智元機器人宣佈發佈 Act2Goal 方案 —— 這不僅僅是一個新的操作算法,更是一種讓機器人“以終為始”的全新思維方式。
根據介紹,不同於傳統機器人機械地執行死板指令,Act2Goal引入了“目標條件世界模型”。這意味着,機器人不再只是“看一步走一步”,而是擁有了預見未來的能力——在真正動手之前,它已經在大腦中構建了從現狀通往目標的完整因果鏈條。這種將視覺推理與動作控制合二為一的端到端架構,讓Act2Goal能夠在從未見過的環境和物體面前,展現出驚人的零樣本泛化能力。
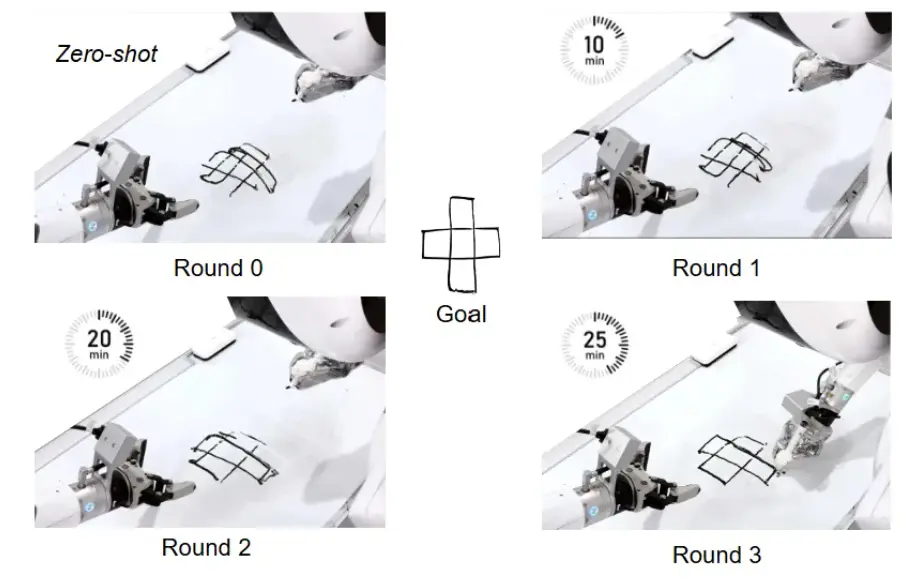
且Act2Goal具備“自我進化”的本能。 它不需要人類手把手教(無獎勵信號),就能在真實世界的交互中,快速“覆盤”自己的行為軌跡。實驗數據顯示,面對高難度的陌生任務,Act2Goal僅需數分鐘的在線自我磨練,成功率就能從30%提升至90%。
“所見即所向,讓機器人的每一次行動,都精準地通往目標。”
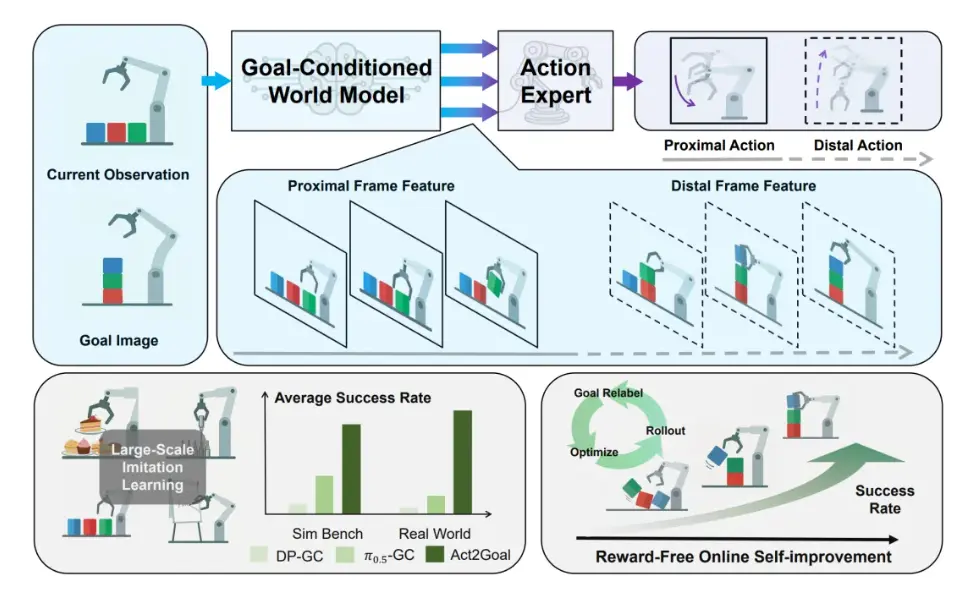
Act2Goal的核心在於將目標條件世界模型與動作生成策略統一於端到端框架,實現對任務演化過程的結構化理解。在每次操作前,系統不僅感知當前狀態和目標狀態,還通過世界模型預測從當前到目標的未來視覺軌跡,為動作專家提供連續、多尺度的規劃依據。通過這種方式,目標不再是靜態終點,而是一條可感知、可跟隨的演化路徑,從而顯著提升長時序操作的穩定性與泛化能力。這一範式帶來了兩個關鍵優勢:
- 長時序任務中保持高精度與全局對齊:端到端設計結合多尺度時間規劃,使機器人既能精確執行短期動作,又能保持整體目標方向一致。
- 零樣本泛化與快速適應新場景:系統能夠在未見過的物體、目標配置或複雜環境中穩定執行,並通過在線自我提升機制快速適應新任務,進一步增強魯棒性和可擴展性。
為了在長時序任務中同時處理精細動作和全局規劃,Act2Goal引入了多尺度時域哈希(Multi-Scale Temporal Hashing, MSTH)機制。系統將規劃過程劃分為:
- 短時精細段(Proximal):連續高頻採樣,用於精確控制機械臂動作;
- 長時粗粒段(Distal):自適應採樣,用於全局路徑規劃和目標對齊。
這種設計使機器人在複雜操作中能夠兼顧局部動作精度與整體目標方向,有效防止誤差累積和目標偏離。
MSTH可同時應用於世界模型的視覺規劃與動作專家模塊的動作規劃。
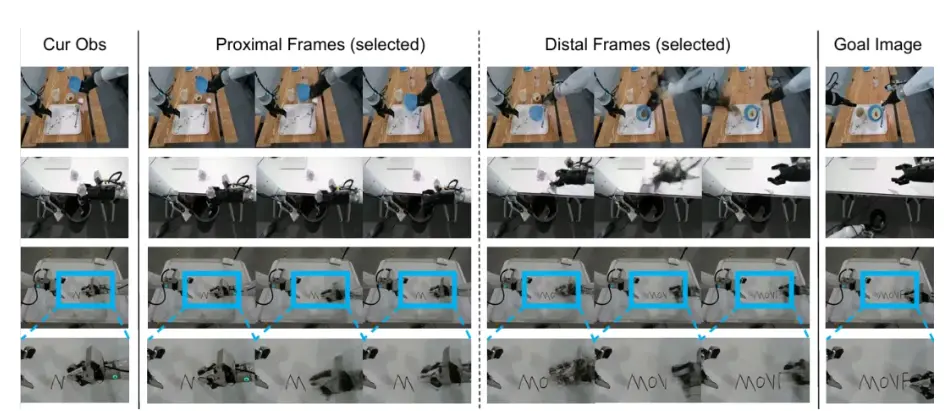
為了讓Act2Goal具備強大的泛化能力,系統首先通過大規模離線模仿學習進行訓練。系統微調預訓練的世界模型,使其能夠生成從當前狀態到目標狀態的多視角、多尺度視覺軌跡,並遵循MSTH規則。動作生成模塊與世界模型聯合訓練,通過參考軌跡預測生成可執行動作。
這種聯合訓練保證了視覺軌跡預測不僅真實可信,而且能夠有效指導動作生成,為動作規劃奠定基礎。系統對整個端到端模型進行行為克隆微調,使從視覺感知到動作生成形成完整閉環。通過以上訓練,Act2Goal學會根據當前狀態和目標狀態預測未來軌跡,並生成可執行動作,從而具備良好的泛化能力和長期操作穩定性。

儘管離線訓練使系統具備較強的泛化能力,但在真實環境中面對新任務、未知物體或複雜操作鏈時,機器人仍可能遇到性能下降。為此,Act2Goal引入在線自我提升機制,利用回顧性經驗重放(HER)實現自主性能優化。
在執行過程中,機器人會自動收集每一步的狀態、動作及執行結果,並將軌跡重新標註為新的目標示例,存入回放緩衝區。無論任務是否成功完成,系統都能利用這些數據進行端到端微調,僅更新新增的LoRA層參數,基礎模型保持凍結。通過這一機制,機器人能夠在未見過的環境和目標中快速適應,實現零樣本泛化與長期穩定操作,為複雜任務提供強大的魯棒性和可擴展性。
Act2Goal的核心貢獻在於重新審視了目標條件操作中的一個基本問題:從當前狀態到目標狀態之間,機器人是否真正理解過程?通過在策略中顯式引入目標條件世界模型,並結合多尺度時間建模與深度融合機制,項目團隊目標條件機器人操作提供了一種新的建模範式。“我們相信,這種“先理解世界如何變化,再決定如何行動”的思路,將為更通用、更可靠的機器人系統提供重要支撐。”
