智元具身研究中心提出 SOP(Scalable Online Post-training)——一套面向真實世界部署的在線後訓練系統。這是業界首次在物理世界的 VLA 後訓練中,系統性地融合在線學習、分佈式架構與多任務通才性,使機器人集羣能夠在真實環境中持續進化,讓個體經驗在羣體中高效複用,從而將“規模”轉化為“智能”。
根據介紹,SOP 的核心目標,是讓機器人在真實世界中實現分佈式、持續的在線學習。項目團隊將 VLA 後訓練從“離線、單機、順序”重構為“在線、集羣、並行”,形成一個低延遲的閉環系統:多機器人並行執行 → 雲端集中在線更新 → 模型參數即時迴流
SOP 採用 Actor–Learner 異步架構:
- Actor(機器人側)並行經驗採集 多台部署了同一policy模型的機器人(actors)在不同地點同時執行多樣任務,持續採集成功、失敗以及人類接管產生的交互數據。每台機器人的經驗數據被彙總傳輸至雲端 Experience Buffer中。
- Learner(雲端)在線學習 所有交互軌跡實時上傳至雲端 learner,形成由在線數據與離線專家示教數據組成的數據池。系統通過動態重採樣策略,根據不同任務的性能表現,自適應調整在線/離線數據比例,以更高效地利用真實世界經驗。
- 即時參數同步 更新後的模型參數在分鐘級別內同步回所有機器人,實現集羣一致進化,維持在線訓練的穩定性。
SOP本身是一套通用的框架,可以即插即用的使用任意後訓練算法,讓VLA從在線經驗數據中獲益。項目團隊選取 HG-DAgger(交互式模仿學習) 與 RECAP(離線強化學習) 作為代表性算法,將其接入 SOP 框架以進化為分佈式在線訓練。
關鍵優勢
- 高效狀態空間探索 分佈式多機器人並行探索,顯著提升狀態–動作覆蓋率,避免單機在線學習的侷限。
- 緩解分佈偏移 所有機器人始終基於低延遲的最新策略進行推理採集,提升在線訓練的穩定性與一致性。
- 在提升性能的同時保留泛化能力 傳統的單機在線訓練往往會使模型退化為只擅長單一任務的“專家”, SOP 通過空間上的並行而非時間上的串行,在提升任務性能的同時保留 VLA 的通用能力,避免退化為單任務專家。
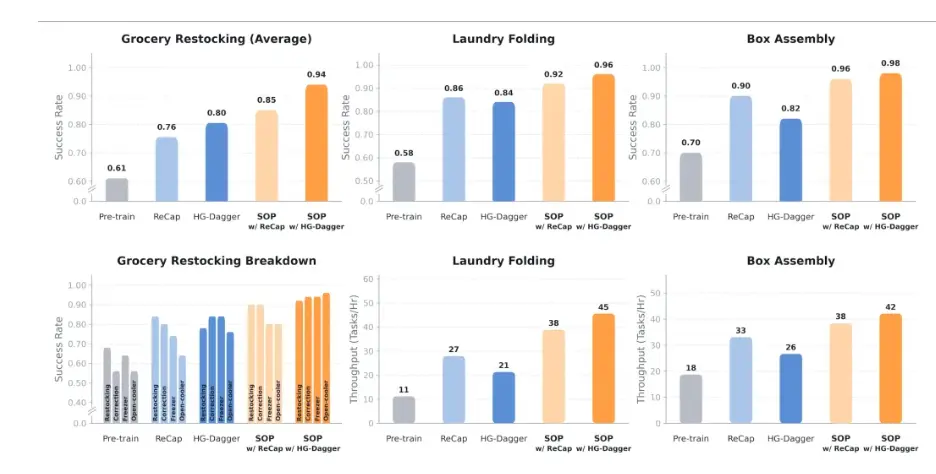
實驗結果表明,在各類測試場景下,結合SOP的後訓練方法均得到了顯著的性能提升。相比預訓練模型,結合SOP的HG-Dagger方法在物品繁雜的商超場景中實現了33% 的綜合性能提升。對於靈巧操作任務(疊衣服和紙盒裝配),SOP 的引入不僅提升了任務的成功率,結合在線經驗學習到的錯誤恢復能力還能明顯提升策略操作的吞吐量。
結合SOP的HG-Dagger方法讓疊衣服的相比HG-Dagger吞吐量躍升114%。SOP讓多任務通才的性能普遍提升至近乎完美,不同任務的成功率均提升至94%以上,紙盒裝配更是達到98%的成功率。
在相同的總訓練時間下,更多數量的機器人帶來了更高的性能表現。在總訓練時間為3小時的限制下,四機進行學習的最終成功率達到了92.5%,比單機高出12%。多機採集可以有效阻止模型過擬合到單機的特定特徵上。同時,SOP 還將硬件的擴展轉化為了學習時長的大幅縮短,四機器人集羣相比單機能夠將模型達到目標性能的訓練速度增至2.4倍。

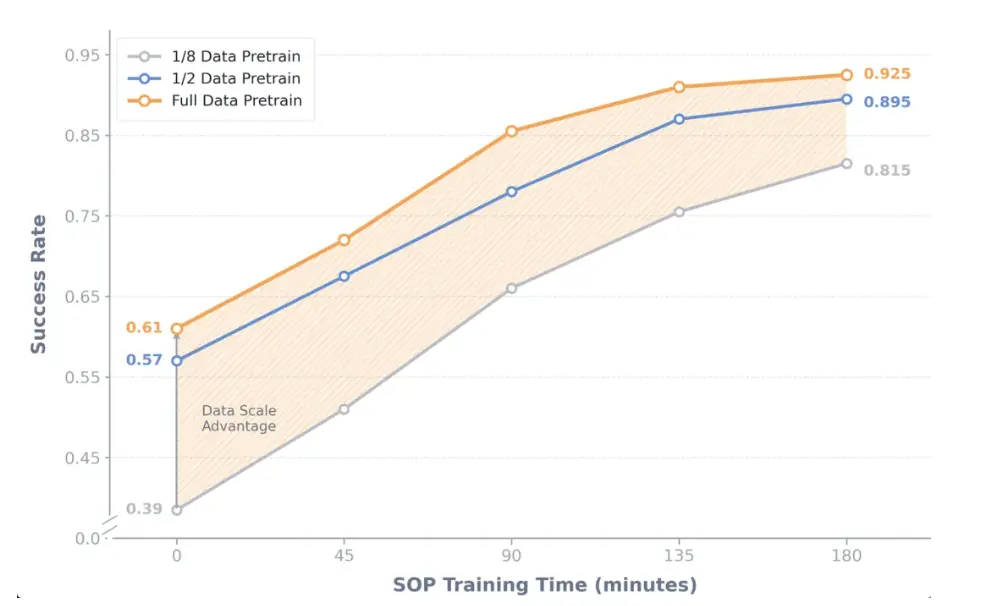
最後還探究了 SOP 和預訓練數據之間的關係。把總量為160小時的多任務預訓練數據分為了三組:20小時,80小時和160小時,分別訓練一組初始模型後再進行 SOP。發現,預訓練的規模決定了基座模型和後訓練提升的軌跡。SOP 能為所有初始模型帶來穩定的提升,且最終性能與VLA預訓練質量正相關。
同時,對比80小時和160小時實驗效果,也可以明顯注意到,在解決特定失敗情況時,在軌策略經驗帶來了非常顯著的邊際效果。SOP 在三小時的在軌經驗下就獲得了約30%的性能提升,而80小時額外人類專家數據只帶來了4%的提升。這説明在預訓練出現邊際效應遞減的情況下,SOP 能夠高效突破VLA性能瓶頸。