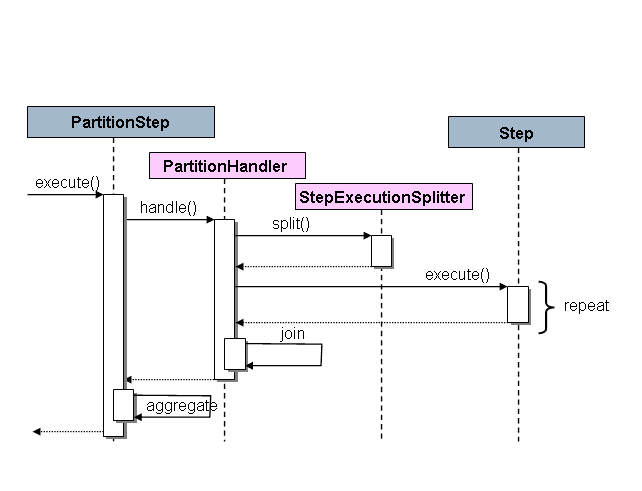
如所示,分區步驟 驅動執行。 分區處理程序 負責將“Master”的工作分割成“Slave”。
最右邊的步驟是奴隸。
3. Maven POM
Maven 依賴與我們上一篇文章中提到的相同。即 Spring Core、Spring Batch 以及數據庫依賴(在本例中是 H2)。
4. 配置
在我們的入門文章中,我們看到了將一些財務數據從 CSV 轉換為 XML 文件的示例。現在,讓我們擴展這個示例。
在這裏,我們將從 5 個 CSV 文件中轉換財務信息,並生成相應的 XML 文件,使用多線程實現。
我們可以通過一個 Job 和 Step 進行分區來實現。我們將有五個線程,每個線程對應一個 CSV 文件。
首先,讓我們創建一個 Job:
@Bean(name = "partitionerJob")
public Job partitionerJob(JobRepository jobRepository)
throws UnexpectedInputException, MalformedURLException, ParseException {
return jobs.get("partitioningJob", jobRepository)
.start(partitionStep())
.build();
}如我們所見,這個 Job 從 PartitioningStep 開始。這是我們的主步驟,它將被分解為各種從步驟:
@Bean
public Step partitionStep(JobRepository jobRepository, PlatformTransactionManager transactionManager)
throws UnexpectedInputException, ParseException {
return new StepBuilder("partitionStep", jobRepository)
.partitioner("slaveStep", partitioner())
.step(slaveStep(jobRepository, transactionManager))
.taskExecutor(taskExecutor())
.build();
}在這裏,我們將使用 StepBuilder 構造函數創建 PartitioningStep,並指定步驟的名稱。為此,我們需要提供有關 SlaveSteps 和 Partitioner 的信息。
Partitioner 是一個接口,它提供了一種定義每個 Slave 的輸入值的機制。換句話説,任務分配到相應線程的邏輯就在這裏。
讓我們創建一個實現,名為 CustomMultiResourcePartitioner,我們將輸入和輸出文件名放入 ExecutionContext 中,以便傳遞給每個 Slave 步驟:
public class CustomMultiResourcePartitioner implements Partitioner {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>(gridSize);
int i = 0, k = 1;
for (Resource resource : resources) {
ExecutionContext context = new ExecutionContext();
Assert.state(resource.exists(), "Resource does not exist: "
+ resource);
context.putString(keyName, resource.getFilename());
context.putString("opFileName", "output"+k+++".xml");
map.put(PARTITION_KEY + i, context);
i++;
}
return map;
}
}我們還將為該類創建 Bean,其中指定輸入文件的源目錄:
@Bean
public CustomMultiResourcePartitioner partitioner() {
CustomMultiResourcePartitioner partitioner
= new CustomMultiResourcePartitioner();
Resource[] resources;
try {
resources = resoursePatternResolver
.getResources("file:src/main/resources/input/*.csv");
} catch (IOException e) {
throw new RuntimeException("I/O problems when resolving"
+ " the input file pattern.", e);
}
partitioner.setResources(resources);
return partitioner;
}我們將定義奴隸步驟,就像任何其他步驟一樣,與讀者和寫入者協同工作。讀者和寫入者將與我們在介紹示例中看到的相同,但它們將從 StepExecutionContext 接收文件名參數。
請注意,這些 Bean 需要具有步驟範圍,以便它們能夠接收 stepExecutionContext 參數,在每個步驟中。如果它們沒有步驟範圍,它們的 Bean 將在初始創建時生成,並且無法在步驟級別接收文件名:
@StepScope
@Bean
public FlatFileItemReader<Transaction> itemReader(
@Value("#{stepExecutionContext[fileName]}") String filename)
throws UnexpectedInputException, ParseException {
FlatFileItemReader<Transaction> reader
= new FlatFileItemReader<>();
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
String[] tokens
= {"username", "userid", "transactiondate", "amount"};
tokenizer.setNames(tokens);
reader.setResource(new ClassPathResource("input/" + filename));
DefaultLineMapper<Transaction> lineMapper
= new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(new RecordFieldSetMapper());
reader.setLinesToSkip(1);
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
@StepScope
public ItemWriter<Transaction> itemWriter(Marshaller marshaller,
@Value("#{stepExecutionContext[opFileName]}") String filename)
throws MalformedURLException {
StaxEventItemWriter<Transaction> itemWriter
= new StaxEventItemWriter<Transaction>();
itemWriter.setMarshaller(marshaller);
itemWriter.setRootTagName("transactionRecord");
itemWriter.setResource(new FileSystemResource("src/main/resources/output/" + filename));
return itemWriter;
}在奴役步驟中提及讀取者和寫入者時,可以將參數傳遞為 null,因為這些文件名將不被使用,因為它們將從 stepExecutionContext 中接收文件名:
@Bean
public Step slaveStep(JobRepository jobRepository, PlatformTransactionManager transactionManager)
throws UnexpectedInputException, ParseException {
return new StepBuilder("slaveStep").<Transaction, Transaction> chunk(1, transactionManager)
.reader(itemReader(null))
.writer(itemWriter(marshaller(), null))
.build();
}結論
在本教程中,我們探討了如何使用 Spring Batch 實現並行處理的作業。

{kind=link}
{kind=link}