美團質效技術部聯合復旦大學周揚帆教授團隊推出KuiTest——零規則UI功能性異常測試工具。KuiTest通過將“人類預期”直接用作Test Oracle,解決了長期以來UI測試Oracle泛化性差的自動化痛點。實驗表明,KuiTest異常召回率達86%,誤報率僅1.2%,已在執行21萬+測試用例,發現百餘例有效缺陷,大幅降低人工成本並提升測試覆蓋率。

1 背景
近來,隨着 App 的功能愈發複雜,UI(用户界面)的交互邏輯也隨之多樣化。為了保障用户體驗,針對 UI 的功能測試一直是質量保障中的重要環節。傳統的 UI 功能測試往往依賴於人工編寫的測試腳本或規則體系:通過手動編寫校驗邏輯來驗證交互是否正確。這種方式雖然精確,但成本高昂,維護困難。
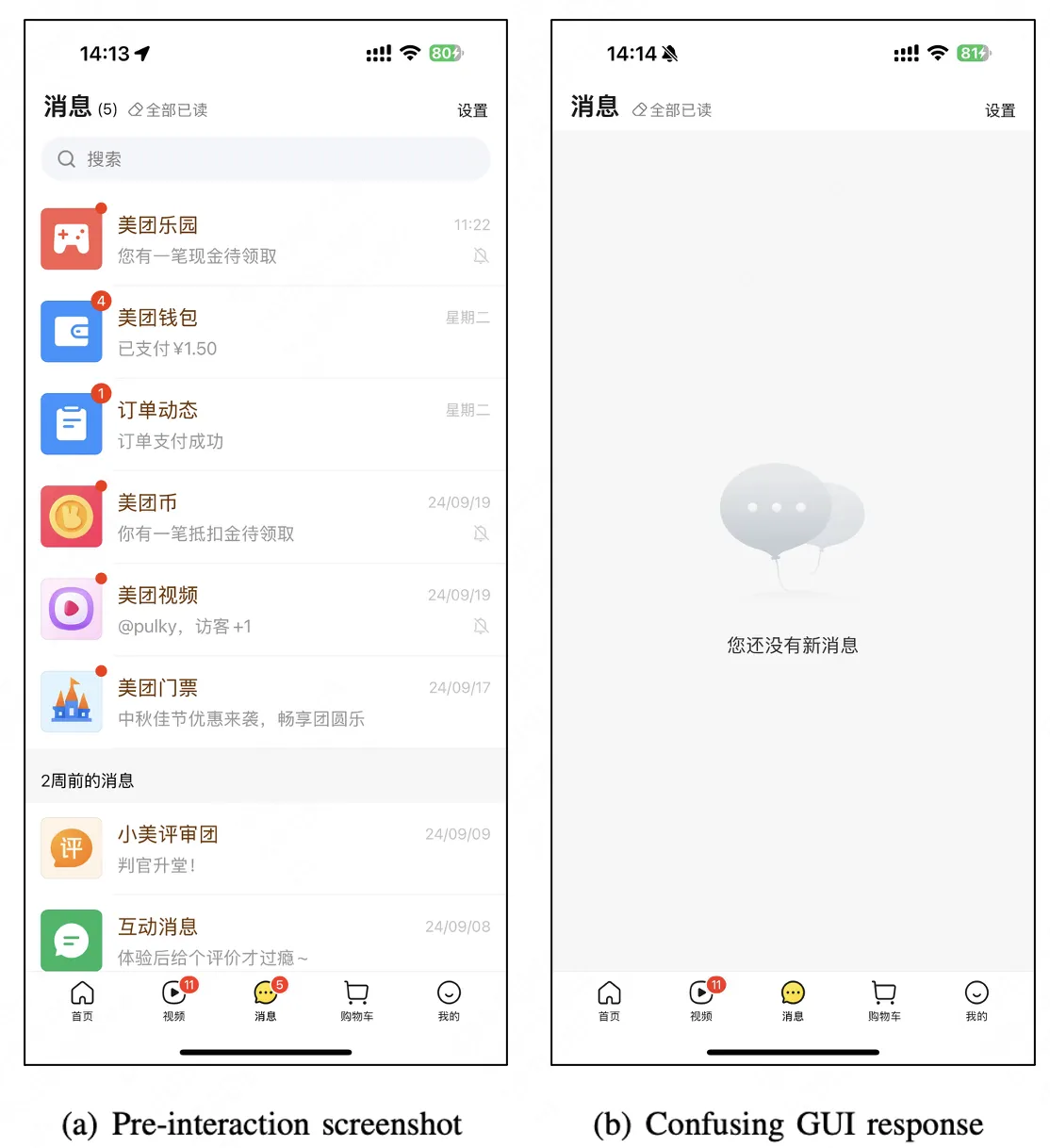
對美團而言, 一個 App 就有可能包含上千種 UI 界面、數萬個交互操作。隨着業務快速迭代、界面頻繁調整、底層平台(如 Android、iOS、HarmonyOS NEXT)的更新,基於規則的測試腳本常常失效。每當腳本失效,測試工程師都需要花費大量時間重新綁定元素、修復規則腳本,極大地提升了測試自動化的開銷。此外,當下的 UI 功能缺陷通常並不表現為崩潰,而是更復雜的響應邏輯異常:例如圖 1 中點擊“全部已讀”卻清空了消息列表等。這類問題嚴重影響用户體驗,但難以通過簡單規則概括,限制了傳統 UI 測試自動化的覆蓋率與效率。
考慮到 UI 功能缺陷雖表現各異,但共性是 App 的響應偏離用户預期。因此,若能實現對用户預期的模擬,就能以此作為測試準則(Oracle)、自動化的檢測 UI 功能性異常。即無需人工逐頁面編寫規則,從而大幅提升自動化的程度與測試覆蓋率。由於大語言模型(LLM)經過海量通用知識訓練,具備一定的模擬人類常識與預期的能力,恰好契合模擬用户預期的需求,且無需針對特定應用 / 功能單獨適配,天然具備泛化性。因此,通過分析 UI 功能缺陷的共性,我們提出了一個全新的思路:能否基於大模型理解“人類對 UI 交互的常識預期”,並以此自動判斷交互是否正確?
基於這一理念,我們與復旦大學計算與智能創新學院 周揚帆教授團隊 展開聯合研究,設計並實現了 KuiTest —— 一套基於 大眾通識 的 無規則(Rule-free)UI 功能測試系統。KuiTest 能夠像人一樣,理解按鈕、圖標等交互組件的含義,預測點擊後的合理結果,並據此自動校驗實際界面反饋是否符合預期,從而在無需手工腳本的情況下完成功能測試。該工作已在美團 App 的多個業務中落地應用,併產出論文《KuiTest: Leveraging Knowledge in the Wild as GUI Testing Oracle for Mobile Apps》,已被國際頂級軟件工程會議 ICSE 2025(CCF-A 類會議)的 Software In Practice Track(軟件工程應用實踐)收錄。
2. 設計思路與實現過程
2.1 總體流程
KuiTest 的核心是檢查 UI 交互後的響應是否符合一般用户的 常識性預期,其中:識別交互組件的功能和常識性預期生成是需要兩項關鍵能力。考慮到通用大模型具備圖文理解能力且從海量的訓練數據中習得了常識性推理能力,因此天然地適合模擬大眾的認知和交互預期。至此,KuiTest 的核心挑戰是提升大模型在執行 UI 功能測試的 性能和可靠性。考慮到通用大模型通常並未接受過 UI 測試領域數據的訓練,因此缺少 UI 認知與測試的經驗,直接讓它識別 UI 功能和缺陷是十分困難的。所以我們借鑑人工測試的操作流程,將測試流程拆分以降低 LLM 的任務難度:
- 可交互組件功能識別:理解每個可交互組件(如按鈕、圖標)的功能含義、預測交互後的響應。
- 交互響應驗證:在執行交互後,驗證界面響應是否符合預期。
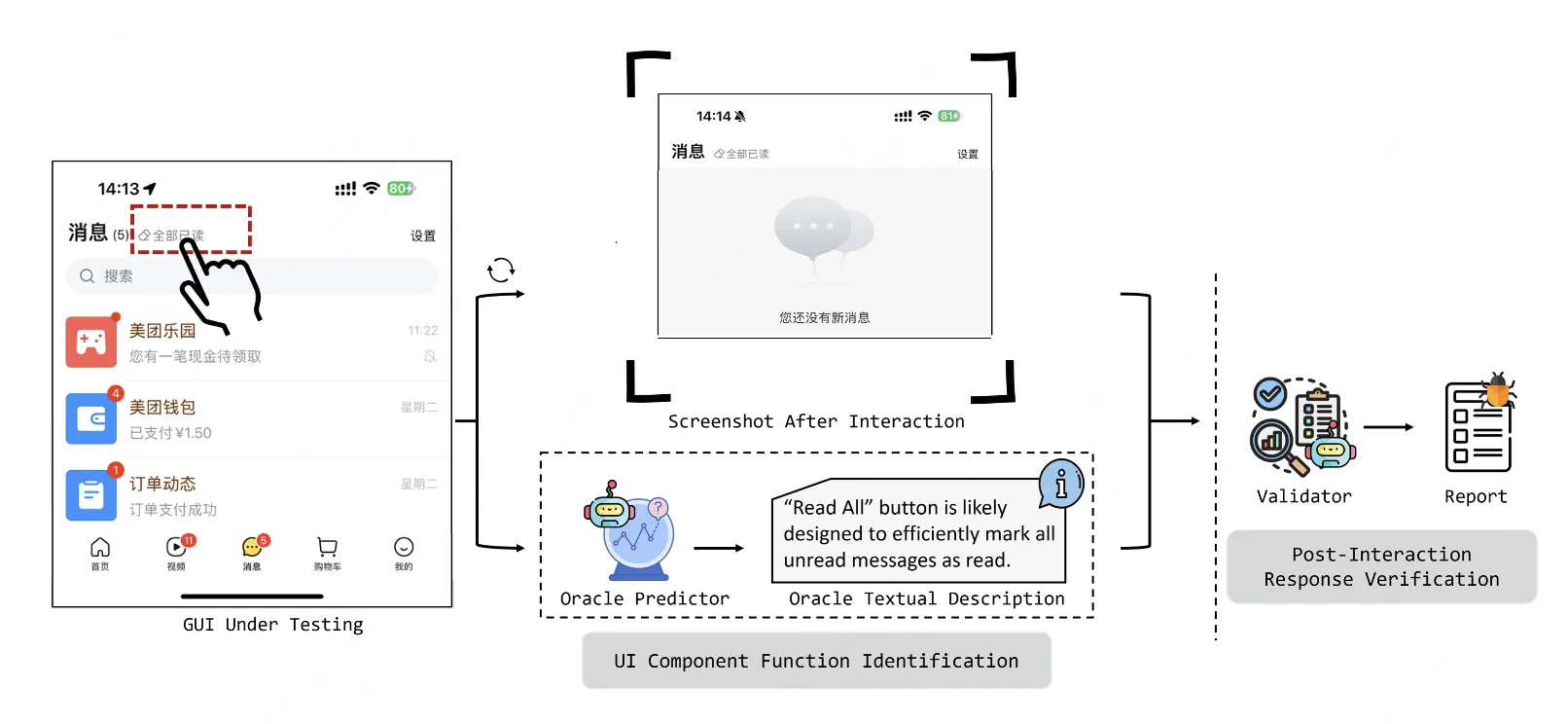
具體來説,如上圖 2 所示,在測試開始時,首先選擇需要交互的組件,KuiTest 會基於 GUI 截圖分析和組件庫匹配獲取該組件的功能,並預測與之交互後的 UI 響應;隨後執行交互,根據組件的預期功能以及交互後的頁面信息判斷實際響應是否符合預期。
2.2 UI 組件功能識別
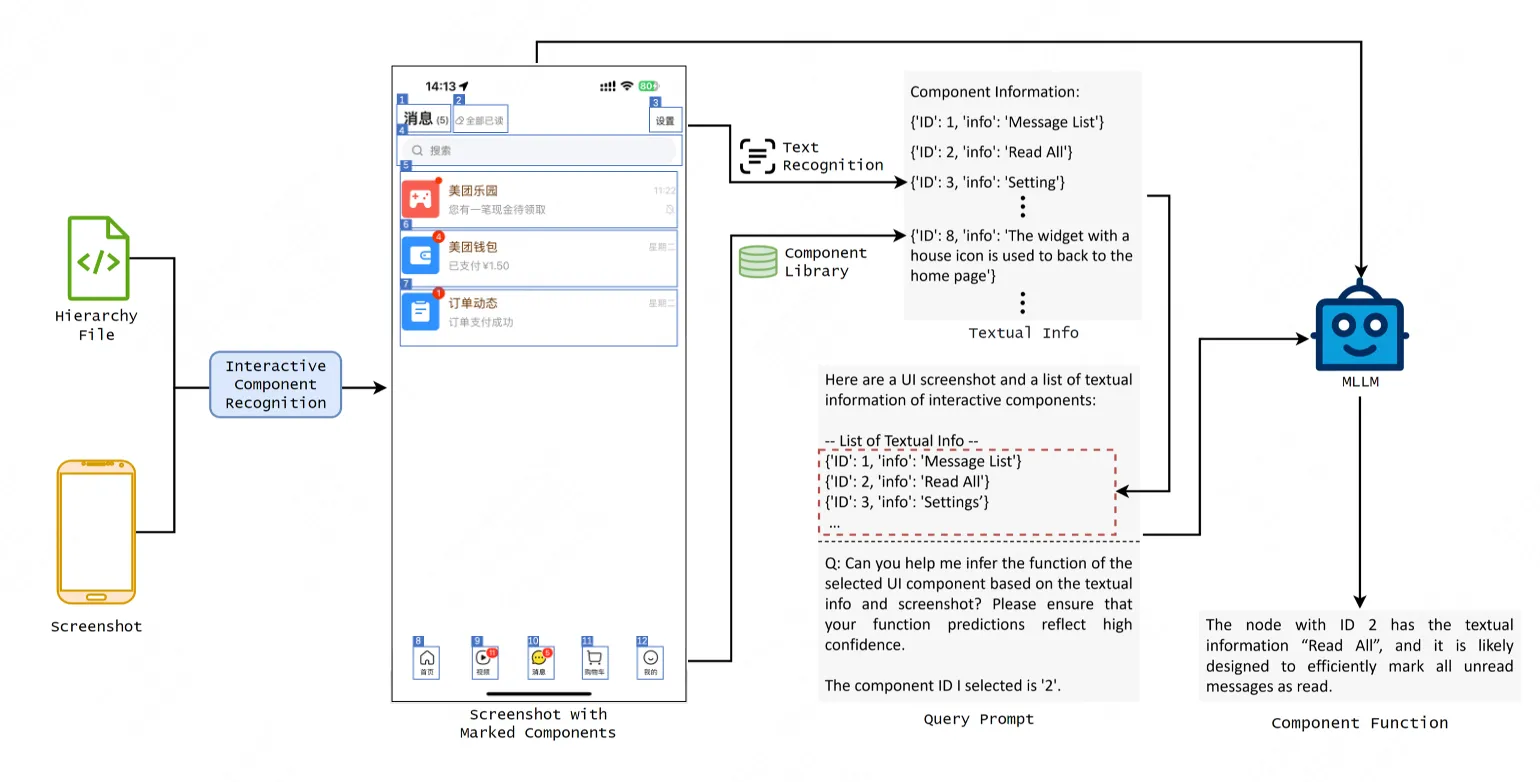
為了提升大模型預測 UI 組件功能的可靠性,KuiTest 整合了多種 UI 頁面相關信息輸入:首先,我們獲取結構化組件樹並結合 Vision-UI 模型<sup>[1]</sup>從截圖中識別所有可交互組件,再用 SoM(Set-of-Mark)策略<sup>[2]</sup>為每個組件添加 bounding box 標記並分配唯一 ID,形成帶標記的 UI 截圖,讓大模型能快速分辨圖中存在的 UI 組件。接着,針對有文本的組件,通過 OCR 提取文字內容並按“組件 ID - 文本”結構化整理;針對無文本的圖標類組件,則利用 CLIP(Contrastive Language–Image Pre-training)模型<sup>[3]</sup>從積累的圖標庫(含歷史識別失敗圖標及人工標註的功能描述)中檢索相似圖標,如果存在相似圖標,則將庫中圖標的功能信息補充至輸入來輔助大模型理解組件。最後,將上述所有信息整合進 Prompt,讓大模型識別指定組件的功能,並預測交互後 UI 界面的響應。這一過程有效緩解了通用多模態大模型 UI 視覺信息理解薄弱的瓶頸,併為後續交互驗證提供 Oracle。
2.3 交互響應驗證
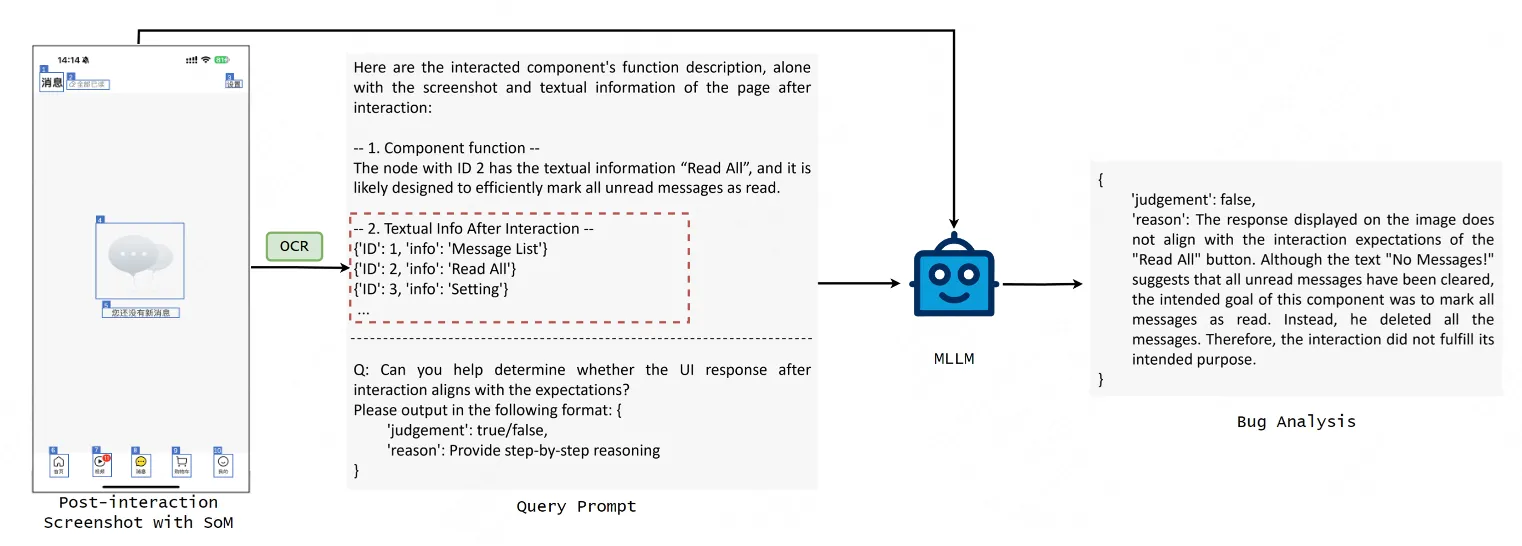
交互後響應驗證是 KuiTest 判斷 UI 功能是否存在 Bug 的核心環節,流程分為狀態比對和 LLM 決策兩步:KuiTest 在模擬用户交互後,先通過像素對比判斷交互前後 UI 是否有視覺變化,若無變化則直接標記為 “UI 交互無響應”;若有變化,則讓多模態模型判斷實際 UI 響應是否符合前述預測。至此,KuiTest 完成了從 UI 功能語義測試到通用推理能力任務的轉換,既規避了傳統基於規則測試繁雜的開發和維護成本,也提升了大模型在 UI 測試領域的決策的可靠性,降低誤報率。
3. 實驗測試
KuiTest 的實驗設計以驗證其對解決工業級 UI 功能的測試能力為核心,在美團實際場景中篩選真實數據構造數據集,並且設計針對性基線對比方案。在驗證技術有效性的同時為業務落地提供數據支撐,下文將繼續介紹實驗設計、設置以及結果分析。
3.1 實驗設計
實驗圍繞三個關鍵問題(RQ)進行,目標是驗證 KuiTest 設計的有效性與合理性,以及是否滿足工業落地要求。針對 LLM 在 UI 理解領域能力不足的問題,設置 RQ1 從誤報率和成本的角度驗證任務分解(拆分為 “組件功能識別 + 交互後響應驗證”)的綜合性能。此外,設置 RQ2 評估多模態輸入 + 圖標庫的方案是否能提高 LLM 的組件識別能力。最後,針對工業場景對 “高召回、低誤報” 的剛需,設置 RQ3 驗證 KuiTest 在美團 App 中的落地能力,重點評估決定缺陷覆蓋度的召回率以及直接影響人工排查成本的誤報率。
3.2 實驗數據與對照方法
實驗使用的基準數據集自美團的核心業務線(外賣、酒店、旅行等),這些業務線的 UI 風格、交互規則均有差異,因此具備對真實的工業測試場景的代表性。具體而言,RQ1 數據集含 150 個 UI 交互操作(25 個歷史 Bug+125 個正常用例),bug 比例 16.7%,對應新功能測試場景;RQ2 數據集涵蓋 250 個可交互 UI 組件(含文本與無文本類型),確保組件多樣性;RQ3 數據集含 100 個真實 UI 頁面(4664 個組件、150 個注入 Bug),Bug 佔比僅 3.2%,與工業場景 Bug 稀疏的實際情況一致。

我們為各實驗設置了基線方法作為對照:RQ1 設無分解(直接讓大模型判斷)與三步分解(單獨提取交互後頁面語義)對照,前者驗證是否需要分解,後者驗證分解步數合理性;RQ2 設純 LLM(僅截圖)、圖片 + 文本(無圖標庫)、SoM + 文本(無圖標庫)對照,分別驗證文本信息、組件標記以及圖標庫的價值,排除單一變量干擾;RQ3 雖無外部工具對照,但通過覆蓋美團內 10 種業務線,以驗證 KuiTest 的現實泛化性。
3.3 實驗結果
RQ1:任務分解的合理性
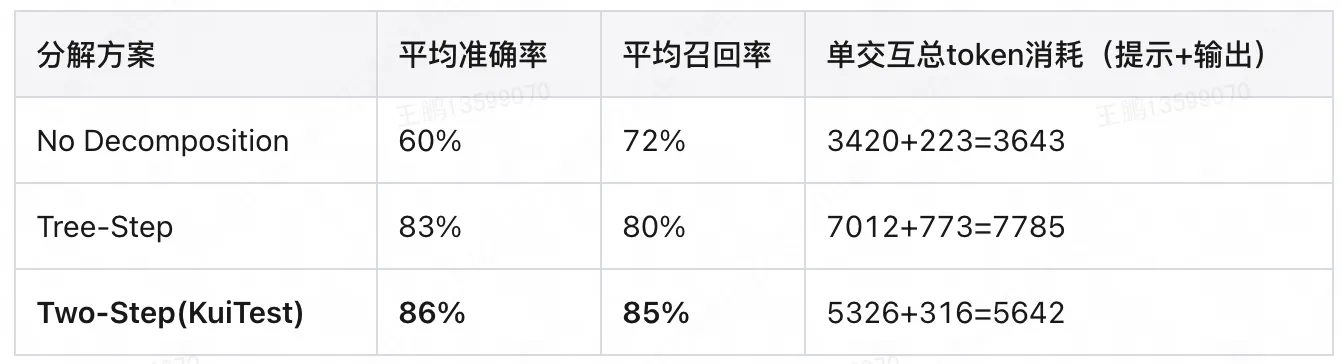
任務分解對比結果顯示,有分解的方案比無分解的方案在準確率和召回率上都有明顯提高,並且 KuiTest 的兩步分解方案(組件識別 + 響應驗證)表現最優:平均準確率 86%、召回率 85%。
這一結果印證了任務分解合理性。對於三步分解的方案效果會略差於兩步分解的結果,我們分析發現三步分解額外語義提取步驟,雖能提升頁面類型理解,但會讓 LLM 忽略圖標顏色變化等細節,導致非跳轉類 UI 功能 Bug 漏檢(如點擊收藏按鈕後按鈕應該從空心變為實心),且增加計算成本。這説明分解並非步驟越多越好,需貼合大模型能力邊界,找到可靠性和效率平衡點,而兩步分解恰好成為實現這一目標的最優解。
RQ2:組件功能識別的有效性
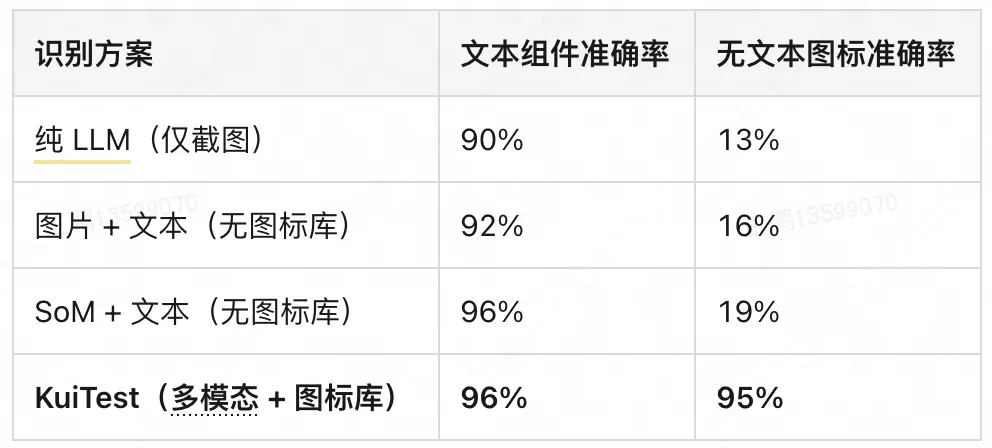
組件功能識別結果顯示,KuiTest 方案的平均識別準確率達 95.5%,其中文本組件準確率 96%,無文本圖標準確率 95%;而對照方案中,純 LLM 的無文本圖標準確率僅 13%,圖片 + 文本和 SoM + 文本的方案准確率也未突破 20%。
這一數據表明對 UI 圖像進行標記以及對 UI 組件語義信息的額外補充,能夠顯著提高 LLM 的 UI 組件功能識別能力。LLM 視覺理解能力薄弱,純截圖輸入無法識別無文本圖標,而 OCR 文本 + 組件標記能補充組件的文本語義,提升文本組件識別準確率。藉助圖標庫為無文本組件補充功能描述,直接將其識別準確率從 13% 提升至 95%。並且這一圖標庫並不是全量的,説明僅通過業務線常用圖標即可覆蓋大部分場景,兼顧準確性與成本。
RQ3:對於真實 UI 功能異常識別的有效性

在美團 10 大業務線的真實場景測試中,KuiTest 整體召回率 86%、精確率 71%、誤報率 1.2%,且各業務線表現穩定。這些實驗結果表明 KuiTest 具備實際落地能力。86% 的召回率意味着能覆蓋絕大多數真實 UI 功能 bug,避免漏檢關鍵缺陷。1.2% 的誤報率有效避免導致測試工程師進行無效排查,大幅降低人工成本。71% 的精確率雖看似不高,但因實驗中 Bug 佔比僅 3.2%(與真實場景一致),在 Bug 稀疏環境下已屬優秀。實驗結果證明了 KuiTest 在真實測試場景中能平衡覆蓋度與準確性。
4. 應用效果
目前,KuiTest 已在美團的多類業務場景中落地應用,過去 6 個月有 20 個業務方向使用,總執行 21 萬+Cases、8000 多個 Jobs,近期周均觸發 5000 多個 Cases;在多個實測項目如鴻蒙適配、神會員地理傳參巡檢、酒店商家多語言適配等,KuiTest 發現了百餘例有效的 UI 功能缺陷。
4.1 HarmonyOS NEXT 平台遍歷
傳統的 GUI 測試腳本的設計依賴於 App 的 UI 邏輯,但是不同操作系統上同一 App 的有所差異,這種差異會導致在一個系統上設計的腳本在另一個系統上失效,因此使得跨平台的測試十分困難,需要測試人員手動調整甚至重新設計測試腳本,適配成本較大。
美團 App 在 Android/iOS 平台的測試腳本較為完善,但是在 HarmonyOS NEXT 平台的測試腳本仍在完善之中,大量頁面仍處於未測試狀態。因此,KuiTest 被率先部署於該平台的穩定性巡檢中,根據指定業務起始頁面,自動地進行跨頁面遍歷,識別並驗證崩潰、報錯、功能不符合預期的情況,以減少重新設計測試腳本的成本。
項目中覆蓋首批適配的 3 項業務,項目交付週期總體累計運行 1230 小時、共 4 萬+個自動化測試用例,發現 34 個有效異常。
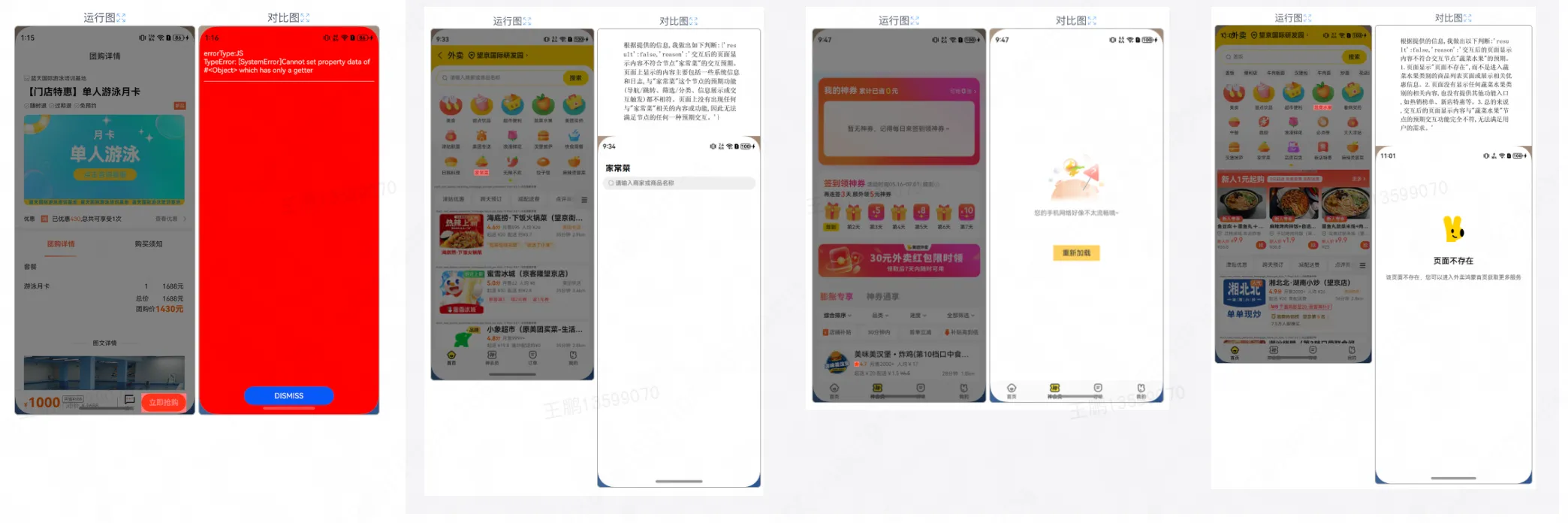
4.2 大前端迴歸巡檢
由於美團 App 的更新速度十分快速,因此每週都需要進行迴歸巡檢。傳統的測試腳本的方法由於人力消耗過大,往往只能覆蓋 App 中的核心業務區域,但是其他區域的 Bug 實際也會影響用户體驗。而 KuiTest 能夠測試一張頁面的所有可交互組件,以一種低成本的方式提高測試覆蓋率。因此,我們將 KuiTest 運用在美團的大前端迴歸巡檢當中:截至目前,KuiTest 已經超一年穩定運行,累計檢測出了 140+有效異常。
5. 認知與展望
KuiTest 作為無規則的移動應用 GUI 功能測試工具,標誌着軟件測試領域向智能化、自動化方向邁出的探索一步。該工具通過合理的任務拆解與多模態 UI 組件功能識別將大模型通識作為測試預言,利用其廣泛的知識模擬用户期望,成功突破了傳統基於規則測試方法的侷限性,切實提升了 LLM 在 GUI 測試場景中的可靠性和實用性。
當前 KuiTest 主要聚焦於單步交互的功能驗證,這是出於對測試可靠性和效率的權衡考慮。然而,向多步交互場景擴展是一個自然且必要的發展趨勢,真實用户場景中存在大量需要多步操作才能觸發的複雜功能 bug,例如,在執行操作序列“查看訂單列表 → 點擊 "待付款" 訂單 → 選擇退款 → 確認退款原因”時發現點擊“待付款”後,頁面卻顯示“退款訂單”。
未來研究應當探索如何將測試能力擴展到長鏈路交互場景。針對長鏈路 Bug 分析,需要建立狀態追蹤機制來記錄每一步交互後的 UI 狀態變化,通過對比預期狀態與實際狀態的差異來識別異常節點,同時利用 LLM 的推理能力建立操作步驟之間的因果關係鏈,當檢測到功能異常時能夠回溯定位是哪一步操作導致了錯誤,這種因果推斷能力對於複雜交互序列中的 Bug 定位至關重要。同時,可以引入基於歷史 Bug 數據的學習機制, 分析過往發現的長鏈路 Bug 模式,自動生成類似的高風險測試路徑,優先探索容易出現問題的操作序列組合。這種智能化的路徑生成不僅能提高測試效率,還能顯著提升對複雜功能 Bug 的檢測能力。
6. 合作方簡介
復旦大學周揚帆教授團隊致力於新型軟件系統的性能優化與故障排查研究,近年團隊在軟件系統領域的重要會議如 OSDI、SOSP、ICSE、FSE 等發表了多篇高影響力論文。最近,該團隊以解決 UI 自動化測試中的複雜問題為核心,將大模型應用於 UI 功能認知與 UI 交互規劃,以一系列創新方法顯著提高了解決方案的適應性和穩定性。團隊注重科研成果的實際應用,積極與企業及相關機構合作,共建實用工具和系統,推動研究成果的落地,助力合作伙伴提升技術能力並實現業務價值。
註釋
- [1] vision-ui 模型:美團視覺 UI 分析工具
- [2] SoM(Set-of-Mark)策略:Yang J, Zhang H, Li F, et al. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v [J]. arXiv preprint arXiv: 2310.11441, 2023.
- [3] CLIP(Contrastive Language–Image Pre-training)模型:Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision [C]//International conference on machine learning. PMLR, 2021: 8748-8763.
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。
