作者:來自 Elastic Scott Martens
探索 Jina多模態嵌入、 Reranker v3 以及語義嵌入模型,並瞭解如何在Elasticsearch中通過 Elastic Inference Service ( EIS ) 原生使用它們。
Elasticsearch 原生集成了行業領先的 Gen AI 工具和提供商。查看我們的網絡研討會,瞭解如何超越 RAG 基礎,或使用Elastic Vector Database構建可用於生產的應用。
為了打造最適合你用例的搜索解決方案,可以開始免費雲試用,或者現在就在本地機器上試用Elastic。
Elastic Jina 為應用和業務流程自動化提供搜索基礎模型。這些模型為將 AI 引入 Elasticsearch 應用和創新 AI 項目提供核心功能。
Jina 模型分為三大類,用於支持信息處理、組織和檢索:
- 語義嵌入模型
- 重排序模型
- 小型生成式語言模型
語義嵌入模型
語義嵌入背後的思想是, AI 模型可以學會用高維空間的幾何關係來表示其輸入含義的各個方面。
你可以將一個語義嵌入看作是高維空間中的一個點(技術上稱為向量)。嵌入模型是一種神經網絡,它接收一些數字數據作為輸入(理論上可以是任何數據,但最常見的是文本或圖像),並以一組數值座標的形式輸出對應的高維點位置。如果模型表現良好,兩個語義嵌入之間的距離就與它們各自對應的數字對象在語義上有多相似成正比。
為了理解這對搜索應用為何重要,可以想象單詞 “ dog ” 和單詞 “ cat ” 各自對應為空間中的兩個點:
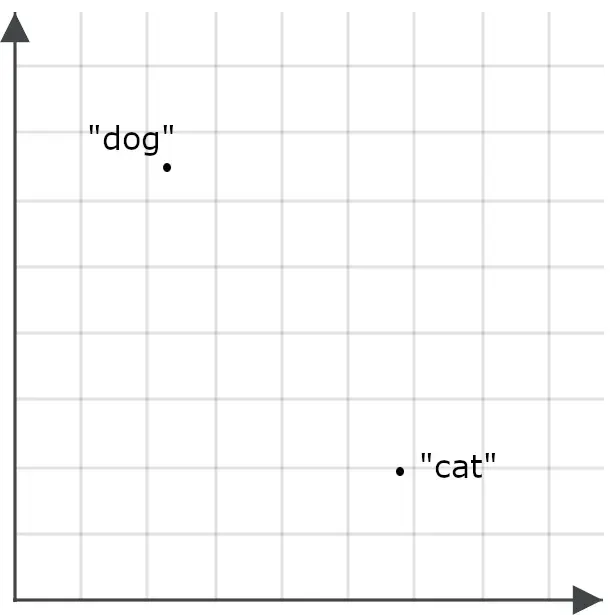
一個好的嵌入模型應該為單詞 “ feline ” 生成一個比 “ cat ” 更接近、而不是 “ dog ” 的嵌入,而 “ canine ” 的嵌入也應該比 “ cat ” 更接近 “ dog ”,因為這些詞的含義幾乎相同:如果模型是多語言的,我們也會期望 “ cat ” 和 “ dog ” 的翻譯具有同樣的效果:

如果模型是多語言的,我們對“cat”和“dog”的翻譯也期望有同樣的反應:

嵌入模型將事物在含義上的相似或不相似,轉化為嵌入之間的空間關係。上面的圖片只有兩個維度,便於在屏幕上展示,但嵌入模型生成的是具有幾十到幾千個維度的向量。這使它們能夠為整段文本編碼細微的語義差別,為包含數千字甚至更多內容的文檔,在一個具有數百或數千個維度的空間中分配一個點。
多模態嵌入
多模態模型將語義嵌入的概念擴展到文本之外,尤其是圖像。我們會期望一張圖片的嵌入與對該圖片的準確描述的嵌入彼此接近:
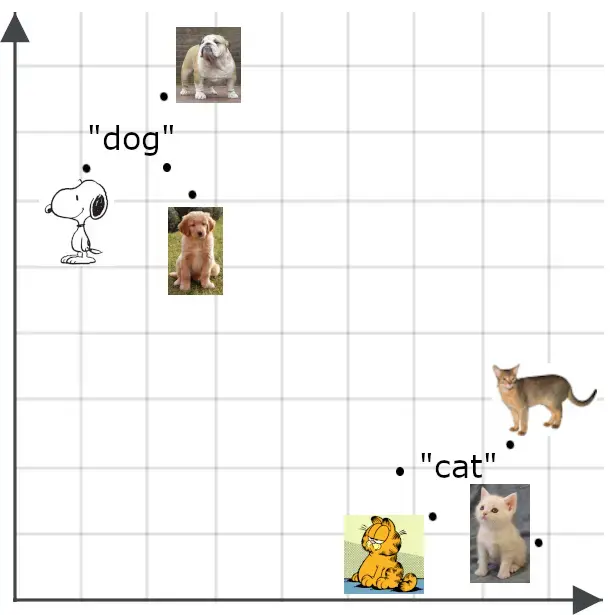
語義嵌入有很多用途。其中,你可以用它們來構建高效的分類器、進行數據聚類,以及完成多種任務,比如數據去重和數據多樣性分析,這兩者對於需要處理大量、無法手動管理數據的大數據應用都非常重要。
嵌入最直接、最重要的用途是在信息檢索中。 Elasticsearch 可以存儲以嵌入作為鍵的檢索對象。查詢會被轉換為嵌入向量,搜索會返回其鍵與查詢嵌入距離最近的已存儲對象。
傳統的基於向量的檢索(有時稱為稀疏向量檢索)使用基於文檔和查詢中的詞或元數據的向量,而基於嵌入的檢索(也稱為稠密向量檢索)使用的是 AI 評估的語義而不是單詞。這使它們通常比傳統搜索方法更靈活,也更準確。
Matryoshka(套娃) 表示學習
嵌入的維度數量以及其中數值的精度會對性能產生顯著影響。非常高維的空間和極高精度的數值可以表示高度細緻和複雜的信息,但需要更大、訓練和運行成本更高的 AI 模型。它們生成的向量需要更多存儲空間,計算向量之間距離也需要更多計算資源。使用語義嵌入模型需要在精度和資源消耗之間做出重要權衡。
為了最大化用户的靈活性, Jina 模型採用了一種稱為Matryoshka Representation Learning的訓練技術。這種技術會將最重要的語義區分優先編碼到嵌入向量的前幾個維度中,因此即使截斷高維部分,也能保持良好的性能。
在實際使用中,這意味着 Jina 模型的用户可以自行選擇嵌入的維度數量。選擇更少的維度會降低精度,但性能下降幅度很小。在大多數任務中,每當將嵌入大小減少 50% 時, Jina 模型的性能指標只會下降約 1–2%,直到大小減少約 95% 為止。
非對稱檢索
語義相似度通常是對稱測量的。比較 “ cat ” 和 “ dog ” 得到的值,與比較 “ dog ” 和 “ cat ” 得到的值是相同的。但在使用嵌入進行信息檢索時,如果打破對稱性,將查詢的編碼方式與檢索對象的編碼方式區分開,會效果更好。
這是因為嵌入模型的訓練方式。訓練數據包含相同元素(如單詞)在許多不同上下文中的實例,模型通過比較元素在上下文中的相似性和差異來學習語義。
例如,我們可能發現單詞 “ animal ” 與 “ cat ” 或 “ dog ” 出現的上下文重疊不多,因此 “ animal ” 的嵌入可能不會特別接近 “ cat ” 或 “ dog ”:
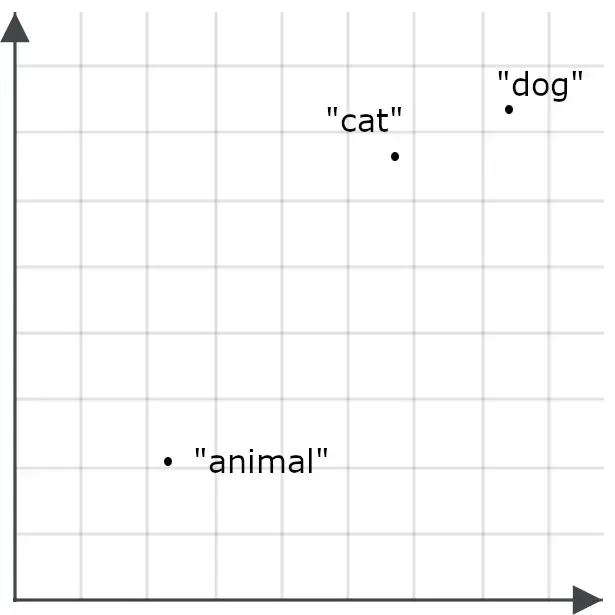
這會使得以 “ animal ” 為查詢的檢索不太可能返回關於 cat 和 dog 的文檔——這與我們的目標相反。因此,當 “ animal ” 作為查詢時,我們會採用不同的編碼方式,而不是作為檢索目標時的編碼方式:
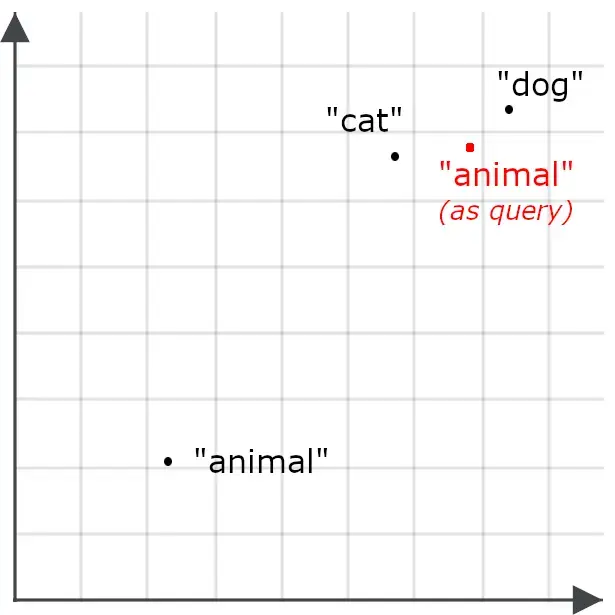
非對稱檢索意味着對查詢使用不同的模型,或者專門訓練一個嵌入模型,使其在存儲用於檢索時採用一種編碼方式,而在處理查詢時採用另一種編碼方式。
多向量嵌入
單一嵌入適用於信息檢索,因為它們符合索引數據庫的基本框架:我們使用單個嵌入向量作為檢索鍵存儲可檢索對象。當用户查詢文檔存儲時,查詢會被轉換為嵌入向量,文檔中鍵與查詢嵌入在高維嵌入空間中最接近的文檔會被檢索出來作為候選匹配。
多向量嵌入的工作方式略有不同。它們不生成固定長度的向量來表示整個查詢或存儲對象,而是為其較小的部分生成一系列嵌入。這些部分通常是文本的 token 或單詞,視覺數據則是圖像塊。這些嵌入反映了該部分在其上下文中的含義。
例如,考慮以下句子:
- She had a heart of gold.
- She had a change of heart.
- She had a heart attack.
表面上看,它們非常相似,但多向量模型很可能為每個 “ heart ” 的實例生成不同的嵌入,表示它在整個句子上下文中的不同含義:
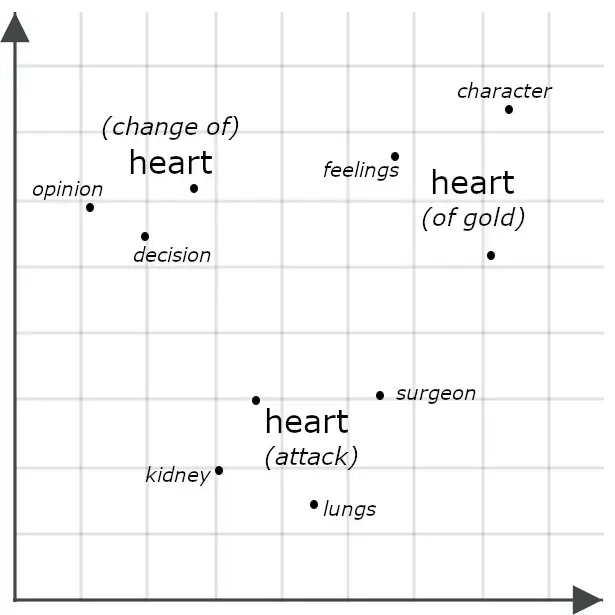
通過多向量嵌入比較兩個對象通常涉及測量它們的 Chamfer 距離:將一個多向量嵌入的每個部分與另一個的每個部分進行比較,並將它們之間的最小距離求和。其他系統,包括下面描述的 Jina Rerankers,會將它們輸入一個專門訓練用於評估相似性的 AI 模型。這兩種方法通常比僅比較單向量嵌入的精度更高,因為多向量嵌入包含比單向量嵌入更多的詳細信息。
然而,多向量嵌入不太適合索引。它們通常用於重排序任務,如下一節中 jina-colbert-v2 模型所描述的。
Jina 嵌入模型
Jina embeddings v4
jina-embeddings-v4 是一個擁有 38 億(3.8x10⁹)參數的多語言、多模態嵌入模型,支持多種常用語言的文本和圖像。它使用了一種新型架構,利用視覺知識和語言知識提升兩類任務的性能,使其在圖像檢索,尤其是視覺文檔檢索方面表現出色。這意味着它可以處理圖表、幻燈片、地圖、截圖、頁面掃描和圖解等圖像 —— 這些常見圖像通常包含重要的嵌入文本,而傳統計算機視覺模型訓練於現實場景圖片時無法覆蓋。
我們通過緊湊的低秩適配器(Low-Rank Adaptation, LoRA)對該模型進行了多任務優化。這使得我們可以訓練一個單一模型在多個任務上進行專精,而不會影響任何任務的性能,並且對內存或計算的額外開銷最小。
主要特點包括:
- 在視覺文檔檢索上表現出最先進的性能,同時在多語言文本和常規圖像處理上也超過了更大型的模型。
- 支持大輸入上下文:32,768 個 token 大約相當於 80 頁雙倍行距的英文文本,20 兆像素相當於 4,500 x 4,500 像素的圖像。
- 用户可選擇嵌入維度,從最大 2048 維到最小 128 維。實證發現,低於該閾值性能會顯著下降。
- 支持單向量嵌入和多向量嵌入。文本的多向量輸出為每個輸入 token 生成一個 128 維嵌入;圖像的多向量輸出為覆蓋圖像所需的每個 28x28 像素塊生成一個 128 維嵌入。
- 通過專門訓練的一對 LoRA 適配器優化非對稱檢索。
- 優化語義相似度計算的 LoRA 適配器。
- 專門支持編程語言和 IT 框架,也通過 LoRA 適配器實現。
我們開發 jina-embeddings-v4 作為一個通用、多用途工具,用於廣泛的常見搜索、自然語言理解和 AI 分析任務。考慮到其能力,它是一個相對較小的模型,但部署仍需顯著資源,最適合通過雲 API 或在高負載環境中使用。
Jina embeddings v3
jina-embeddings-v3 是一個緊湊、高性能、多語言、僅文本的嵌入模型,參數少於 6 億。它支持最多 8192 個 token 的文本輸入,並輸出單向量嵌入,嵌入維度可由用户選擇,從默認的 1024 維到最小 64 維。
我們為多種文本任務訓練了 jina-embeddings-v3 —— 不僅包括信息檢索和語義相似性,還包括分類任務,如情感分析和內容審核,以及聚類任務,如新聞聚合和推薦。與 jina-embeddings-v4 類似,該模型提供 LoRA 適配器,專門用於以下使用場景:
- 非對稱檢索
- 語義相似度
- 分類
- 聚類
jina-embeddings-v3 的模型遠小於 jina-embeddings-v4,輸入上下文也大幅縮小,但運行成本更低。儘管如此,它在文本處理上性能仍非常有競爭力,是許多用例的更佳選擇。
Jina 代碼嵌入
Jina 的專用代碼嵌入模型 —— jina-code-embeddings(0.5b 和 1.5b)——支持 15 種編程語言和框架,以及與計算機和信息技術相關的 English 文本。它們是緊湊模型,參數分別為 5 億(0.5x10⁹)和 15 億(1.5x10⁹)。兩個模型都支持最多 32,768 個 token 的輸入上下文,並允許用户選擇輸出嵌入維度:小模型為 896 到 64 維,大模型為 1536 到 128 維。
這些模型支持針對五種任務特定的非對稱檢索,使用前綴微調而非 LoRA 適配器:
- 代碼到代碼(Code to code):跨編程語言檢索相似代碼,用於代碼對齊、代碼去重,以及支持移植和重構。
- 自然語言到代碼(Natural language to code):根據自然語言查詢、註釋、描述和文檔檢索匹配代碼。
- 代碼到自然語言(Code to natural language):將代碼匹配到文檔或其他自然語言文本。
- 代碼補全(Code-to-code completion):建議相關代碼以完成或增強現有代碼。
- 技術問答(Technical Q&A):識別與信息技術相關問題的自然語言答案,非常適合技術支持場景。
這些模型在處理計算機文檔和編程材料任務時提供出色性能,同時計算成本相對較低,非常適合集成到開發環境和代碼助手中。
Jina ColBERT v2
jina-colbert-v2 是一個擁有 5.6 億參數的多向量文本嵌入模型。它是多語言模型,使用 89 種語言的材料進行訓練,並支持可變嵌入維度和非對稱檢索。
如前所述,多向量嵌入不適合索引,但非常適合提高其他搜索策略結果的精度。使用 jina-colbert-v2,你可以提前計算多向量嵌入,然後在查詢時用它們對檢索候選進行重排序。這種方法的精度低於下一節中的重排序模型,但效率更高,因為它只涉及比較已存儲的多向量嵌入,而不必為每個查詢和候選匹配調用整個 AI 模型。它非常適合在使用重排序模型的延遲和計算開銷過大,或者需要比較的候選數量太多而不適合重排序模型的場景中使用。
該模型輸出一系列嵌入,每個輸入 token 對應一個嵌入,用户可以選擇 128、96 或 64 維的 token 嵌入。候選文本匹配限制為 8,192 個 token。查詢採用非對稱編碼,因此用户必須指定文本是查詢還是候選匹配,並且查詢 token 數量必須限制在 32 個以內。
Jina CLIP v2
jina-clip-v2 是一個擁有 9 億參數的多模態嵌入模型,訓練目標是讓文本和圖像在嵌入空間中彼此接近,如果文本描述了圖像的內容。它的主要用途是基於文本查詢檢索圖像,但它也是一個高性能的純文本模型,從而降低用户成本,因為無需為文本到文本和文本到圖像的檢索使用不同模型。
該模型支持 8,192 token 的文本輸入上下文,圖像在生成嵌入前會縮放至 512x512 像素。
對比語言–圖像預訓練(CLIP)架構易於訓練和操作,並能生成非常緊湊的模型,但存在一些根本性限制。它們無法利用一種媒介的知識來提升在另一種媒介上的性能。換句話説,雖然模型可能知道單詞 “ dog ” 和 “ cat ” 的語義比任何一個與 “ car ” 更接近,但它不一定知道狗的圖片和貓的圖片比它們各自與汽車圖片更相關。
它們還存在所謂的模態差距(modality gap):關於狗的文本嵌入可能比狗的圖片嵌入更接近關於貓的文本嵌入。基於這一限制,我們建議將 CLIP 用作文本到圖像的檢索模型,或純文本模型,而不要在單次查詢中混合使用兩者。
重排序模型
重排序模型會將一個或多個候選匹配項與查詢一起作為模型輸入,並直接進行比較,從而生成精度更高的匹配結果。
原則上,你可以直接使用重排序器進行信息檢索,通過將每個查詢與每個存儲文檔進行比較,但這計算成本非常高,除了最小的數據集外幾乎不可行。因此,重排序器通常用於評估通過其他方法找到的相對較短的候選匹配列表,比如基於嵌入的搜索或其他檢索算法。重排序模型非常適合用於混合和聯合搜索方案,其中搜索可能意味着查詢會發送到不同數據集的獨立搜索系統,每個系統返回不同結果。它們在將多樣化結果合併為單個高質量結果方面表現出色。Jina 重排序模型
Jina Reranker m0
jina-reranker-m0 是一個擁有 24 億(2.4x10⁹)參數的多模態重排序模型,支持文本查詢和由文本和/或圖像組成的候選匹配。它是視覺文檔檢索的領先模型,非常適合用於存儲 PDF、文本掃描、截圖以及其他包含文本或半結構化信息的計算機生成或修改的圖像,也適用於由文本文檔和圖像混合組成的數據。
該模型接受單個查詢和一個候選匹配,並返回一個分數。當相同查詢用於不同候選時,分數可比較並用於排序。它支持總輸入大小最多 10,240 個 token,包括查詢文本和候選文本或圖像。覆蓋圖像所需的每個 28x28 像素塊都算作一個 token,用於計算輸入大小。
Jina Reranker v3
jina-reranker-v3 是一個擁有 6 億參數的文本重排序模型,在同等規模模型中性能處於最先進水平。與 jina-reranker-m0 不同,它接受單個查詢和最多 64 個候選匹配的列表,並返回排序順序。它的輸入上下文為 131,000 個 token,包括查詢和所有文本候選。
Jina Reranker v2
jina-reranker-v2-base-multilingual 是一個非常緊湊的通用重排序模型,具有額外功能以支持函數調用和 SQL 查詢。參數少於 3 億,提供快速、高效且準確的多語言文本重排序,並額外支持選擇與文本查詢匹配的 SQL 表和外部函數,非常適合 agentic 場景使用。
小型生成語言模型
生成語言模型是指像 OpenAI 的 ChatGPT、Google Gemini 以及 Anthropic 的 Claude 這樣的模型,它們接受文本或多媒體輸入,並輸出文本。大語言模型(arge language models - LLMs)與小語言模型(small language models - SLMs)之間沒有明確界限,但開發、運行和使用頂級 LLM 的實際問題是眾所周知的。最知名的 LLM 並未公開分發,因此只能估計其規模,但 ChatGPT、Gemini 和 Claude 預計在 1–3 萬億(1–3x10¹²)參數範圍內。
運行這些模型,即便公開可用,也遠超傳統硬件能力,需使用最先進的芯片並組成龐大的並行陣列。你可以通過付費 API 訪問 LLM,但這會產生高額成本、較大延遲,並難以滿足數據保護、數字主權和雲遷移的要求。此外,訓練和定製此類模型的成本也非常可觀。
因此,研究人員投入大量精力開發更小的模型,這些模型可能不具備最大 LLMs 的全部能力,但能以較低成本完成特定任務。企業通常部署軟件來解決特定問題,AI 軟件也不例外,因此基於 SLM 的解決方案通常比 LLM 更可取。它們通常可以在普通硬件上運行,速度更快、能耗更低,並且更容易定製。
隨着我們關注如何將 AI 最有效地引入實際搜索解決方案,Jina 的 SLM 產品也在不斷增長。
Jina SLMs
ReaderLM v2
ReaderLM-v2 是一個生成語言模型,可根據用户提供的 JSON schema 和自然語言指令,將 HTML 轉換為 Markdown 或 JSON。
數據預處理和規範化是開發優秀數字數據搜索解決方案的重要環節,但現實世界的數據,尤其是來自網頁的信息,通常非常混亂,簡單的轉換策略常常非常脆弱。ReaderLM-v2 提供了智能 AI 模型解決方案,能夠理解網頁 DOM 樹的混亂結構,並穩健地識別有用元素。
該模型擁有 15 億(1.5x10⁹)參數,比最先進的 LLM 小三個數量級,但在這個單一任務上的表現與它們相當。
Jina VLM
jina-vlm 是一個擁有 24 億(2.4x10⁹)參數的生成語言模型,訓練目標是回答關於圖像的自然語言問題。它在視覺文檔分析方面表現非常強大,即回答關於掃描件、截圖、幻燈片、圖解以及類似的非自然圖像數據的問題。
例如:

它在識別圖像中的文本方面也非常出色:

但 jina-vlm 真正擅長的是理解信息性和人工生成圖像的內容:
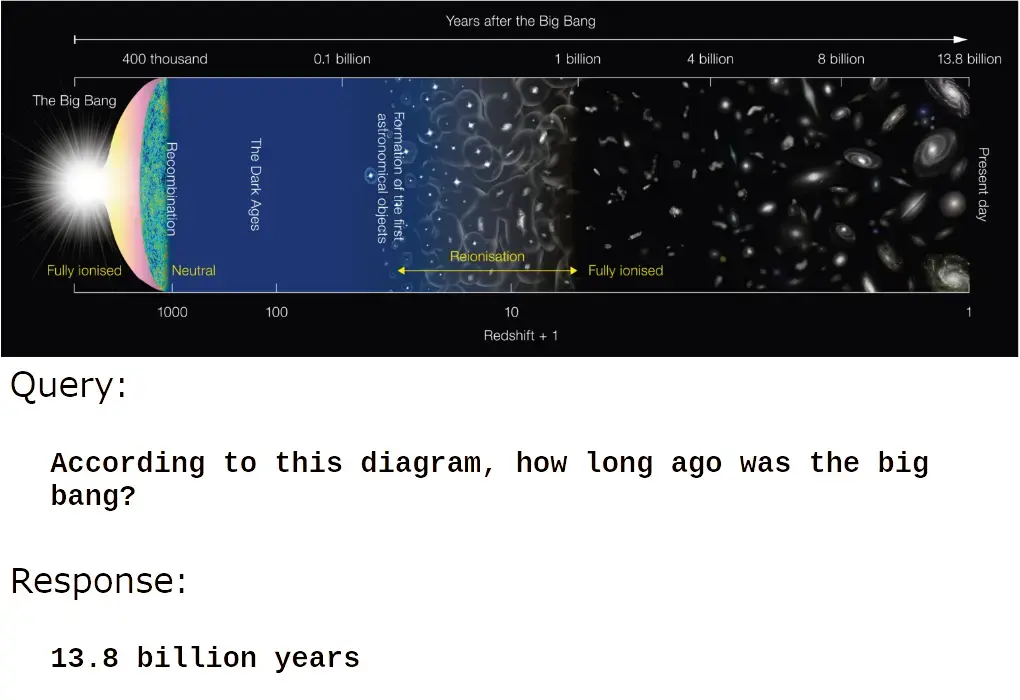
或者:

jina-vlm 非常適合自動生成圖像説明、產品描述、圖片替代文本,以及為視障人士提供的可訪問性應用。它還為檢索增強生成(RAG)系統使用視覺信息,以及讓 AI agent 無需人工即可處理圖像創造了可能性。
原文:Jina models: embeddings, rerankers, and small generative language models - Elasticsearch Labs
