寫代碼時,你是否也曾在大海撈針,在海量代碼庫中苦苦尋找一個函數或解決方案?
在 RAG-for-Code 時代,一個強大的代碼 Embedding 模型就是你的“智能導航儀”。但問題是,專為自然語言設計的 Embedding 模型,在理解結構嚴謹、邏輯性強的代碼時,常常會“水土不服”。傳統的池化策略,要麼是平均池化,無法充分發揮大模型潛力,要麼直接使用 EOS 表徵,會因信息瓶頸而丟失關鍵細節。a
現在,代碼檢索領域迎來了新的王者!
螞蟻集團與上海交通大學繼 F2LLM 後再度聯手,重磅推出 C2LLM (Contrastive Code Large Language Models) 系列模型。我們通過基於注意力的創新池化機制,精準解決了代碼表徵的痛點,一舉登頂權威代碼榜單 MTEB-Code。
最重要的是,C2LLM 作為 CodeFuse Embedding 開源家族的第四位成員,將繼續秉承開放精神,將模型權重、技術報告、使用方式全套回饋社區,希望能為代碼大模型的研發提供一個更強的基線!

✨ C2LLM 核心亮點一覽
-
**🏆 登頂榜首:**C2LLM-7B 在權威的 MTEB-Code 代碼榜單上力壓羣雄,總分排名第一,超越包括閉源模型在內的一眾強手
-
**👑 小模型之王:**C2LLM-0.5B 在 1B 以下尺寸模型中勇奪桂冠,性能甚至超越了許多 7B 參數量的模型,是輕量化部署的絕佳選擇
-
**💡 獨創架構:**創新性地將注意力池化(PMA)引入代碼 Embedding,讓模型學會“抓重點”,告別信息瓶頸
-
**💯 完全開源:**模型權重、訓練細節以及使用方式全部開放,方便社區復現與二次開發
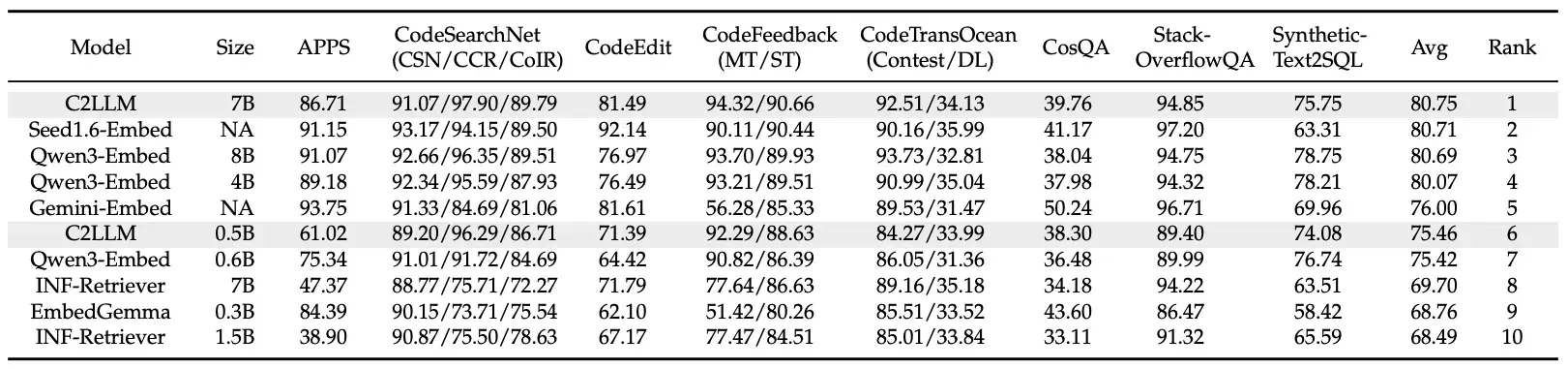
話不多説,直接上數據,感受 C2LLM 在 MTEB-Code 榜單上的王者表現:
💡 C2LLM 的獨家秘方:會“抓重點”的注意力池化
如此卓越的性能背後,是我們在模型架構上的大膽創新。
我們發現,對於代碼這種長序列、結構化的數據,傳統的池化方法存在天然缺陷:
-
**平均池化 (Mean Pooling):**像“大鍋飯”,粗暴地將所有 Token 信息平均,無法體現代碼中函數簽名、關鍵邏輯等核心部分的重要性。
-
**EOS 池化 (End-of-Sequence Pooling):**將所有信息壓縮到最後一個 Token,容易造成“信息瓶頸”,對於動輒上千行的代碼文件尤其致命。
為了解決這個難題,我們為 C2LLM 引入了一個輕量而強大的模塊——**注意力池化 (PMA, Pooling by Multihead Attention) **。
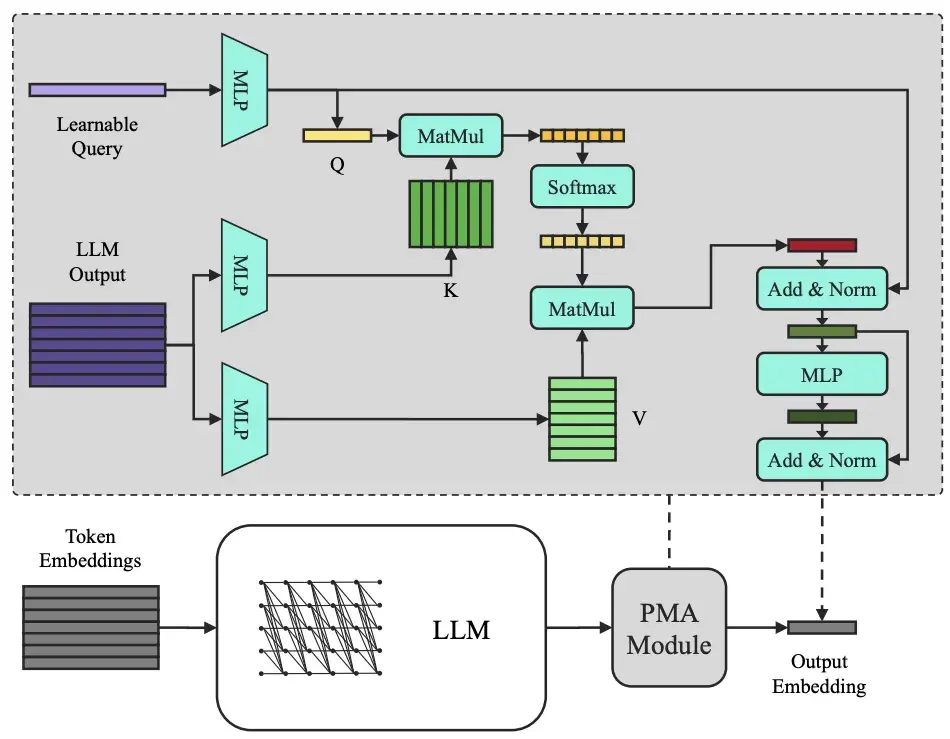
你可以把 PMA 想象成給模型配上了一位聰明的“項目經理”。這位經理(一個可學習的查詢向量)會審閲所有員工(代碼 Token)的工作報告,然後根據當前的項目目標(檢索任務),智能地為不同部分分配權重,提煉出最核心的信息,最終形成一份高度濃縮、直擊要點的最終報告(也就是代碼 Embedding)。
這種設計的優勢顯而易見:
-
**精準聚合:**模型能自主學習哪些代碼部分(如函數定義、核心算法)對於理解代碼意圖最關鍵。
-
**保留潛力:**完美兼容 Qwen2.5-Coder 等先進代碼大模型的因果注意力結構,充分釋放其預訓練能力。
-
**靈活高效:**在幾乎不增加計算開銷的同時,還能靈活控制輸出的 Embedding 維度,對向量數據庫非常友好。
📊 實力霸榜!MTEB-Code 成績見真章
是騾子是馬,拉出來遛遛!在被廣泛認可的 MTEB-Code 榜單上,C2LLM 家族用實力證明了一切。該榜單包含 12 項不同的代碼檢索任務,全面考察模型的綜合能力。
-
C2LLM-7B:總分高達 80.75,在所有開源和閉源模型中排名第一,尤其在面向代碼的複雜自然語言查詢任務上表現出色。
-
**C2LLM-0.5B:**以 75.46 的高分,不僅在 1B 以下模型中一騎絕塵,更是超越了 Qwen3-Embed-0.6B、INF-Retriever-7B 等更大參數的模型。
這一成績充分證明,通過先進的架構設計,我們可以在不依賴海量私有數據的情況下,實現代碼表徵能力的巨大飛躍。
🚀 立即體驗 C2LLM!
我們相信,開放是推動技術進步的最佳燃料。C2LLM 的所有成果現已開放,歡迎大家使用、研究和反饋!
-
**📄 論文鏈接:**https://arxiv.org/abs/2512.21332
-
💻 GitHub 代碼庫: https://github.com/codefuse-ai/CodeFuse-Embeddings
-
🤗 Hugging Face 模型: https://huggingface.co/collections/codefuse-ai/codefuse-embeddings
期待 C2LLM 能成為你下一個 AI for Code 項目的得力干將,也歡迎社區在此基礎上構建更強大的模型!
🌟 彩蛋預告:更全、更強的 CodeFuse Embedding 模型即將亮相
開源不息,進化不止。感謝社區一直以來對 CodeFuse 的支持與厚愛!
我們在此也提前向大家透露一個好消息:性能更強悍、語言支持更豐富的新版 C2LLM 和 F2LLM 已經在加急研發中!我們致力於打造全能的 Embedding 模型,讓 AI 能理解每一種自然語言和編程語言,讓每一位開發者都能在海量代碼中“精準導航”。代碼智能的未來,邀您一同見證,敬請關注!
關於我們
我們是螞蟻集團智能平台工程的全模態代碼算法團隊。C2LLM 是我們繼 D2LLM、E2LLM、F2LLM 之後,在 CodeFuse Embedding 開源模型系列的又一力作。
團隊成立3年以來,在 ACL、EMNLP、ICLR、NeurIPS、ICML 等頂級會議發表論文20餘篇,兩次獲得螞蟻技術最高獎 T-Star,1次螞蟻集團最高獎 SuperMA,CodeFuse 項目連續兩年蟬聯學術開源先鋒項目。團隊常年招聘研究型實習生,有志於 NLP、大模型、多模態、圖神經網絡的同學歡迎聯繫 hyu.hugo@antgroup.com,期待科研路上與你同行!
如果您想更快地獲取到最新信息,歡迎加入我們的微信羣。

企業用户如有需求,加入羣聊時還可私聊“CodeFuse服務助手”聯繫解決方案專家~
