YuanLab.ai 團隊正式開源發佈 源 Yuan3.0 Flash 多模態基礎大模型。包括模型權重(16bit與4bit模型)、技術報告,完整的訓練方法與評測結果,支持社區在此基礎上進行二次訓練與行業定製。
根據介紹,Yuan3.0 Flash 是一款 40B 參數規模的多模態基礎大模型,採用稀疏混合專家(MoE)架構,單次推理僅激活約 3.7B 參數。Yuan3.0 Flash創新性地提出和採用了強化學習訓練方法(RAPO),通過反思抑制獎勵機制(RIRM),從訓練層面引導模型減少無效反思,在提升推理準確性的同時,大幅壓縮了推理過程的 token 消耗,顯著降低算力成本,在 “更少算力、更高智能” 的大模型優化路徑上更進一步。
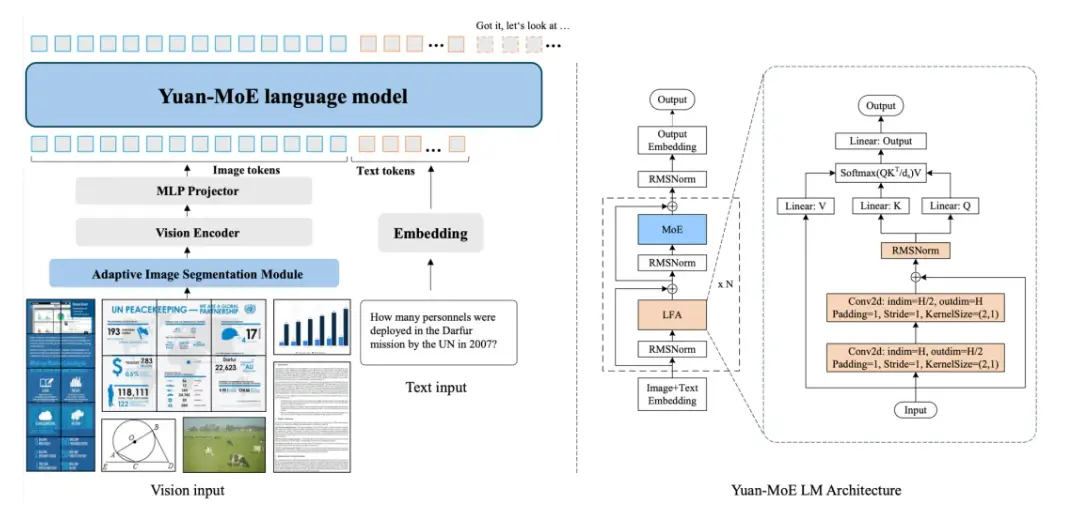
Yuan3.0 Flash 由視覺編碼器、語言主幹網絡以及多模態對齊模塊組成。語言主幹網絡採用局部過濾增強的Attention結構(LFA)和混合專家(MoE)結構,在提升注意力精度的同時,顯著降低訓練與推理的算力開銷。
多模態方面,採用視覺編碼器,將視覺信號轉化為token,與語言token一起輸入到語言主幹網絡,通過多模態對齊模塊實現高效、穩定的跨模態特徵對齊。同時,引入自適應圖像分割機制,在支持高分辨率圖像理解的同時,有效降低顯存需求及算力開銷。
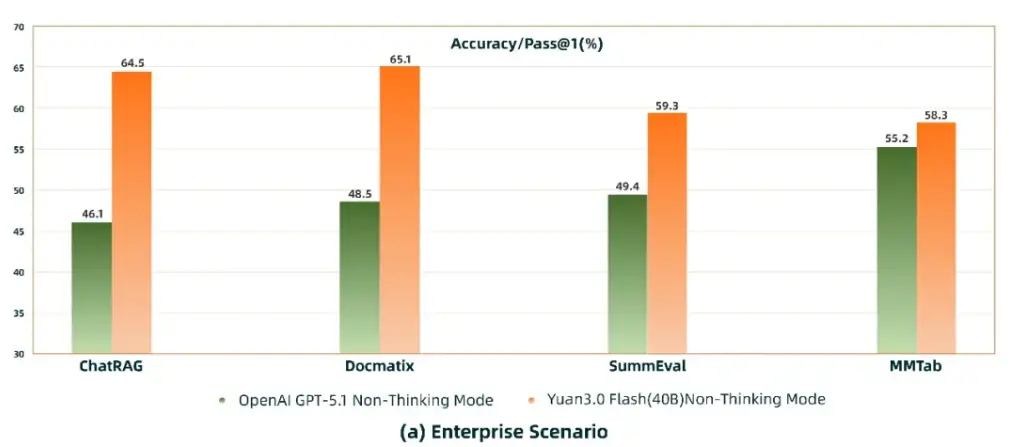
公告稱,在企業場景的 RAG(ChatRAG)、多模態檢索(Docmatix)、多模態表格理解(MMTab)、摘要生成(SummEval)等任務中,Yuan3.0 Flash 的表現已優於 GPT-5.1,體現出其在企業應用場景中的明顯能力優勢。
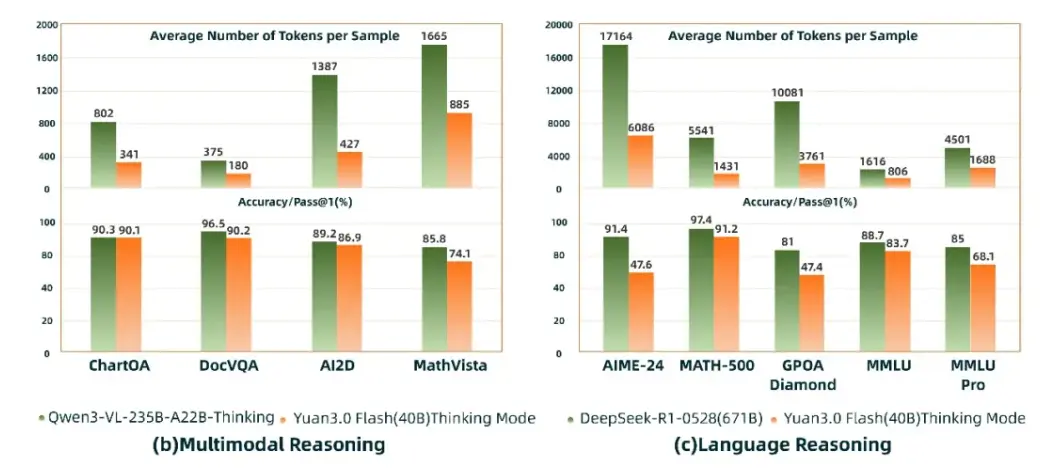
在多模態推理與語言推理評測中,Yuan3.0 Flash(40B)精度接近Qwen3-VL235B-A22B(235B)與DeepSeek-R1-0528(671B),但 token 消耗僅約為其 1/4 ~ 1/2,顯著降低了企業大模型應用成本。
源Yuan 3.0基礎大模型將包含Flash、Pro和Ultra等版本,模型參數量為40B、200B和1T等。
