
文章大綱
- 本月榜單導覽
- 測評基準升級
- 新增的主流模型技術解析與對比
- 評測模型升級更新
- 三大核心維度綜合榜單
- 結論與推薦部署矩陣
- 專家點評
一、本月榜單導覽
2025 年 12 月,SCALE 完成了核心數據集和榜單模型的迭代。本月更新的核心價值在於:SQL 調優維度測評數據集 2.0 正式上線 。該版本標誌着評測基準從學術化 SQL 調優,全面轉向對"生產級複雜性"場景的真實模擬。
與此同時,本月完成了針對 GPT-5 系列 、Claude 4.5 系列 及 螞蟻百靈 Ling-2.0-Flash 等新一代模型的首發評測。我們旨在通過嚴苛的基準數據集,為企業技術決策者提供模型 SQL 能力具備落地價值的參考。
二、測評基準升級
為系統化評估大語言模型(LLM)在真實生產環境複雜業務邏輯處理中的實戰能力,本次我們對 SQL 優化維度的評測數據集進行了大幅度的體量擴充和難度升級。
需要特別説明的是,由於新版測試用例在 SQL 複雜度和業務場景覆蓋上均顯著提升,本次測評中各模型與基線應用的整體得分相較此前出現了一定程度的回落。
其中 DeepSeek V3.1 、Kimi-K2 和 DeepSeek R1 的得分降幅相對明顯,較上一期分別下降了 22.7、18.0 和 14.1 分。這一現象客觀反映了複雜業務 SQL 對模型的優化能力提出了遠高於常規語法改寫的挑戰。
以下將詳細介紹本次數據集升級的核心特徵及各模型的具體表現。
SQL 層面的核心設計特徵
新版數據集摒棄了理想化的語法改寫,覆蓋 MySQL、Oracle、Postgres 與 SQL Server 多種方言,聚焦於解決生產環境中的真實性能瓶頸:
- 豐富的語法覆蓋:包含 CTE、嵌套子查詢、窗口函數、聚合、複雜表達式與多種內置函數,能夠考察模型對複雜 SQL 語義的理解與改寫能力。
- 接近真實業務的複雜查詢:多表 JOIN、長鏈式子查詢與多層嵌套、混合聚合與過濾等寫法模擬生產場景,能暴露模型在實際工程中遇到的難點。
- 方言與索引敏感寫法並存:同時包含 MySQL/Oracle/Postgres/SQL Server 的方言特性與易讓索引失效的寫法(隱式類型轉換、LIKE、字符串/時間處理),用於檢測模型的方言適配與索引意識。
- 明確且可判定的優化目標:每條 SQL 都有對應的"期望觸發規則"(如謂詞下推、投影下推、LEFT→INNER、子查詢扁平化等),便於判定模型輸出是否實現了具體且可驗證的改寫。
- 強調語義等價與可執行性:要求優化保持語義等價和語法正確,既檢驗模型的改寫能力,也保證輸出在實際數據庫上具有可驗證性。
涵蓋的典型優化規則
數據集裏的規則以"可被模型發現並通過改寫實現的語義等價優化"為主,其中常見但不限於包括以下規則族:
- 投影下推 / 刪除冗餘投影 (Projection pushdown)
- 説明:移除子查詢返回但外層未使用的列,或在更內層就只保留外層需要的列,減少 IO 和網絡傳輸。
- 示例場景:多層嵌套子查詢中,內層 gender 列沒有被外層使用,應該移除。
- 謂詞下推 (包括將外層 WHERE 下推到內層)與 LIKE 前綴改寫為範圍查詢
- 説明:把過濾條件儘早在數據源處執行;對
LIKE 'prefix%'的前綴匹配可改寫為範圍比較(col >= 'prefix' AND col < 'prefix{next_char}')以利用索引。 - 示例場景:外層
WHERE teacher_name LIKE 'Dr.%'可以下推並改寫成範圍條件以走索引。
- 説明:把過濾條件儘早在數據源處執行;對
- 子查詢摺疊 / 子查詢扁平化 (subquery folding / flattening)
- 説明:將不必要的嵌套子查詢合併到一個查詢塊,減少臨時中間結果。
- 示例場景:多個層級的 SELECT/ FROM 包裝可以合併,消除中間表別名產生的冗餘。
- 無輸出 JOIN 轉 EXISTS / LEFT JOIN 轉 INNER JOIN
- 説明:當外連接實際不會產生 NULL 擴展或存在等價約束時,用更高效的 JOIN/EXISTS 語義替換,或者消除沒有輸出貢獻的表。
- 示例場景:子查詢語義保證某一列有值,則
LEFT JOIN可安全變為INNER JOIN。
- 消除隱式類型轉換 / 時間條件優化
- 説明:避免字符串與日期/時間之間的隱式轉換,改用一致的類型或顯式函數以避免索引失效。
- 示例場景:日期字符串比較應改為使用標準時間戳或使用
TO_DATE後與索引列比較。
SQL 優化分項指標表現
基於強化後的數據集,我們通過邏輯等價性、語法正確性、優化深度三個核心技術子維度評估模型在數據升級後的真實表現:
邏輯等價
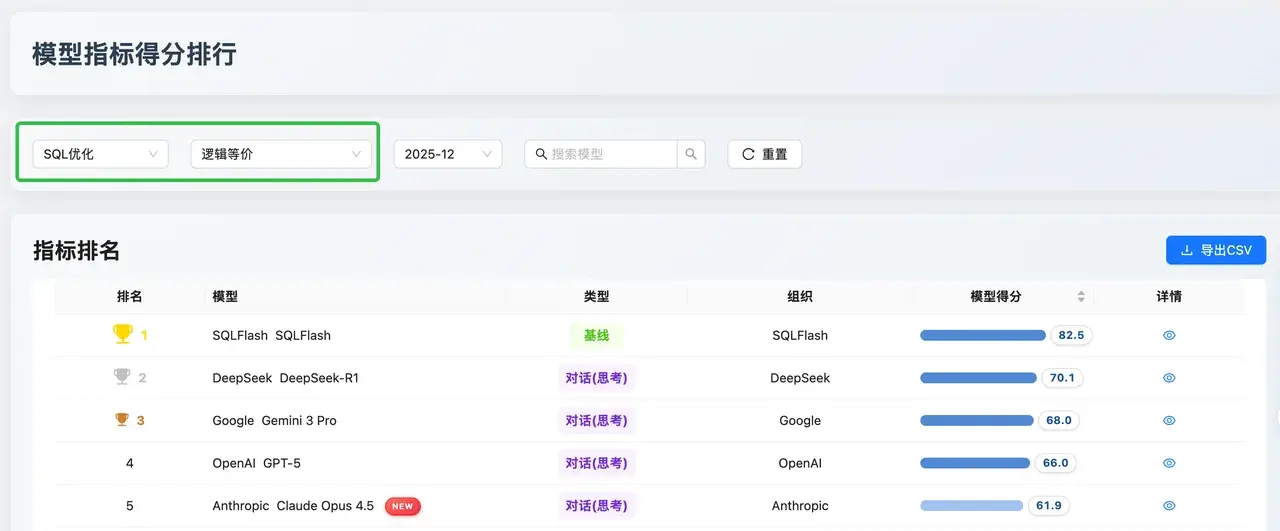
數據解讀 :在長文本和複雜業務SQL場景下,SQLFlash 以 82.5 的高分確立了基線優勢,展現了極高的穩定性。在對話類模型中,DeepSeek-R1(70.1) 與 Gemini 3 Pro(68.0) 表現接近,位居前列。
評價 :這一維度考察的是"改寫後 SQL 是否與原始 SQL 邏輯一致 "。DeepSeek-R1 在處理複雜邏輯嵌套和函數時表現出優於 GPT-5 的邏輯收斂性,證明了其推理模型架構在保證業務邏輯不偏離方面的優勢。
優化深度
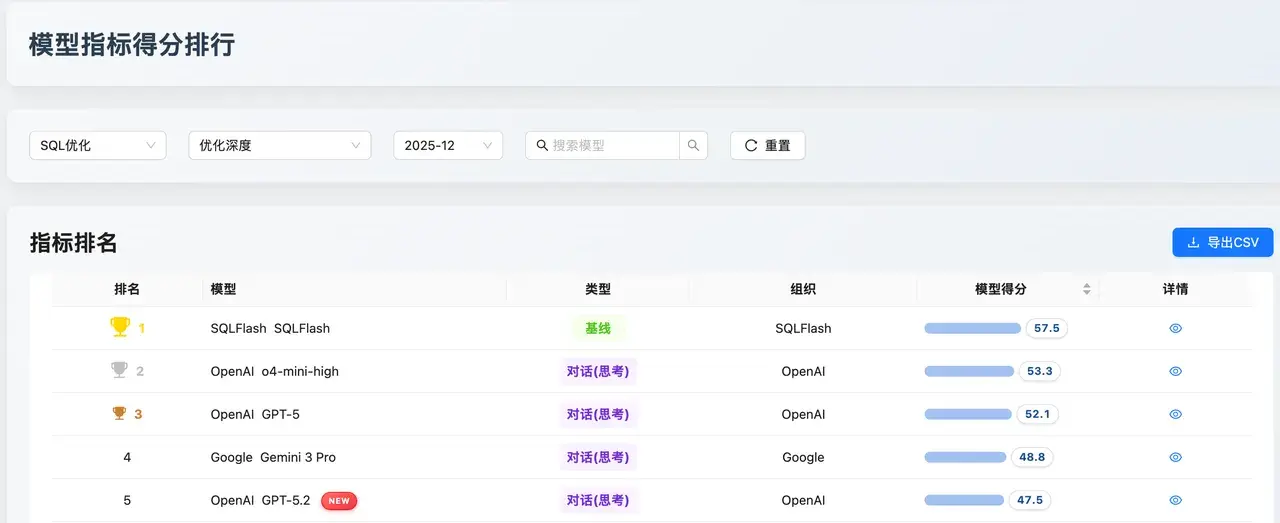
數據解讀 :這是難度最高的維度。SQLFlash(57.5) 依然領跑。值得注意的是,OpenAI o4-mini-high(53.3) 和 GPT-5(52.1) 緊隨其後,反超了其他競爭對手 。
評價:該維度衡量模型是否具備 DBA 級別的物理代價評估能力。OpenAI 系列模型在此展現了其"物理執行計劃專家"的特質,能夠主動識別索引失效等底層痛點並進行深層重構。
語法錯誤檢測
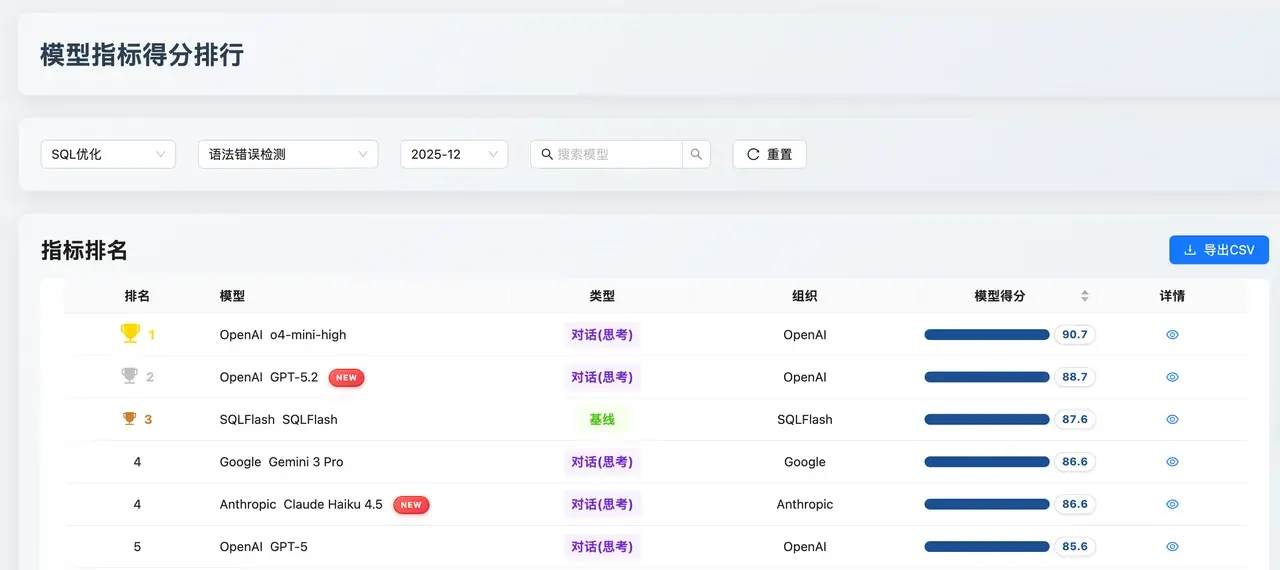
數據解讀 :OpenAI o4-mini-high 以 90.7 的相對高分位居榜首,GPT-5.2(88.7) 和 SQLFlash(87.6) 緊隨其後。
評價 :在代碼合規性和語法安全性方面,OpenAI 陣營展現了統治力。這表明在構建自動化 SQL 代碼校驗工具時,o4-mini-high 是當前最具性價比的選擇。
SQL 優化維度測評總結
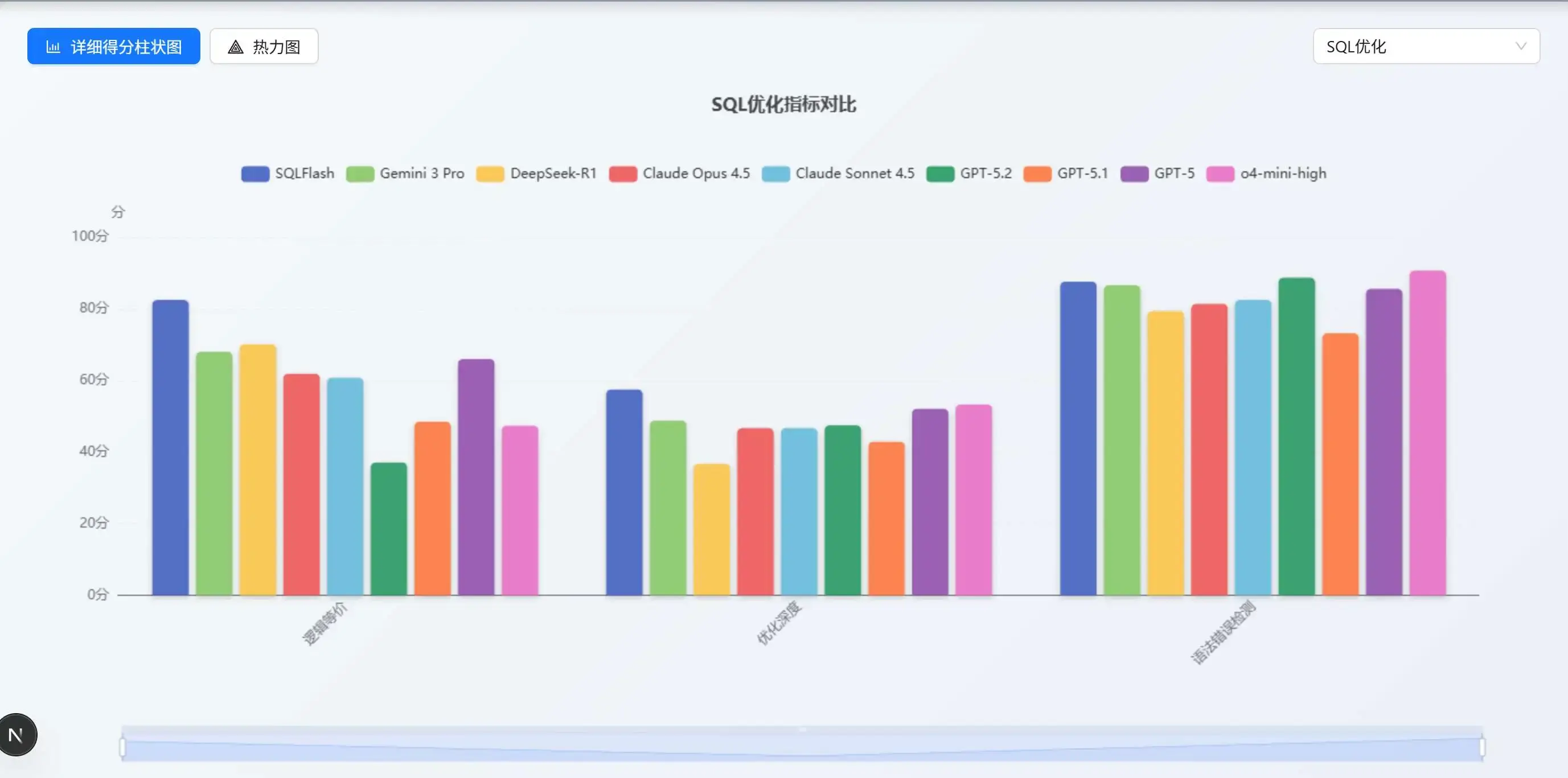
本次測評基於更貼近真實生產環境的數據集展開,測試用例在 SQL 複雜度和業務場景覆蓋上均有所提升。在這一背景下,各模型與基線應用的整體得分相較此前出現一定回落,反映出複雜業務 SQL 對模型優化能力提出了更高要求。
與此同時,SQLFlash 作為專注於 SQL 優化的專業應用,在綜合表現上仍保持領先優勢。當前主流模型在 SQL 優化維度各項指標上的具體表現如下圖所示:
三、新增的主流模型技術解析與對比
OpenAI
GPT-5.2:高精度語法糾錯與執行專家
- 能力核心 : SQL 理解(81.3)能力穩居第一梯隊。其最大的亮點在於 語法錯誤檢測(優化維度 88.7 / 理解維度 82.9),是所有模型中對語法最敏感的。同時在國產數據庫支持上也表現不俗(86.8)。
- 業務價值:極佳的 SQL 調試助手和代碼質量守門員。在開發階段集成該模型,可以有效攔截絕大多數語法錯誤,提升代碼上線質量;同時保證了較高的執行準確性。
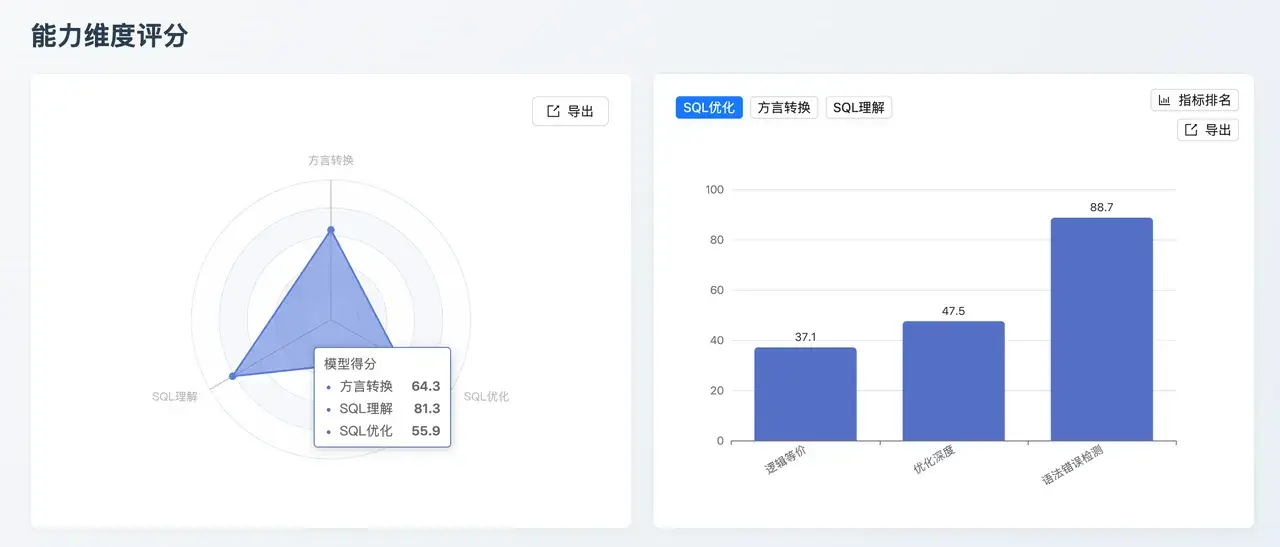
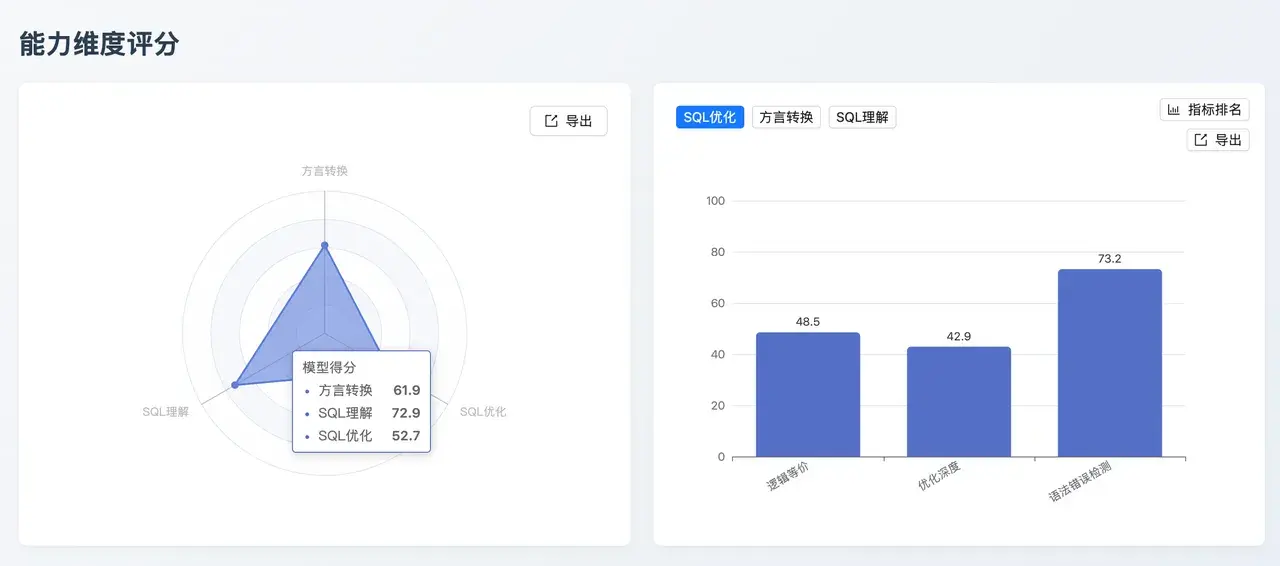
GPT-5.1:國產數據庫適配領航者
- 能力核心 : 在 國產數據庫(94.7) 這一細分指標上取得了全場最高分(與 QwQ 並列)。雖然在優化深度和大 SQL 轉換上稍弱,但在特定環境下的適應性極強。
- 業務價值:針對本土化業務場景,尤其是信創環境下的數據庫遷移和應用開發具有極高的可用性,能準確處理國產數據庫特有的語法特性。
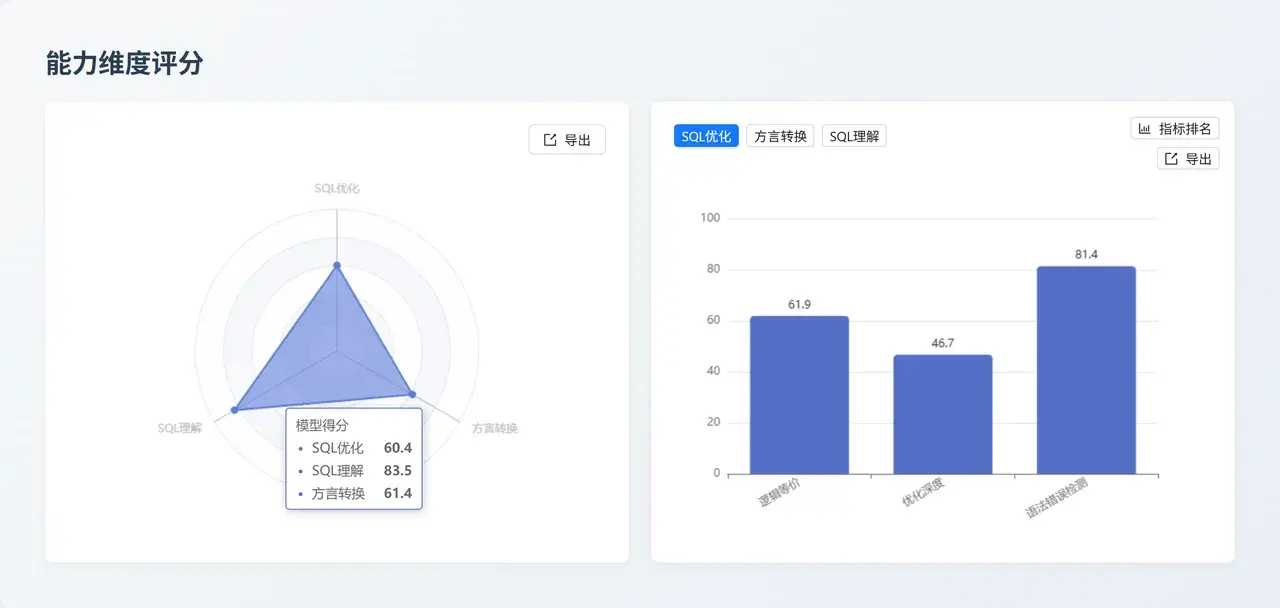
Anthropic
Claude Opus 4.5:全能型 SQL 架構師(理解與優化雙料冠軍)
- 能力核心 :該模型在 SQL 理解(83.5) 和 SQL 優化 (60.4) 兩個最關鍵的維度均取得了全場最高分。它在執行計劃檢測(87.1) 和邏輯等價性(61.9)方面表現出極高的穩定性。
- 業務價值:適用於對準確性要求極高的核心業務場景,如複雜查詢的深度調優、自動化運維診斷以及作為 SQL 審核的高級專家系統,能夠顯著降低數據庫性能風險。
Claude Sonnet 4.5:複雜 SQL 遷移與重構專家
-
能力核心 :綜合能力極強,並在 方言轉換(72.2) 維度表現出色。特別是 大 SQL 轉換(71.0) 分數遠超其他模型(其他多在 40 分以下),展現了驚人的長文本和複雜邏輯處理能力。同時在 SQL 優化方面與 Opus 並列第一。
-
業務價值:是傳統數據庫向雲原生數據庫遷移、或異構數據庫遷移的最佳選擇,尤其擅長處理遺留系統中的超長複雜存儲過程和查詢語句,大幅降低人工重構成本。
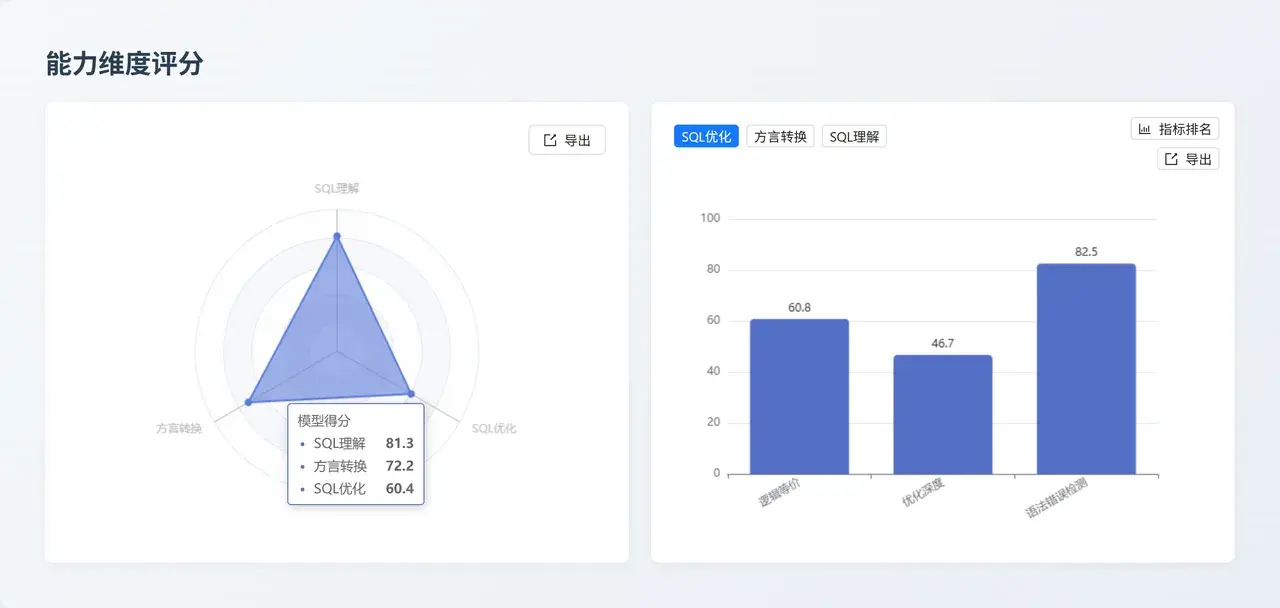
Claude Haiku 4.5:高效異構方言轉換器
- 能力核心:以 73.3 的高分拿下了 方言轉換 維度的全場第一。雖然在 SQL 理解深度上略遜於 Opus 和 Sonnet,但在處理不同數據庫語法差異(尤其是邏輯等價性高達 90.3)方面表現極其敏鋭。
- 業務價值: 適合高頻、大批量的多數據庫適配任務,如多雲環境下的 SQL 兼容性轉換工具,能夠快速、低成本地實現跨平台 SQL 語法的自動化翻譯。
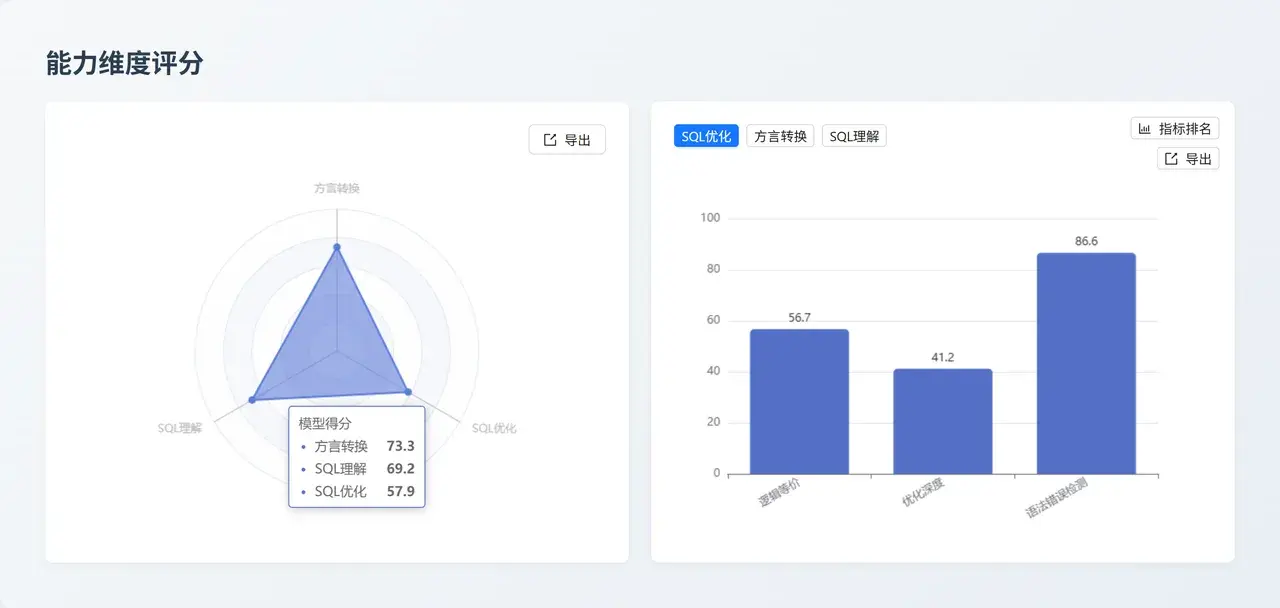
螞蟻百靈
Ling-2.0-Flash:基礎 SQL 輔助工具
-
能力核心:各項指標表現相對平緩,方言轉換能力 (43.5) 較弱,但在國產數據庫支持 (84.2) 和基礎語法檢測 (80.4) 上仍有一戰之力。
-
業務價值:適用於輕量級應用場景或作為輔助性的備選模型,用於處理簡單的 SQL 校驗和基礎國產庫適配任務。
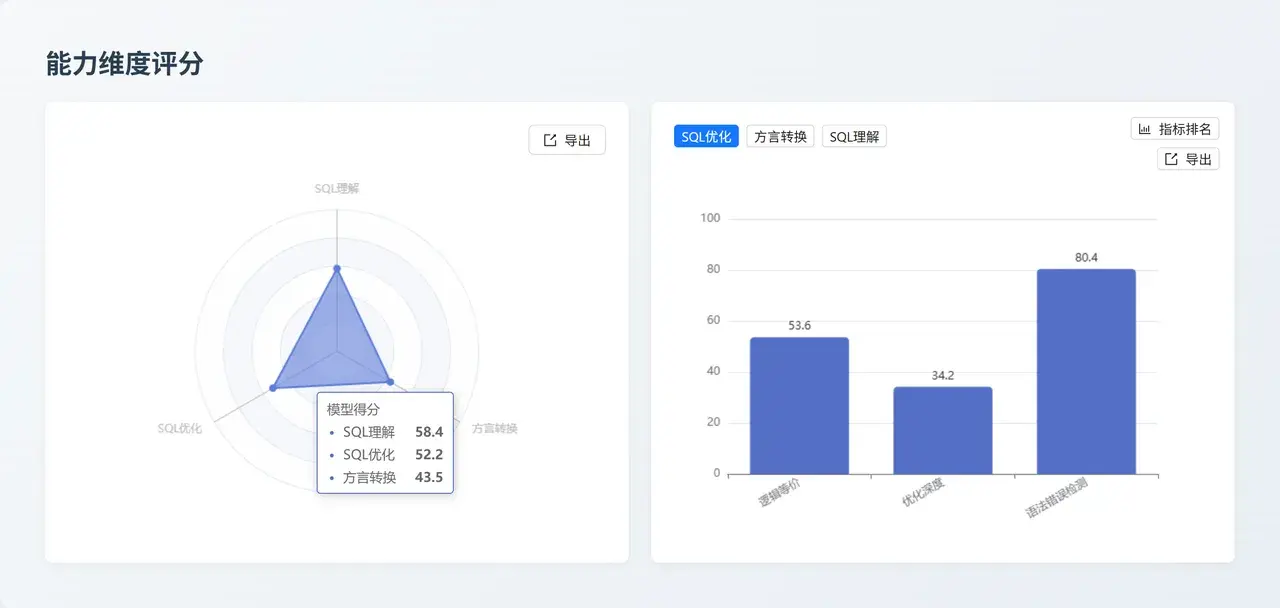
千問
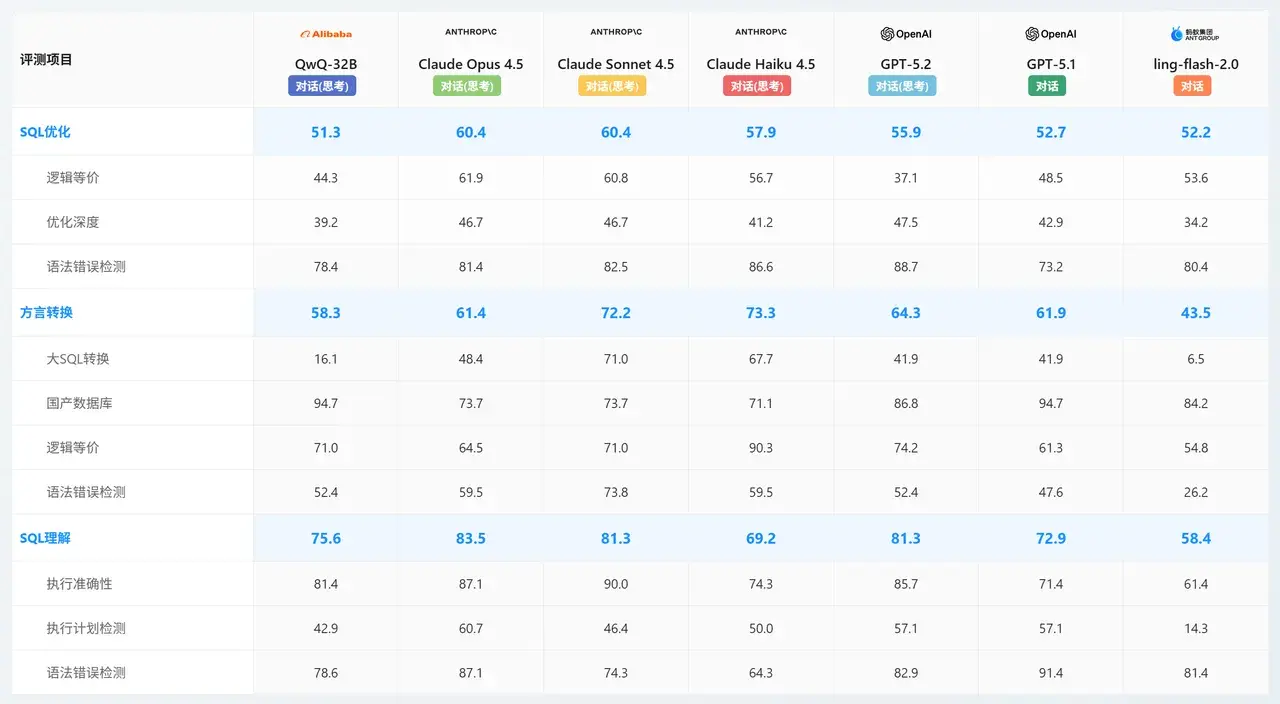
QwQ-32B:高性價比國產化集成方案
-
能力核心:同樣在 國產數據庫 (94.7) 指標上表現卓越。雖然在 SQL 優化 (51.3) 和複雜轉換上相對較弱,但在基礎的 SQL 理解 (75.6) 和語法檢測 (78.6) 上保持了可用的基準水平。
-
業務價值:作為參數量相對較小的模型,它是私有化部署和國產化替代的高性價比選擇,特別適合處理涉及國產數據庫的基礎查詢和交互任務。
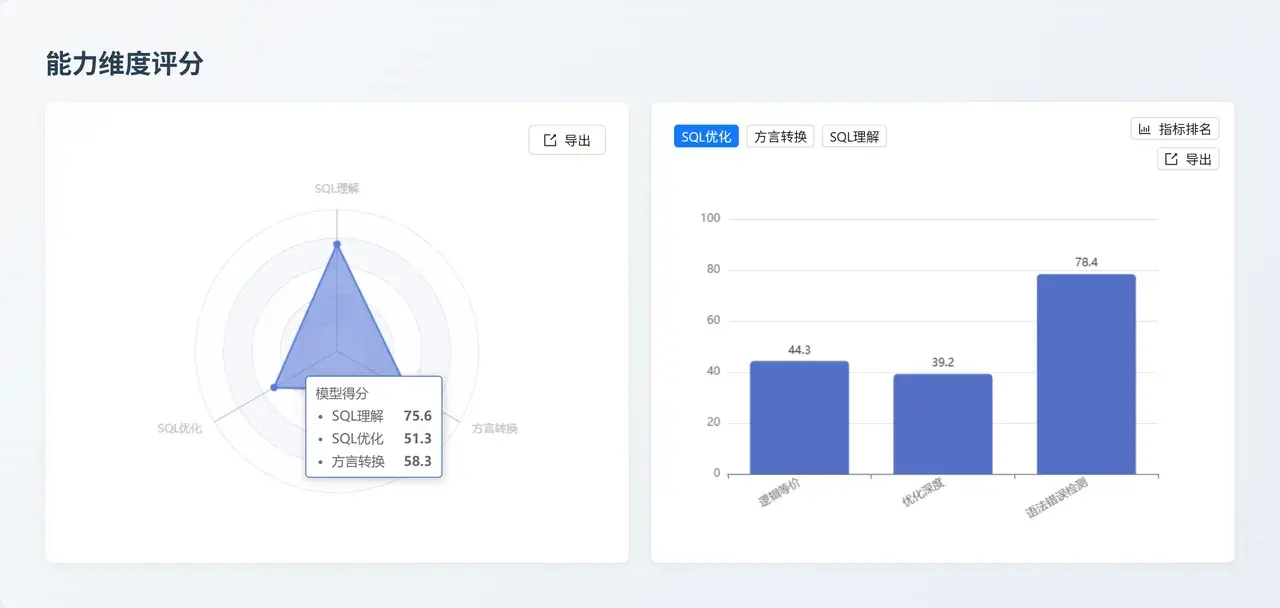
四、評測模型升級更新
新增評測模型
- Claude 4.5 系列:Opus、Sonnet、Haiku 全量進入評測矩陣。
- OpenAI 系列:GPT-5.1、GPT-5.2 快照穩定版本。
- 螞蟻百靈系列:Ling-2.0-Flash。
- 千問系列:QWQ-32B。
存量模型升級與快照更新
- o4-mini-high:替換舊版版本,顯著提升了多表關聯場景下的邏輯收斂性。
- GPT-5 統一快照:將所有實驗分支統一更新為最新的 Snapshot 版本,確保後期評測的一致性。
- DeepSeek-V3.2 正式版:由實驗版 (Exp) 切換至穩定版,重點針對 Oracle 語法下的幻覺問題進行了針對性修復。
五、三大核心維度綜合榜單
基於 SQL 優化數據集 2.0 評測標準,本月模型在各維度的性能排布如下:
SQL 優化能力榜

榜單點評 :SQLFlash(72.6) 作為垂直領域基線模型繼續霸榜。在通用大模型中,GPT-5(65.1) 憑藉其在優化深度上的積累位居第一,Gemini 3 Pro(64.4) 緊隨其後。這表明在處理高性能需求時,GPT-5 仍是通用模型中的最優解 。
SQL 方言轉換榜
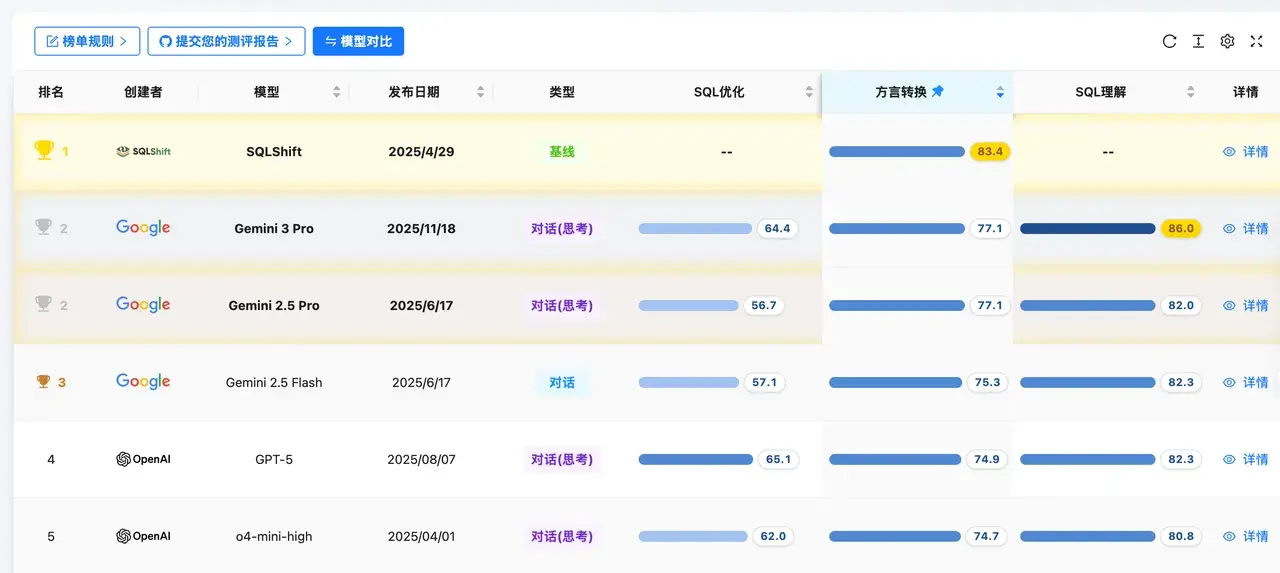
榜單點評 :SQLShift(83.4) 展現了專有模型的優勢。通用模型方面,Gemini 3 Pro(77.1) 與 Gemini 2.5 Pro(77.1) 並列第二,顯示了 Google 模型在跨平台語言理解上的深厚功底,尤其是在異構數據庫遷移場景下表現穩健。
SQL 理解能力榜
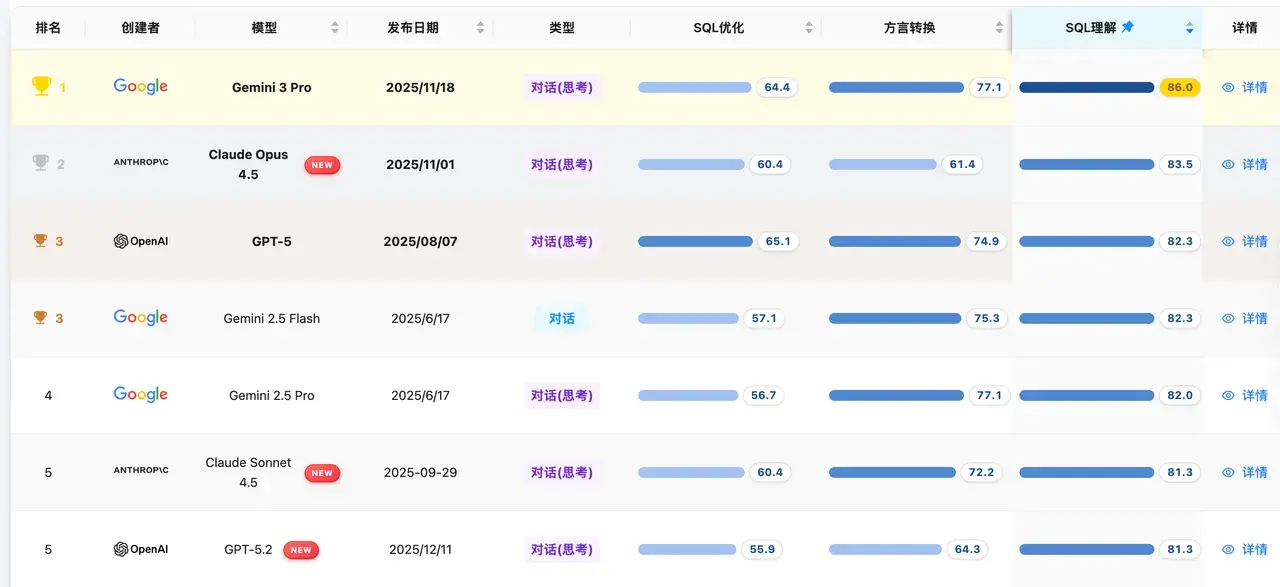
榜單點評 :Gemini 3 Pro(86.0) 在此維度表現卓越,超越了 Claude Opus 4.5(83.5) 。這意味着在代碼審查和執行計劃分析任務中,Gemini 3 Pro 擁有最強的上下文理解與潛在風險識別能力。
六、 結論與推薦部署矩陣
根據 SQL 優化數據集 2.0 的實戰評測得分,我們建議用户按需選擇部署方案:
- 生產環境慢 SQL 性能調優 :首選 SQLFlash 專業的SQL調優應用, 模型可選 GPT-5.2,利用其在物理層執行路徑的深度優化能力。
- 高保真 SQL 重寫/規整 :首選 SQLFlash,確保改寫後業務邏輯零偏差,適合核心交易鏈路代碼規整。
- 複雜業務邏輯遷移和國產化信創支持 :首選 SQLShift 專業的 SQL 方言轉換應用,模型可選 Claude Opus 4.5,確保在跨庫遷移中的極致邏輯一致性。
- 高頻實時 SQL 審計與校驗 :首選 Claude Haiku 4.5 或 Ling-2.0-Flash,在極低時延下提供高可靠的語法診斷。
七、專家點評

吳炳錫,Databend Labs 聯合創始人, 騰訊 TVP 成員, 中國數據庫大會顧問團成員。
點評內容:
SCALE 是可以讓每個人輕鬆的關注大模型的 SQL 排行榜。SCALE 站在開源角度公開測試的數據和腳本,持續對比,每個月一更新用於展示每個大模型在 SQL 領域的真實水平。同時 SCALE 保持社區共建,測試及過程公開,鼓勵提交測試用例,鼓勵團隊一同參與。
整體來講 SCALE 對於 DBA 或是開發人員快速瞭解大模型在 SQL 方面的能力用於 SQL 性能方面的優化,同時對於模型團隊,也可以快速的瞭解模型在 SQL 方面的短板,利於後期的優化。
目前來看 SCALE 的 SQL 能力還是主要以 MySQL 類的 SQL 為主,希望後期也引入分析類湖倉產品,如 Databend , 可以支持更復雜的 SQL,也可以進一步看看大模型的能力。最後建議從月更到周更,大模型行業進化太快,感覺周更可以更好的看到模型的進展。
查看完整榜單並聯系我們提交您的產品進行測評。https://sql-llm-leaderboard.com/
SCALE:為專業 SQL 任務,選專業 AI 模型。
