字節跳動發佈了其最新的多模態大語言模型 Vidi2,一個擁有120億參數、專用於視頻理解的AI模型。該模型能夠處理數小時長的原始素材,理解其中的故事脈絡,並根據簡單提示生成完整的TikTok短視頻或電影片段,被視為對現有視頻編輯行業的重大顛覆。
Vidi2的關鍵在於其視頻理解能力。新模型新增了精細的時空定位(STG)功能,能夠同時識別視頻中的時間戳和目標對象的邊界框。給定文本查詢,Vidi2不僅能找到對應的時間段,還能在這些時間範圍內準確標記出具體物體的位置。
在技術細節上:
-
時空定位:模型返回“管道”(時間索引邊界框),以一秒粒度跟蹤指定對象和人物,直接支持編輯,例如在人羣中跟蹤特定人物。
-
技術架構:Vidi2升級使用Gemma-3作為主幹網絡,並輔以重新設計的自適應標記壓縮技術,確保在處理長視頻時保持效率而不丟失關鍵細節。
在用於開放式時間檢索的 VUE-TR-V2基準上,Vidi2 總體 IoU 達到48.75,尤其在超長視頻(超過1小時)上的表現比商業模型領先17.5個百分點。在定位任務(VUE-STG)上,模型也取得了vIoU32.57和tIoU53.19的最佳性能。
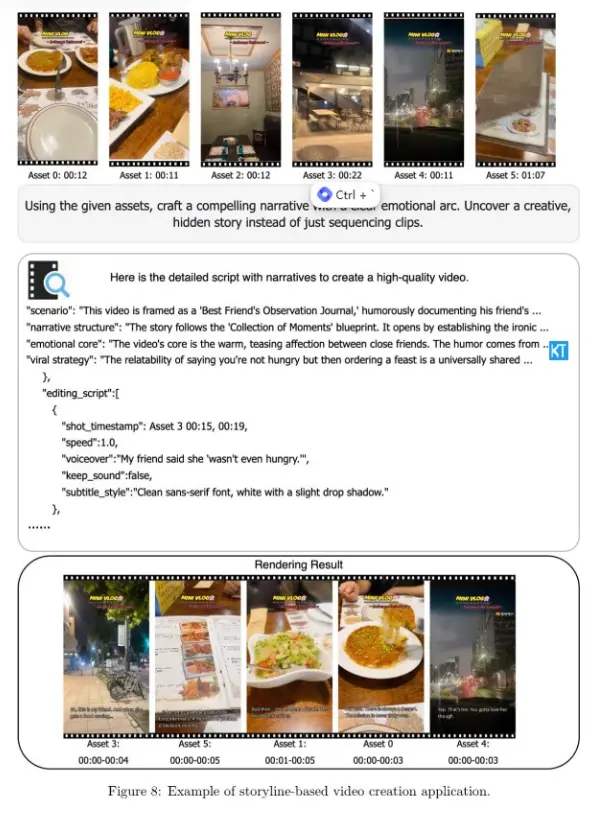
字節跳動基於 Vidi2 已開發出多個實用的自動化編輯工具,包括:高光提取、故事感知剪切、內容感知重構圖和多視角切換,且這些功能都可以在消費級硬件上運行。
-
TikTok應用:相關技術已應用於TikTok的Smart Split功能,能夠自動剪輯、重構圖、添加字幕,並將長視頻轉錄成適合TikTok的短片段。
-
AI Outline:該工具能將簡單提示或熱門話題轉化為結構化的視頻標題、開頭和大綱。
目前 Vidi2仍處於研究階段,官方表示 Demo 即將發佈。
