編者按: 如果你正在為邊緣計算、本地部署或資源受限場景尋找高效的語言模型解決方案,你是否曾困惑:在眾多小型語言模型(SLM)中,哪一個才是微調的最佳起點?是否真的存在"小而強"的模型,能在微調後媲美甚至超越規模大數十倍的教師模型?
近期,distil labs 團隊進行了一項嚴謹的基準研究,或許能為你提供數據驅動的答案。他們在 8 類任務(涵蓋分類、信息抽取、開卷與閉卷問答)上,對 12 個主流小型模型(包括 Qwen3、Llama、Gemma、Granite、SmolLM 等系列)進行了統一微調與評估,並對比了其與 120B 參數教師模型(GPT-OSS-120B)的性能差異。
作者 | Distil Labs
編譯 | 嶽揚
01 TL;DR
經過微調的小型語言模型(SLM)可以勝過規模大得多的模型:微調後的 Qwen3-4B 在 8 項基準測試中的 7 項上表現能夠超越或戰平 GPT-OSS-120B(一個比它模型規模大 30 倍的教師模型),剩下的一項差距也不到 3 個百分點。在 SQuAD 2.0 數據集上,微調後的學生模型甚至比教師模型高出 19 分。這意味着你只需極低的成本,就能在自己的硬件上實現前沿模型級別的準確率。
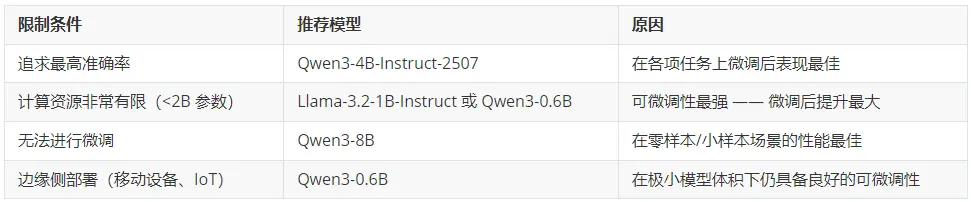
微調後性能最佳的模型:Qwen3 系列模型在微調後始終表現最強,其中 4B 版本整體表現最優。如果你的目標是在特定任務上獲得最高準確率,Qwen3-4B 就是你的首選。
最具可微調性(🐟-ble)(微調收益最大):小型模型從微調中獲得的提升遠超大型模型。 如果你受限於使用非常小的模型(1B--3B),也不必擔心 ------ 它們能從微調中獲益最多,能夠大幅縮小與更大模型之間的性能差距。
02 引言
如果你正在構建需要在設備端、本地或邊緣側運行的 AI 應用,你很可能問過自己:我該微調哪個小型語言模型(SLM)?目前 SLM 領域選擇眾多(Qwen、Llama、Gemma、Granite、SmolLM),每個系列都提供多種模型規模的版本。選錯基礎模型可能意味着有數週時間在浪費計算資源,或者得到的模型始終無法達到生產質量要求。
我們進行了一項系統的基準測試,用數據來回答這個問題。藉助 distil labs 平台,我們在 8 個不同的任務上(分類、信息抽取、開卷問答、閉卷問答)微調了 12 個模型,然後將它們的性能相互比較,並與用於生成合成訓練數據的教師大模型進行對比。
本文回答了四個實際問題:
- 哪個模型在微調後效果最好?
- 哪個模型最具可微調性?(即微調後提升最大)
- 哪個模型的基礎性能最強?(即未經微調前)
- 我們表現最好的學生模型,真的能媲美教師模型嗎?
03 實驗方法
我們評估了以下模型:
- Qwen3 系列:Qwen3-8B、Qwen3-4B-Instruct-2507、Qwen3-1.7B、Qwen3-0.6B。注意,我們關閉了該系列的"thinking"功能,以保證實驗的公平。
- Llama 系列:Llama-3.1-8B-Instruct、Llama-3.2-3B-Instruct、Llama-3.2-1B-Instruct
- SmolLM2 系列:SmolLM2-1.7B-Instruct、SmolLM2-135M-Instruct
- Gemma 系列:gemma-3-1b-it、gemma-3-270m-it
- Granite:granite-3.3-8b-instruct
針對每個模型,我們測量了:
- Base score:僅使用提示詞(prompting)的小樣本(few-shot)場景下的性能
- Finetuned score:在由我們的教師模型(GPT-OSS 120B)生成的合成數據上微調後的性能
我們的 8 項基準測試涵蓋分類 (TREC、Banking77、Ecommerce、Mental Health)、文檔理解 (docs)以及問答任務(HotpotQA、Roman Empire QA、SQuAD 2.0)。
為了實現公平測量,我們分別計算了每個模型在各個基準測試上的排名,然後計算所有任務上的平均排名,並以 95% 置信區間作為誤差棒(error bars)繪製在圖中。平均排名越低,表示整體性能越好。
04 問題一:哪個模型在微調後效果最好?
冠軍:Qwen3-4B-Instruct-2507(平均排名:2.25)
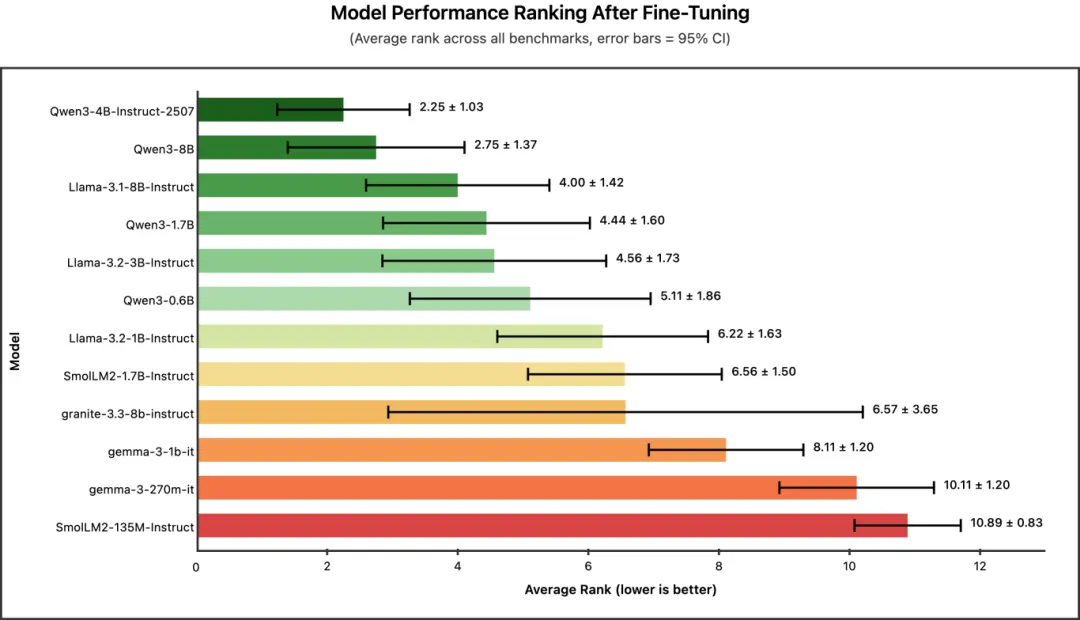
Qwen3 系列佔據了排行榜前列,其中 Qwen3-4B-Instruct-2507 摘得桂冠。值得注意的是,這款 4B 模型的表現甚至超過了更大的 Qwen3-8B,這表明在蒸餾任務中,Qwen3 的較新版本(2025 年 7 月 25 日更新的版本)比之前的 8B SLM 效果更好。
核心結論:如果你希望獲得效果最好的微調模型,並且擁有支持約 4B 參數規模模型微調的 GPU 顯存,那麼 Qwen3-4B-Instruct-2507 是你的首選。
05 問題二:哪個模型最具可微調性?(即微調後提升最大)
冠軍: Llama-3.2-1B-Instruct(平均排名:3.44)
這裏我們測量的是可微調性(tunability) ------ 即從基礎性能到微調後性能的提升幅度(finetuned_score - base_score)。一個高度可微調的模型初始表現可能較弱,但經過微調後提升顯著。
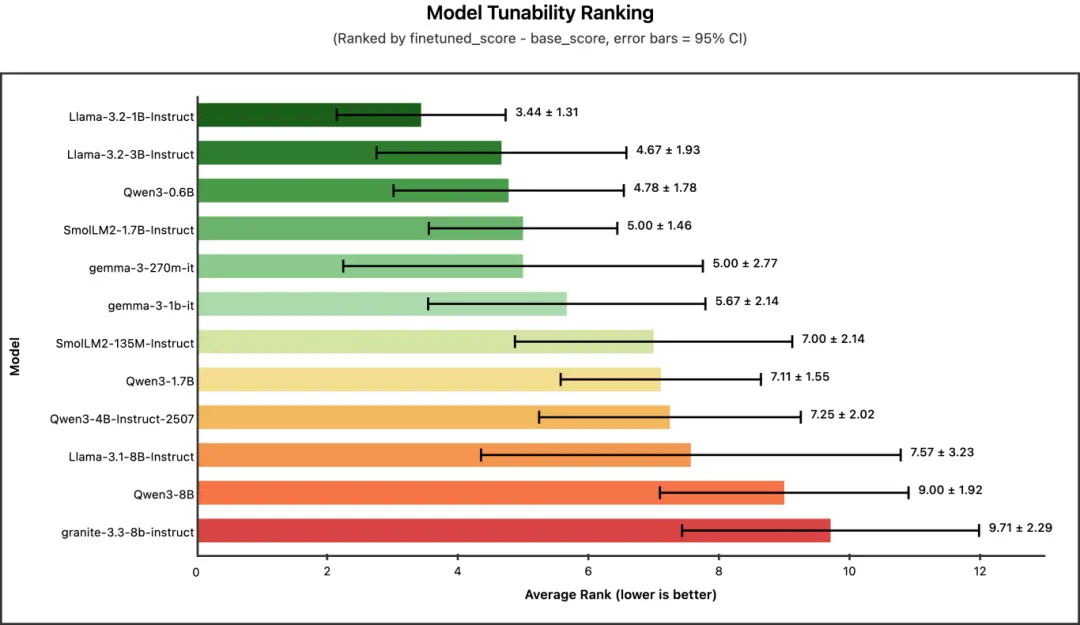
有趣的是,可微調性排名與模型大小的排序正好相反。像 Llama-3.2-1B 和 Qwen3-0.6B 這樣的小型模型,從微調中獲得的提升最大。而規模最大的模型(如 Qwen3-8B、granite-3.3-8b)在可微調性排名中接近墊底 ------ 這並非因為它們表現差,而是因為它們起點相對較高,進步空間相對有限。
核心結論:如果你受限於使用極小的模型(<2B 參數),不必灰心。這些模型從微調中獲益最大,並且能夠顯著縮小與更大模型之間的性能差距。
06 問題三:哪個模型的基礎性能最強?(即未經微調前)
冠軍: Qwen3-8B (平均排名: 1.75)
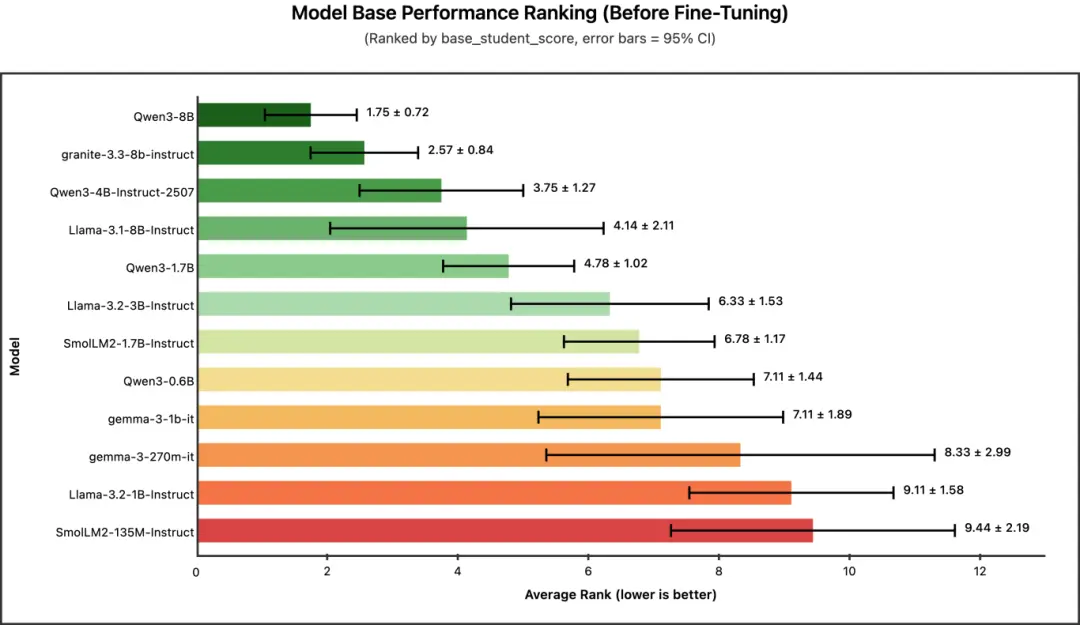
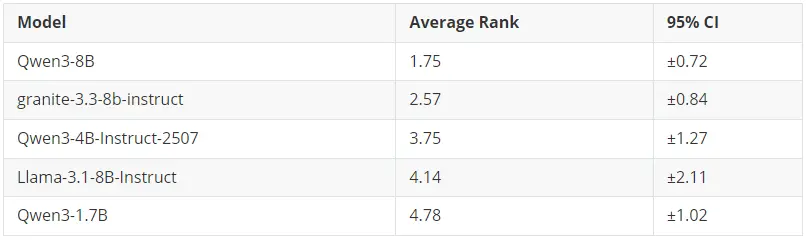
在未經任何微調的情況下,哪個模型開箱即用的表現最好?
正如預期,基礎性能與模型大小呈正相關。8B 模型佔據了榜首位置,其中 Qwen3-8B 在所有基準測試中都展現出非常穩定的性能(標準差最低)。
核心結論:如果你需要在不進行微調的情況下在零樣本/小樣本場景下也獲得較優的性能,大模型仍是你的最佳選擇。但請記住 ------ 經過微調後,這種優勢會減弱。
07 問題四:我們表現最好的學生模型,真的能媲美教師模型嗎?
是的。Qwen3-4B-Instruct-2507 在 8 項基準測試中的 7 項上達到或超越了教師模型。
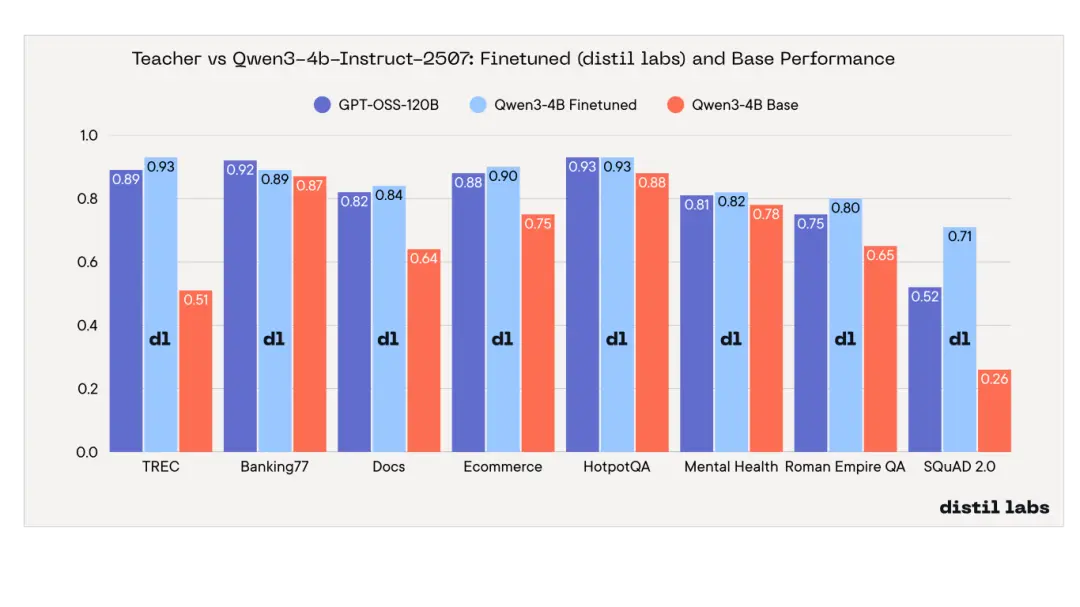
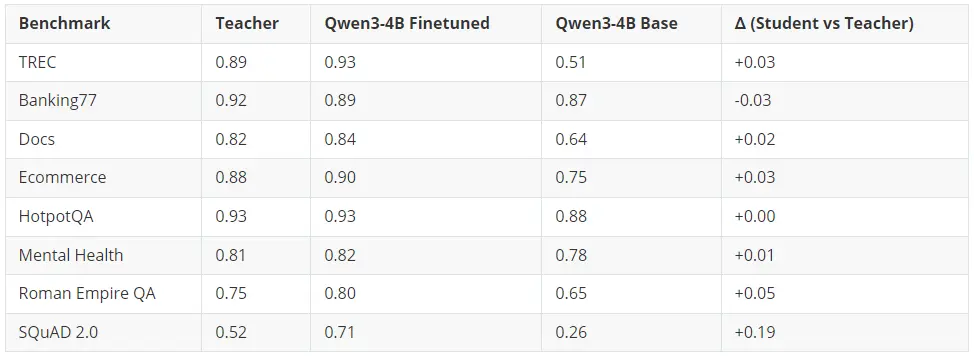
經過微調的 4B 學生模型在 6 項基準測試上超越了 120B+ 參數的教師模型,在 1 項(HotpotQA)上持平,僅在 1 項(Banking77)上略微落後(差距在誤差範圍內)。提升最顯著的是 SQuAD 2.0 閉卷問答任務,學生模型比教師模型高出 19 個百分點 ------ 這充分證明,微調比單純依賴提示詞(prompting)能更有效地將領域知識注入模型。
核心結論:一個經過適當微調的 4B 參數模型,可以媲美甚至超越規模達其 30 倍的模型。這意味着推理成本可降低約 30 倍,並且能夠完全在本地部署運行。
08 實用建議
基於我們的基準測試結果,以下是選擇基礎模型的建議:
09 後續我們將進行的工作
本次基準測試只是一個起點,我們正在積極努力讓這些結果更加可靠:
- 評估更多模型:SLM 領域發展迅速。我們計劃在 Qwen3.5、Phi-4 和 Mistral 系列等新模型版本發佈後及時納入評測。
- 增加運行輪次:目前我們的結果基於有限次數的運行取平均。我們將為每項基準測試增加更多運行輪次,以縮小置信區間,確保排名具有統計可靠性。
- 擴展基準測試覆蓋範圍:我們希望納入更多任務類型,如文本摘要、代碼生成和多輪對話,從而更全面地反映模型能力。
10 訓練細節
每個模型都在使用我們蒸餾流程生成的合成數據進行微調(有關數據合成過程的詳細信息,請參見《Small Expert Agents from 10 Examples》[1])。針對每個基準測試,我們使用教師模型(GPTOss-120B)生成了 10,000 條訓練樣本。
微調採用 distil labs 的默認配置[2]:訓練 4 個 epoch,學習率 5e-5,使用線性學習率調度器,以及 rank 為 64 的 LoRA。
所有模型均使用完全相同的超參數進行訓練。評估在訓練和合成數據生成過程中均未接觸過的預留測試集上進行。
11 結論
並非所有小型模型的性能都差不多,但經過微調後,它們之間的差距會大幅縮小。我們的基準測試表明,Qwen3-4B-Instruct-2507 在整體微調性能上表現最佳,不僅能媲美 120B+ 參數的教師模型,還能在單塊消費級 GPU 上部署運行。在資源極度受限的環境中,像 Llama-3.2-1B 這樣的小模型展現出卓越的可微調性,能夠大幅縮小與大模型的性能差距。
核心結論:微調比基礎模型的選擇更重要。一個經過良好微調的 1B 模型,可以勝過僅靠提示詞(prompting)驅動的 8B 模型。
END
本期互動內容 🍻
❓你在微調小型語言模型時,最看重的是"開箱即用的強基礎能力",還是"微調後巨大的提升空間"?為什麼?
文中鏈接
[1]https://www.distillabs.ai/blog/small-expert-agents-from-10-examples
[2]https://docs.distillabs.ai/how-to/input-preparation/config
原文鏈接:
https://www.distillabs.ai/blog/we-benchmarked-12-small-language-models-across-8-tasks-to-find-the-best-base-model-for-fine-tuning
