openGemini 發佈 v1.5 版本更新。帶來了眾多新功能,以及在讀寫性能方面實現了顯著提升
一、數據模型:TSBS cpu-only
為了確保測試的公平性和可比性,項目團隊就採用了業界廣泛使用的 TSBS (cpu-only) 基準測試工具,模擬了典型的時間序列數據模型。
- 測試環境:3節點集羣
- 節點配置:8核32G內
- 時間線數:30萬條
- 測試機型:c3.2xlarge.4,https://www.huaweicloud.com/product/ecs.html
二、寫入性能測試:速度提升,資源更省
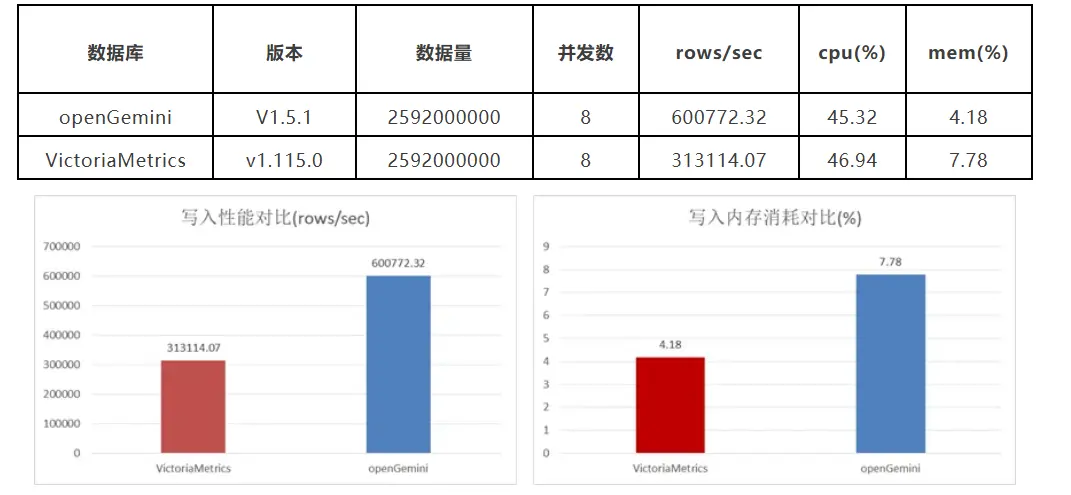
在TSBS cpu-only 模型下,openGemini 寫入性能約為 VM 的2 倍,內存佔用僅為 VM 的1/2,CPU使用率則與 VM 相當。
三、查詢性能測試:簡單更快,複雜更穩
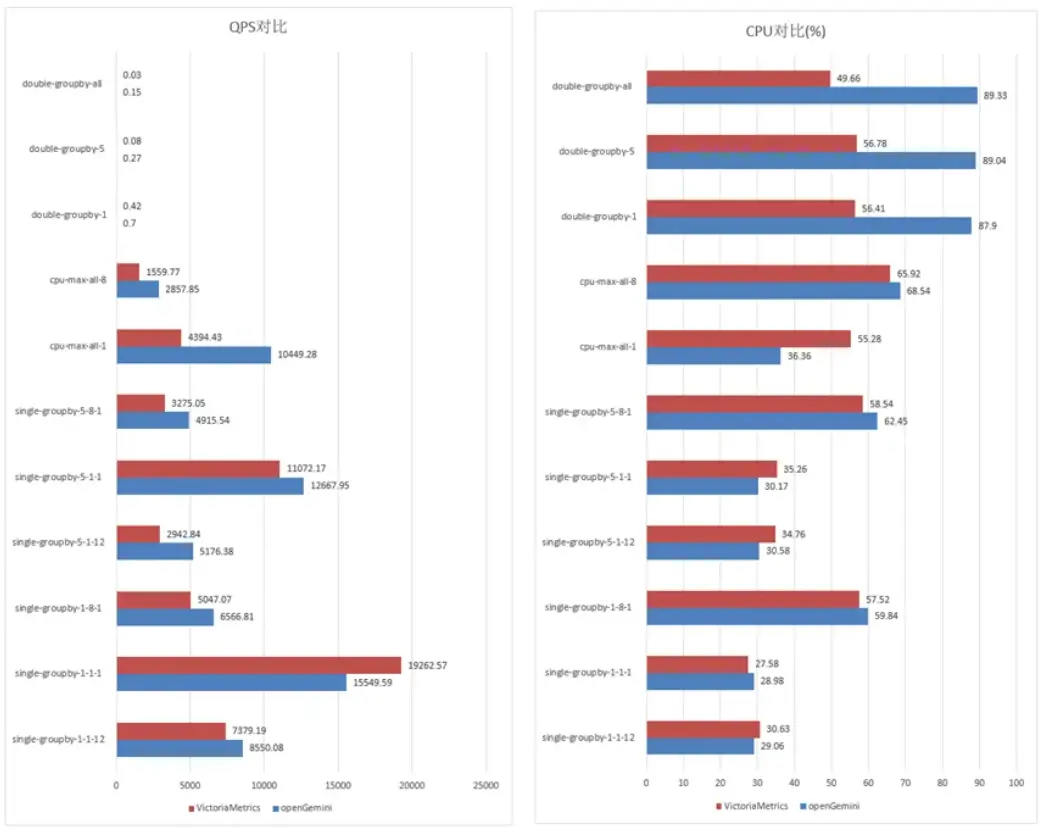
可以從結果看出來,openGemini在資源差不多的情況下,總共11個場景的10個場景查詢性能優於VictoriaMetrics(簡稱 VM),查詢模型single-groupby和查詢模型cpu-max-all:openGemini查詢性能約為 VM查詢性能的1.2-2.4倍;查詢模型double-groupby-5、double-groupby-all:openGemini查詢性能約為VM查詢性能的1-3倍。在single-groupby-1-1-1 場景下,VM依然表現出色。其設計理念是“極致簡潔”,不做過多的計算下推,因此在最簡單的查詢場景中具有天然優勢。
而 openGemini 在複雜聚合場景中表現更佳,主要得益於團隊對計算下推的深度優。v1.5 做了多種計算下推的流程優化,使得在包含多個條件過濾、聚合和連接操作的複雜查詢中,響應速度和性能表現顯著優於簡單查詢場景。
當然,項目團隊也意識到目前的實現方式在某些簡單查詢中存在“過度計算”的問題。在後續版本中計劃引入更智能的下推策略,實現“既要又要”的目標:在簡單查詢中保持高效,在複雜查詢中保持領先。
四、性能優化背後的“硬核技術點”
核心優化點解析:
1. 查詢語句匹配機制
- 特徵識別:基於車聯網、實時監控等典型業務場景,提取高頻查詢語句特徵。
- 高效匹配:通過預定義特徵與執行鏈路的映射機制,使查詢匹配成功後,執行器構建時延從毫秒級降至微秒級,極大提升響應速度。
2. 輕量化執行器設計
- 查詢上下文簡化:查詢上下文更“輕”,網絡傳輸編解碼開銷更小。
- 算子融合優化:持續優化掃描、過濾、聚合、投影四大核心算子,部分算子融合(如 scan/filter、agg/merge),減少冗餘計算。
- 調用鏈路優化:採用 pull-based 與push-based混用模式,簡化調用棧,降低函數調用開銷。
- 數據傳遞優化:構建內存親和與向量化數據格式,提升 CPU 緩存命中率,減少數據編解碼開銷。
3. 數據統一複用機制
- 統一數據結構:自底向上統一 Record 為數據載體,支持 Record到JSON的數據轉換,避免中間格式轉換。
- 高效內存複用:構建分層內存池機制,實現 Record 數據的編解碼複用與執行器構建複用,有效降低系統 GC 壓力。
