AAAI 是人工智能領域頂級的國際學術會議,本文精選了美團技術團隊被收錄的8篇學術論文(附下載鏈接),覆蓋大模型推理、 退火策略、過程獎勵模型、強化學習、視覺文本渲染等多個技術領域,希望這些論文能對大家有所幫助或啓發。

01 Promoting Efficient Reasoning with Verifiable Stepwise Reward
論文類型:Poster
論文下載 :PDF
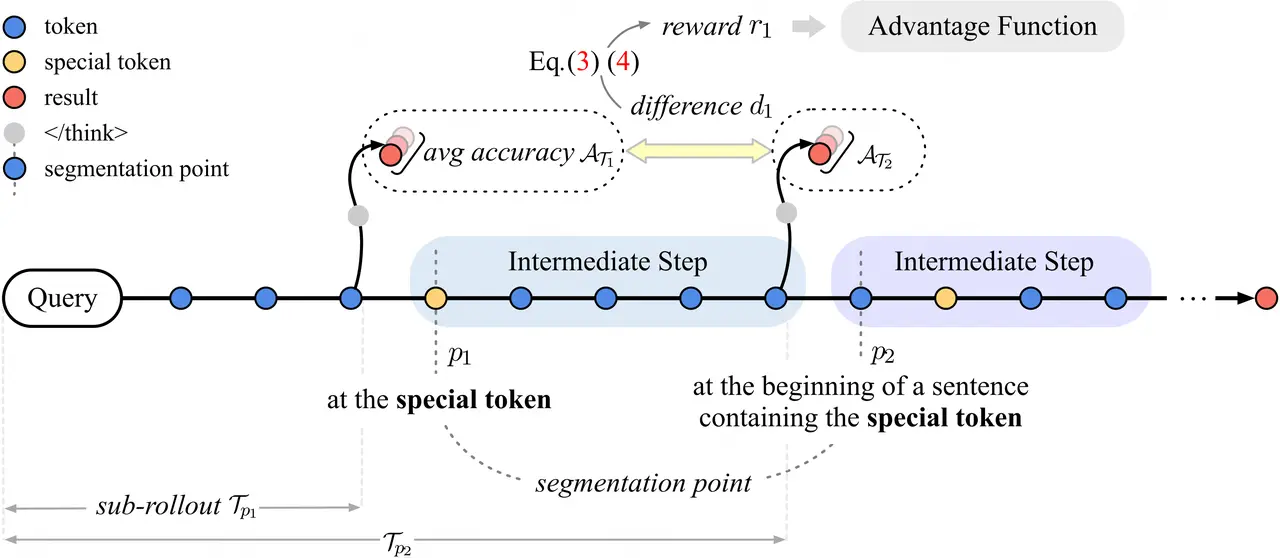
論文簡介:大推理模型通過強化學習提升了鏈式推理能力,但輸出冗長,導致推理開銷增大和用户體驗下降,即「過度思考」問題。針對這一現象,本文提出了可驗證的過程獎勵機制(VSRM),通過獎勵有效步驟、懲戒無效步驟,優化模型推理過程。VSRM首先通過特殊token劃分推理步驟,並結合三條規則保證每個步驟的內容可讀性。各步驟通過插入token生成子軌跡,模型根據每步前後正確率變化分配步驟級獎勵。為避免獎勵信號稀疏,引入前瞻窗口機制,通過折扣因子傳播未來正確率變化,使獎勵更密集。
實驗表明,VSRM能大幅縮減輸出長度,且在多種數學benchmark和不同模型、算法下保持甚至提升性能。消融實驗證明前瞻窗口機制有效,顯式長度懲罰對VSRM無益。VSRM機制可與各類強化學習算法無縫結合,有效抑制無效步驟,鼓勵有效推理,是解決過度思考問題、提升模型推理效率的有效方法。
02 Scaling and Transferability of Annealing Strategies in Large Language Model Training
論文類型:Long Paper
論文下載 :PDF
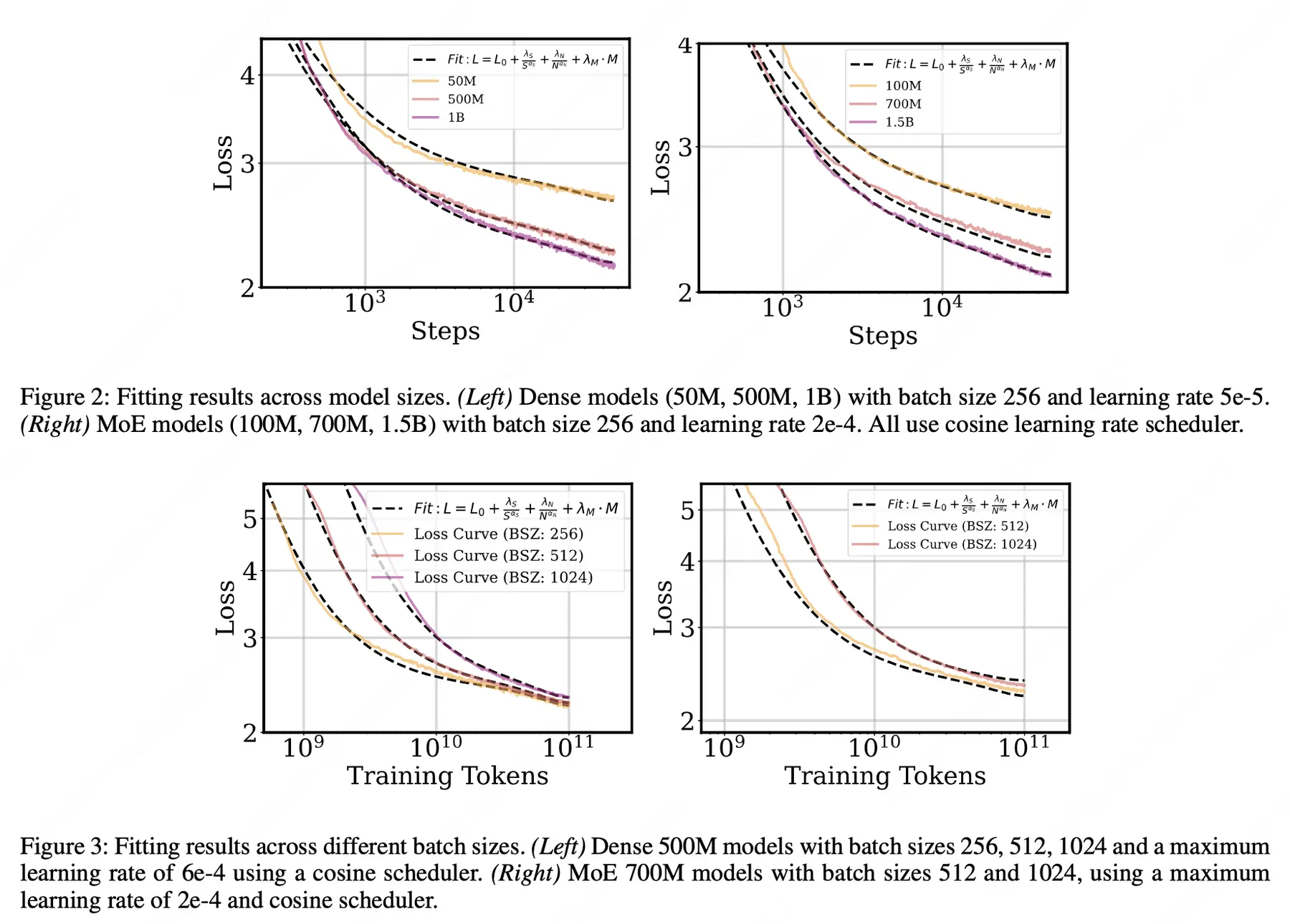
論文簡介:本文深入研究了大型語言模型訓練過程中退火策略(Annealing Strategies)對模型性能的影響,提出了一個新的縮放法則公式來預測不同訓練配置下的損失曲線。研究發現,即使在相同的訓練token數量和模型規模下,不同的批次大小(batch size)和學習率調度器也會導致顯著不同的訓練曲線。為此,作者提出了一個改進的縮放法則公式:
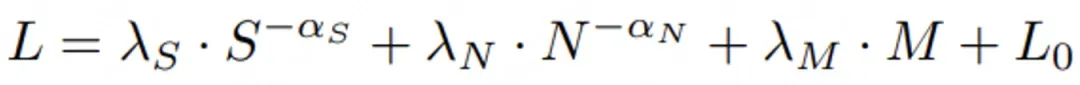
其中S表示學習率對訓練步數的積分(前向效應),M表示動量對訓練步數的積分(退火動量項),N代表模型規模。
論文的核心貢獻包括:(1) 證明在特定情況下,訓練步數比訓練token數更適合作為追蹤損失曲線的指標;(2) 發現最優退火比率(Ropt)隨總訓練步數增加而減小,遵循冪律關係;(3) 驗證了最優退火比率在訓練集和驗證集上保持一致;(4) 通過在Dense模型和MoE(Mixture-of-Experts)模型上的大量實驗,證明小模型可以作為優化大模型訓練動態的可靠代理。該研究為大規模語言模型的訓練提供了更精確的理論指導,有助於優化訓練效率和模型性能。
03 From Mathematical Reasoning to Code: Generalization of Process Reward Models in Test-Time Scaling
論文類型:Long Paper (Oral)
論文下載 :PDF
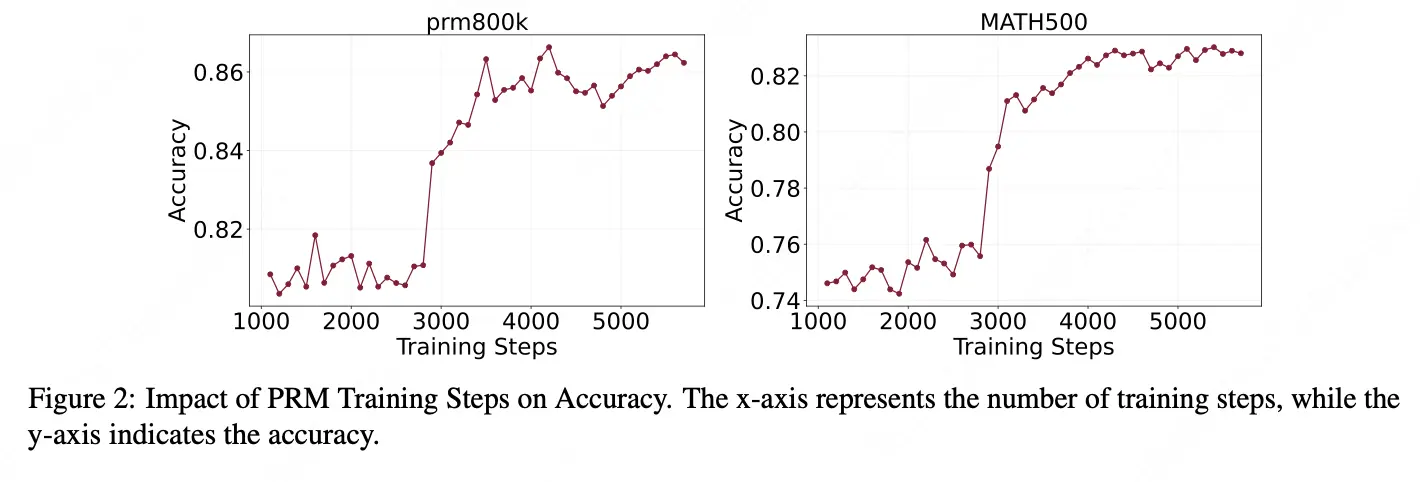
論文簡介:本文系統研究了過程獎勵模型(Process Reward Models, PRMs)在提升大型語言模型推理能力方面的作用,特別關注其從數學推理到代碼生成任務的跨域泛化能力。研究從訓練方法、可擴展性和泛化能力等多個維度對PRMs進行了深入分析。
論文的核心發現包括:
- 訓練計算資源的影響:研究發現隨着PRM模型規模的增大,性能提升呈現邊際遞減效應,強調了在模型規模和計算成本之間尋找平衡的重要性。同時,訓練數據集的多樣性顯著影響PRM性能,作者提出的ASLAF(自動步驟級標註與過濾)方法在多個基準測試中表現優異。
- 測試時擴展策略:論文評估了Best-of-N採樣、束搜索、蒙特卡洛樹搜索(MCTS)和多數投票等多種搜索策略。結果表明,在計算資源充足時MCTS效果最佳,而在資源受限情況下Best-of-N採樣是實用的替代方案。
- 跨域泛化能力:令人驚訝的是,在數學數據集上訓練的PRMs在代碼生成任務上的表現與專門針對代碼訓練的模型相當,展現出強大的跨域適應能力。通過梯度分析,研究還發現PRMs傾向於選擇具有相似底層推理模式的響應,這為理解其優化機制提供了新視角。該研究為優化大規模語言模型的訓練和部署提供了重要的理論指導和實踐參考。
04 Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
論文類型:Poster
論文下載 :PDF
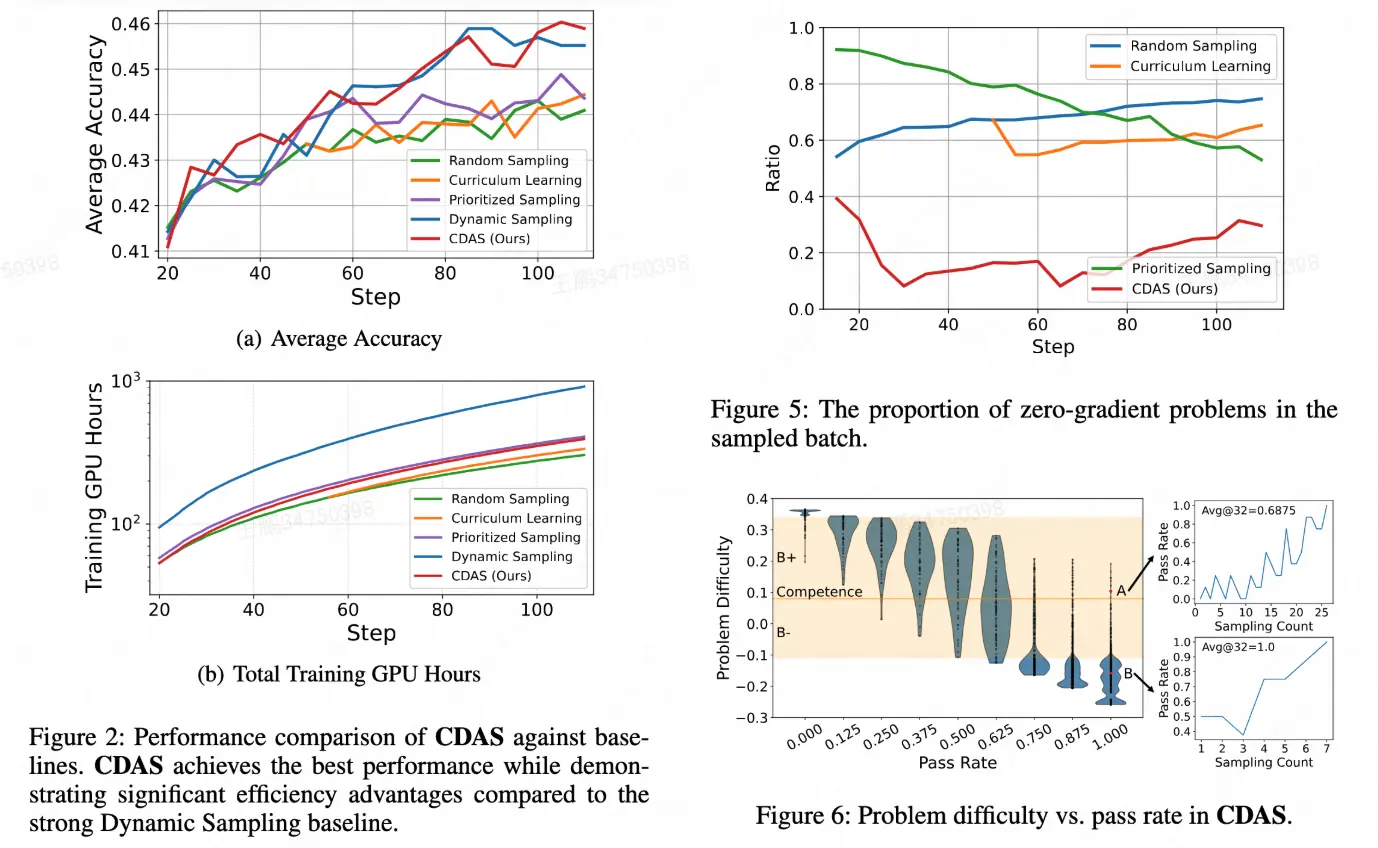
論文簡介:本文對強化學習(RL)中的問題採樣策略進行了系統性研究,當前主流採樣策略大多直接依賴單步通過率(Pass Rate) 作為問題難度指標,存在 1)對問題難度的估計不夠穩定;2)無法有效捕捉模型能力與問題難度的對齊關係的問題。
針對這些問題,本文提出了 CDAS(Competence-Difficulty Alignment Sampling):一種將模型能力與問題難度顯式建模並對齊的動態採樣方法。CDAS 不依賴單步通過率,而是通過累積歷史表現差異來構建更穩定的難度估計;同時定義模型能力,並以不動點系統確保兩者在訓練過程中共同收斂。基於能力---難度差值構建對齊指標,再通過對稱採樣策略,選取最匹配模型當前能力的問題,從而提升有效梯度比例與訓練效率。CDAS 在數學推理和代碼生成場景中均通過 RL 訓練 驗證,結果顯示 CDAS 顯著提升了採樣效率與模型性能,擊敗了多種主流採樣策略。
05 ViType: High-Fidelity Visual Text Rendering via Glyph-Aware Multimodal Diffusion
論文類型:Oral
論文下載 :PDF
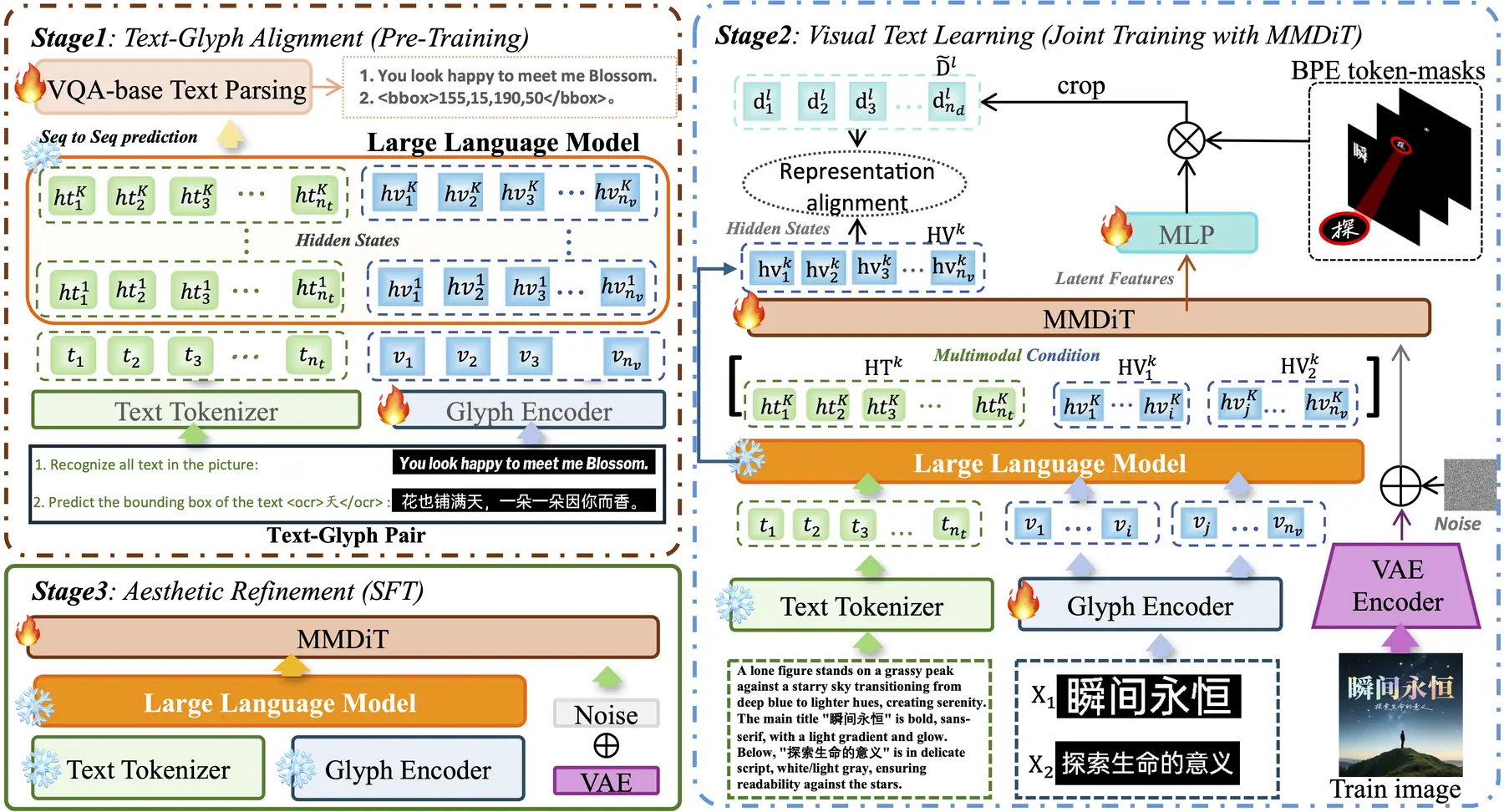
論文簡介:隨着文生圖模型在電商營銷等領域的廣泛應用,視覺文本渲染的準確性已成為制約生成質量的核心瓶頸。現有模型因缺乏字形級理解能力,難以精確刻畫多語言字符結構,導致海報、商品圖等商業場景中文字亂碼、字形失真等問題頻發,嚴重阻礙了AIGC在智能設計中的實際落地。
針對這一關鍵挑戰,我們提出ViType三階段對齊增強框架:首先通過視覺問答機制實現文本-字形顯式對齊,將字符視覺結構注入大語言模型語義空間;其次創新性地將預對齊字形嵌入與文本token同步輸入多模態擴散Transformer,通過聯合訓練建立跨模態特徵協同;最後基於高質量圖文對進行美學精調,確保生成圖像的版式和諧與視覺美感。該框架使字符準確率提升15%以上,為電商海報、營銷物料等高精度視覺內容創作提供了可靠的技術支撐。
06 DSCF: Dual-Source Counterfactual Fusion for High-Dimensional Combinatorial Interventions
論文類型:Poster
論文下載 :PDF
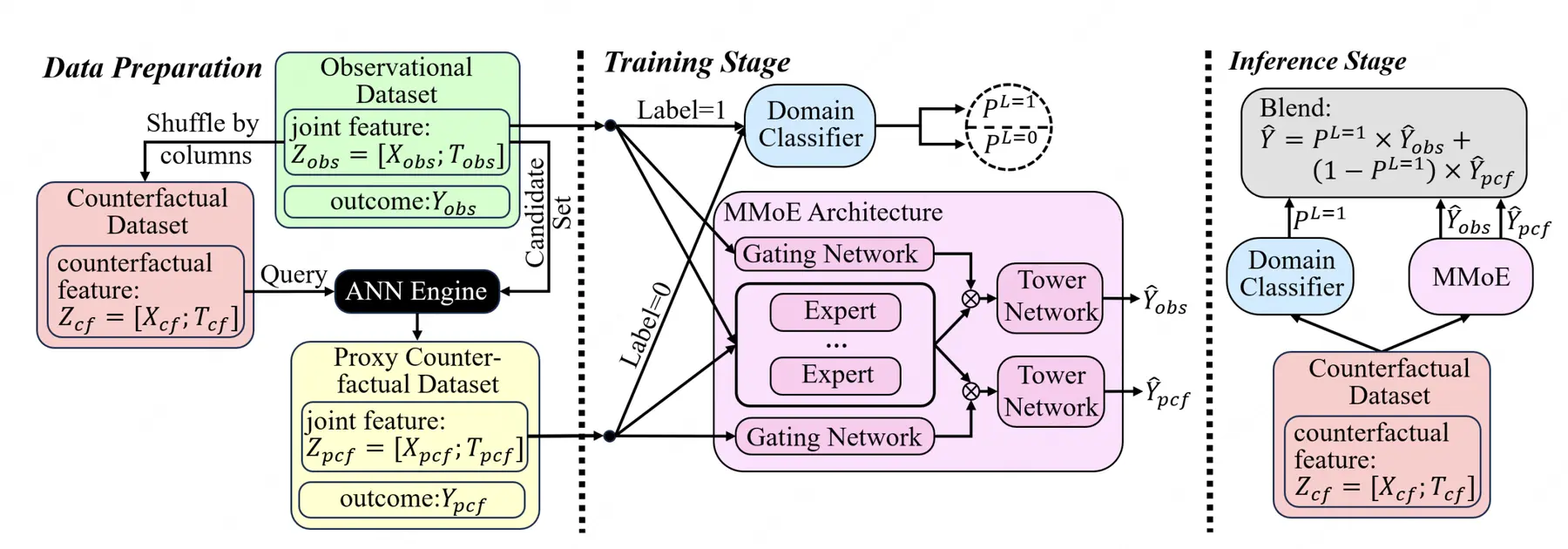
論文簡介:在個性化推薦、數字營銷和醫療健康等領域,基於觀測數據預測反事實結果對科學決策至關重要。在這些應用場景中,決策過程往往涉及高維組合干預策略,例如多渠道資源捆綁投放或產品組合推薦。面向這類場景,無論是歷史策略的效果評估還是新策略的優化,都需要模型能夠對歷史數據中很少出現甚至從未出現過的策略組合效果進行準確預測。此外,觀測數據中源於歷史分配策略和傾向性投放的選擇偏差會進一步加劇數據稀疏問題,從而影響反事實推斷的準確性。
為此,本文提出雙源反事實融合模型(Dual-Source Counterfactual Fusion,DSCF),該可擴展框架通過雙專家混合架構聯合建模觀測數據和代理反事實樣本,並採用領域引導融合機制,在有效平衡偏差消除與信息多樣性的同時,還能自適應地泛化到反事實輸入場景。在合成和半合成數據集上的大量實驗表明,DSCF框架能夠顯著提升高維組合干預場景下的預測準確性,並在不同情境下展現出優異的魯棒性表現。
07 Compress-then-Rank: Faster and Better Listwise Reranking with Large Language Models via Ranking-Aware Passage Compression
論文類型:Poster
論文下載 :PDF
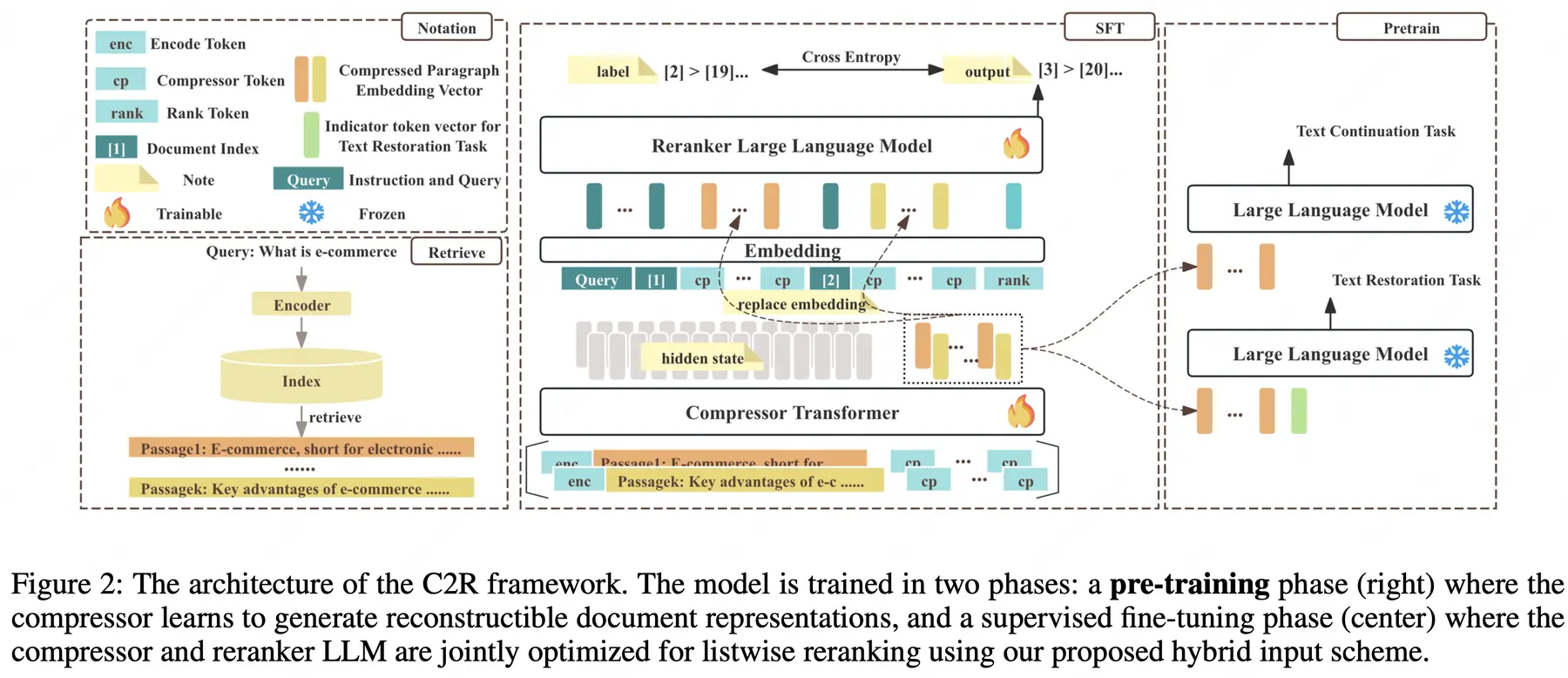
論文簡介:基於大型語言模型(LLMs)的列表重排序(listwise reranking)已經成為最先進的方法,在段落重排序任務中不斷創下新的性能基準。然而,其實際應用面臨兩個關鍵挑戰:處理長序列時高昂的計算開銷和高延遲,以及由於"迷失在中間"等現象導致的長上下文性能下降。
為了解決這些問題,我們提出了一種高效的框架壓縮後排序(Compress-then-Rank, C2R),該框架不是直接對原始段落進行列表重排序,而是對其緊湊的多向量代理進行操作。這些代理可以預先計算並緩存,適用於語料庫中的所有段落。C2R 的有效性依賴於三項關鍵創新。首先,壓縮模型通過結合文本恢復和文本延續目標進行預訓練,生成高保真的壓縮向量序列,從而減輕了單向量方法中常見的語義損失問題。其次,一種新穎的輸入方案將每個序數索引的嵌入添加到其對應的壓縮向量序列前,這不僅劃定了段落邊界,還引導重排序 LLM 生成排序列表。最後,壓縮模型和重排序模型通過聯合優化,使壓縮過程對排序目標具有排序感知能力。在主要重排序基準上的廣泛實驗表明,C2R 在提供顯著加速的同時,能夠實現與全文重排序方法相當甚至更優的排序性能。
08 Multi-Aspect Cross-modal Quantization for Generative Recommendation
論文類型:Oral
論文下載 :PDF
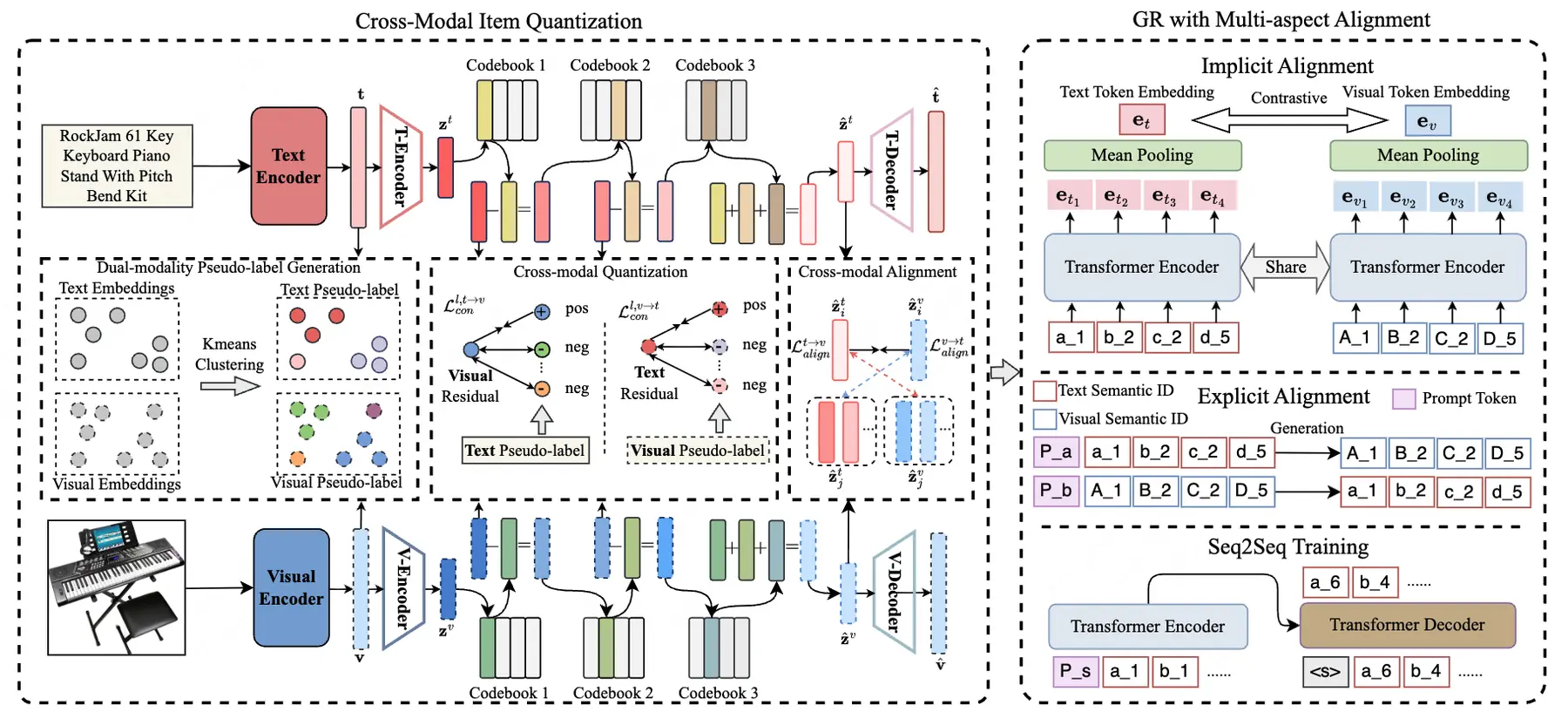
論文簡介:本文提出一種基於多模態融合的生成式推薦框架(MACRec),旨在解決現有生成式推薦方法因模態信息利用不足和跨模態交互缺失導致的性能瓶頸。
針對文本與視覺模態的量化難題,MACRec引入跨模態量化與多角度對齊機制,通過兩階段技術路線實現優化:1)跨模態殘差量化:將對比學習融入分層量化過程,生成兼具語義層次性與模態兼容性的物品標識符,顯著降低多模態表徵衝突;2)跨模態協同對齊:通過顯式-隱式協同對齊策略,分別建模文本與視覺模態的共享特徵和互補特徵,增強生成式推薦的多模態理解能力。在亞馬遜電商推薦數據集上的實驗結果表明,MACRec相較基準模型在推薦性能上有顯著提升;各模態的碼本分佈更均衡、利用率更低,充分驗證了跨模態量化與對齊機制在提升生成式推薦有效性方面的優勢。
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明"內容轉載自美團技術團隊"。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
