阿布扎技術創新研究院(Technology Innovation Institute,TII)發佈了全新推理優化的開源大型語言模型 Falcon H1R 7B。它基於 Falcon-H1 系列,在保持緊湊 7B 參數規模的前提下,提供了行業領先的推理表現,大幅挑戰傳統“大模型越大越強”的理念。

核心設計與訓練方法
雙階段訓練流程
-
冷啓動監督微調(SFT):在 Falcon-H1-7B 基礎模型上進行,專注長鏈推理、數學、編程和科學等領域訓練。
-
強化學習增強(GRPO):在 SFT 基礎上進一步優化,通過獎勵正確推理鏈條來提升邏輯性和多樣性輸出。
三維性能優化指標
模型圍繞速度、Token 效率、準確率 三大維度優化,並集成了名為 Deep Think with Confidence(DeepConf) 的置信度驅動測試時推理方法,在生成更少 Token 的同時提升整體準確性。
混合架構優勢
採用 Transformer + Mamba(狀態空間模型)混合結構,兼具深入關注能力與高效序列處理,提升長上下文處理能力與推理吞吐率。
領先 benchmark 成績
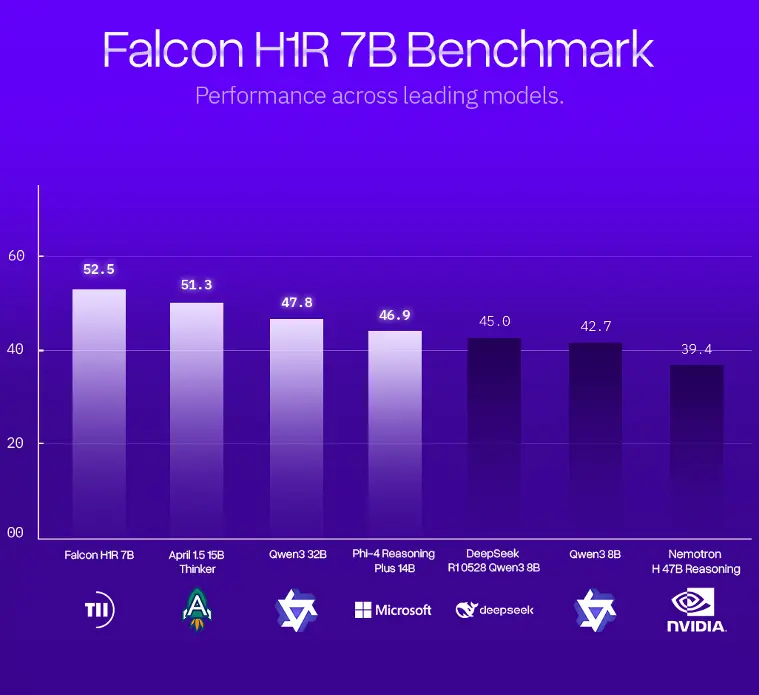
Falcon H1R 7B 在多個公開評測中表現優異:
| 任務類別 | 表現亮點 |
|---|---|
| 數學推理 | AIME-24 達 88.1%,領先 15B 級模型 |
| 代碼與代理任務 | LCB v6 得分 68.6%,在 <8B 模型中最高 |
| 通用推理能力 | 在 MMLU-Pro 和 GPQA 等測試中競爭力接近甚至優於更大規模模型 |
推理性能與效率提升
- 推理吞吐量領先:在常見 batch 大小下,每 GPU 令牌處理速度高達 ~1500 tokens/s,幾乎是部分對手的兩倍。
- 高效推理成本:憑藉架構與訓練優化,在較低算力環境下仍能實現深度推理任務,適合開發者和企業部署。
Falcon H1R 7B 在 Hugging Face 上提供完整檢查點和量化(GGUF)版本,並採用 Falcon-LLM 開源許可發佈,便於研究、產品開發和實驗用途。詳情查看:https://huggingface.co/collections/tiiuae/falcon-h1r
