DeepSeek 團隊發佈新論文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,提出了可擴展的“查找式記憶”,為大模型提供了區別於傳統 Transformer 與 MoE 的全新稀疏性維度。
代碼地址:https://github.com/deepseek-ai/Engram
論文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf

DeepSeek 團隊在論文中指出,當前主流大模型在處理兩類任務時存在結構性低效:一類是依賴固定知識的「查表式」記憶,另一類是複雜推理與組合計算。傳統 Transformer(無論 Dense 或 MoE)均需通過多層注意力與 MLP 重建這些靜態模式,導致計算資源被大量消耗在「重複構造已知模式」上。
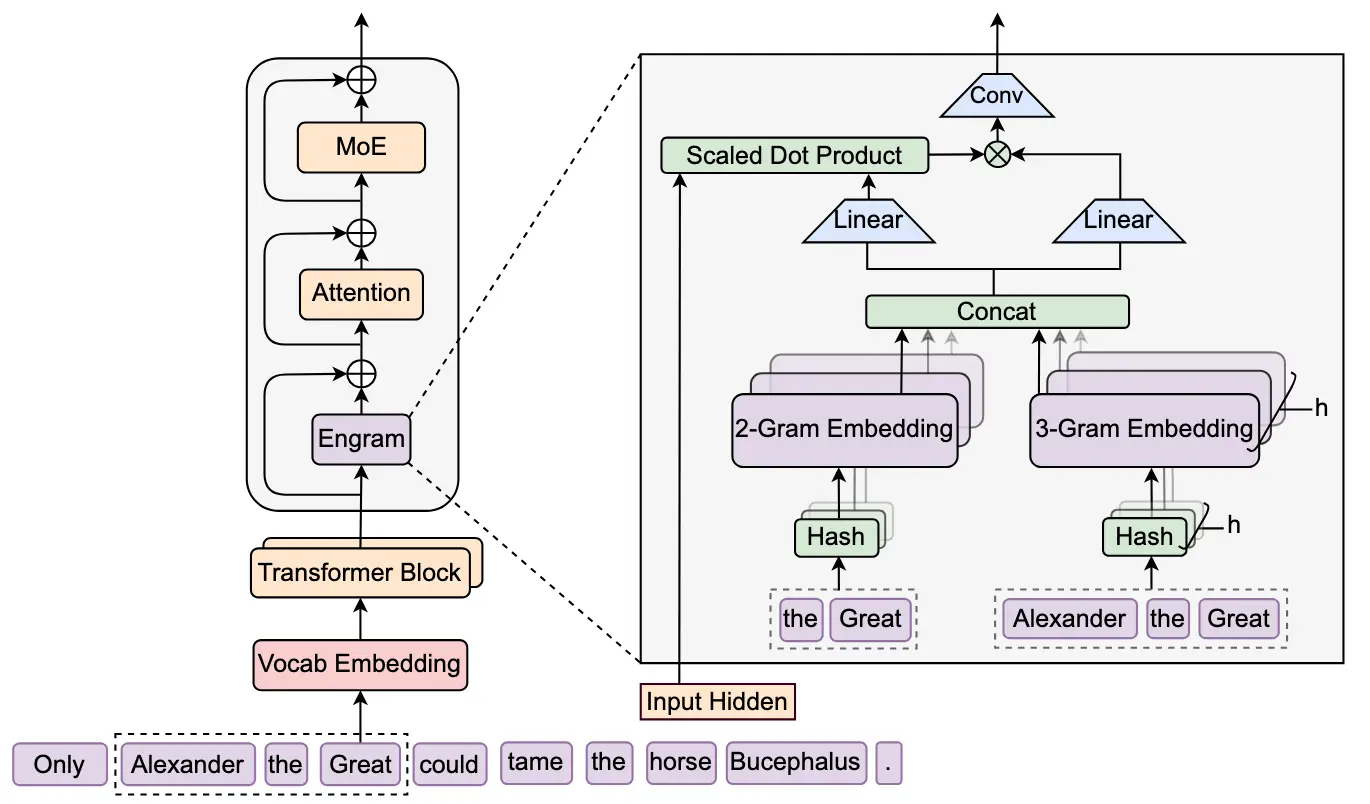
Engram 的核心機制是基於現代化哈希 N-Gram 嵌入的 O(1) 查找式記憶。模塊會對輸入 Token 序列進行 N-Gram 切片,並通過多頭哈希映射到一個規模可擴展的靜態記憶表中,實現常數時間的檢索。
論文強調,這種查找與模型規模無關,即便記憶表擴展至百億級參數,檢索成本仍保持穩定。與 MoE 的條件計算不同,Engram 提供的是「條件記憶」。模塊會根據當前上下文隱向量決定是否啓用查找結果,並通過門控機制與主幹網絡融合。
論文顯示,Engram 通常被放置在模型早期層,用於承擔「模式重建」職責,從而釋放後續層的計算深度用於複雜推理。DeepSeek 在 27B 參數規模的實驗中,將部分 MoE 專家參數重新分配給 Engram 記憶表,在等參數、等算力條件下,模型在知識、推理、代碼與數學任務上均取得顯著提升。
在 X 平台上,相關技術討論認為 Engram 的機制有效減少了模型早期層對靜態模式的重建需求,使模型在推理部分表現得更「深」。部分開發者指出,這種架構讓大規模靜態記憶得以脱離 GPU 存儲限制,通過確定性尋址實現主機內存預取,從而在推理階段保持低開銷。多位觀察者推測,Engram 很可能成為 DeepSeek 下一代模型「V4」的核心技術基礎。
