導語 | 隨着人工智能技術的迅速發展,基於大語言模型(LLMs)的應用逐漸成為主流。然而,這些大模型在實際應用中仍像在“閉卷考試”,一旦題目超綱便只能憑空編造,即便後來引入 RAG 讓其“開卷”,也常因翻不到正確的頁碼而答非所問。尤其在垂直領域的應用中,單純依靠大模型往往無法滿足複雜業務對精準問答、實時知識更新和推理深度的需求。因此,技術正從 RAG (Retrieval Augmented Generation, 檢索增強生成) 走向 KAG (Knowledge Augmented Generation,知識增強生成框架) :通過整合知識庫與結構化推理,讓“開卷”不僅翻得到頁,還能按邏輯劃重點。本文特邀同濟大學特聘研究員、博導、騰訊雲 TVP 王昊奮重點探討從 RAG 到 KAG 的技術演進過程,並分析 KAG 框架如何有效解決傳統 RAG 模型的不足,為垂直領域應用提供更加精準和高效的解決方案。
作者簡介

王昊奮,同濟大學特聘研究員、博導、騰訊雲 TVP。研究方向包括知識圖譜、自然語言處理、對話機器人等。長期在一線人工智能公司擔任 CTO 之職。是全球最大的中文開放知識圖譜聯盟 OpenKG 發起人之一。負責主持多項國家級和上海市 AI 相關項目,發表 100 餘篇 AI 領域高水平論文,谷歌學術引用 7550 餘次,H-index 達到 31。構建了全球首個可交互養成的虛擬偶像—“琥珀·虛顏”;所構建的智能客服機器人已累計服務用户超過 10 億人次。目前擔任中國計算機學會術語工委副主任,SIGKG 主席,上海秘書長,中國中文信息學會理事,語言與知識計算專委會副秘書長,上海市計算機學會自然語言處理專委會副主任,上海交通大學 AI 校友會秘書長等社會職位。
一、從“閉卷”到“開卷”:大模型能力的轉變
在大模型的實際應用中,通常依賴於兩個核心功能:一是聯網搜索,二是深度思考。這兩者在技術邏輯上互為補充:搜索功能能夠提供實時的知識更新,而思考功能則確保了邏輯的嚴謹性。然而,當大模型應用於垂直領域時,常常面臨以下五大痛點:
- 幻覺生成:模型因參數化知識不足而編造虛假信息;
- 知識滯後:預訓練數據無法覆蓋最新政策、市場動態;
- 效率瓶頸:複雜問題需要多輪檢索與推理,響應時間過長;
- 領域適配難:行業術語、規則體系與通用模型存在語義斷層;
- 推理脆弱性:多步推理中易因知識缺失或邏輯斷點導致結果偏差。
這些痛點的根本原因在於,模型從“閉卷考試”(依賴內在知識)向“開卷考試”(藉助外部信息)轉型時,能力出現了斷層。無論是在搜索、推薦、問答還是對話等場景中,核心需求可以歸納為兩點:首先是輸出精準可靠,其次是能夠與內部大數據系統進行深度對接。用户習慣使用 AI 搜索也反映了這一需求:雖然 AI 搜索引用的來源可能存在虛假信息,但其提供的“證據鏈”能夠增強用户的信任感。同時,用户還希望技術成本可控,並確保數據的安全性與隱私保護。
為應對這些挑戰,目前的技術探索趨向於通過外掛知識庫(如 RAG)來彌補大模型本身的不足。儘管 RAG 技術已從最初的基礎 RAG 發展到具備自主決策能力的 Agentic RAG,但在實際應用中仍然面臨挑戰。即便引入了 RAG,當大模型遇到預訓練數據未覆蓋的最新或特定領域問題時(例如政策法規中的“關税”細節,見下圖),其表現依舊可能無法令人滿意。
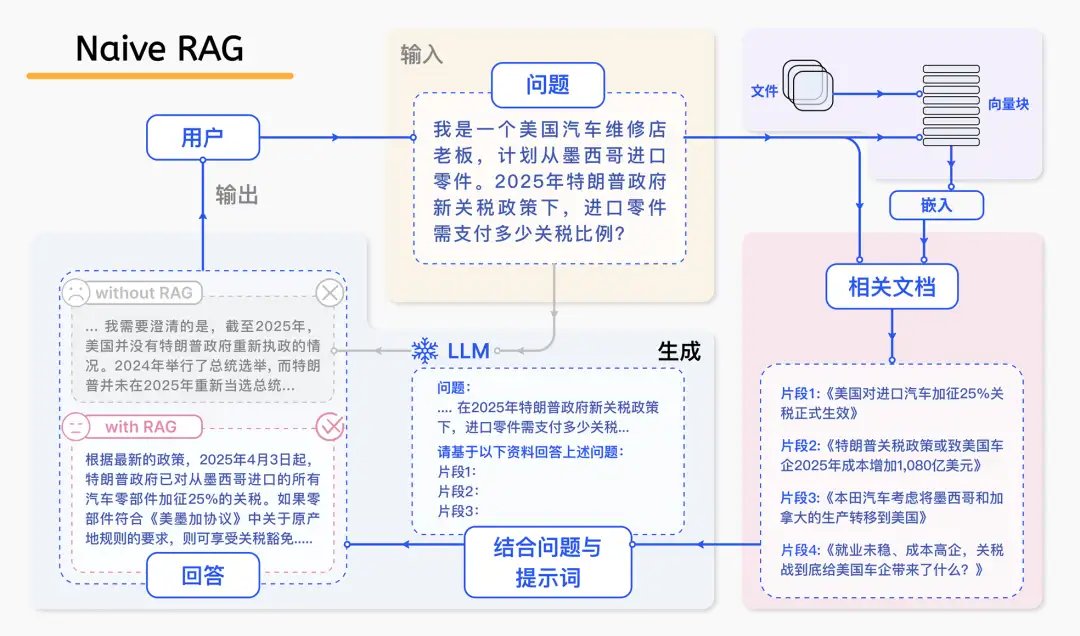
關税問題示例:Naive RAG 模型
在這一過程中,可以提煉出一個基本框架:通過為大模型提供大量額外的相關知識,使其能力從依賴有限內在知識的“閉卷考試”模式,轉變為能夠參考外部信息的“開卷考試”模式。舉例來説,解讀特定問題時,可以提供詳盡的關税細則、適用條款和豁免情況等詳細信息,幫助模型更準確地進行判斷和推理。
這一轉變的關鍵在於賦予模型深度閲讀理解的能力。通過引入外部知識庫,模型不僅可以獲取更多的背景信息,還能在生成回答時,依據實時和特定領域的數據做出更合理的決策。這種能力使得大模型在面對複雜問題時,能夠在保持邏輯嚴謹性的同時,彌補內在知識的不足。
二、RAG的進化:當檢索開始會“思考”
隨着技術的不斷進步,RAG 模型逐漸與推理技術相結合,形成了更為強大的推理增強 RAG(Reasoning-Augmented RAG)模型。這一技術突破為人工智能在複雜任務中的應用提供了新的發展機遇,尤其是在垂直領域的實際落地中,展現出了巨大的潛力。
RAG與推理的結合的發展階段
RAG 與推理的結合經歷了兩個關鍵的歷史性階段:第一個階段由 OpenAI 推出的 o1 模型開啓,o1 的出現標誌着訓練時擴展(train time scaling)到推理時擴展(inference time scaling)的轉變。這一進步使得自動化思維鏈成為可能,並能夠通過思考過程提供更精確的回答。第二個階段出現在今年年初,DeepSeek-R1 的發佈進一步推動了技術的發展,特別是DeepSeek-R1 採用的開源策略,以及其創新的輕量、高效且可控的 GRPO(Group Relative Policy Optimization)強化學習方法,為該領域注入了新的活力。
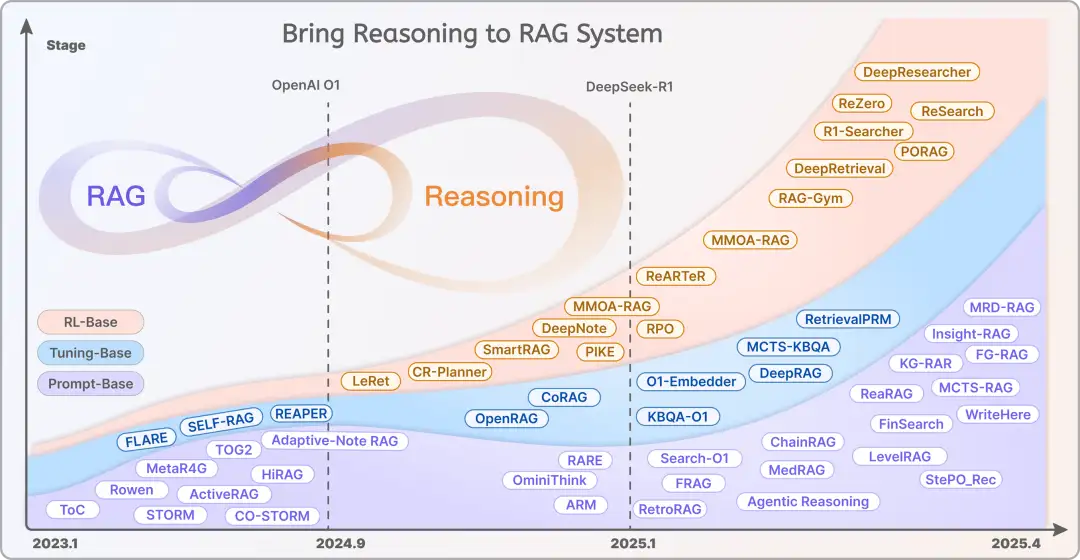
將推理引入 RAG
隨着 OpenAI o1 和 DeepSeek-R1 等慢思考模型的興起,RAG 與推理能力結合的研究逐漸增多,促進了 RAG 技術在垂直領域的落地和發展。在這一過程中,技術創新不僅涵蓋了最輕量級的提示工程(Prompt Engineering)和微調方法(Fine Tuning),更重要的是基於強化學習(Reinforcement Learning,RL)的方法,特別是在 DeepSeek-R1 發佈之後,這類方法變得愈加普及和廣泛應用(例如上圖橙色區域)。
RAG與推理能力結合的價值
RAG 與推理能力結合的價值,可以從以下兩個互補的視角來進行深入分析:
● 彌補現有 RAG 的不足,引入推理增強檢索:通過引入推理能力,可以在檢索過程中增強推理效果,解決 RAG(尤其是Agentic RAG)在複雜問題解析中的痛點。例如,跨文檔協同困難、跨內容檢索不連貫、以及效率與精度之間的難以平衡等問題,都能通過推理增強得到有效解決。
● 從大模型自身需求出發,市場主流大模型均內置聯網搜索功能:這一設計本質上是在推理過程中對檢索的增強。在多步推理過程中,大模型可能因缺乏實時知識而導致推理斷層,因規則缺失而產生邊界模糊,或因搜索空間爆炸而陷入局部優化。通過動態檢索外部知識,可以有效平衡推理的深度與廣度,避免知識滯後或規則缺失引發的推理斷裂,從而為技術優化提供新的路徑。
通過這兩種視角的結合,我們不僅能夠提升 RAG 技術的應用效果,還能更好地應對實際應用中的各種挑戰,促進 AI 技術在更多領域的落地實施。
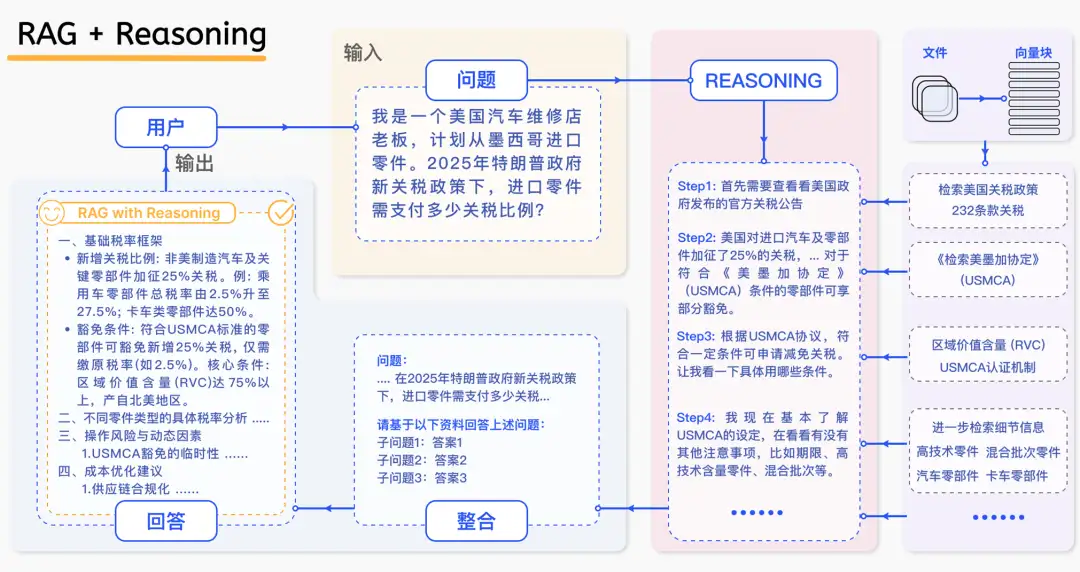
關税問題示例:RAG+Reasoning 模型
RAG 與推理的融合,本質上是一個動態任務規劃與執行的過程。它將複雜問題系統性地拆解為多個子任務,如理解、分解、檢索、驗證與整合,從而形成一條邏輯自洽的推理鏈。在上圖關税案例中,傳統 RAG 模型可能會直接拼接多個信息片段,生成一個籠統的回答。而 RAG + Reasoning 模型則會採取更為精細的步驟:首先理解問題結構,然後分解子問題,進行多輪檢索與交叉驗證,最終綜合推理並生成建議。這種方法使得結果不僅僅是信息的簡單堆砌,而是一份結構清晰、邏輯嚴密、並具備實用價值的專業建議。
三、RAG技術的核心問題與技術演進路徑
對於企業用户(To B)來説,RAG 技術的核心在於:輸入內容通常是企業內部的私有文檔和數據,而輸出則主要服務於兩類任務——專業領域的問答服務和智能寫作輔助,這兩類應用在實際業務場景中具有重要價值。隨着 DeepSeek 等大模型技術的落地應用,尤其是通過一體機形式部署後,企業對 RAG 提出了“既要又要還要”的需求。具體表現為對知識的精準性和完備性要求,其次是對邏輯嚴謹性的需求,再者,大模型在處理時間和數值等方面仍存在提升空間。隨着這一過程的深入,用户逐漸建立了從離線索引到在線檢索推理與生成的完整流程,實現了更高效的信息處理與知識生成。
在大模型的實際應用過程中,面臨一些亟待解決的問題。這些問題一方面源自自迴歸模型固有的限制,另一方面也與我們對技術的高期望存在差距,尤其是在技術的成熟度尚需進一步提升的背景下。以下是一些常見的挑戰:
- 錯誤定性或錯誤邏輯
- 事實性錯誤或無依據
- 時間、數值不敏感
- 張冠李戴
- 不能區分重要性
- 語義不精準
- 召回不完備
這些問題的存在,反映了目前大模型在某些特定任務中的侷限性。隨着技術的不斷髮展,解決這些問題將是提升大模型應用效果和可靠性的關鍵。
通過對 RAG 系統的深度剖析,可歸納出三大核心問題:檢索機制缺陷、問題思考的邏輯穩定性不足以及計算與邏輯嚴謹性缺失。這些問題表明,在垂直領域的知識庫建設過程中,我們正從基礎的信息檢索向更高階的認知推理轉型。這個能力升級的過程可以類比於自動駕駛的分級體系,具體包括以下幾個層次:
- 第一層為顯性知識檢索,僅需從知識庫中直接調取明確信息,對應基礎 RAG 技術,解決"有沒有知識"的問題。
- 第二層是將隱性知識結合,需整合多份文檔中的關聯信息,對應推理增強 RAG,通過思維鏈或動態檢索解決"知識如何串聯"的問題。
- 第三層則是明確規則的演繹推理,基於預設規則進行嚴格推導,需模型具備邏輯穩定性,避免思維鏈波動,對應強化學習優化的推理模型。
- 第四層需要基於結果的推斷,需從結果反推原因、總結規律或遷移經驗,對模型的邏輯嚴謹性和泛化能力要求最高,對應內生推理框架(如 KAG)的終極目標——通過非強化學習範式實現自主推理。
這一層級劃分揭示了垂域 AI 從"信息檢索"到"認知推理"的技術演進路徑:每提升一層,對模型的知識整合、邏輯穩定和推理嚴謹性的要求均呈指數級增長。而這些正是當前技術突破的重點方向。
四、大模型外掛知識庫的三種技術路線
大模型外掛知識庫可分為三類路線,各有優劣且非互相取代,未來需集成優勢、規避缺點:
● 路線一:搜索引擎技術延展,流程為索引(index)-檢索(retrieve)-生成(含規劃與生成)。問題在於:索引階段僅做文檔間簡單分塊(chunking)和嵌入(embedding),缺乏語義關聯;檢索階段無推理能力;規劃與生成階段的自然語言規劃不嚴謹,摘要無後校驗(大模型參數凍結未調優)。
● 路線二:升級到 GraphRAG,在索引階段通過圖結構增強文檔間語義關聯,檢索階段提升檢索召回相關性,但規劃與生成環節未改進。
● 路線三:傳統知識問答基於圖索引,同樣面臨圖譜構建成本高、門檻高的問題;檢索階段知識覆蓋度低(無法像大模型“兜底”所有問題),優點在於規劃生成環節嚴謹、準確性高。
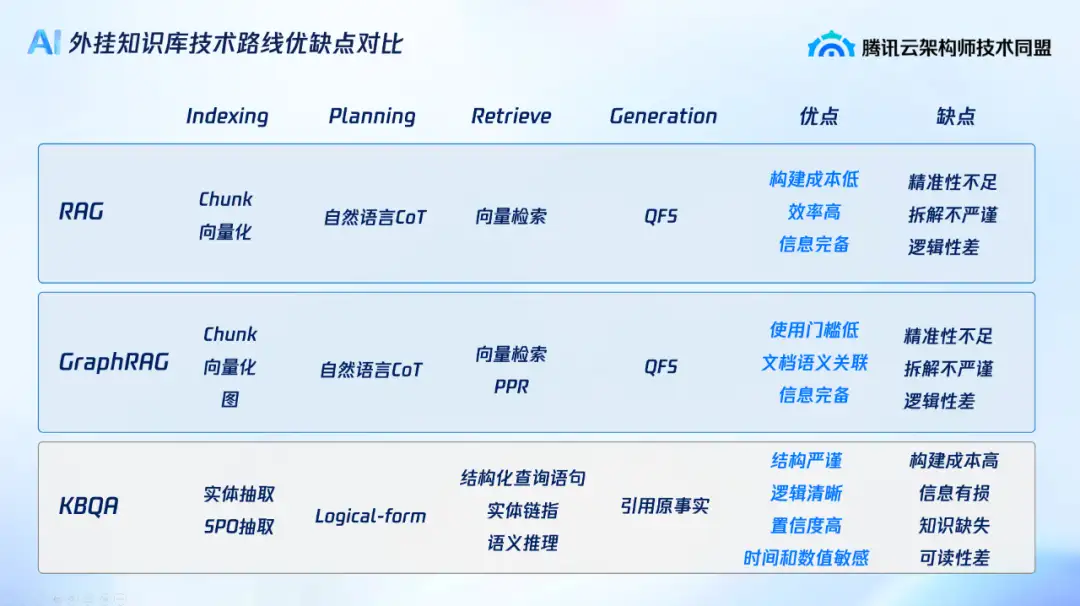
外掛知識庫技術路線優缺點對比
對比上述三種技術路線,我們可以看到它們在索引、規劃、檢索和生成等方面各自的優缺點。顯然,並不存在一種方案能夠完全取代其他兩種方式。事實上,這三類路線如同軟件發展的不同階段,並非互相替代,而是並存共生。 這一現象引導我們思考如何將這些技術路線的優點進行集成,並規避其缺點。答案是從 RAG 走向 KAG(Knowledge-Augmented Generation,知識增強生成)的路線。
五、KAG(知識增強生成)路線的提出
KAG 的核心理念(CoreIdea)是充分利用知識庫或知識圖譜中結構嚴謹的優勢,通過多重表徵和互索引的方式來優化信息組織,並藉助知識和邏輯的語義引導幫助實現結構化的思考和推理。
回顧前文所述的幾種外掛知識庫技術路線,我們可以看到現有的傳統方法各自存在明顯的缺陷,然而,在實際應用中,我們對系統能力提出了更高的要求。所以,我們提出了一種全新的 KAG 框架——以知識點為中心的知識索引與知識引導的複雜問題求解方案。該框架包括知識構建(Builder)、問題求解(Solver)以及底層支撐的模型(Model)三個部分,涵蓋理解、生成和推理等多個階段,能夠在複雜任務中提供更為精確、可靠的解決方案。
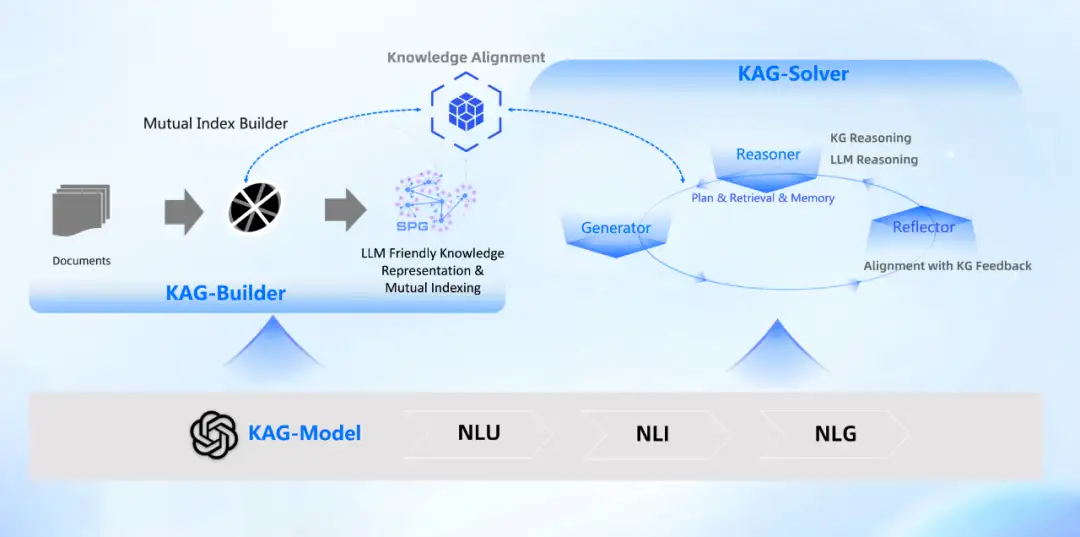
KAG 模型框架
KAG知識索引:自動化知識構建
在實際應用中,藉助大模型的能力,我們可以實現知識的自動化構建,這一過程不僅包括開放信息抽取,還涵蓋從業務系統中獲取的結構化數據。關鍵在於實現雙向校驗與互補:一方面,數據庫或大數據體系中的結構化知識雖然較為精準,但往往缺乏上下文信息;另一方面,非結構化文本雖然富含上下文,但容易產生噪聲。通過知識語義對齊,一方面可以降低知識構建成本,另一方面也能有效緩解開放信息抽取帶來的噪聲問題。
在這一過程中,我們發現知識本身是分層的,包括概念層面的知識和實際應用層面的知識。此外,知識也具有分類性,涵蓋各種實體、事件、屬性、關係、概念等結構化知識,以及自然語言描述的陳述性知識(如規則、計算過程等)。同時,還涉及大量的案例知識和推理知識。
KAG知識索引:分層知識表示
因此,如何通過語義對齊將這些不同類型的知識整合到同一個語義空間中變得至關重要。在這一過程中,我們不必要求所有知識都遵循嚴格的 schema,這意味着我們需要優化傳統的知識圖譜與大數據時代的架構,使其更適應大模型的需求。這樣的表示方式可以分為以下幾個層次:
● 嚴謹層(Rigorousness):這一層的最大優點在於其完整性(Completeness),它提供了非常完備的知識表示。
● 靈活層(Flexible Schema):這一層具有一定的結構信息,但並不強制要求強schema,更像是一個自由模式(Free Schema)圖或數據圖的概念。
● 領域特定層(Domain-specific Strong Schema):這一層則依賴於領域內的精確schema來確保準確性(Accuracy)。
通過這種表示方式,我們可以在不同的應用場景中平滑地調整專業決策、信息檢索和知識完整性的平衡。這樣的架構設計,使得我們在面對具體問題時,可以根據實際需求更加靈活地選擇最適合的知識表示形式,並在不同層次之間做出合理的權衡。
知識融合與索引構建中的關鍵要素以及優化方案
在原有知識結構的基礎上,我們將增加若干關鍵要素,以進一步提升知識的可用性和應用效果。具體而言,每個知識點或結構化知識項將添加摘要(summary),並且增加知識點與原始文本 chunk 之間的關聯。這樣一來,我們就能夠通過結構化的節點,類似於傳統的倒排索引,將知識轉換為具有關聯關係的圖結構。在此基礎上,我們將通過 schema 注入來實現與傳統圖數據庫中 key-value 形式的對接。通過這一方式,既能充分利用現有圖數據庫的優勢,又能結合新興技術提升知識庫的表達能力和查詢效率。
在知識融合的過程中,特別是在構建索引時,我們需要重點考慮以下幾個要素:對於實體信息,必須補充時空信息、文本段落上下文以及所屬領域的本體信息。缺少這些要素時,當前廣泛使用的 embedding 模型,尤其是檢索模型,可能面臨一系列問題:
● 指代缺失或錯位:例如,模型可能認為“俄羅斯總統訪華”與“美國總統訪華”更為相近,而實際上,“俄羅斯總統訪華”與“普京抵達北京首都機場”才是更相關的事件;
● 時空錯位:例如,2024 年 5 月 30 日與 2024 年 6 月 1 日時間上更接近,但模型可能錯誤地將其與 2023 年 5 月 30 日匹配;
● 數值混淆:例如,法律條文中的條款編號與金額數值可能被混為一談;
● 邏輯錯位:例如,哮喘屬於呼吸系統慢性疾病,但可能被錯誤關聯到消化系統慢性疾病。
為了避免上述問題,我們採用了一個多層次的過程來提升知識的連通性和準確性:從文檔出發,經過開放信息抽取,再到語義增強,包括本體對齊、上位概念生成、概念間關聯構建以及同義詞擴展,有效提升知識的連接性,確保模型能夠準確理解不同概念間的關係。通過增強稀疏關聯、抑制噪聲,使知識結構更加緊密和準確,進一步提高檢索和推理的準確性。
同時在整個流程中,我們引入了基於規劃的控制機制,將原本依賴思維鏈(Chain-of-Thought,CoT)的自然語言推理過程,轉化為可控的邏輯表達式,從而實現對推理路徑的精確引導。這種形式化的表達使得系統能夠按需調用不同的求解器(Solver),例如語義檢索模塊,從而更有效地建立知識關聯。
六、KAG推理框架:邏輯符號引導的結構化推理
KAG 技術的核心之一是如何通過邏輯符號引導的結構化推理來實現複雜問題的求解。為此,我們需要將原始問題按需分解為多個子問題,並清晰地刻畫這些子問題之間的邏輯依賴關係。在此基礎上,系統應能自主判斷以下幾項決策:
- 是否調用符號化知識圖譜進行推理?
- 是否執行文本 chunk 的檢索?
- 是否在結構化數據上進行圖遍歷與子圖匹配?
- 是否在擴展後的文本內容上進行閲讀理解與“思考”操作?
最終,通過多種推理方式的協同工作,系統能夠動態更新與整合當前問題相關記憶(memory),為求解提供更為精準的答案。
在整個推理過程中,我們會使用多種邏輯形式(Logical form),包括檢索、排序、數學計算、邏輯推理、反問以及輸出等對應的邏輯表達形式。通過引入特定的標記(special token),能夠將原本單一的數據流轉變為數據流與控制流相結合的協同機制。這種機制通過不同的操作符(Operator)和求解器(Solver)可以實現本身的輸出校驗,確保結果的準確性;還能支持推理問答以及檢索過程中的動態數值計算,從而增強模型的推理深度和靈活性。
典型任務示例:博士生申請居住證
以博士生申請居住證是否需要學校開具在讀證明為例,該問題的求解過程可以分解為一系列結構化操作:
- 定位所在地區:首先確定所在地區的相關政策。
- 查找相關辦事事項:查詢該地區居住證辦理的相關要求。
- 判斷是否需提供在讀證明:根據相關政策,判斷是否需要提交學校開具的在讀證明。
這些步驟實質上轉化為檢索(retrieve)、擴散查詢(diffuse)等具體操作符的有序執行,從而形成從問題到答案的結構化推理路徑。
從這個典型任務可以看出,核心在於實現可控的規劃過程。需要強調的是,並非所有內容都必須結構化,也並非所有處理都需依賴圖結構才能完成。實際上,在一些輕量級的應用場景中,我們可以在保證效果相當的前提下,有效控制構建成本,這對於本地化部署和垂直領域的落地應用非常重要。
七、從外部依賴到內化推理:KAG-Thinker的創新路徑
在前述討論中,我們提到大模型通過引入外部檢索和求解器調用來擴展其能力,但這種依賴在實際應用中也面臨一系列挑戰。隨着從大模型到 RAG 的過渡,雖然引入了外部知識庫,系統的存儲開銷、token 消耗以及授權成本等方面卻顯著增加。此外,儘管推理增強能夠處理更復雜的任務,但整體流程耗時增加,這對實際落地應用提出了新的挑戰。
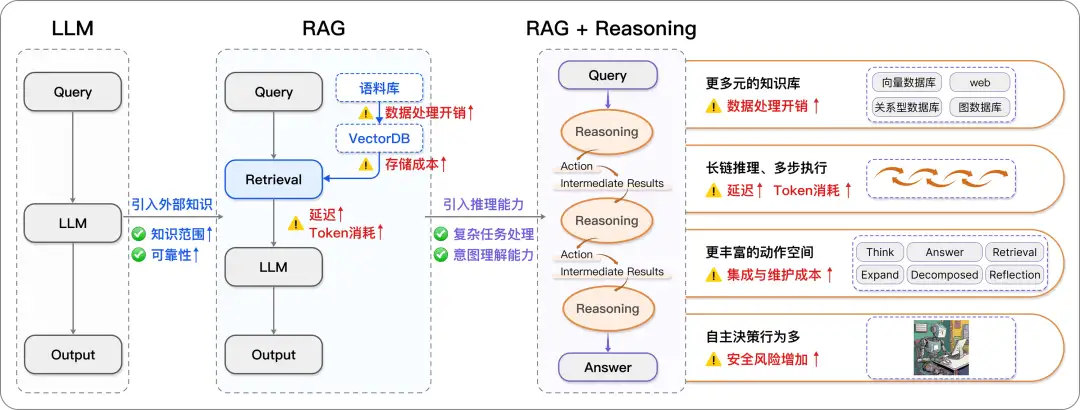
從大模型到推理增強RAG面臨的挑戰
另一方面,儘管大模型具備自主決策的潛力,但“進化”行為的方向未必符合預期,這可能帶來額外的安全風險。為了應對這些問題,我們提出了 KAG-Thinker,為模型的思考過程建立一套清晰、分層的 “腳手架”,從而提升複雜任務中推理過程的邏輯性與穩定性。
具體來説,KAG-Thinker 其實是以邏輯形式(Logical Form)為中心,將三類推理模式進行統一,一是純自然語言推理,二是自然語言結合變量與運算符的推理,三是僅基於變量與運算符的形式化推理。通過這種統一表達,KAG-Thinker 能夠將外部依賴(如外部檢索、調用外部求解器等)轉化為內化推理過程,從而有效提升推理的可控性與可解釋性。
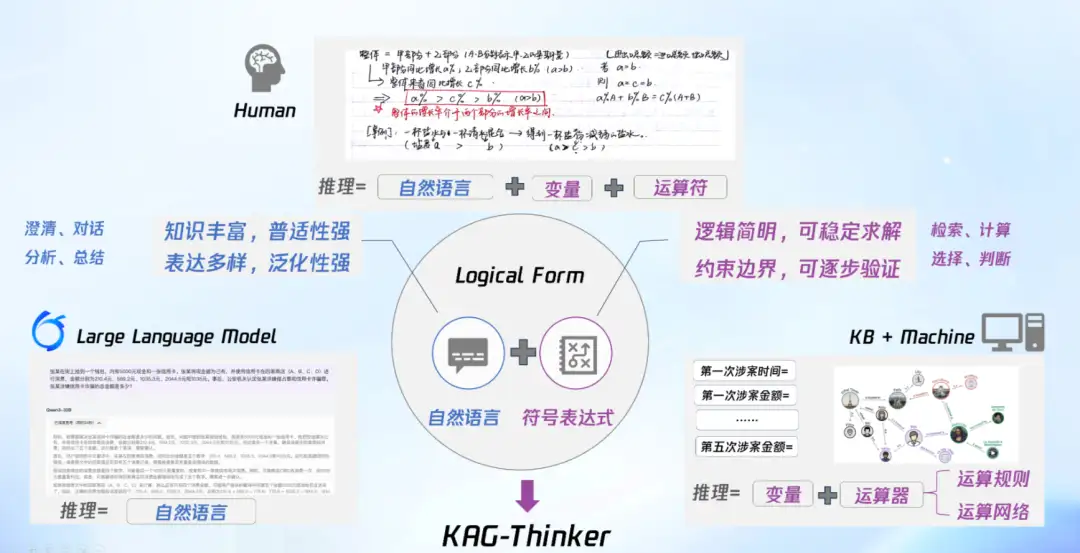
KAG-Thinker:以邏輯形式為中心
KAG-Thinker模型能力
在 KAG-Thinker 模型的設計過程中,我們對系統提出了幾個核心要求:邏輯性、穩定性,以及對知識邊界的清晰判斷。具體來説,模型需要能夠明確識別何時調用內部知識,以及何時依賴外部信息。此外,還需要確保求解過程的嚴謹性,並具備對檢索噪聲的魯棒性。
目前常見的做法是採用強化學習(RL)手段進行優化。然而,在 KAG-Thinker 框架中,我們並未採用 RL 的方式,而是選擇了監督微調(SFT)的方法。這是因為,在生成包含特殊標記(special token)和長思維鏈的結構化推理路徑時,SFT 能夠通過大量合成數據並根據行業需求靈活調整模型行為,確保推理過程的準確性和可靠性。
我們所使用的合成數據涵蓋了通用領域與垂直領域的多樣化樣本,整體覆蓋了問題的廣度分解、深度求解過程中的知識邊界識別、求解器調用策略、多源知識融合時的注意力聚焦,以及關鍵推理節點的準確表達。
通過這種方式,我們能夠逐步引導模型完成複雜任務,並利用高質量的訓練數據持續優化其推理能力。如下圖所示,KAG-Thinker 模型通過邏輯形式將複雜問題分解為獨立可解的子問題,構建了結構化的思維過程,增強了問答任務中推理過程的邏輯連貫性和上下文一致性。這種方式實現了可控、可解釋的智能生成,確保每一步推理都可以追溯,並能夠根據用户需求靈活調整。模型不僅在高效求解上表現出色,還能保證推理過程的透明性和可靠性。
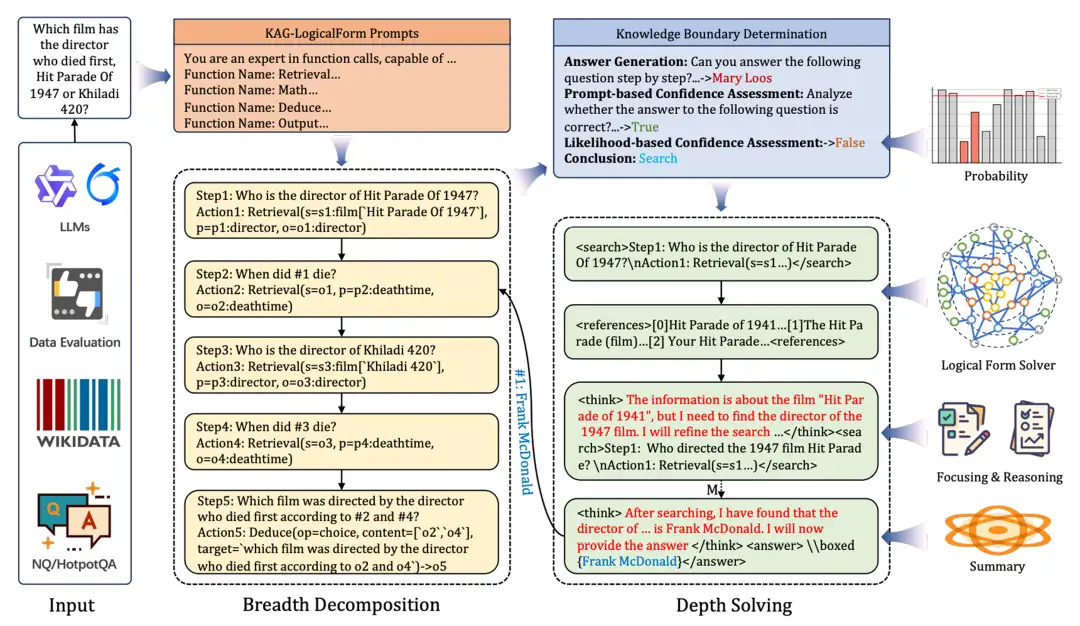
複雜問題求解概覽圖
大模型推理與檢索過程中存在的問題
在大模型的推理與檢索過程中,至關重要的一點是識別和應對“知識四象限”問題:即模型是否能夠區分“知道自己知道”、“知道自己不知道”、“不知道自己知道”和“不知道自己不知道”這四種狀態。如何改善模型對這四類情況的識別能力,是提升其可靠性的關鍵。只有當模型能夠準確識別併合理應對這些不同的知識狀態時,才能確保推理的有效性與準確性。
我們希望模型在回答正確問題時,具備較高且可控的置信度(confidence)。例如,當模型生成正確答案時,其置信度應保持在較高水平(如0.95以上)。然而,當前許多大模型存在過度自信的問題,尤其是在輸出錯誤答案時,常表現出過高的置信度,這導致了可信度失衡。這種情況常常是模型幻覺現象的根源之一。因此,必須設計有效機制來將置信度控制在合理範圍內,避免不準確的答案被過度自信地輸出。
此外,在性能層面還有兩個關鍵指標:一是推理過程的穩定性,二是對“過度自信”(over-confidence)的控制。大模型普遍存在過度自信的問題,即在缺乏依據的情況下仍以高置信度輸出錯誤結果,這正是幻覺現象的重要成因之一。因此,必須通過機制設計將其控制在合理範圍內。
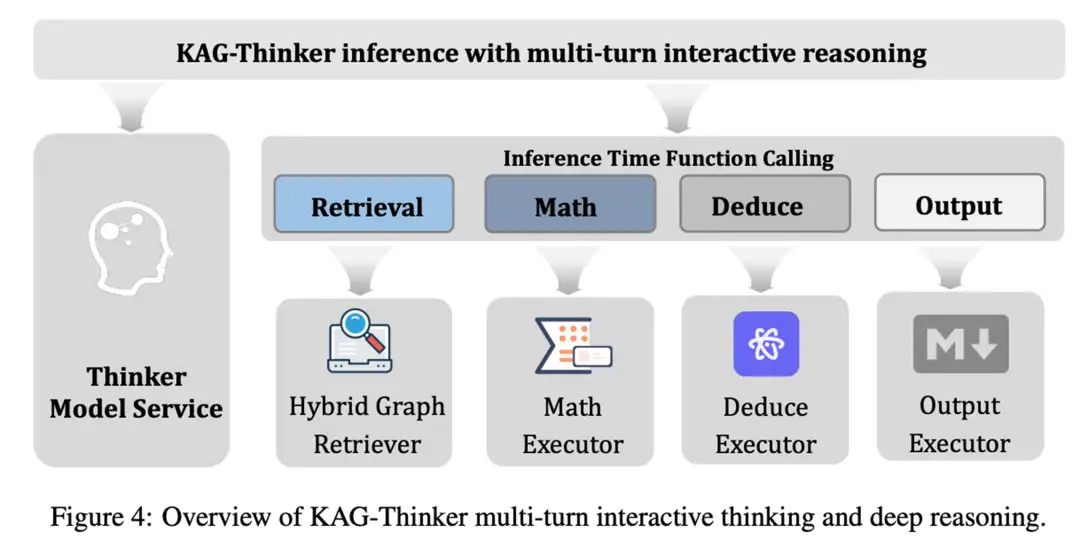
KAG-Thinker 模型
最終,所有的推理與判斷過程都將被集成到模型服務(model serving)環節,確保推理(inference)與 AI 服務流程的深度融合。通過這種方式,模型不僅能夠在推理時準確識別何時應依賴內在知識,何時應調用外部信息,還能有效控制置信度,提升服務質量與系統的可靠性。
八、從助手到夥伴:RAG到KAG的四大躍遷路線
RAG 技術在目前的應用中仍然存在大量的優化空間,其本質目標是將大模型從一個被動的知識助手,逐步發展為具備認知能力的智能夥伴。為實現這一目標,我認為可以從以下四個方面進行提升:
- 從傳統的模糊語義匹配轉向邏輯驅動的定向精準檢索。這包括對問題進行子問題分解,並在推理過程中觸發精準、有針對性的檢索操作,提升信息獲取的準確性和效率。
- 從單一的問答模式升級為系統性決策支持。面對複雜任務,需支持多路徑、多分支的推理流程,形成結構化的決策鏈條,而不僅僅是孤立地回答單個問題。
- 針對大模型常出現的信息堆砌問題,應增強對返回信息的邏輯自洽性校驗,並實現動態補全。通過判斷信息之間的一致性,按需觸發新的檢索或推理步驟,形成閉環的求解過程。
- 當前大模型存在盲目搜索和過度思考的問題,因此需要實現智能的資源分配機制,合理調度推理深度與廣度,避免資源浪費,提升響應效率與結果質量。
通過這四個方向的提升,我們不僅能夠優化現有 RAG 技術的應用效果,更能推動大模型從單純的知識檢索工具向具備認知和決策能力的智能夥伴演變。這一轉變將極大地拓展大模型在垂直領域中的應用潛力,併為未來的智能系統提供更加精確、靈活的推理支持。
