一、認識解析器 & SQL解析器
1.1、什麼是解析器?
解析器是計算機科學和編程語言領域中至關重要的工具,其核心作用是將人類可理解的 “形式化語言”(如代碼、數據格式、表達式等)轉換為機器可處理的結構,從而實現信息的解析、驗證和後續處理。我們需要解析器的原因可以從多個維度來理解。
人類使用的語言(無論是編程語言如 Python、數據格式如 JSON,還是查詢語句如 SQL)是結構化的字符串,但機器無法直接理解這種字符串的邏輯含義。
- 例如,程序員寫的
x = (a + b) * 3是一串字符,但機器需要知道這是 “先算a+b,再乘以 3,最後賦值給 x” 的運算邏輯,解析器充當這個角色,解析為一個語法樹,再按照指定的規則一步步來進行運算。
// 解析器 掃描解析方程 x = (a + b) * 3 得到的語法樹AST
[=]
/ \
[x] [*]
/ \
[+] [3]
/ \
[a] [b]
解釋執行步驟:
1、從根節點 = 開始,表示這是一個賦值操作。
2、左子樹 x 是賦值目標,右子樹 * 是計算內容。
3、計算 * 時,先計算左子樹 +(a + b),再乘以右子樹 3。
4、最後將結果賦值給 x。- 例如,程序員寫的編程語言,如C語言、Java語言等,這些語言都有特定的語法規則,通過解析器來將代碼轉為AST語法規則樹,再進行編譯字節碼、機器碼來執行。
// 解析器 掃描解析 Java代碼 if (x > 0) { y = 10; } 得到的語法樹AST
[if]
/ \
[>] [block]
/ \ \
[x] [0] [=]
/ \
[y] [10]
解析執行步驟:
1、根節點 if 表示條件判斷。
2、先計算條件 >(x > 0),如果為真:
3、進入 block 執行內部語句 y = 10(將 10 賦值給 y)。
4、如果為假,跳過整個 block。- ...
解析器的作用就是將這種字符串 “拆解” 為有意義的語法結構(如抽象語法樹 AST),讓機器能按規則執行。
1.2、如何實現解析器?
在編譯器實現中, 主要要做的就是詞法分析和語法分析:
- 詞法分析:解析代碼並生成Token(一個單詞的字面和它的種類及語義值)序列, 詞法分析的實現一般稱為掃描器(Scanner);
-
- 核心邏輯:定義token(語義)、scanner(用於掃描token)
- 語法分析:利用掃描器生成的Token序列來生成抽象語法樹, 語法分析的實現一般稱為解析器(Parser).
-
- 核心邏輯:作用是進行語法檢查、並構建由輸入的單詞組成的數據結構(一般是語法分析樹、抽象語法樹等層次化的數據結構)。
舉個例子:
數學表達式:1 + 2 * 3
// 首先在進行詞法、語法分析前,我們先定義好token
單詞字面 Token類型 説明
1 INTEGER 整數1
+ ADD_OP 加法運算符
2 INTEGER 整數2
* MUL_OP 乘法運算符
3 INTEGER 整數3
// 1、進行詞法分析,從表達式前往後掃描會得到一組Token流(實際會在詞法分析掃描過程的同時進行語法分析來不斷構建AST)
[INTEGER(1), ADD_OP(+), INTEGER(2), MUL_OP(*), INTEGER(3)]
// 2、語法分析(整個過程會去校驗是否有語法錯誤問題),根據運算符優先級(*優先於+)和Token流,構建AST:
[+]
/ \
1 [*]
/ \
2 3通常我們按照上面兩個核心組件即可實現一個解析器,利用解析器解析得到AST 語法樹之後我們就可以做很多事情了。
問題來了,我們現在就有一個需求需要實現一種規則的解析器怎麼辦?
- 方式一:不依賴任何工具,那就必須手寫掃描器和解析器。
- 方式二:使用現成市面上解析器, 實際上掃描器和解析器也都可以根據一定的規則自動生成。於是就出現了一系列的解析器生成器, 如Yacc, Anltr, JavaCC等。
若是使用方式二,這些解析器生成器都可以根據自定義的語法規則文件自動生成解析器代碼:
- 比如JavaCC可以根據後綴為
.jj的語法規則文件生成解析器的Java代碼, 這就避免了手動編寫掃描器和解析器的繁瑣, 可以讓我們專注於語法規則的設計。 - 比如antlr可以通過編寫.g4語法規則文件,也可以生成相應的解析器、掃描器來助力我們快速實現一些編譯器。
1.3、什麼是SQL解析器?
SQL解析器是能夠將SQL語句轉換為計算機可理解和執行結構的程序組件。它將文本形式的SQL語句轉換為抽象語法樹(AST),為後續的查詢優化和執行提供基礎。
**通俗一點來説:**能夠對SQL進行解析轉換語法樹的一個解析工具。
為什麼需要SQL解析?
操作數據庫的結構化數據,可以編寫一套SQL規則,人類按照指定規則編寫SQL,就可以完成一些數據的增刪改查的處理,那麼就需要有SQL解析器能夠解析SQL從而執行對應操作。
SQL解析器使用場景位於哪裏?我們數棧又為什麼需要SQLParser解析器呢?
常見數據庫執行sql,整個解析過程:
SQL文本 → 詞法分析(Tokenizer)→ 語法分析(Parser)→ AST → 語義分析 → 優化SQL -> 產生執行計劃對應執行任務 應用到袋鼠雲數棧平台上的場景:
SQL文本 → 詞法分析(Tokenizer)→ 語法分析(Parser)→ AST → 應用層(實現類型識別,表字段血緣、表解析、SQL脱敏) -> 子產品應用1.4、認識市面上的一些解析器 & SQL解析器
一覽圖
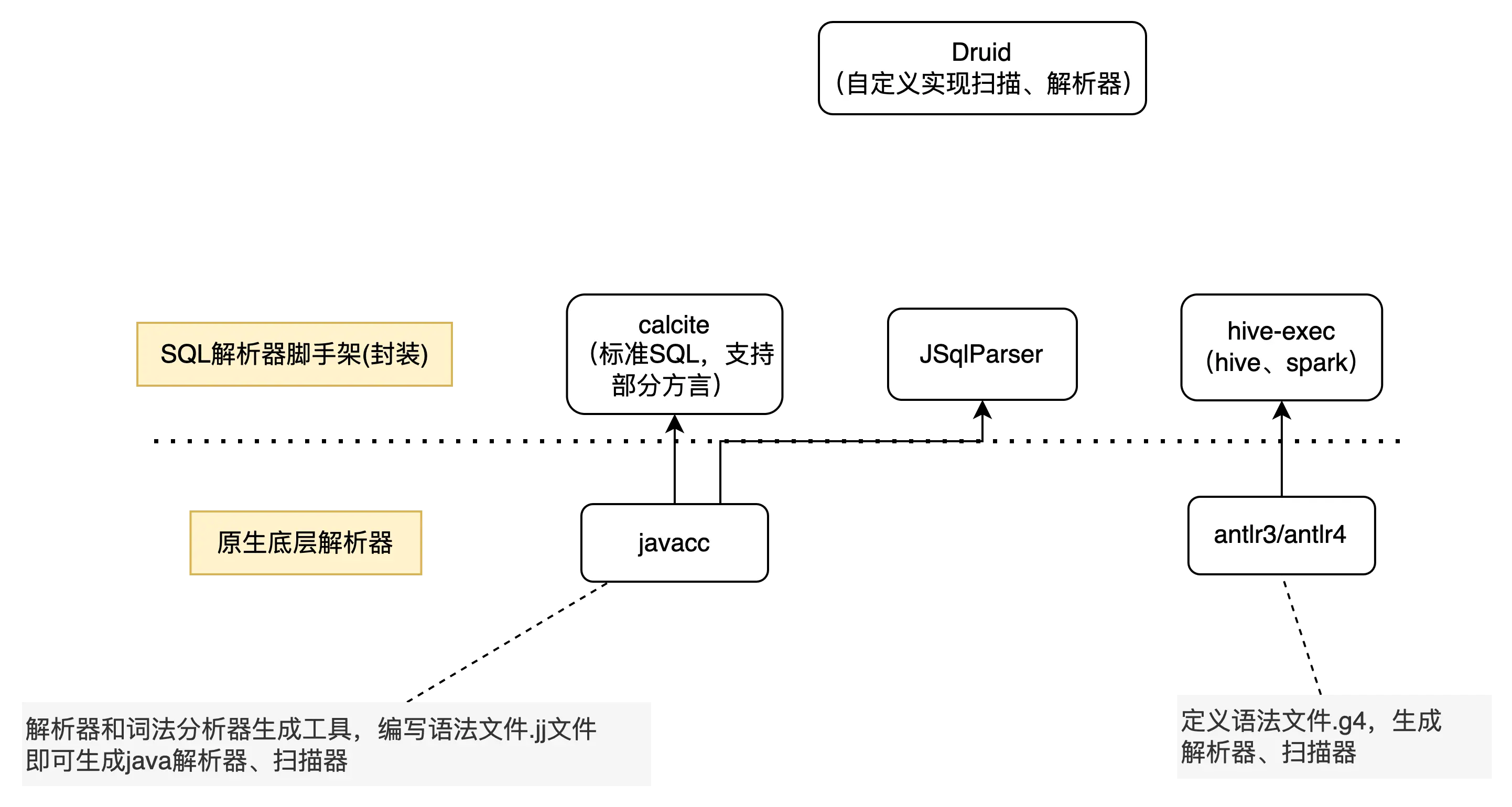
1.4.1、底層解析器
1)底層解析器件:市面上主流就是javacc、antlr3/4,內部已經幫你封裝好掃描器、解析器,你只需要按照一定的規則去編寫語法文件,即可完成掃描器、語法解析器代碼編寫,下面是區別:
|
特性 |
JavaCC |
ANTLR 3 |
ANTLR 4 |
|
語法分析算法 |
LL(k) |
LL(*) |
LL (*)(自適應預測) |
|
左遞歸處理 |
不支持,需手動轉換 |
需手動轉換 |
自動處理 |
|
目標語言 |
Java |
Java、C#、Python 等 |
同 ANTLR 3 |
|
錯誤處理 |
基礎錯誤恢復 |
增強的錯誤恢復 |
智能錯誤恢復與診斷 |
|
語法複雜度 |
簡單直觀 |
較複雜 |
簡化(相比 ANTLR 3) |
|
工具鏈 |
基礎工具 |
豐富(包括調試工具) |
進一步增強(如可視化工具) |
|
應用場景 |
小型項目、教育 |
中大型項目 |
大型項目、複雜語法 |
|
社區活躍度 |
一般 |
活躍 |
非常活躍 |
|
發佈時間 |
1990 年代 |
2007 年左右 |
2012 年發佈 |
JavaCC:
- javacc官網:https://javacc.github.io/javacc/
- github:https://github.com/javacc/javacc
Antlr4:
- 官網:https://www.antlr.org/
- github:https://github.com/antlr/antlr4
值得一提的是,antlr4支持很多編程語言以及各種類型的SQL,antlr4有一個官方語法倉庫:https://github.com/antlr/antlr4,支持了大量的SQL語法規則,都已經適配好了,至於為什麼後續我們改造中沒有直接使用antlr4,而是選擇使用druid-core來進行二開實現後續會進行單獨説明。
- grammars-v4:這是一個開源項目,提供了多種語言的語法文件,包括 SQL 方言(如 MySQL、PL/SQL、T-SQL 等)。開發者可以直接使用這些語法文件,或者在此基礎上進行擴展。
- PS:袋鼠雲的數棧前端團隊離線任務等其他子產品的SQL編輯器裏就使用到了SQLParser(強依賴antlr4),我這裏貼下開源倉庫地址 https://github.com/DTStack/dt-sql-parser/blob/main/README-zh_CN.md,基於antlr4-c3來進行擴展一些額外功能,他們主要實現的如關鍵詞高亮,代碼補全等功能。
1.4.2、calcite & hive-exec(SQL解析器)
為什麼説他們是SQL解析器腳手架呢?
- 腳手架指的是已經實現了在sql標準規範上給我們基於javacc、或者antlr實現了一套SQL詞法、語法解析規則,我們只需要按照他們實現的擴展即可,主要包含如下:
calcite:基於javacc,已經實現了標準SQL解析的能力,一個模塊化、可擴展的SQL解析器和優化器框架,你可以基於這套標準SQL解析框架去擴展自定義的SQL語法。
- 官網:https://calcite.apache.org/
- github:https://github.com/apache/calcite
hive-exec包:基於antlr3,支持hive數據源的語法解析。
- 底層基於antlr3實現,是hive的核心包。
- 早期數棧就是使用的這個核心包來對hive、spark實現SQL解析,後續來實現一系列的應用層解析能力。
1.4.3、JSqlParser、Druid-core
JSqlParser:JSqlParser是一個SQL語句解析器。它在Java類的可遍歷層次結構中轉換SQL。JSqlParser不限於一個數據庫,而是提供了對Oracle,SqlServer,MySQL,PostgreSQL等許多特殊數據庫的支持。
- 官方網站:https://jsqlparser.github.io/JSqlParser/
- JSqlParser:https://github.com/JSQLParser/JSqlParser
Druid-core:完成使用java自己實現掃描器、語法解析器,解析出來的語法樹同樣是一顆更加具像化的抽象語法樹(具有繼承關係)
- 開源地址:https://github.com/alibaba/druid
核心對比區別
|
工具 |
javacc |
antlr4 |
calcite |
hive-exec |
JsqlParser |
Druid-core |
|
依賴工具 |
原生定義解析規則 |
原生定義解析規則 |
基於javacc |
基於antlr3 |
基於javacc |
原生java實現掃描、解析器件 |
|
解析SQL能力 |
無 |
有,官方有相應擴展SQL類型語法規則(生態極好) |
標準SQL(支持多方言擴展,生態實現較弱) |
HiveSQL、Spark |
標準SQL,支持Oracle,MySql,SQLServer、PostgreSQL特定方面解析 |
支持mysql、oracle、hive、spark、doris、starrocks等 |
|
語法樹節點是否具有類繼承關係(抽象SQL結構) |
無 |
無 |
有 |
無 |
有 |
有(極強) |
|
優缺點 |
從零定義SQL規則 |
官方語法生態支持能力強,支持visitor等模式,解析語法樹無抽象繼承關係 |
提供標準SQL解析,但生態數據源語法支持較弱,需要手動去擴展分層單獨寫語法規則文件(成本大) |
只支持特定hive、spark語法解析,無法擴展分層其他數據源 |
api層面無區分數據源類型,雖然整體提供較好特性能力且支持部分SQL方言 |
支持數據源解析能力的分層,**解析AST 語法樹有繼承關係,支持數據源生態較好。**缺點:java代碼自實現分析掃描器,入門學習有難度。 |
二、數棧原始的SQLParser
歷史背景
下面是各個服務會涉及到的功能以及使用到的解析器:
離線服務:
- 涉及功能:sql類型識別、真實表解析、SQL脱敏、行列級權限
- 實現:calcite & hive-exec模塊解析器,加上druid兜底
API服務:
- 涉及功能:api解析(預編譯、非預編譯)、真實表解析、行列級權限
- 實現:calcite + druid
label標籤:
- 涉及功能:標籤解析
- 實現:calcite
實時 flinksql:
- 涉及功能:字段、表血緣
- 實現:Flink提供的parser、hive-exec、正則。
資產服務:
- 涉及功能:表、字段血緣解析、真實表解析、SQL類型識別
- 實現:使用到calicite、druid 以及hive-exec。
**總體描述:**目前主要維護較多的離線、API、資產模塊的SQL解析,可以看到不同的子產品解析會使用涉及到很多解析工具,也同樣包含多種兜底情況。
關於SQL解析擴展方面:歷史針對於SQL語法層面的擴展很少,=做過擴展的就是基於calcite擴展了部分語法(統一是在extend-calcite模塊中,做過語法擴展歷史有limit、like關鍵字等)
歷史設計實現思路
不同數據源整體分類:calcite(rdb類型)、hive-exec(spark、hive)進行解析。【druid、正則方式作為兜底】
業務邏輯分類:
一類:對於SQL類型識別、表解析、SQL脱敏、行列級權限
- 根據SQL類型使用calcite、hive-exec來進行SQL解析得到語法樹
- 根據語法樹來進行上述業務邏輯處理
另一類:對於血緣實現,calcite、hive-exec解析得到的語法樹 => 轉換數棧自己的語法樹 => 針對自己語法樹來實現表、字段血緣解析。
- 根據SQL類型使用calcite、hive-exec來進行SQL解析得到語法樹
- 自定義語法樹,實現了兩套轉換器Node Adapter邏輯,calcite語法樹 => 自定義語法樹、hive-exec語法樹(AstNode) => 自定義語法樹
- 通過血緣解析邏輯針對於自定義語法樹完成解析能力 【以前設計應該是聚焦一套邏輯實現血緣解析】
歷史設計的遺留問題
1、不同數據源語法解析擴展能力弱,基本不同rdb語法需要去正則前置處理 或者 單獨去extend-calcite去擴展語法(擴展語法集中在一個模塊)
2、使用到了多種不同的解析框架,各種兜底,代碼維護難,拿到語法樹之後進行應用層解析邏輯也冗餘到一起,維護起來到處都是if 判斷數據源兼容邏輯,可能改一個地方會影響到其他地方,從而不可維護。
3、血緣解析擴展弱,學習成本極高。
- 首先你需要了解calcite、astnode的各種類型節點定義,你還需要有自定義語法樹能力。
- 有了這兩點前置基礎之後,你需要去擴展calcite、astnode節點轉換自定義語法樹節點的邏輯(容易死循環)。
- 直到轉換自己的語法樹之後,才到了血緣解析層面的解析,你還需要懂血緣解析的邏輯,這一套下來門檻很高。
三、SQLParser技術改造
3.1、SQLParser分層改造(雙層改造)
拆分為兩個層面分層:語法解析、應用層解析
第一個層面:語法解析分層
解析器方面:
在解析SQL層面,我們期望能夠有一個可擴展實現的解析器和掃描器,這就需要我們有一個基於標準SQL的解析掃描實現,在上層抽象類中定義各個抽象的指定類型的掃描方法,能夠實現後續各個不同數據源的掃描擴展。
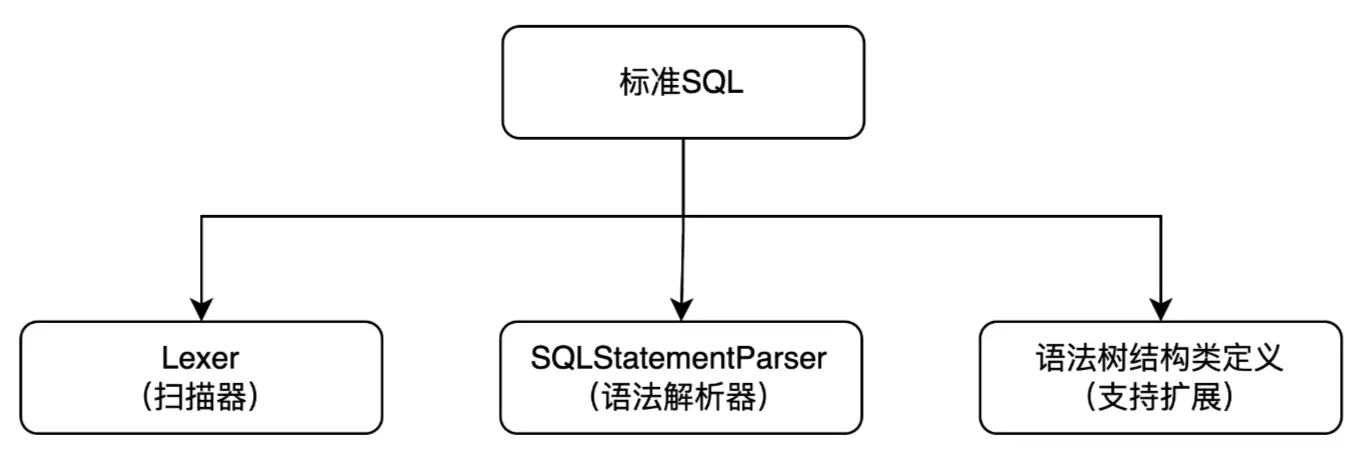
分層實現掃描器、解析器都可支持繼承複用功能,且相互獨立互不影響,結構類可自定義擴展:
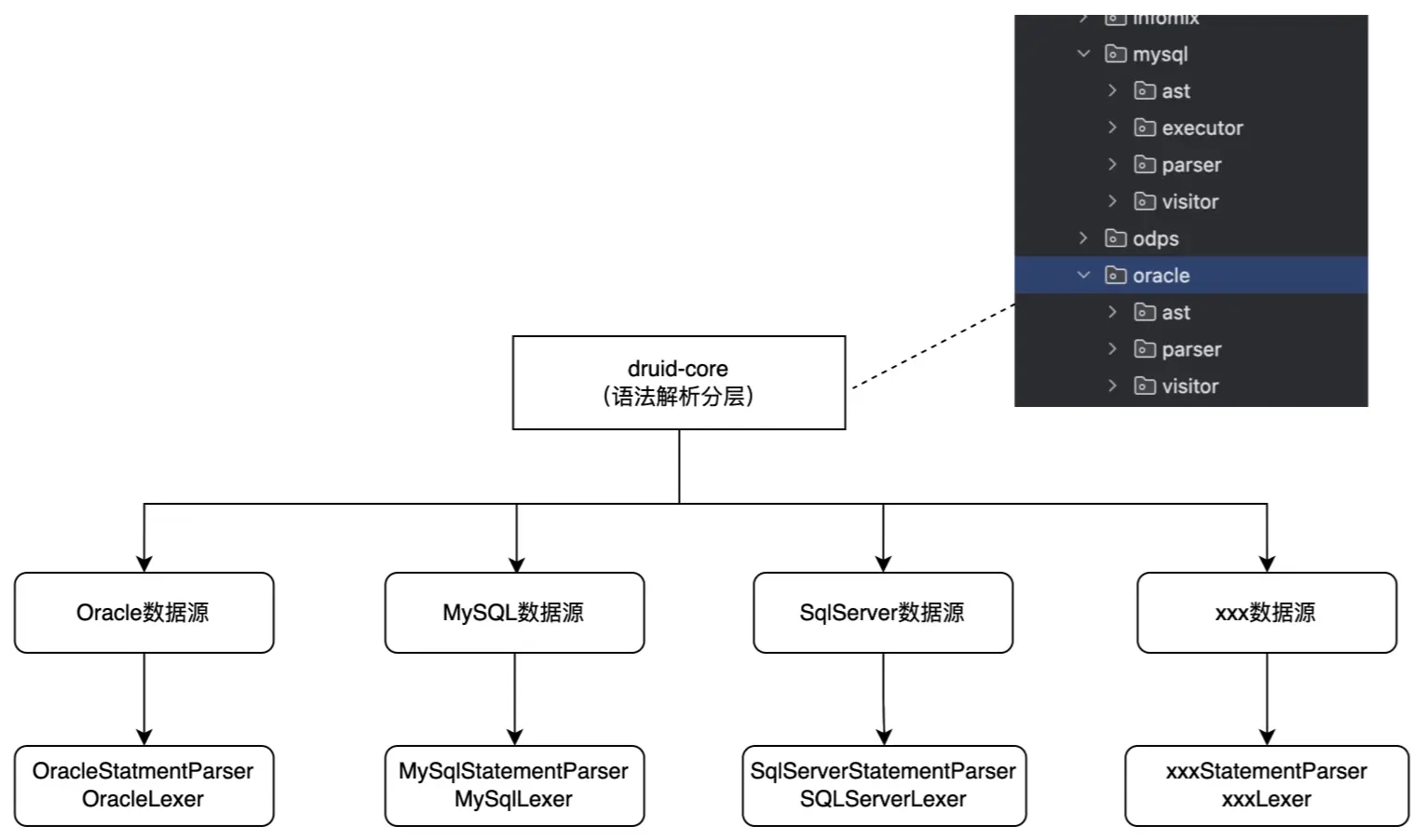
語法樹方面:
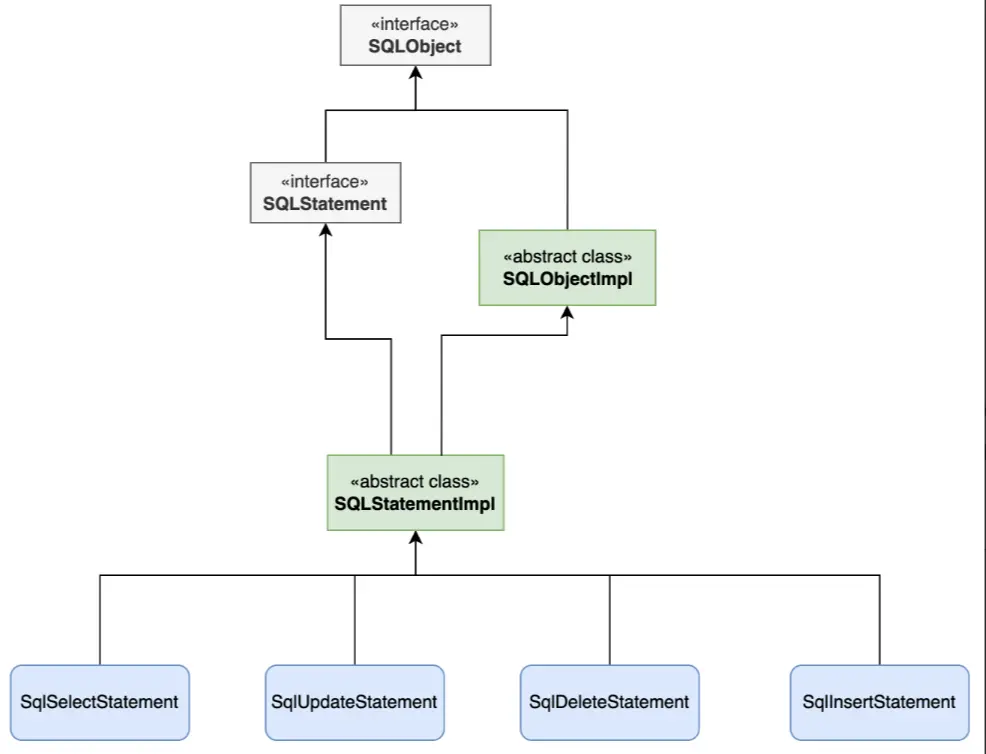
通過解析器,能夠將SQL轉為一個語法樹,而對於最終的語法樹,我們更期望的應該是一個具象的語法樹,而不是特別精細的類似於antlr4的語法樹,我們期望的應該是所有不同類型的SQL可以轉為一個對應具體類型的一個結構,如:create sql、select sql、insert sql、update sql、delete sql,能夠都去抽象出來對應的類如下圖,每個類有對應特定類型的屬性值,如表名、字段名等屬性。【這裏是拿到druid的抽象實現】
當我們來解析同一個sql,來看下不同的解析框架得到的結果:
select * from changlu where id = 1 and name = 3;Druid得到的語法樹結構則為SQLSelectStatment,其為一個select sql,同時整個sql中的各個結構則為各個屬性:
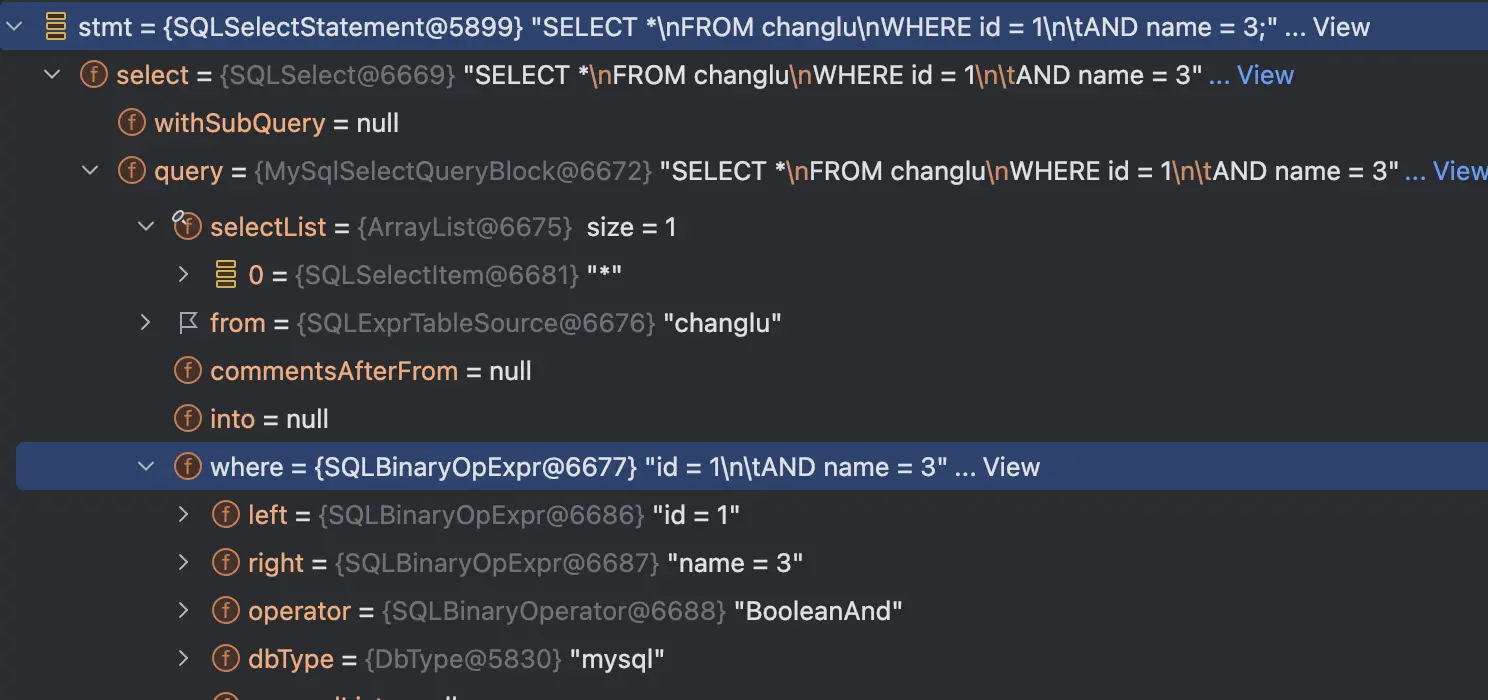
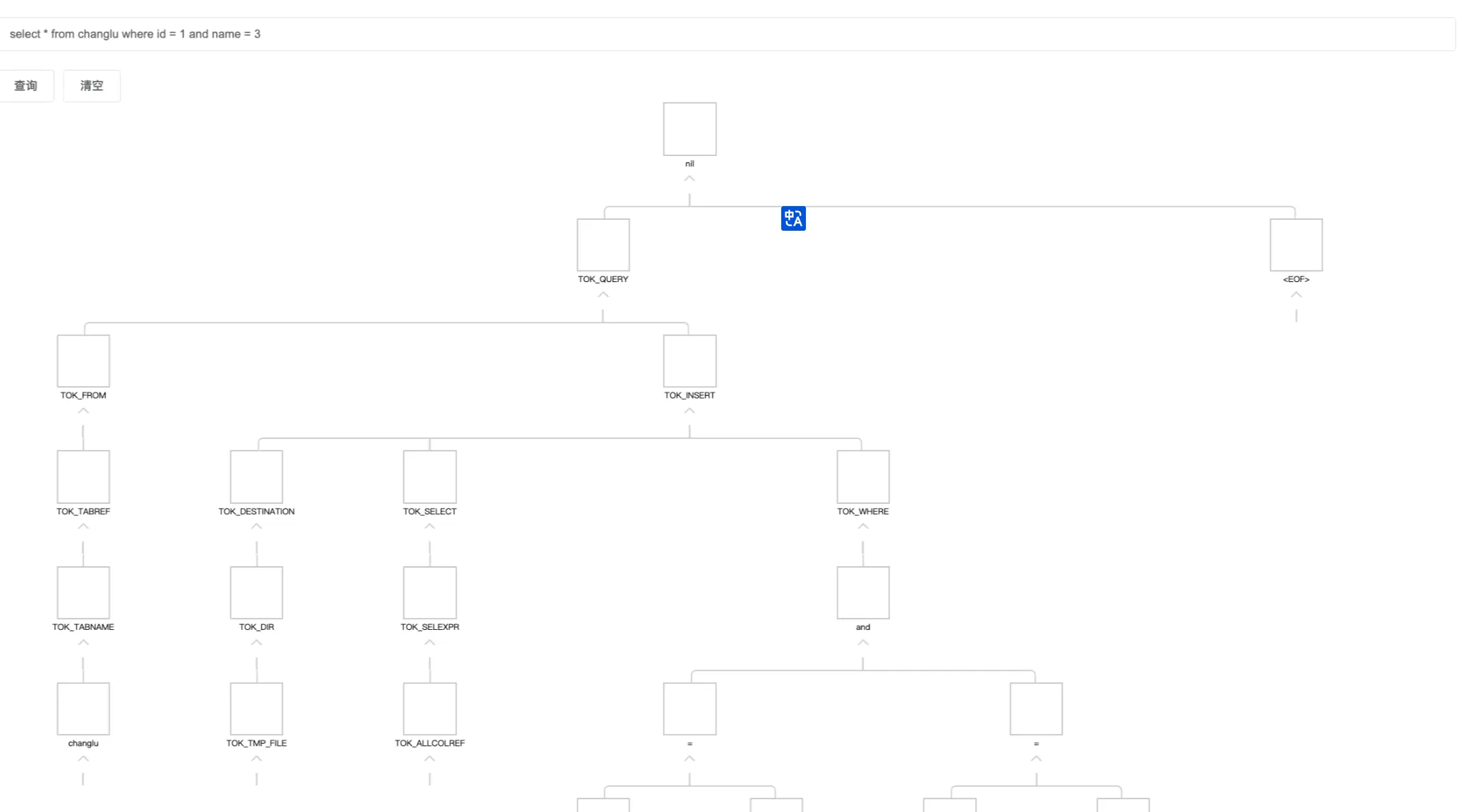
而不是antlr3得到的一顆語法樹,如下(這個是hive-exec包解析到的樹,底層使用的是antlr3):
通過對市面上各種SQL解析器調研,發現druid中的core包中就實現了我們想要的這樣子可擴展實現的掃描器、解析器,最終不同的數據源SQL都可以具像化的轉為對應類型的Statement類結構,也就是比較具像化的語法樹,後續我們就可以在這樣子的統一結構的語法樹中實現一套業務邏輯處理,就能夠實現表解析、血緣解析、SQL脱敏等等業務層功能。
實際上通過使用calcite、antlr3/4都可以實現後續的業務邏輯處理,這裏選擇druid-core的原因和其他數據源的對比主要有以下幾點:
1、calcite分層的話,單獨數據源需要單獨抽取一個模塊,同時需要單獨每一個數據源去維護一個語法規則文件,具有調試難度較大,官方對於特定不同數據源語法的支持較弱,如果要實現calcite分層,基本我們需要從頭開始去針對不同數據源去完善語法規則文件,而且還只是在語法解析層面。
2、anlr4官網提供的grammer庫,雖然很全,但是並不適用我們需要對多種不同類型的SQL實現多種業務邏輯解析,如表解析、血緣等,因為雖然官網提供grammer庫支持了很多數據源,但是你會發現解析到語法樹之後,他們不同類型的sql對應的語法樹節點的名稱都是各不相同的,你可以理解每一種數據源解析出來語法樹之後,需要對每一個語法樹來進行適配各個業務層解析。
3、druid-core對於掃描解析全部自定義實現,同時掃描器、解析器支持可擴展分層,同時不同SQL類型解析出來的語法樹都是同一棵具象語法樹,我們可以輕鬆的寫一套邏輯即可適用多種不同的RDB SQL類型的業務解析。
- 唯一缺點就是:你需要理解其掃描器、語法解析器的核心原理實現,要能夠理解原始node節點的抽象設計並很好的繼承去實現。
關於druid-core內部使用方面:
- 目前團隊內部已經開始進行druid二開,獨立一個druid倉庫來去維護後續語法解析能力的擴展,截止目前已進行了多次語法擴展,如支持doris的alter類型的sql、like %${var}%結構類型以及select 字段精確點位記錄等,擴展速度方面也較快。
- 對於後續druid官方開源倉庫更新迭代,我們也會去定期進行合併代碼進來,在針對我們自己的SQL語法擴展中,我們單獨去維護了一組單測,主要用於測試驗證我們自行擴展的語法,避免後期合併代碼 & 修改業務邏輯影響語法解析能力。
第二個層面:業務解析分層
**回顧之前的解析層:**我們對於不同類型的SQL通過一套通用的掃描解析器 解析之後可以得到一顆統一抽象結構語法樹。
那針對我們應用層:針對統一的語法樹實現一套解析方法實現。在實現這樣子的一套通用的解析方法過程中,我們也考慮到可能不同的SQL類型我們就擴展特定的SQLStatment節點,我們還去進行了業務層解析的分層,能夠實現針對某個數據源來進行業務解析分層擴展。
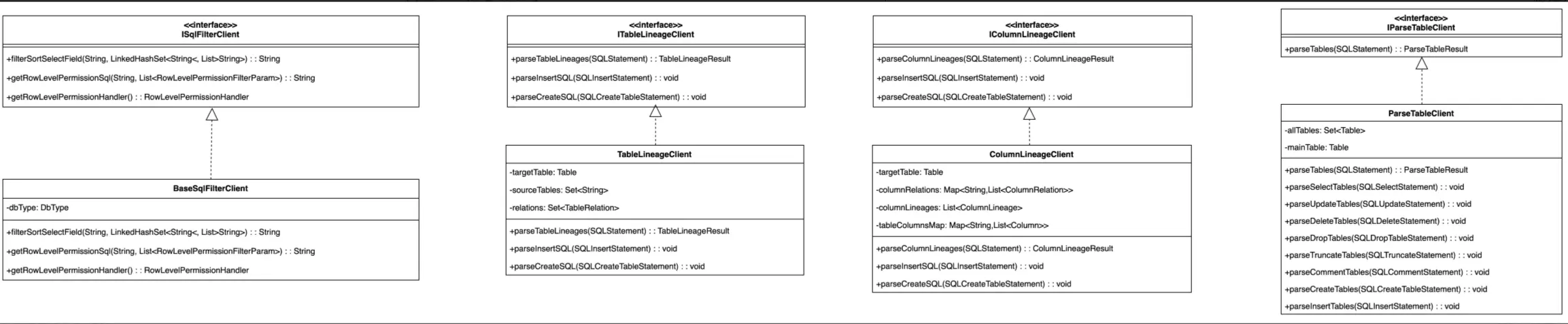
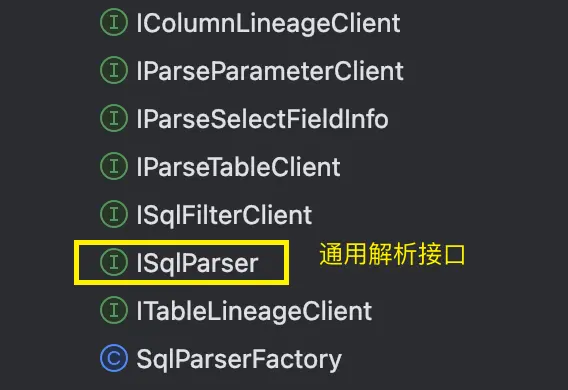
我們設計了接口及相應的組件:
- ISqlParser接口,這個接口具有不同業務層解析的能力,如表、字段血緣解析、表解析、函數解析、SQL脱敏、API解析等等。
- BaseSqlParser類:作為一套通用的解析語法樹的基類解析實現類,其內部設計了多個getxxxClient的獲取特定組件的方法,實際上對應的一些解析方法具體實現會根據所綁定的具體client來提供某個解析能力。

例如權限相關的解析我們單獨設計了一個ISqlFilterClient接口,其就有一個BaseSqlFilterClient的基類實現,將這個組件通過get的方式封裝到BaseSqlParser中,就能夠實現後續不同的ISqlParser解析方面的動態分層擴展更換相應的組件了。
目前在我們sqlparser模塊中維護了業務層解析分層的實現:
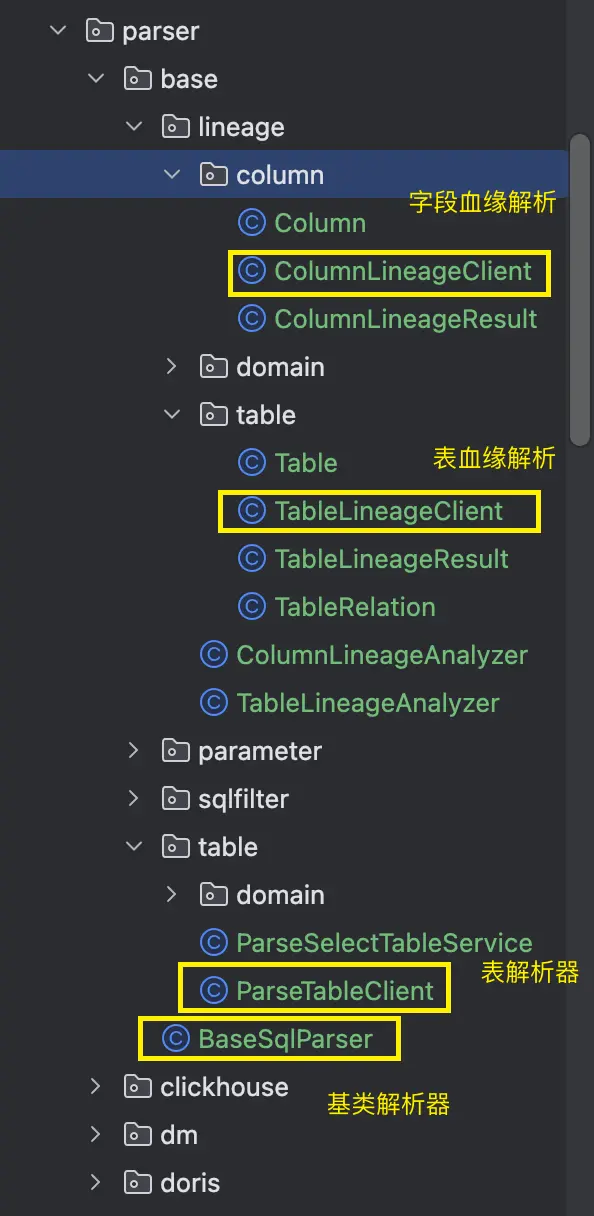
在我們基類BaseSqlParser中實現大致如下:
public class BaseSqlParser implements ISqlParser {
@Override
public ColumnLineageResult parseColumnLineages(String sql, Map<String, List<Column>> tableColumnsMap) {
SQLStatement sqlStatement = this.parseStatement(sql);
return this.parseColumnLineages(sqlStatement, tableColumnsMap);
}
@Override
public ColumnLineageResult parseColumnLineages(SQLStatement sqlStatement, Map<String, List<Column>> tableColumnsMap) {
IColumnLineageClient columnLineageClient = this.getColumnLineageClient(tableColumnsMap);
// 執行字段血緣解析
return columnLineageClient.parseColumnLineages(sqlStatement);
}
@Override
public ParseTableResult parseTables(SQLStatement sqlStatement) {
IParseTableClient parseTableClient = this.getParseTableClient();
// 執行表解析
return parseTableClient.parseTables(sqlStatement);
}
// 替換解析表組件
protected IParseTableClient getParseTableClient() {
return new ParseTableClient();
}
// 替換字段血緣解析組件
protected IColumnLineageClient getColumnLineageClient(Map<String, List<Column>> tableColumnsMap) {
return new ColumnLineageClient(tableColumnsMap);
}
}對於具體的業務解析就會分別分佈在特定的xxxClient中去實現。
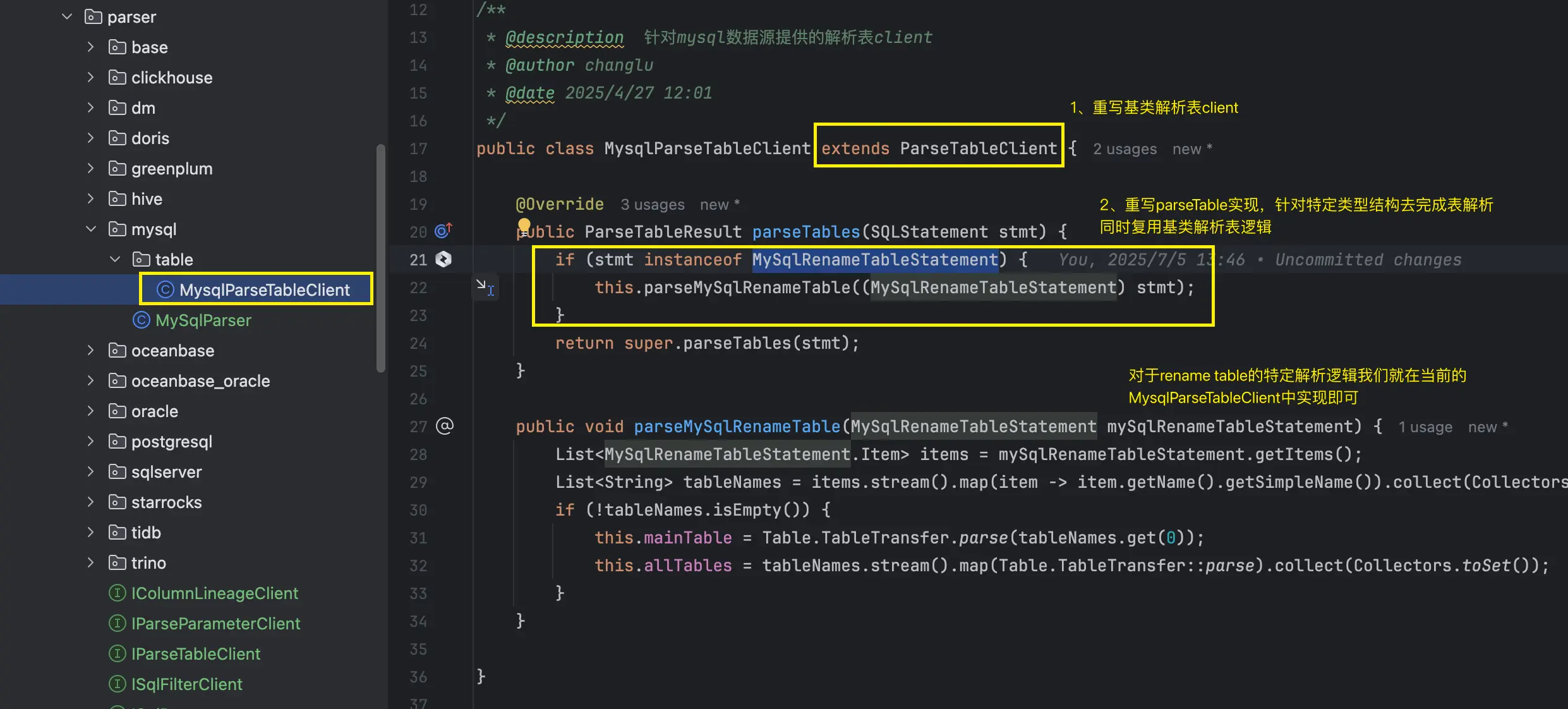
**那麼語法層的解析如何去擴展呢?**例如我們在二開的druid-core中去擴展了mysql的特定SQL類型的statemnet節點:MySqlRenameTableStatement。
那麼在對應的業務層表解析中,我們實際上在進行表解析邏輯處理時,也要對該類型的statement類型來進行解析,不然的話就會出現遺漏掉需要解析的真實表。
我們首先單獨定義一個叫做MysqlParseTableClint,其繼承ParseTableClient,並重寫其中的parseTables方法:
接着將該解析組件註冊到MySqlParser中:
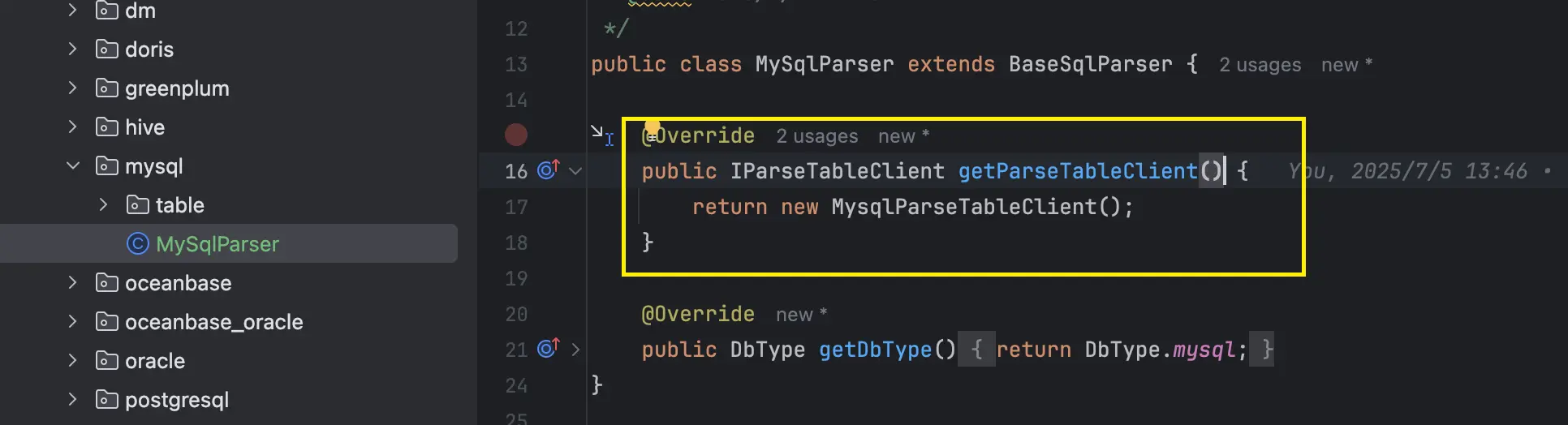
這樣子我們就完成了特定MySQL的SQL解析器件的擴展。
3.2、分層改造後的API使用方式
我們在去使用特定SQL解析的時候,首先通過工廠類SqlParserFactory來根據指定數據源類型拿到特定的SqlParser實現,接着使用這個sqlparser即可完成特定的表解析、字段解析、血緣解析等等,接口調用方式目前還是非常簡潔易懂的。
// 準備sql
String sql = getSql();
// 1、獲取到sqlparser解析器
// 方式一:工廠方式獲取
ISqlParser sqlParser = SqlParserFactory.getSqlParser(DbType.mysql);
// 方式二:直接new
// MySqlParser mySqlParser = new MySqlParser();
// 2、實現解析功能
// 2.1、解析表
ParseTableResult parseTableResult = sqlParser.parseTables(sql);
System.out.println("====解析表====");
System.out.println(parseTableResult.getMainTable());// 獲取主表
System.out.println(parseTableResult.getAllTableName()); // 獲取解析到的所有表
// 2.2、解析字段血緣
System.out.println("\n====解析字段血緣====");
// 針對select * from table 場景,可傳入tableColumnsMap封裝真實的表字段信息
Map<String, List<Column>> tableColumnsMap = new HashMap<String, List<Column>>(){
{
this.put("users",
Arrays.asList(new Column("id", 0)
, new Column("name", 1)
));
this.put("orders",
Arrays.asList(new Column("amount", 0)
, new Column("id", 1)
));
}
};
ColumnLineageResult columnLineageResult = sqlParser.parseColumnLineages(sql, tableColumnsMap);
columnLineageResult.printColumnLineage();
// 2.3、解析表血緣
System.out.println("\n====解析表血緣====");
TableLineageResult tableLineageResult = sqlParser.parseTableLineages(sql);
List<TableLineage> tableLineages = tableLineageResult.getTableLineages();
System.out.println(tableLineages);
// 2.4、解析函數
System.out.println("\n====解析函數====");
Set<String> functions = sqlParser.parseFunction(sql);
System.out.println(functions);3.3、內部子產品 & 歷史邏輯兼容處理
通過此次技術改造,我們可以説是重點會對druid-core來進行二開語法解析擴展,同時還會基於druid-core完成解析表、血緣等等的業務邏輯處理,我們將目前數棧應用到的業務邏輯,基於druid解析到的語法樹都進行重新實現了一遍。
對於歷史子產品的兼容邏輯處理,我們額外單獨設計了一個Proxy類和特定的DruidNodeParser,用於替換歷史的calciteNodeParser,將歷史的CalciteNodeParser作為解析兜底,後續碰到語法解析能力不足的優先都會以當前這一套分層實現來去擴展維護。
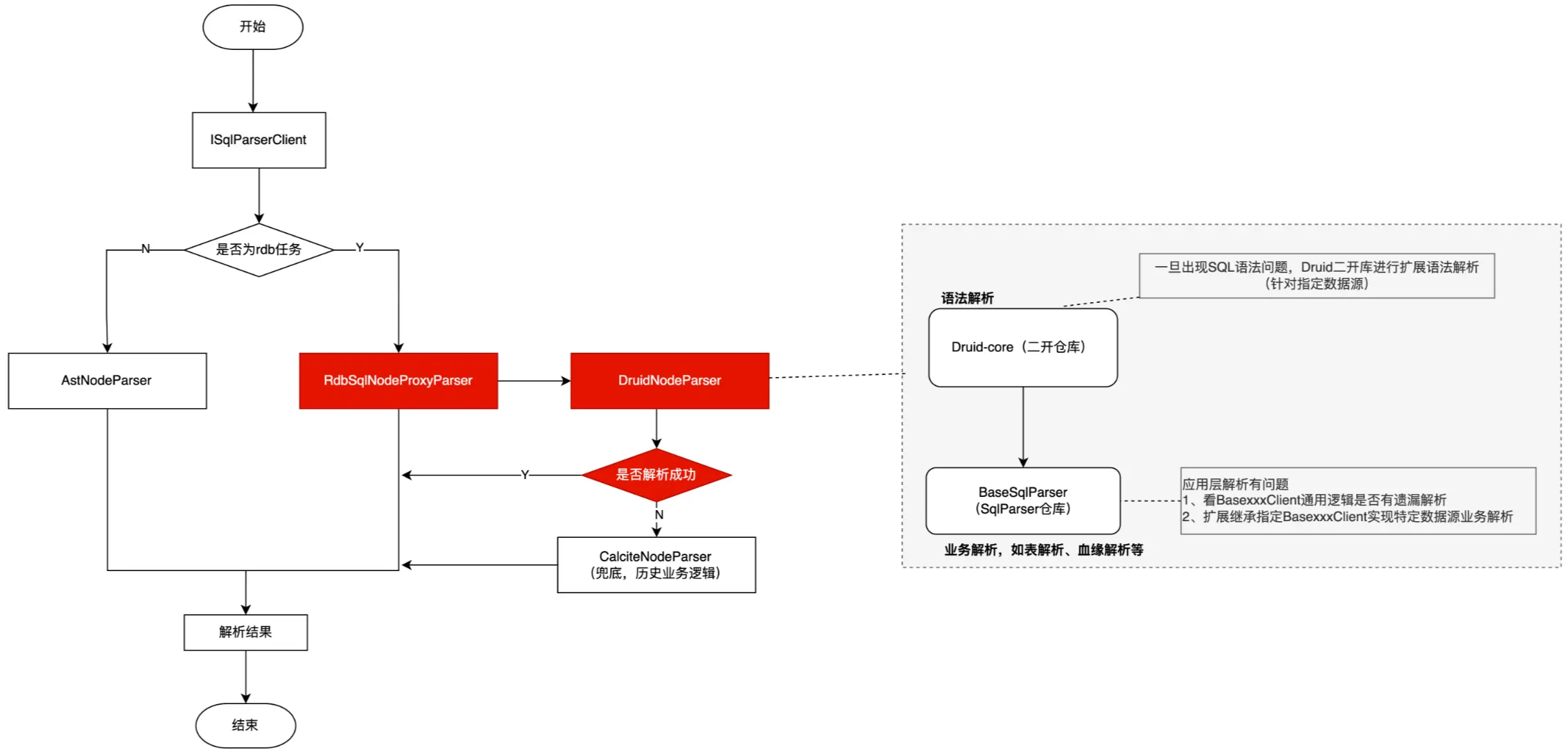
這對這個proxy類實現&兜底邏輯,我們主要目的也是去本地單測未涉及到以及測試側驗證的單例來進行兜底,避免影響客户原始業務邏輯能力。
同時目前我們並沒有將所有的不同數據源SQL類型的解析之前一次性遷移為當前這一套邏輯,因為袋鼠雲是面向toB場景,為大量很多公司、政企服務,我們目前也在內部慢慢針對部分特定數據源解析邏輯進行平滑遷移,實現未來能夠支撐更多不同類型SQL的解析能力和業務擴展能力。
未來設想
後續我們完善測試驗證之後,會對這樣一套SQL解析框架核心實現邏輯進行開源,各位小夥伴可以期待一下。
