Volcano 是 CNCF 首個雲原生智能調度引擎,由華為雲發起開源並深度參與貢獻。12月29日,Volcano 宣佈社區迎來了一個新的子項目 Kthena!

Kthena 是一個專為 Kubernetes 設計的雲原生、高性能的 LLM 推理路由和編排、調度系統。它旨在解決在生產環境中大規模編排、部署和服務 LLM 所面臨的核心挑戰,通過其獨特的 超節點拓撲感知的親和性調度,KV Cache 感知的流量調度、Prefill/Decode 分離路由等高級功能,顯著提升 GPU/NPU 資源利用率和吞吐,降低推理延遲,並賦予企業前所未有的靈活性和控制力。作為 Volcano 的子項目,Kthena將致力於幫助 Volcano 擴展除 AI 訓練之外的邊界,打造訓推一體的完整解決方案。
LLM 服務化的“最後一公里”困境
大語言模型(LLM)正在以前所未有的速度重塑各行各業,但將其高效、經濟地部署在生產環境中,特別是基於 Kubernetes 的雲原生平台上,仍然困難重重。開發者們普遍面臨以下挑戰:
- 資源利用率低:LLM 推理,尤其是其獨特的 KV Cache 機制,對 GPU、NPU 顯存的佔用是動態且巨大的。傳統的負載均衡一般採用Round-Robin算法,無法感知這種負載特性,導致 GPU、NPU 資源閒置與請求排隊並存,成本高昂。
- 延遲與吞吐量難以兼顧:LLM 推理分為“Prefill”(處理輸入提示)和“Decode”(生成 Token)兩個階段,前者是計算密集型,後者是訪存密集型。將兩者混合調度,常常導致無法針對性優化,影響整體服務的響應速度和吞吐能力。因此PD分離的部署已經成為主流,但如何高效路由和調度,仍是一個難題。
- 多租户與多模型管理複雜:在企業環境中,通常需要同時提供多個不同模型、不同版本或經過 LoRA 微調的模型。如何實現請求的公平調度、優先級管理以及動態路由,是一個複雜的工程難題,業界甚至有些方案將AI網關與大模型一一對應。
- 缺乏K8s原生集成:許多現有的解決方案要麼是外部系統,與 Kubernetes 生態割裂;要麼過於複雜,無法滿足生產級所需的簡單易用性和靈活運維。
Kthena:雲原生 LLM 推理的智能大腦
為了攻克上述難題,Kthena 應運而生。它並非要取代現有的 LLM 服務框架(如 vLLM, sgLang),而是作為它們上層的智能“交通樞紐”和“調度中心”,深度集成於 Kubernetes 之中。
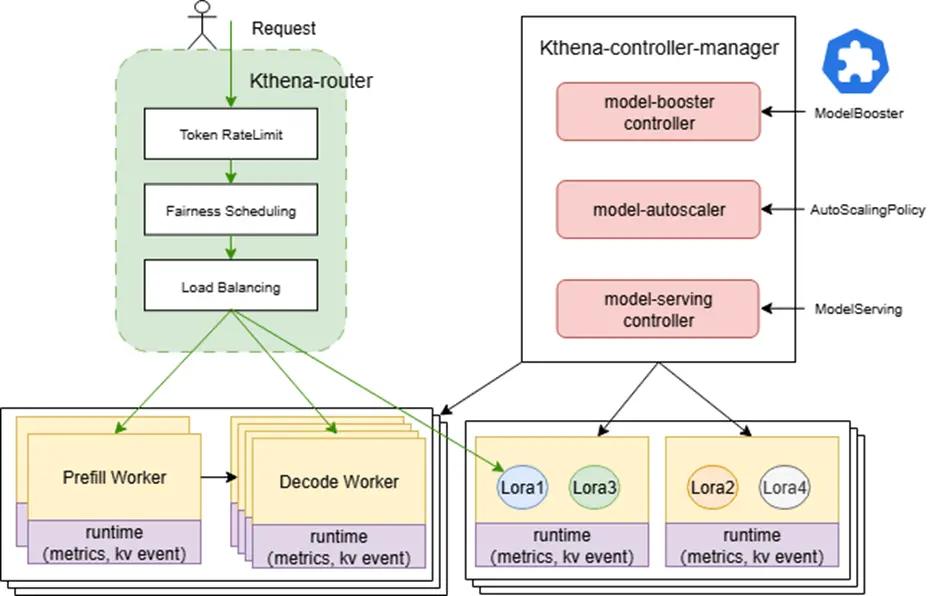
Kthena 架構圖
Kthena 的核心由兩大組件構成:
- Kthena Router:一個獨立、高性能面向多模型的router,負責接收所有推理請求,並根據 `ModelRoute` 規則,智能地將請求分發到後端的 `ModelServer`。
- Kthena Controller Manager:Kubernetes 控制平面的控制器,它主要包含多種控制器,負責 LLM 工作負載的編排與生命週期管理。它持續調諧並聯動多類 CRD(如 `ModelBooster`、`ModelServing`、`AutoScalingPolicy`/`AutoScalingPolicyBinding`、以及 `ModelRoute`/`ModelServer`),將聲明式API轉化為運行時資源:ModelServing 控制器編排 `ServingGroup` 與 `Prefill/Decode` 角色分組;支持網絡拓撲親和調度和Gang調度、滾動升級與故障恢復;基於 `AutoScalingPolicy` 實現彈性擴縮容。
這種架構使得 Kthena 成為連接用户請求與 LLM 模型的高度可編程的橋樑。
核心特性與優勢
Kthena 的強大之處在於其專為 LLM 推理場景設計的核心功能:
1) 生產級推理編排(ModelServing)
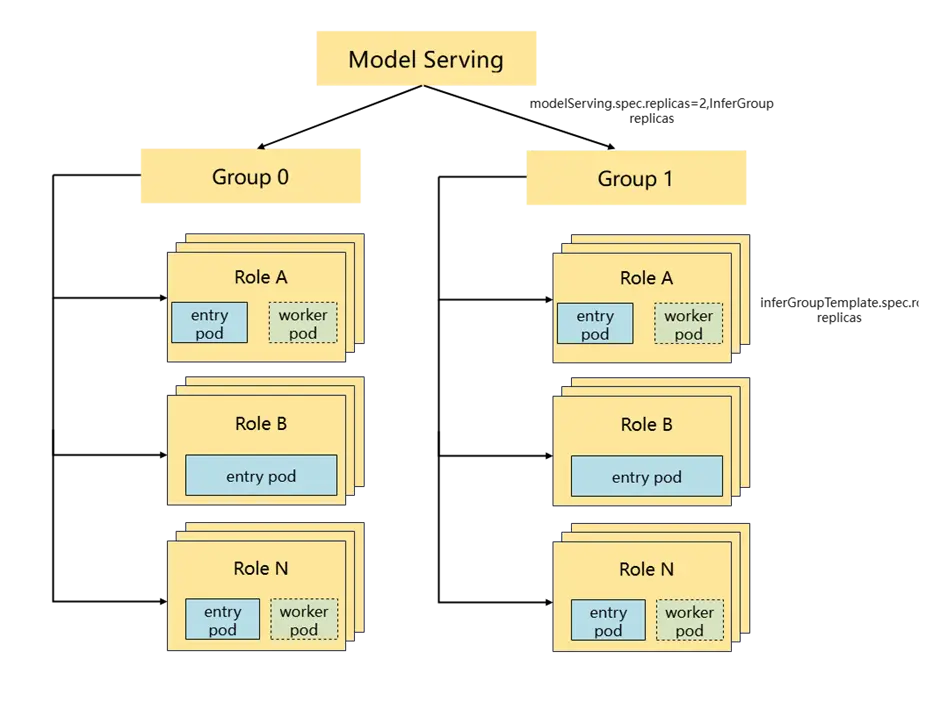
- LLM工作負載三層架構設計:ModelServing > ServingGroup -> Role,一個API,支持LLM原生部署、PD分離部署,乃至大EP部署等多種部署形態,簡化管理多LWS的負擔。例如對於PD分離的大規模部署,可用一個ModelServing表示,根據負載的大小每個ModelServing可以包含任意數目的 ServingGroup(xPyD 分組), 每個ServingGroup包含多個角色(Prefill Decode,他們通常部署在同一個超節點內以提升推理性能),相同的角色可以等價為一個LeaderWorkerSet,支持TP/PP/EP等多節推理並行計算。
- 原生支持PrefillDecode分離部署:將計算密集型的 Prefill 實例調度到配備高性能計算卡的節點組,而將訪存密集型的 Decode 實例調度到配備高帶寬顯存的節點組,實現資源的最佳匹配和極致的端到端延遲優化。另可以獨立伸縮,動態調整PrefillDecode的比例,更靈活的應對各種複雜的業務場景(如長短句混合、實時推理等)。
- 多並行範式支持:TP/PP/DP/EP 等並行模式靈活配置,最大化提升資源利用率和SLO
- 內置拓撲感知、Gang 調度支持:Gang調度確保ServingGroup/Role“成組原子化”落地,避免資源浪費;拓撲感知調度通過將Role內的一組Pod調度到網絡拓撲更優的節點,提升並行計算的數據傳輸時延。
2) 開箱即用的模型上線(ModelBooster)
- 針對主流的大模型,提供包括PD分離在內的多種部署範式模板,自動生成ModelRoute/ModelServer/ModelServing/Autoscaling等路由策略和生命週期管理資源
- 覆蓋通用的部署場景,至於更靈活的編排可通過ModelServing進行細粒度的控制
3) 智能、模型感知的路由(Kthena Router)
- 多模型路由:兼容OpenAI API,根據請求頭或Body體內容,將流量調度到不同的基礎模型。
- 插件化調度算法:提供最少請求、最小時延、KV Cache 感知、Prefix Cache 感知、LoRA 親和、GPU 利用率感知、公平調度等多種負載均衡算法,滿足用户不同業務場景和部署形態的需求
- LoRA 模型熱插拔無中斷:感知推理引擎加載的LoRA 適配器,提供無中斷的插拔和路由能力
- 豐富的流量治理策略:基於權重的模型路由,金絲雀發佈、Token級流控、故障轉移·
- Allin-one實現架構,無需部署Envoy Gateway,原生支持PD分離的流量調度,將多層路由合併成一層,易於維護
4) 成本驅動的自動擴縮容(Autoscaler)
- 同構伸縮:支持穩定、突發雙模式,按業務指標(CPU/GPU/內存/自定義)精準擴縮
- 異構部署優化:在多推理引擎/異構加速器組合中按“成本能力”貪心分配,最大化性價比
5) 主流推理引擎與異構硬件支持
- 支持多種主流推理引擎vLLM、SGLang、Triton/TGI 等,統一API抽象、標準化指標
- 支持GPU/NPU 等異構混部,配合異構 Autoscaling 實現成本與 SLO 的動態平衡
6) 內置流量控制與公平性調度
- 公平調度:支持基於優先級和歷史Token消耗的的公平調度,既兼顧用户的優先級,對高優先級用户提供更好的服務,又防止低優先級用户“餓死”
- 流量控制:支持按照用户、模型、token長度進行精細化流量控制
極致的性能提升
基於 Kthena Router 的調度插件架構,在長系統提示詞場景(如 4096 tokens)下,採用“KV Cache 感知 + 最少請求”策略相較隨機基線:
- 吞吐可提升約 2.73 倍
- TTFT 降低約 73.5%
- 端到端時延降低超過 60%
|
Plugin Configuration |
Throughput (req/s) |
TTFT (s) |
E2E Latency (s) |
|
Least Request + KVCacheAware |
32.22 |
9.22 |
0.57 |
|
Least Request + Prefix Cache |
23.87 |
12.47 |
0.83 |
|
Random |
11.81 |
25.23 |
2.15 |
短提示詞場景差距會隨提示詞長度收斂,但在多輪對話、模板化生成、前綴高度相似的業務中,KV Cache 感知策略優勢顯著。實際收益與模型規模、Prompt長短、硬件緊密相關,但“按需組合、按場景選型”已被驗證有效。
社區展望 / Call for Contribution
Kthena 在項目規劃和發展的初期便得到了部分社區用户單位的關注和支持,但這只是一個開始。我們計劃在未來支持更高效的調度算法、更廣泛的大模型最佳部署實踐,並持續深耕 LLM 推理的大規模部署和性能優化。
“開源是技術創新的源頭活水,也是推動產業標準化的最強引擎。作為Volcano項目的發起單位,華為雲很榮幸能夠與社區其他夥伴一起推出全新的Kthena分佈式推理項目。這不僅是Volcano社區技術演進重要里程碑,更是華為雲在雲原生AI領域長期投入與持續創新的有力見證。它將與華為雲CCE(雲容器引擎)、CCI(雲容器實例)等基礎設施深度結合,進一步釋放包括昇騰(Ascend)在內的多元算力價值,為客户提供極致的算力性價比。我們希望通過Kthena,與全球開發者與夥伴,共建、共享一個開放、繁榮的雲原生AI生態,為千行萬業的智能化升級構築最堅實的算力底座。”
—— 祁小波,華為雲通用計算服務產品部部長
“Kthena進一步鞏固了Volcano在智能計算調度領域的領先地位。我們的平台利用Volcano的統一調度與資源池化能力,一站式滿足通用計算與智能計算中訓練、推理等多類算力需求。這使得算力資源能夠在不同場景間靈活流轉,有效避免了資源割裂的問題。展望未來,我們期待 Kthena結合Volcano的彈性伸縮能力與Volcano Global的跨集羣調度特性,共同推動算力資源利用率進一步提升!”
—— 楊磊,中電信人工智能公司 PaaS研發總監楊磊
“Volcano 項目自誕生之日起,便始終與社區以及各類 AI 場景深度共建、同頻演進,逐步沉澱出一整套面向 AI 工作負載的調度與批處理生態。今天,Kthena 的出現,不僅將這條共建鏈路進一步拓展到大模型推理領域,把推理這一關鍵一環真正納入 Volcano 生態之中,更是在統一編排與智能路由層面,將 Volcano 在調度、彈性伸縮以及多算力適配上的多年實踐,凝練成一個令人振奮的里程碑式能力。藉助既有的 Kubernetes / Volcano 生態,更多團隊可以用更低的成本,獲得更智能的調度決策和更高效的算力利用,並在開放協作的基礎上持續演進。這不僅為道客解決了在推理場景中遇到的實際問題,也是我們所期待的雲原生 AI 形態——一個足夠開放、足夠智能、值得我們長期投入和深度參與的社區方向。”
—— 徐俊傑,DaoCloud 開源團隊負責人、Kubernetes 社區指導委員會成員
“自建大模型推理服務的生產級部署和運維難題,是一個覆蓋推理服務全生命週期管理(部署、運維、彈性、故障恢復等),GPU集羣穩定性,資源調度效率、推理服務性能提升,推理流量智能調度、AI可觀測等領域的系統工程。而這也正是Kthena項目的技術定位。
早在Kthena的規劃階段,小紅書雲原生團隊就和Volcano貢獻者做了深度的溝通,在推理流量智能調度方向,一起設計了多種流量調度策略和路由實現。未來,雙方將繼續在AI網關方向合作,結合小紅書內部業務經驗,一起為社區提供更精細化的AI流量智能調度能力,模型API管理能力,MCP協議支持等多種生產可用能力。”
—— 空古(陳華昌),小紅書雲原生業務網關負責人
“在深入調研並試用Kthena這一雲原生AI推理平台後,聯通雲對其展現出的前瞻能力印象深刻。我們尤為看好其與Volcano實現的聯合調度特性,其網絡拓撲感知與Gang Scheduling功能,能夠有效解決大規模分佈式模型推理場景下中,關於效率與可靠性的核心訴求,為破解複雜調度難題提供了極具潛力的解決方案。我們相信,Kthena卓越的低延遲、高吞吐與多模型智能路由能力,將為開源社區帶來真正具備生產級的AI推理解決方案,助力開發者更高效地構建和管理雲原生環境下的智能應用。”
—— 盧照旭,聯通雲智算能力中心團隊長
“開放和協作是構建社區的未來、加速技術創新的核心動力。在CNCF,我們持續致力於推動基礎設施向‘AI Native’演進,為整個雲原生生態提供標準、中立且可擴展的基礎能力。Volcano社區通過孵化Kthena子項目,將其在大規模批量計算和調度上積累的拓撲感知、Gang調度等核心經驗,精準地應用到了LLM在線推理這一關鍵場景。Kthena的價值在於,它提供了一套專為大模型設計、可供業界參考和借鑑的雲原生調度原語和抽象,如Prefill/Decode分離編排和KV Cache感知路由,這有助於將複雜的LLM推理工作負載,真正以Kubernetes原生的一等公民身份進行高效管理。這不僅是Volcano項目技術演進的重要一步,更是社區生態在解決AI規模化部署挑戰中貢獻的一份重要實踐經驗。我們誠摯邀請全球的開發者、研究人員和所有云原生愛好者加入,共同貢獻智慧,完善這些關鍵AI基礎設施,加速 AI Native 進程。”
—— Kevin Wang, Volcano Maintainer、CNCF TOC 副主席
立即開始探索 Kthena
GitHub 倉庫: https://github.com/volcano-sh/kthena
官網: https://kthena.volcano.sh/
社區: 加入我們的 Slack https://cloud-native.slack.com/archives/C011GJDQS0N
