谷歌宣佈推出新一代開源醫療 AI 模型 MedGemma 1.5,增強對醫學影像的支持。同時發佈的還有開源醫療語音轉文本模型 MedASR。兩款模型旨在提升臨牀工作流程效率,支持全球開發者和醫療機構免費使用,推動人工智能在醫療領域的應用與發展。
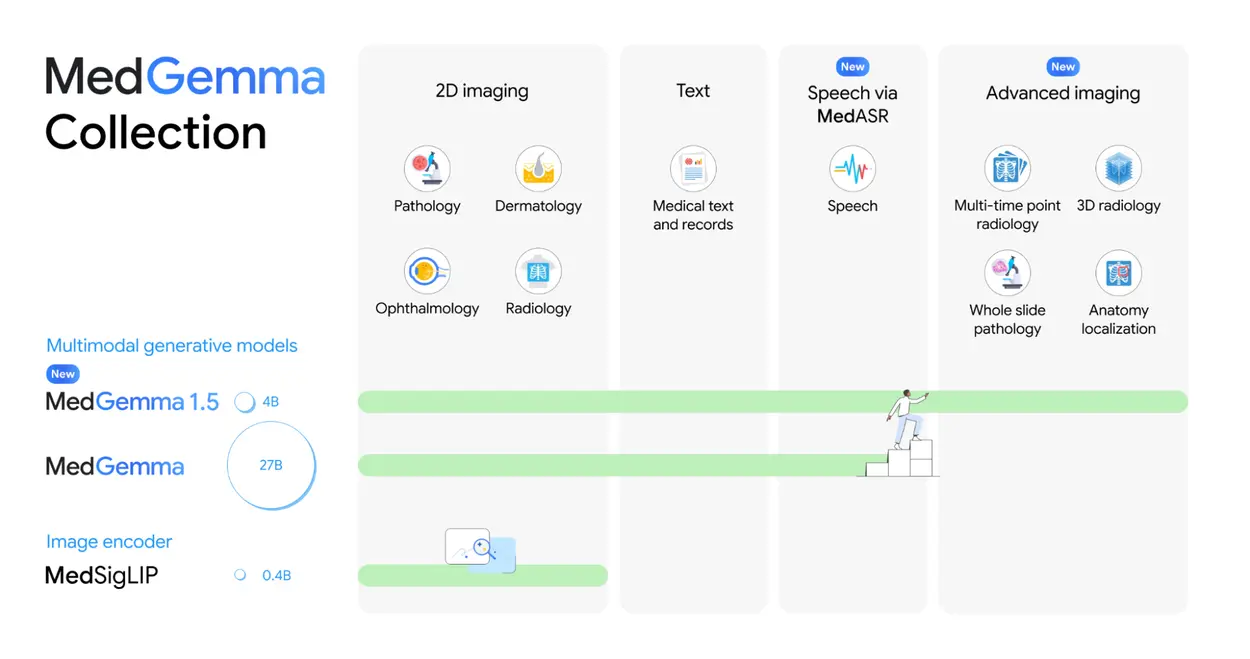
MedGemma 1.5:更強的醫療圖像與文本理解能力
更廣泛的醫療圖像支持
-
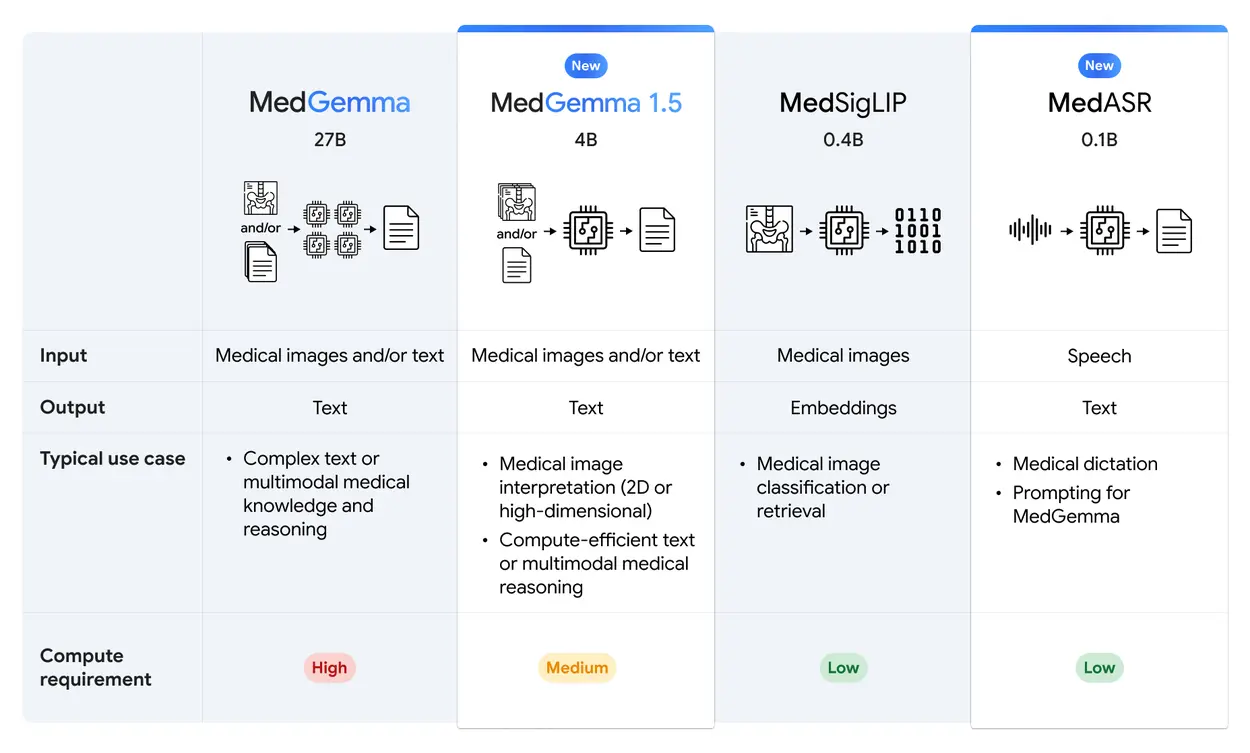
MedGemma 1.5 擴展了對高維醫學影像的支持,包括 CT、MRI 體積數據和整片組織病理圖像;也提升了對胸部 X 光時間序列及解剖標註的理解能力。
-
這是目前首個公開可用、支持三維體積數據與二維圖像同時處理的多模態大型語言模型。
性能顯著提升
內部基準顯示,與前一代相比:
-
CT 相關病變分類準確率提高~3%;MRI 提升~14%。
-
在病理圖像等多個醫學影像任務上表現更穩健。
-
文本能力也更強,在醫學問答(MedQA)和電子病歷問答任務上分別提升了約 5% 和 22%。
支持開發更強大應用
-
MedGemma 1.5 提供了更好的 DICOM 支持,便於與臨牀影像系統無縫對接。
-
模型保持開源,開發者可在 Hugging Face 與 Google Cloud Vertex AI 上使用與擴展。

MedASR:為醫療場景定製的語音識別模型
谷歌同時發佈了 MedASR,一款針對醫學口述語音特別訓練的 自動語音識別(ASR)模型:
-
相比通用語音識別模型(如 Whisper large-v3),MedASR 在醫療口述轉寫上的錯誤率大幅下降,在胸片報告語音轉寫上錯誤率減少約 58%。
-
MedASR 可用於實時醫囑記錄、臨牀對話轉寫,甚至作為觸發 MedGemma 推理的語音接口。
-
與 MedGemma 配合,構建 “聽 — 理解 — 寫” 的醫療 AI 工作流更為自然。
詳細內容查看:https://research.google/blog/next-generation-medical-image-interpretation-with-medgemma-15-and-medical-speech-to-text-with-medasr/
