光影煥像(Lightillusions)是一家專注於空間智能技術,結合 3D 視覺、圖形學和生成模型技術,致力於打造創新的 3D 基礎模型公司。公司由譚平教授領導,譚教授曾擔任阿里巴巴達摩院實驗室負責人,目前是香港科技大學的教授,同時擔任馮諾伊曼人工智能研究室副院長,並是香港科技大學與比亞迪聯合實驗室的主任。
區別於二維模型,三維模型單個模型的大小可達幾 GB,尤其是點雲數據等複雜模型。當數據量達到 PB 級別時,管理與存儲成為巨大的挑戰。經過嘗試 NFS、GlusterFS 等方案後,我們最終選擇了 JuiceFS,成功搭建了一個統一的存儲平台,為多個場景服務,並支持跨平台訪問,包括 Windows 和 Linux 系統。該平台目前已管理上億文件,數據處理速度提升了 200%~250%,還實現了高效的存儲擴容,同時運維管理得到了極大簡化,使得團隊能夠更專注於核心任務的推進。
01 3D-AIGC 存儲需求
我們的研究主要集中在感知和生成兩個方向。在三維領域,任務的複雜性與圖像和文本處理有本質區別,這對我們的 AI 模型、算法以及基礎設施建設都提出了更高的要求。
我們通過一個 3D 數據處理流程,來展示三維數據處理的複雜性。下圖左側是一個三維模型,包含紋理(左上角的折射紋理)和幾何信息(右下角的幾何結構)。首先,我們生成渲染圖像。每個模型還附帶文本標籤,描述其內容、幾何特徵和紋理特徵,這些標籤與每個模型緊密相關。此外,我們還處理幾何數據,如採樣點以及從數據預處理過程中得到的必要數值(如 3DS、SDF 等)。需要注意的是,三維模型的文件格式非常多樣,圖片格式也各不相同。
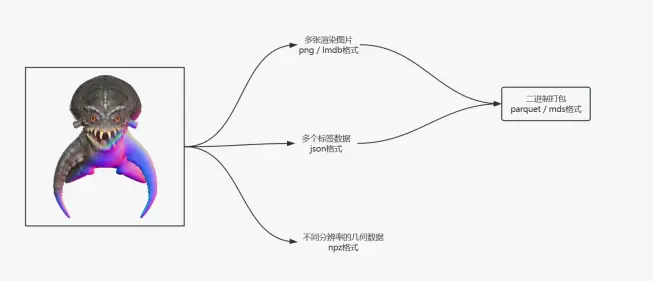
我們的工作場景涉及語言模型、圖像/視頻模型到三維模型,隨着數據量的增長,存儲負擔也在不斷增加。以下是這些場景中數據使用的主要特點:
- 語言模型的數據通常由大量小文件組成。儘管單個文本文件較小,但隨着數據量的增加,文件數量可能達到數百萬甚至數千萬個,這使得管理如此龐大的文件數成為存儲的一個主要難點。
- 圖像和視頻數據,尤其是高分辨率圖像和長時間的視頻,通常較為龐大。單張圖像的大小通常在幾百 KB 到幾 MB 之間,而視頻文件可能達到 GB 級別。在預處理過程中,如數據增強、分辨率調整和幀提取等,數據量會顯著增加,特別是在視頻處理中,每個視頻通常會被拆解為大量的圖像文件,管理這些龐大的文件集,帶來了更高的複雜性。
- 三維模型,特別是點雲數據等複雜模型,單個模型的大小可達幾 GB。三維數據的預處理過程比其他數據更加複雜,涉及紋理映射、幾何重建等多個步驟,這些處理不僅消耗大量計算資源,還可能增加數據體積。此外,三維模型通常由多個文件組成,文件數量龐大,隨着數據量的增長,管理這些文件的難度也會增加。

由上述環節的存儲特點,我們希望構建的存儲平台能夠滿足以下幾項要求:
-
多樣的數據格式與跨節點共享:不同模型的數據格式差異較大,特別是三維模型的格式複雜性和跨平台兼容問題,存儲系統需要支持多種格式,並有效管理跨節點和跨平台的數據共享。
-
可以處理不同尺寸的數據模型:無論是語言模型的小文件、大規模圖片/視頻數據,還是三維模型的大文件,存儲系統必須具備高擴展性,以應對快速增長的存儲需求,並高效處理大尺寸數據的存儲和訪問。
-
跨雲與集羣存儲的挑戰:隨着數據量的增加,特別是三維模型的 PB 級存儲需求,跨雲和集羣存儲問題愈加突出。存儲系統需要支持跨區域、跨雲的無縫數據訪問和高效的集羣管理。
-
方便擴容:無論是語言模型、圖片/視頻模型,還是三維模型,擴容需求始終存在,尤其是三維模型的存儲和處理對擴容的需求更高。
-
簡單的運維:存儲系統應提供簡便的管理界面和工具,尤其是對於三維模型的管理,運維要求更高,自動化管理和容錯能力是必不可少的。
02 存儲方案探索:從 NFS、Gluster、CephFS 到 JuiceFS
前期方案:NFS 掛載
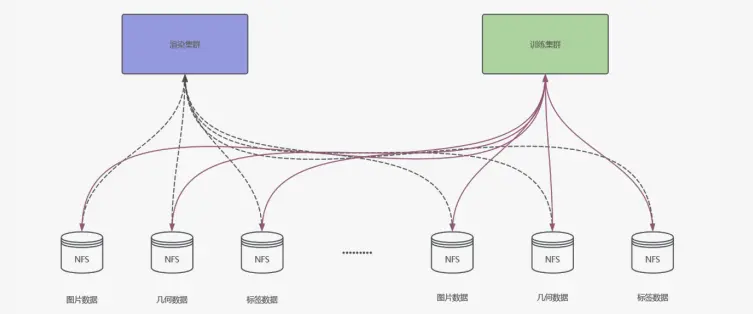
最初,我們採用了最簡單的方案------使用 NFS 進行掛載。然而,在實際操作中,我們發現訓練集羣和渲染集羣需要各自獨立的集羣來進行掛載操作。這種方式的維護非常繁瑣,尤其是當添加新的數據時,我們需要單獨為每個新數據寫入掛載點。到了數據量達到約 100 萬物體級別時,我們已經無法繼續維持這種方案,因此在早期階段,我們就放棄了這一方案。
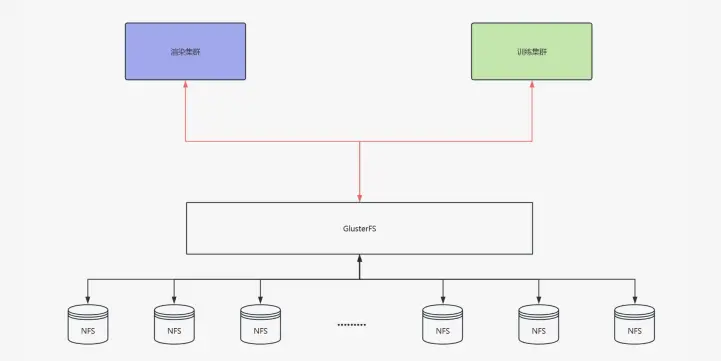
中期方案:GlusterFS
GlusterFS 是一個相對易於上手的選擇,安裝配置簡單,性能也能得到一定保障,且無需劃分多個掛載點,只需增加新節點即可。雖然在前期使用時,GlusterFS 大大減輕了我們的工作量,但我們也發現它的生態系統存在一些問題。
首先,GlusterFS 許多執行腳本和功能需要手動編寫定時任務。特別是在添加新存儲時,它還會有一些額外要求,例如需要按特定倍數增加節點。此外,像克隆、數據同步等操作的支持也相對較弱,導致我們在使用過程中頻繁查閲文檔,且許多操作並不穩定。例如,使用 FIO 等工具進行測速時,結果並不總是可靠。
更為嚴重的問題是,當存儲的小文件數量達到一定規模時,GlusterFS 的性能會急劇下降。舉個例子,一個模型可能會生成 100 張圖片,若有 1000 萬個模型,就會產生 10 億張圖片。GlusterFS 在後期的尋址變得極為困難,尤其是小文件過多時,性能會顯著下降,導致系統崩潰。
最終選型:CephFS vs JuiceFS
隨着存儲需求的增加,我們決定轉向可持續性更好的方案。在評估了多種方案後,我們主要對比了 CephFS 和 JuiceFS。雖然 Ceph 被廣泛使用,但通過自己的實踐和對比文檔,我們發現 Ceph 的運維和管理成本非常高,尤其對於我們這樣的小團隊來説,處理這些複雜的運維任務顯得尤為困難。
JuiceFS 有兩個原生自帶的特性非常符合我們的需求。首先是客户端數據緩存功能。對於我們的模型訓練集羣,通常會配備高性能的 NVMe 存儲。如果能夠充分利用客户端的緩存,便能顯著加速模型訓練,並減少對 JuiceFS 存儲的壓力。
其次,JuiceFS 對 S3 的兼容性對我們也至關重要。由於我們基於存儲開發了一些可視化平台用於數據標註、整理和統計,S3 兼容性使得我們能夠快速進行網頁開發,支持可視化和數據統計操作等功能。

03 基於 JuiceFS 的存儲平台實踐
元數據引擎選擇與拓撲
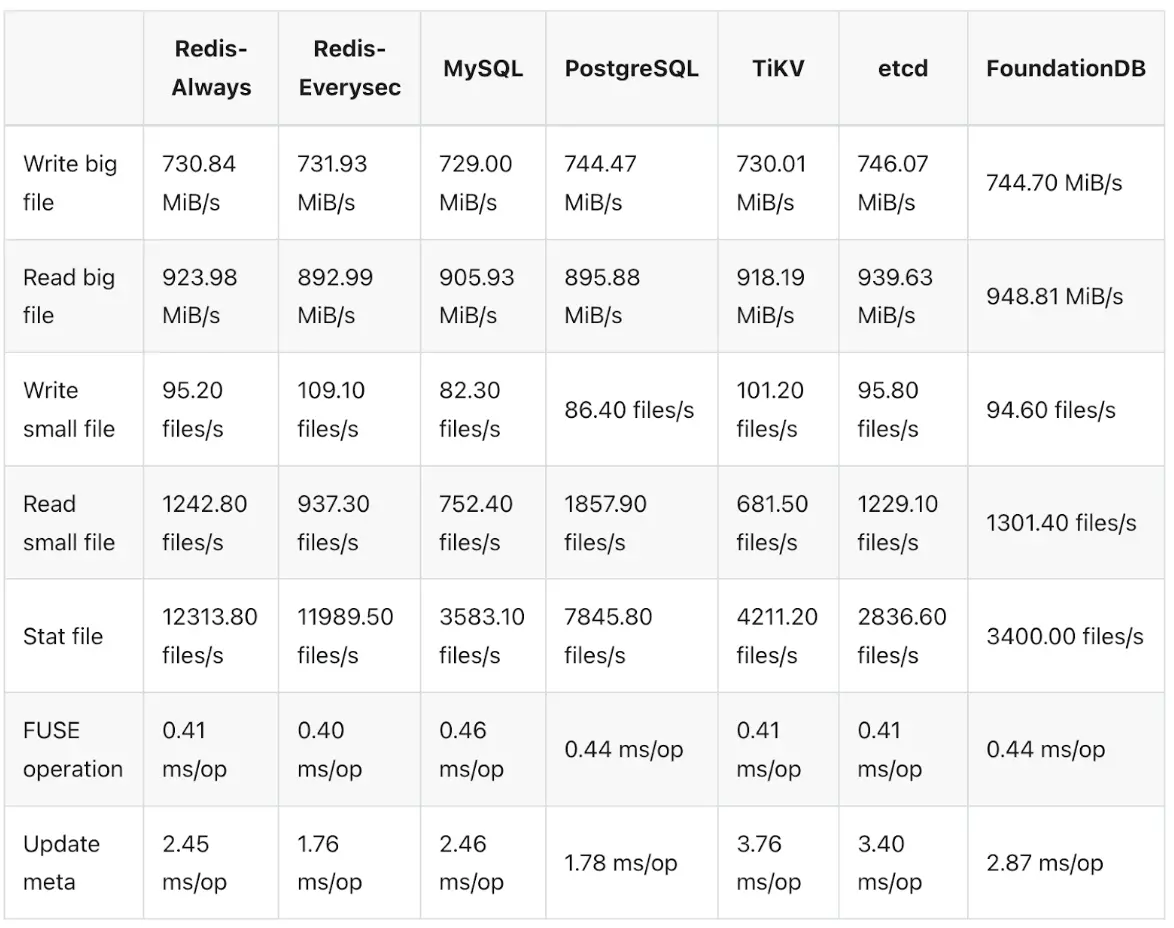
JuiceFS 採用的是元數據與數據分離的架構,有多種元數據引擎可供選擇。我們首先快速驗證了 Redis 存儲方案,官方提供了詳細的文檔支持。Redis 的優勢在於其輕量化,配置過程通常只需一天或半天時間,數據遷移也相對順利。然而,當小文件數量超過 1 億時,Redis 的速度和性能會顯著下降。
正如之前提到的,每個模型可能會渲染出 100 張圖片,再加上其他雜項文件,導致小文件的數量急劇增加。雖然我們可以通過打包小文件來減輕問題,但一旦打包後進行修改或可視化操作,複雜性就大大增加。因此,我們希望能夠保留原始的小圖片文件,以便後續處理。
隨着文件數量的增加,很快超出 Redis 的處理能力,我們決定將存儲系統遷移到 TiKV 和 Kubernetes 組合上。TiKV 與 K8s 的組合能夠為我們提供更高可用的元數據存儲方案。此外,通過基準測試我們發現,儘管 TiKV 的性能稍遜一籌,但差距並不顯著,且相較於 Redis,它對小文件的支持更好。我們也諮詢過 JuiceFS 的工程師,瞭解到 Redis 在集羣模式下的擴展性較差,於是我們準備切換到 TiKV。
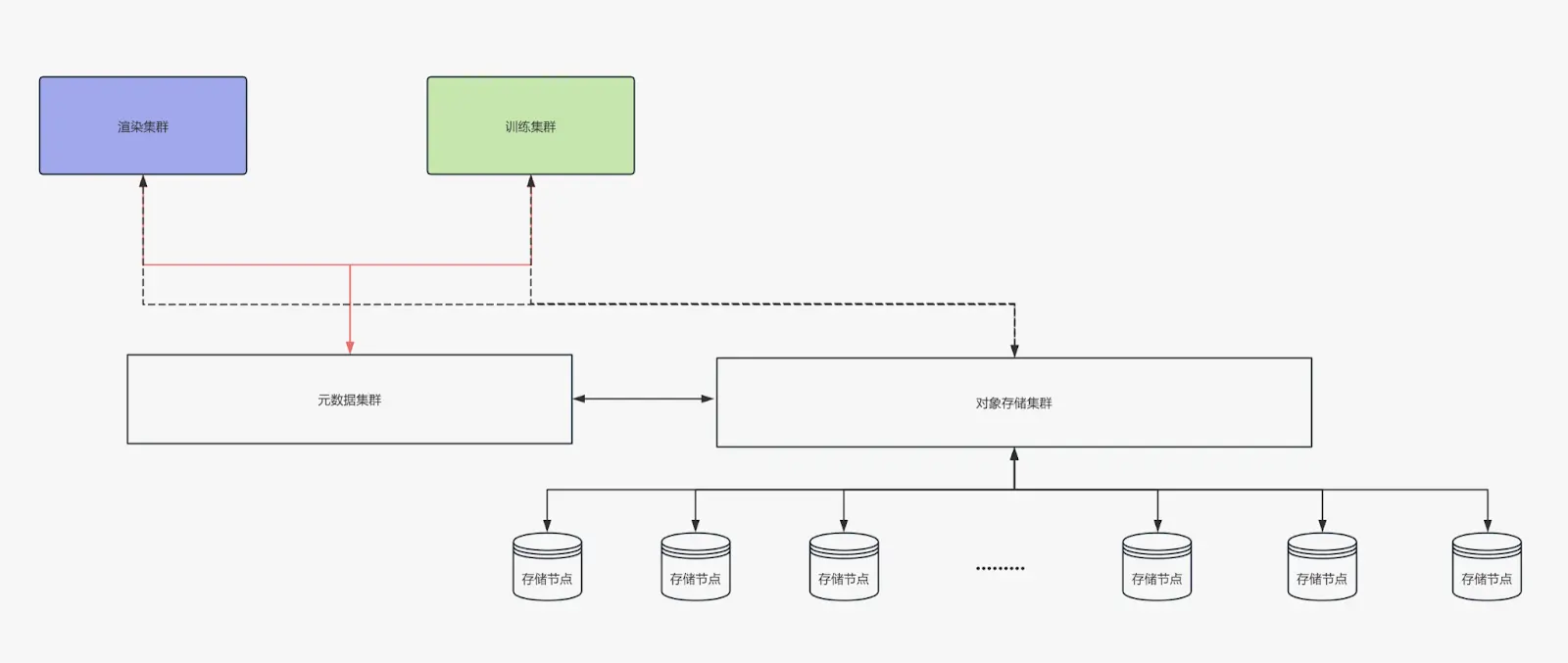
最新架構:JuiceFS + TiKV + SeaweedFS
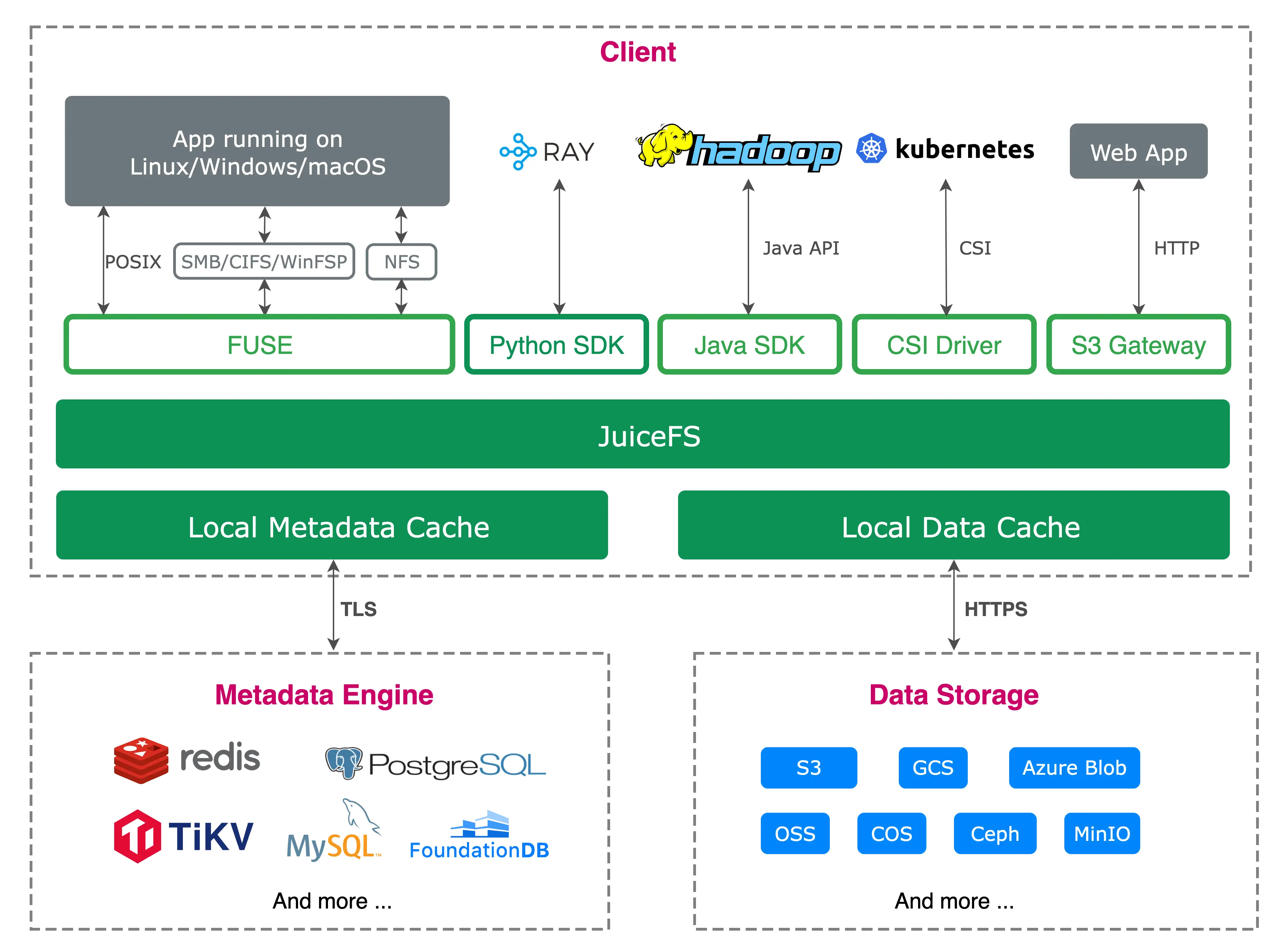
我們使用了 JuiceFS 來管理對象存儲。TiKV 和 K8s 來搭建元數據存儲系統。對象存儲部分使用了 SeaweedFS,這使得我們能夠快速擴展存儲規模,且無論是小數據還是大數據,訪問速度都很快。此外,我們的對象存儲分佈在多個平台:包括本地存儲、阿里雲存儲以及國外的 R2 和 Amazon 對象存儲。通過 JuiceFS,我們能夠將這些不同存儲系統集成起來,並提供一個統一的接口。
為了更好地管理系統資源,我們在 K8s 上搭建了資源監控平台。當前系統由大約 60 台 Linux 機器和若干 Windows 機器組成,負責渲染和數據處理任務。我們對讀取穩定性進行了監控,結果顯示,即使是多台異構服務器同時進行讀取操作,整個系統的 I/O 性能依然非常穩定,基本能夠充分利用帶寬資源。

實踐中遇到的問題
在優化存儲方案的過程中,我們最初嘗試了 EC(糾刪碼) 存儲方案,旨在減少存儲需求並提升效率。然而,在大規模數據遷移中,EC 存儲的計算速度較慢,並且在高吞吐量和頻繁數據變化的場景下,性能表現不佳,尤其與 SeaweedFS 結合時,存在性能瓶頸。基於這些問題,我們決定放棄 EC 存儲,轉而採用副本存儲方案。
我們設置了獨立服務器並配置了定時任務,以進行大數據量的元數據備份。在 TiKV 中,我們實現了冗餘副本機制,採用了多個副本方案來確保數據的完整性。同時,在對象存儲方面,我們採用了雙副本編碼來進一步提高數據可靠性。雖然副本存儲能夠有效保證數據冗餘和高可用性,但由於處理 PB 級數據和大量增量數據,存儲成本依然較高。未來,我們可能會考慮進一步優化存儲方案,以降低存儲成本。
另外,我們也發現當使用全閃存服務器 + JuiceFS 並未帶來顯著的性能提升。瓶頸主要出現在網絡帶寬和延遲上。因此,我們計劃在後期考慮使用 InfiniBand(IB)連接存儲服務器和訓練服務器,以最大化資源利用效率。
04 小結
在使用 GlusterFS 時,我們每天最多隻能處理 20 萬個模型;而切換到 JuiceFS 後,處理能力大幅提升,日均數據處理能力增加了 2.5 倍,小文件吞吐能力也顯著提高,特別是在存儲量達到 70% 後,系統仍能保持穩定運行。此外,擴容也非常便捷,而之前的架構,擴容過程非常繁瑣,操作起來比較麻煩。
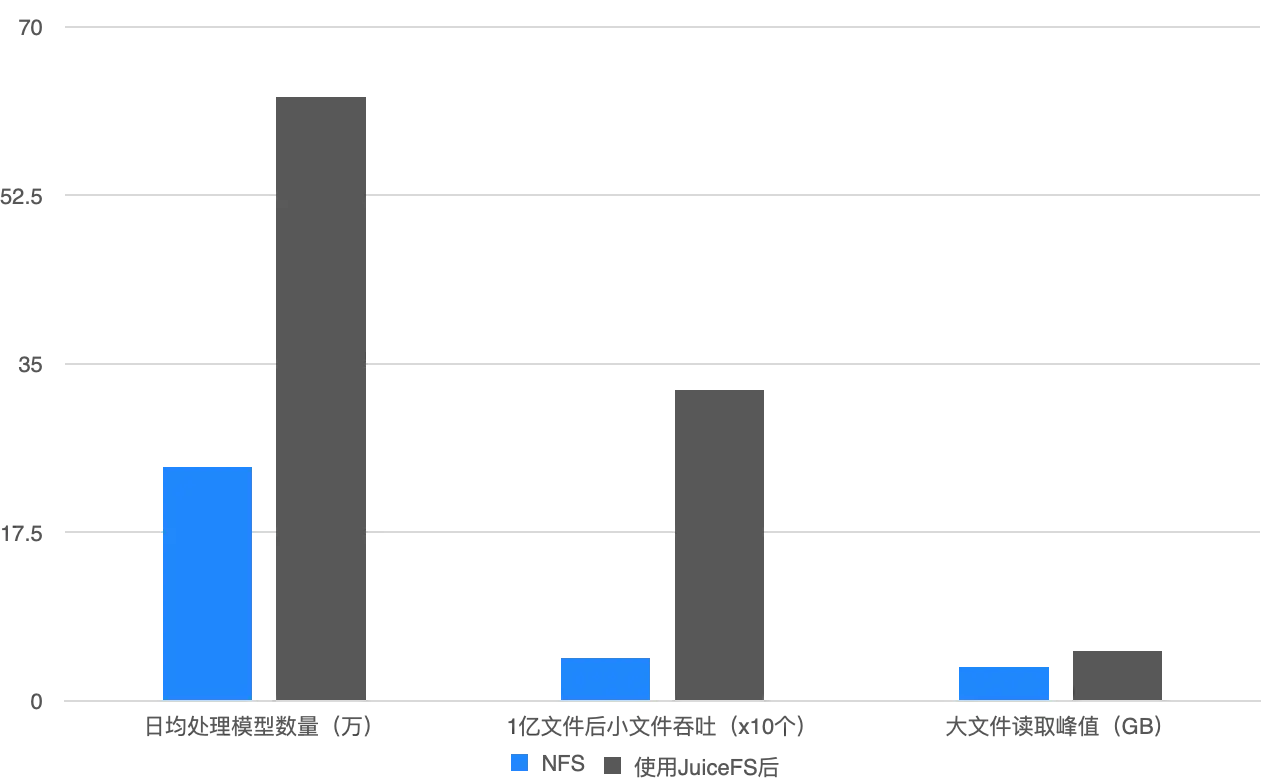
最後再總結一下 JuiceFS 在三維生成任務中表現出來的優勢:
-
小文件性能: 小文件處理能力是一個關鍵點,JuiceFS 依然提供了一個較好的解決方案。
-
跨平台特性: 跨平台支持非常重要。我們發現有些數據只能在 Windows 軟件中打開,因此需要同時在 Windows 和 Linux 系統上處理相同的數據,並在同一個掛載節點上進行讀寫。這種需求使得跨平台的特性尤為關鍵,JuiceFS 的設計很好地解決了這一問題。
-
低運維成本: JuiceFS 的運維成本極低。配置完成後,只需要進行一些簡單的測試和節點的管理(例如,丟棄某些節點並監控魯棒性)。我們在遷移數據時花費了大約半年的時間,到目前為止並未遇到太大的問題。
-
本地緩存機制: 之前,如果想使用本地緩存,我們需要手動在代碼中實現本地緩存邏輯,但 JuiceFS 提供了非常方便的本地緩存機制,通過設置掛載參數來優化訓練場景的性能。
-
遷移成本低: 尤其是在遷移小文件時,我們發現使用 JuiceFS 進行元數據和對象存儲的遷移非常方便,節省了我們大量時間和精力。相比之下,之前使用其他存儲系統遷移時,過程非常痛苦。
綜上所述,JuiceFS 在大規模數據處理中的表現非常出色,提供了高效、穩定的存儲解決方案。它不僅簡化了存儲管理和擴容過程,還大大提升了系統性能,讓我們能夠更加專注於核心任務的推進。
此外,官方提供一些工具也非常便捷,例如我們使用 Sync 在處理小文件遷移時,效率極高。在沒有額外性能優化的情況下,我們成功遷移了 500TB 的數據,其中包含大量的小數據和圖片文件,遷移時間不到 5 天,結果超出我們的預期。
我們希望本文中的一些實踐經驗,能為正在面臨類似問題的開發者提供參考,如果有其他疑問歡迎加入 JuiceFS 社區與大家共同交流。
