Z Lab 發佈了開源推測解碼框架 DFlash,這是一種利用輕量級 Block Diffusion 模型進行草稿生成的推測解碼方法。該方法旨在解決自迴歸大語言模型在推測解碼中因串行草稿生成導致的效率瓶頸。
DFlash 通過融合目標模型的隱藏特徵作為上下文條件,實現了高效且高質量的並行草稿預測。
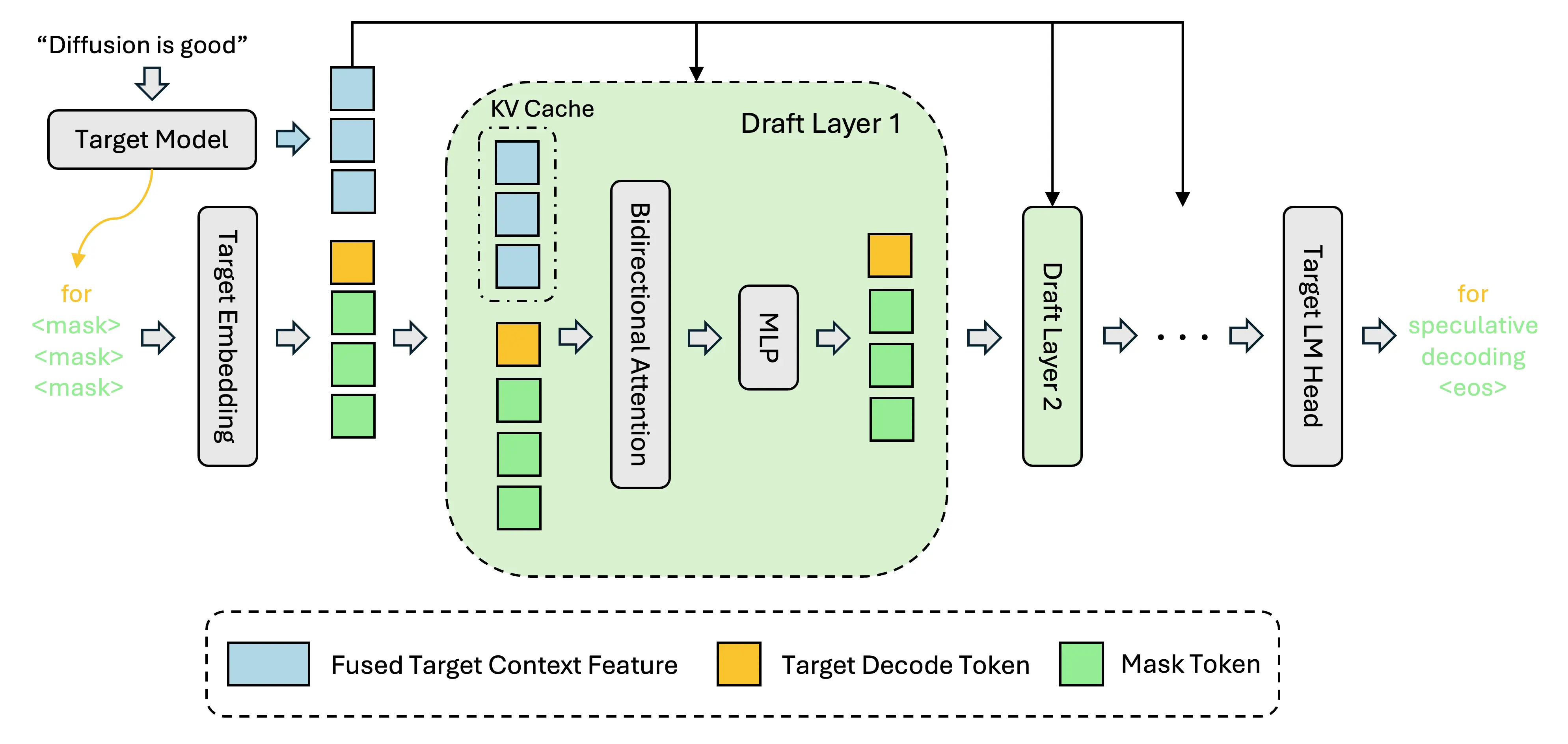
https://github.com/z-lab/dflash
官方數據顯示,DFlash 在 Qwen3-8B 上實現了高達 6.17倍 的無損加速,其解碼速度比目前最先進的推測解碼方法 EAGLE-3 快近 2.5倍。目前,該項目已開源併發布了適配 Qwen3-4B 和 Qwen3-8B 的模型,相關論文即將發佈。
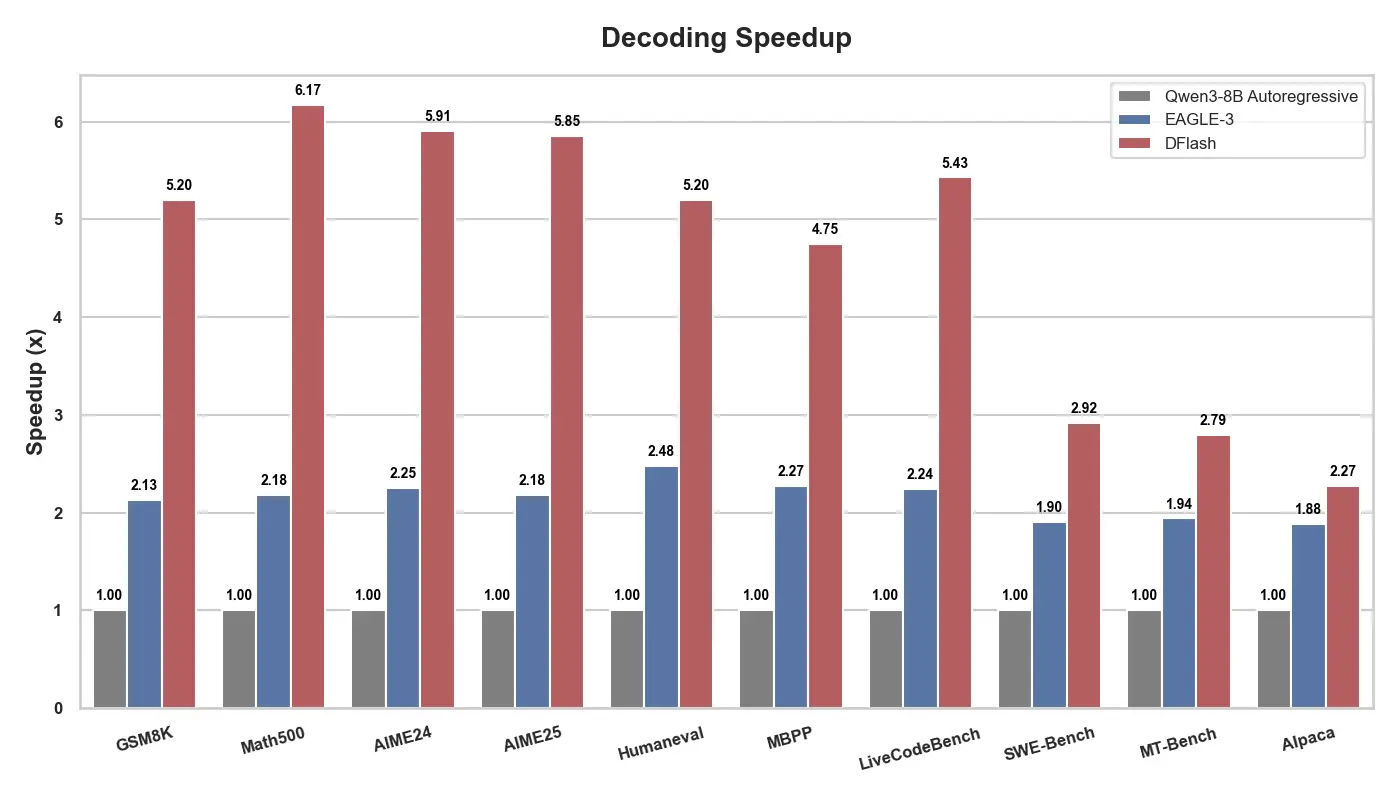
官方團隊表示,目前正在將 DFlash 集成到 vLLM 中,並計劃支持更大規模的 MoE 模型。
