作者:來自 Elastic Alexander Marquardt
瞭解為什麼加法提升方法會破壞BM25排名,以及乘法評分如何在Elasticsearch中提供受控且可擴展的排名影響。
測試Elastic最前沿、開箱即用的能力。快來看看我們的示例筆記本,開始免費雲試用,或者現在就在本地機器上試用Elastic吧。
BM25是 Elasticsearch 中最廣泛使用的基於文本的評分模型之一。在許多電子商務實現中,它是決定產品相關性的主要組成部分,因為它提供了一個易於理解、可解釋的分數,用來反映商品與用户查詢的匹配程度。除了這種文本相關性之外,商品運營和搜索團隊通常還需要通過業務指標來影響排序,例如利潤率、庫存水平、受歡迎程度、個性化或營銷活動策略,同時又不破壞底層的文本相關性。
實現這一點最直觀的手段是使用帶 boost 的should子句或rank_feature字段。它們在一開始看起來可能有效,但隨着查詢模式變化或商品目錄結構發生變化,這兩種方法都會退化,甚至失效。它們的共同侷限在於:在一個不同查詢之間尺度變化很大的評分系統中,引入了加法調整。像 “+2” 這樣的 boost,可能在某些查詢中壓倒基礎的 BM25 分數,而在另一些查詢中幾乎不起作用。換句話説,加法方法可能會導致脆弱且不可預測的排序行為。
相比之下,使用function_score的乘法增強提供了一種穩定、數學上成比例的方式來塑造 BM25 分數,而不會扭曲其底層結構。你的應用邏輯決定哪些因素值得提升;function_score 以一種可預測、可解釋的方式表達這種意圖,保留了 BM25 相關性信號的幾何結構(高層次的相對排序),通過受控的方式微調排名,而不是淹沒核心的文本相關性。
本文基於之前的兩篇文章,這兩篇文章展示了乘法增強的實際用法:(1)使用 Elasticsearch 中的 function score query 通過利潤和受歡迎度來增強電子商務搜索,以及 (2)如何通過個性化的、基於羣組的排序來提升電子商務搜索相關性。在這裏,我們從這些示例中抽身,回到其背後的架構原則:為什麼通過 function_score 進行乘法增強,是在 Elasticsearch 中影響基於 BM25 排名時最可靠、最具擴展性的方法之一。
為什麼保留基礎 BM25 排名很重要
在許多基於 Elasticsearch 的應用中(包括電子商務),BM25 仍然是評估文本相關性的核心組成部分。它提供了一個可解釋、透明的信號,方便需要理解為什麼某個產品會排在當前位置的團隊使用。這些特性使 BM25 在強調可解釋性和運行可預測性的環境中特別有吸引力。
正因為如此,大多數團隊希望對 BM25 生成的排名進行塑形,而不是替換它。例如,他們可能希望讓高利潤商品稍微更常出現,降低低庫存商品的曝光度但不將其隱藏,或者突出與特定用户羣體匹配的商品。理想情況下,這種塑形應當保留 BM25 算法生成的排名幾何結構。
問題出現在團隊嘗試通過在基礎 BM25 排名之上疊加獨立評分流來實現這些目標時。這些加法調整並不總是與 BM25 的評分尺度可比,並且會隨着查詢、數據分佈和商品目錄結構的變化而表現不一致。隨着時間推移,排序會變得脆弱、不直觀,且難以調優。一個可靠的影響機制必須與 BM25 的評分幾何結構協同工作,而不是壓倒它。
使用乘法增強的 function_score 查詢正具備這一特性。它允許團隊以成比例、可解釋的方式施加業務影響,同時保持 BM25 底層結構的完整性。
為什麼許多影響排序的方法會削弱(甚至破壞)BM25
團隊通常會從一些看起來很直接的機制入手:帶 boost 的 should 子句、rank_feature 字段,或自定義script_score邏輯。這些工具在各自的設計場景中是有效的,這也是為什麼它們看起來像是添加業務影響的自然手段。但當它們被用來塑造或影響基於 BM25 的文本相關性時,往往會導致不穩定、不透明或脆弱的排序行為。
根本問題在於,這些方法在一個基礎 BM25 值在不同查詢、字段和數據集之間差異很大的系統中,引入了彼此獨立的加法評分貢獻。如果不尊重這種變化性,影響效果就會變得不可預測。
下面是三種最常見的模式,以及它們在實際中為何會失敗。
1)通過 should 子句進行加法增強
帶 boost 的 should 子句看起來很直觀:“提升符合這個業務規則的商品。” 但在底層,這種行為本質上是加法的。
考慮如下形式的查詢:
GET products/_search
{
"query": {
"bool": {
"must": [ { "match": { "description": "running shoes" }}],
"should": [ { "term": { "brand": { "value": "nike", "boost": 1 }}}]
}
}
}
這種查詢會產生如下行為:
final_score = base_BM25 + should_BM25
問題在於 base_BM25 和 should_BM25 並不會一起按比例變化。隨着數據集變化,或發出不同的查詢,BM25 的量級可能會發生巨大變化。例如,在某種情況下,三個商品的基礎 BM25 分數可能是 12、8、4;而在另一種情況下,可能變成 0.12、0.08、0.04。這種變化可能發生在商品目錄更新之後,或查詢結構被修改之後。
一個帶 boost 的 should 子句會向最終分數中加入它自己的 BM25 風格貢獻。在這種情況下,加法貢獻(例如 should_BM25 = +2)會表現得非常不一致:
- 當 base_BM25 很小(0.12)時,+2 會主導最終分數 —— 大約是 18 倍的提升。
- 當 base_BM25 很大(12)時,同樣的 +2 幾乎不會改變文檔位置 —— 只有大約 17% 的提升。
這種不穩定性意味着,組合後的 must 分數和 should 分數在不同查詢或不同商品目錄之間並沒有穩定的語義。一個在某個查詢中只是輕微提升品牌的規則,可能在另一個查詢中主導整個排序,又在第三個查詢中幾乎不起作用。這不是調參問題,而是加法評分在結構層面上的固有屬性。
2)使用 rank_feature 來施加業務影響
rank_feature 系列在表示諸如新鮮度或受歡迎度等數值特徵時非常有用。它速度快、存儲緊湊、運維簡單。然而,當它被用來影響文本相關性(BM25)時,會遇到與上一節所述相同的結構性限制。
rank_feature 子句會生成它自己的評分貢獻,然後將其加到 BM25 分數之上:
final_score = base_BM25 + feature_score
就像帶 boost 的 should 子句一樣,這兩個組成部分並不會一起按比例變化。BM25 的取值會隨着查詢中詞項的稀有程度和商品目錄統計而大幅波動,而 feature_score 則遵循被增強的業務屬性本身的尺度(例如受歡迎度或新鮮度),這一尺度通常與 BM25 的尺度毫無關係。結果是,隨着語料或查詢模式的演進,這兩條評分流會逐漸偏離。
其後果與前面討論的 should 子句問題是一樣的:
- feature score 可能在某個查詢中主導 BM25,而在另一個查詢中幾乎可以忽略不計。
- 調參變得非常脆弱,因為你在校準兩個彼此獨立的尺度 —— 一個是隨查詢詞項統計變化的 BM25,另一個是隨業務屬性自身分佈變化的 feature score。
儘管 rank_feature 仍然是表示原始數值屬性的優秀機制,但它並不適合用於對 BM25 施加成比例的影響;在這種場景下,目標不是增加第二個分數,而是對已有分數進行温和的塑形。
使用 script_score 進行自定義評分
當帶 boost 的子句或 rank_feature 字段難以調優時,團隊通常會將 script_score 作為最後手段。它提供了完全的自由來操作分數,包括根據任何業務規則加、減、乘或替換 BM25 值。script_score 查詢會用自定義邏輯替換 Elasticsearch 的評分管道。腳本不是對 BM25 分數進行塑形,而是構建一個獨立的評分機制,其行為完全取決於腳本內部的代碼。雖然這很強大,但在系統規模擴大時,會引入三個更為顯著的挑戰。
- 不透明性
評分邏輯隱藏在腳本中,而非以聲明方式表達。當排名行為出現意外變化時,很難判斷問題出在腳本本身、數據變化,還是與 BM25 的交互。商品運營和相關性工程師失去了理解文檔排名變化原因的能力。 - 性能與運維成本
腳本評分繞過了 Elasticsearch 的許多優化和緩存路徑。每個匹配初始查詢的文檔都必須執行腳本,通常導致 CPU 使用率升高和延遲不可預測。 - 與 BM25 結合時的脆弱性
由於 script_score 允許任意計算,很容易產生不再類似 BM25 的評分行為,或者無法保持其相對結構。隨着數據集的發展或查詢模式的變化,自定義邏輯可能以意想不到的方式與 BM25 交互。在開發初期表現合理的腳本,一旦商品目錄增長或數據分佈變化,就可能產生令人意外或不穩定的結果。由於 script_score 允許任意數學操作,不同工程師在系統不同部分可能無意中編碼了衝突的評分模型,使得隨着組織規模擴大,排名變得難以理解。
function_score 如何對 BM25 提供可預測影響
BM25 已經衡量了文檔與查詢的匹配程度。它反映了文本相關性、詞項稀有度、文檔長度以及語料庫的統計特性。當團隊引入商業信號,包括 margin、庫存水平、流行度、個性化或 merchandising 策略時,目標不是替代這種相關性,而是影響它。
這種區別微妙但關鍵。大多數業務需求本質上是比例性的:
- 略微提升高 margin 商品
- 減少低庫存商品的曝光,但不隱藏它們
- 對這個用户羣體的匹配商品略微提升
- 提升流行度,但不要讓文本相關性丟失
這些自然以百分比調整而非固定加值表示。merchandiser 很少會要求“+2 分的 score”;他們要求的是“稍微增加可見度”,無論 BM25 分數的絕對數值是多少。數學上,這意味着所需的變換是:
final_score = BM25 × boost_factor
boost_factor 可能是 1.05、1.2 或 1.5,取決於信號。乘法提升不會試圖重新發明評分;它只是按比例調整 BM25 輸出。乘法調整有三個特性,與現實世界的排序控制非常契合:
- 提升保持比例。換句話説,20% 的提升始終是 20% —— 無論 BM25 是 0.12 還是 12。提升的大小不依賴於 BM25 的底層尺度。
- BM25 保持其作為主要信號的作用。乘法調整輕微改變排序而不覆蓋它。強文本匹配仍然優先;商業邏輯影響排序,但不主導。
- 因為操作是乘法而非加法,改變查詢或更新語料庫時不需要重新調整數值常量。提升在任何地方都有相同的意義。
Elasticsearch 的 function_score 查詢提供了一個優雅的機制來表達這種模式。通過使用:
- score_mode: “sum” 來組合 boost factor(構建乘數),以及
- boost_mode: “multiply” 將提升(乘數)應用到 BM25
你可以以一種穩定且可解釋的方式表達商業意圖,隨着數據和查詢模式的發展仍然有效。function_score 不是在 BM25 旁邊增加第二個分數,而是直接轉換 BM25 —— 輕柔、可預測地調整,符合 merchandisers 和產品負責人對排序調整的思路。
實踐中的例子:乘法提升在真實電商查詢中的表現
為了説明乘法提升在真實排序場景中的作用,查看一個小而具體的例子會很有幫助。這裏的目標不是展示調優或生產級評分,而是展示 function_score 如何以可預測、比例化的方式影響 BM25,與商業意圖保持一致。
考慮一個簡單的目錄,有三雙不同品牌的籃球鞋:Nike、Adidas 和 Reebok。產品描述是有意設計的,使 BM25 分數根據查詢的具體性和字段長度表現出自然差異 —— 就像在真實目錄中一樣。
示例數據集
在以下例子中,我們使用一個小而簡單的樣本數據集,具有以下特徵。
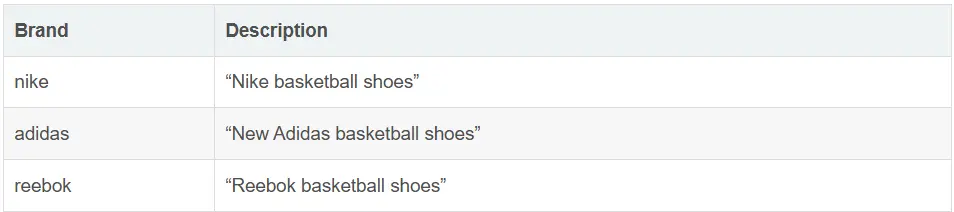
我們可以使用 Kibana Dev Tools 中以下命令創建包含上述產品的索引:
PUT products
{
"mappings": {
"properties": {
"brand": { "type": "keyword" },
"description": { "type": "text" }
}
}
}
POST products/_bulk
{ "index": { "_id": "nike-001" } }
{ "brand": "nike", "description": "Nike basketball shoes" }
{ "index": { "_id": "adi-001" } }
{ "brand": "adidas", "description": "New Adidas basketball shoes" }
{ "index": { "_id": "ree-001" } }
{ "brand": "reebok", "description": "Reebok basketball shoes" }
使用這個數據集,我們現在評估三個查詢:
- 基準 “basketball shoes” 搜索
- 同樣的查詢,但對 Adidas 提升 50%,對 Nike 提升 25%
- 一個特定的 “Reebok basketball shoes” 查詢,同時 Adidas 和 Nike 的提升仍然生效
每個場景都展示了乘法提升的不同特性。
1)基準排序:無提升
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"match": { "description": "basketball shoes" }
}
}
⚠️ 本文中的示例在單節點測試集羣(Elasticsearch 8.18.1)上運行,並且索引只有一個 primary shard。如果你使用 Elastic Cloud Serverless,它默認會為你的索引分配三個 primary shard。因此,如果你想重現本文中顯示的相同 BM25 分數,你可以通過在搜索請求中添加 ?search_type=dfs_query_then_fetch 來啓用全局分數計算。這個參數對於重現分數很有用,但通常不需要,並且不推薦在生產系統中使用。包含此參數後,上述查詢將變為:
POST blog_food_products/_search?search_type=dfs_query_then_fetch
{
"size": 5,
"_source": ["description", "margin"],
"query": {
"match": {
"description": "McCain Chips"
}
}
}
dfs_query_then_fetch會在索引級別而非每個 shard 級別計算 BM25 詞項統計,從而使分數在不同環境中更加一致。
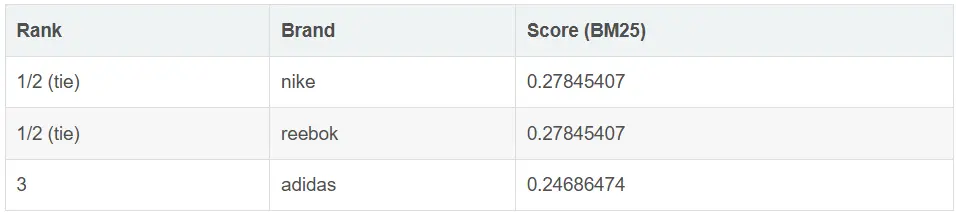
該查詢返回以下結果,其中 Nike 和 Reebok 排在 adidas 之前:
2)使用 function_score 給 Adidas 和 Nike 增加權重
如果市場活動要求 Adidas 籃球鞋增加 50% 權重,Nike 增加 25% 權重,應用層可以這樣構造查詢:
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"function_score": {
"query": {
"match": { "description": "basketball shoes" }
},
"functions": [
{
"filter": { "term": { "brand": "adidas" } },
"weight": 0.5
},
{
"filter": { "term": { "brand": "nike" } },
"weight": 0.25
},
{
"weight": 1.0
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}
乘數是如何構造的:
- 基礎權重 = 1.0
- Adidas 額外增加 +0.5 → Adidas 的乘數 = 1.5
- Nike 額外增加 +0.25 → Nike 的乘數 = 1.25
- 其他品牌(包括 Reebok)保持基礎權重乘數 = 1.0
應用乘數:
最終得分 = BM25 × 乘數
Product BM25 Multiplier Final score Adidas 0.24686474 1.5 0.37029710 Nike 0.27845407 1.25 0.34806758 Reebok 0.27845407 1.0 0.27845407
結果
Adidas 排到最前,Nike 緊隨其後,Reebok 保持在底部,分數沒有變化。這正是乘法提升設計要實現的效果:
- Adidas 和 Nike 都獲得了更多曝光,但按配置的提升比例增加。
- BM25 的相對差異仍然重要;我們是在調整排名,而不是替換它。
- 排序變化主要發生在 BM25 分數接近的情況下。
- 使用加法提升時,相同的 “50% 對 25%” 業務意圖需要在任意 BM25 量表上用數字常量近似,並且效果會在不同查詢間大幅變化。
3)特定意圖仍然優先:“Reebok basketball shoes”
現在運行一個針對 “Reebok basketball shoes” 的高特定品牌查詢,同時保持 Adidas(50%)和 Nike(25%)的促銷仍然生效:
GET products/_search
{
"size": 3,
"_source": ["brand", "description"],
"query": {
"function_score": {
"query": {
"match": { "description": "Reebok basketball shoes" }
},
"functions": [
{
"filter": { "term": { "brand": "adidas" } },
"weight": 0.5
},
{
"filter": { "term": { "brand": "nike" } },
"weight": 0.25
},
{
"weight": 1.0
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}
結果顯示如下:
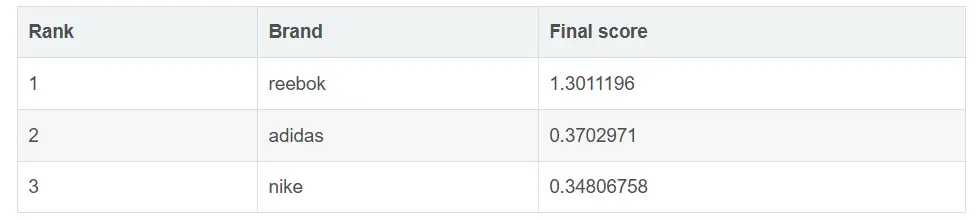
結果
Reebok 壓倒性獲勝,因為 BM25 正確識別了 “Reebok basketball shoes” 的強烈意圖。Adidas 和 Nike 仍分別獲得 50% 和 25% 的提升,但這些乘數遠不足以覆蓋 BM25 分數。
這正是乘法提升設計要實現的效果:
- 當 BM25 分數接近時,提升可以改變相對排序。
- 當 BM25 分數差異顯著時(如本例,由於強文本匹配),相同的提升幾乎沒有實際效果。
- 促銷影響排名,但不會覆蓋核心文本相關性信號。
本例展示了什麼
這些實際查詢展示了乘法提升的關鍵特性:
- 影響是按比例的,而非任意的。基於百分比的提升在任何 BM25 量表下都有相同比例效果。
- 文本相關性保持主導。強品牌意圖的查詢仍然顯示正確的產品。
- 系統行為直觀。商品經理可以看到期望的排名變化。
- 數學在所有查詢中穩定。無論匹配廣泛還是高度具體,相同的促銷都能正確應用。
- 應用邏輯保持清晰。業務層決定提升;Elasticsearch 可預測地應用它。
通過 function_score 的乘法提升在可控和可預測的方式下保留了相關性,同時實現了業務影響。
應用邏輯仍然是影響的作者
決定哪些內容應該被提升與在 Elasticsearch 中應用該提升之間有明確的分離。function_score 負責第二部分,而第一部分完全屬於應用邏輯。
你的應用邏輯負責做出如下決策:
- 哪些利潤閾值對業務重要
- 是否根據季節性調整受歡迎度
- 如何解讀客户行為或羣體歸屬
- 如何編碼活動規則
- 何時顯示或屏蔽某些產品組
這些是業務決策,而不是評分決策。Elasticsearch 不會判斷用户是注重預算還是奢侈品、是否有促銷活動,或者低庫存是否需要調整曝光度。這些判斷髮生在上游系統中,系統可以訪問用户上下文、會話特徵、分析數據和業務配置。在應用邏輯生成明確的數字信號(如權重、提升因子、閾值、羣體標籤)之後,function_score 查詢提供了一種可靠方式,將這些信號以可控乘數應用於 BM25。
這創建了一個清晰的架構約定:
- 應用邏輯:決定哪些內容應受影響
- BM25:提供核心文本相關性
- function_score:以數學穩定的方式應用影響
因為業務邏輯位於索引之外,團隊可以在不重新索引或重構文檔的情況下調整或實驗提升策略。
結論
電商搜索必須在核心文本相關性與業務考慮(如盈利能力、庫存狀況、客户意圖、季節性和個性化)之間取得平衡。BM25 提供穩定且可解釋的文本相關性基礎,但影響該分數需要謹慎。業務信號應塑造排名,而非覆蓋它。
然而,最常用的手段如 boosted should 子句、rank_feature 字段和臨時腳本評分往往表現不穩定。這些方法在開發早期看似有效,但隨着目錄變化或新查詢模式出現,其侷限性很快顯現。加法提升波動巨大,因為其影響完全依賴於 BM25 的底層量表,而 BM25 在不同查詢中變化極大。在某種情況下產生微小調整的提升,在另一種情況下可能主導排序。腳本評分則帶來不透明邏輯、性能下降以及評分行為難以理解或維護的問題。
通過 function_score 的乘法提升避免了這些問題,它按比例調整 BM25,而不是與其競爭。它不是添加一個獨立的分數組件,而是對 BM25 本身應用可控乘數。這產生了商品經理實際期望的可預測調整,例如:輕微提升高利潤商品、適度降低低庫存商品的可見性,或為相關用户羣體提供温和提升。
同樣重要的是,架構保持清晰。應用邏輯決定哪些業務信號重要,function_score 以一致且可解釋的方式應用它們。業務團隊可以演化策略而不破壞相關性,工程團隊可以優化相關性而不干擾業務規則。
這一原則是之前博客的基礎,這些博客展示瞭如何影響電商排名:
- 使用 Elasticsearch 的 function_score 查詢按利潤和受歡迎度提升電商搜索
- 如何通過個性化羣體感知排名提升電商搜索相關性
兩種方法都基於一個理念:業務信號應引導 BM25,而不是覆蓋它。通過 function_score 的乘法提升,提供了一種在實際電商搜索中實現這種平衡的可行、透明且可擴展的方法。
原文:BM25 ranking with multiplicative boosts in Elasticsearch - Elasticsearch Labs
