智譜宣佈聯合華為開源新一代圖像生成模型GLM-Image,模型基於昇騰Atlas 800T A2設備和昇思MindSpore AI框架完成從數據到訓練的全流程,是首個在國產芯片上完成全程訓練的SOTA多模態模型。
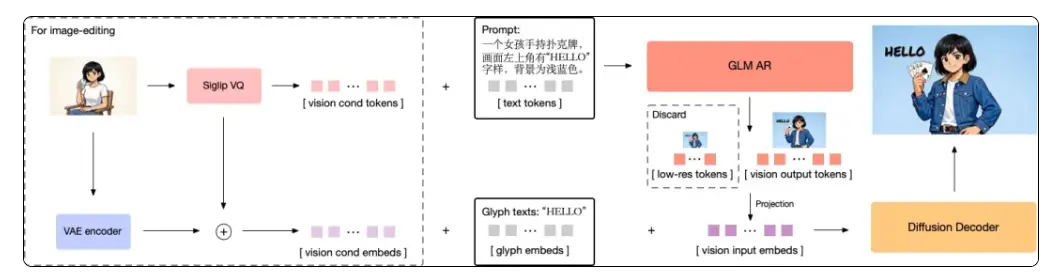
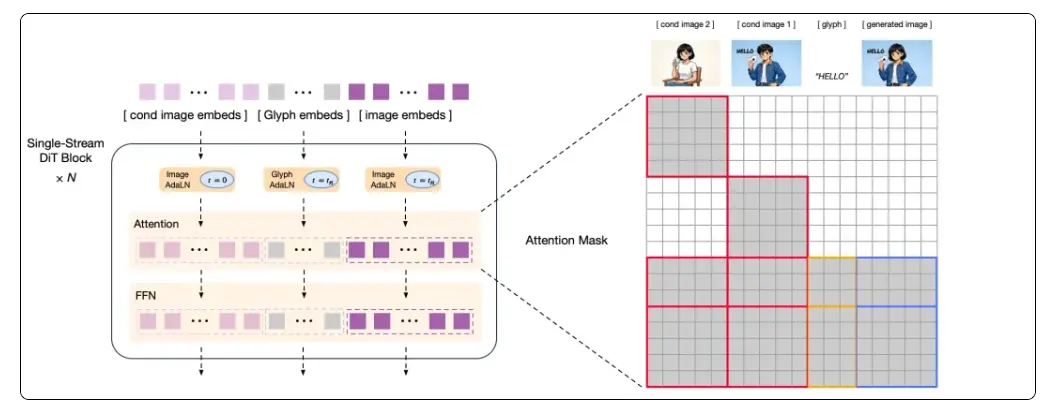
根據介紹,GLM-Image採用自主創新的「自迴歸+擴散解碼器」混合架構,實現了圖像生成與語言模型的聯合,是我們面向以Nano Banana Pro為代表的新一代「認知型生成」技術範式的一次重要探索。
核心亮點如下:
- 架構革新,面向「認知型生成」的技術探索:採用創新的「自迴歸 + 擴散編碼器」混合架構,兼顧全局指令理解與局部細節刻畫,克服了海報、PPT、科普圖等知識密集型場景生成難題,向探索以Nano Banana Pro為代表的新一代“知識+推理”的認知型生成模型邁出了重要一步。
- 首個在國產芯片完成全程訓練的SOTA模型:模型自迴歸結構基座基於昇騰Atlas 800T A2設備與昇思MindSpore AI框架,完成了從數據預處理到大規模訓練的全流程構建,驗證了在國產全棧算力底座上訓練前沿模型的可行性。
- 文字渲染開源SOTA:在CVTG-2K(複雜視覺文本生成)和LongText-Bench(長文本渲染)榜單獲得開源第一,尤其擅長漢字生成任務。
- 高性價比與速度優化:API調用模式下,生成一張圖片僅需0.1元,速度優化版本即將更新。
評測結果顯示,GLM-Image在文字渲染的權威榜單中達到開源SOTA水平。
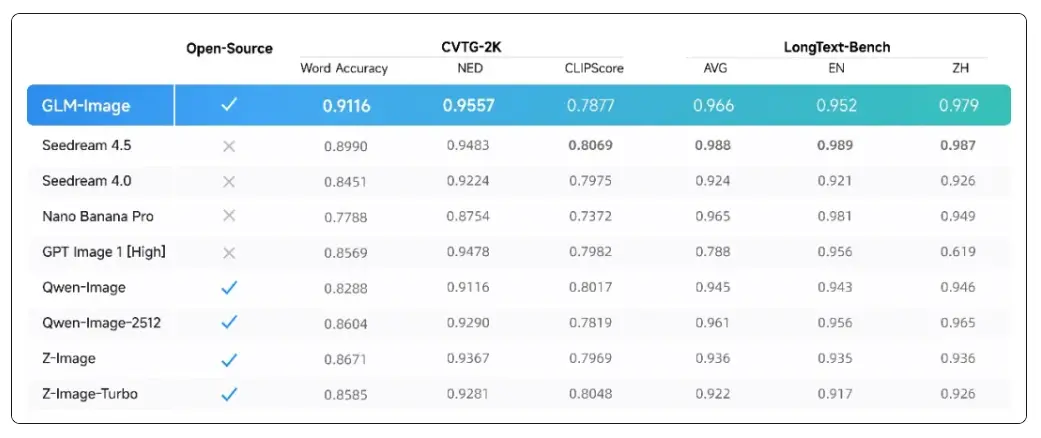
- CVTG-2K(複雜視覺文字生成)榜單核心考察模型在圖像中同時生成多處文字的準確性。在多區域文字生成準確率上,GLM-Image憑藉0.9116的Word Accuracy(文字準確率)成績,位列開源模型第一。在NED(歸一化編輯距離)指標上,GLM-Image同樣以0.9557領先,表明其生成的文字與目標文字高度一致,錯字、漏字情況更少。
- LongText-Bench(長文本渲染)榜單考察模型渲染長文本、多行文字的準確性,覆蓋招牌、海報、PPT、對話框等8種文字密集場景,並分設中英雙語測試,GLM-Image以英文0.952、中文0.979的成績位列開源模型第一。
