阿里通義大模型團隊正式開源發佈 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,這兩個模型基於 Qwen3-VL 構建,專為多模態信息檢索與跨模態理解設計,為圖文、視頻等混合內容的理解與檢索提供統一、高效的解決方案。

- 多模態通用性
兩個模型系列均能在統一框架內處理文本、圖像、可視化文檔(圖表、代碼、UI組件......)、視頻等多種模態輸入。在圖文檢索、視頻-文本匹配、視覺問答(VQA),多模態內容聚類等多樣化任務中,均達到了業界領先水平。
- 統一表示學習(Embedding)
Qwen3-VL-Embedding 充分利用 Qwen3-VL 基礎模型的優勢,能夠生成語義豐富的向量表示,將視覺與文本信息映射到同一語義空間中,從而實現高效的跨模態相似度計算與檢索。
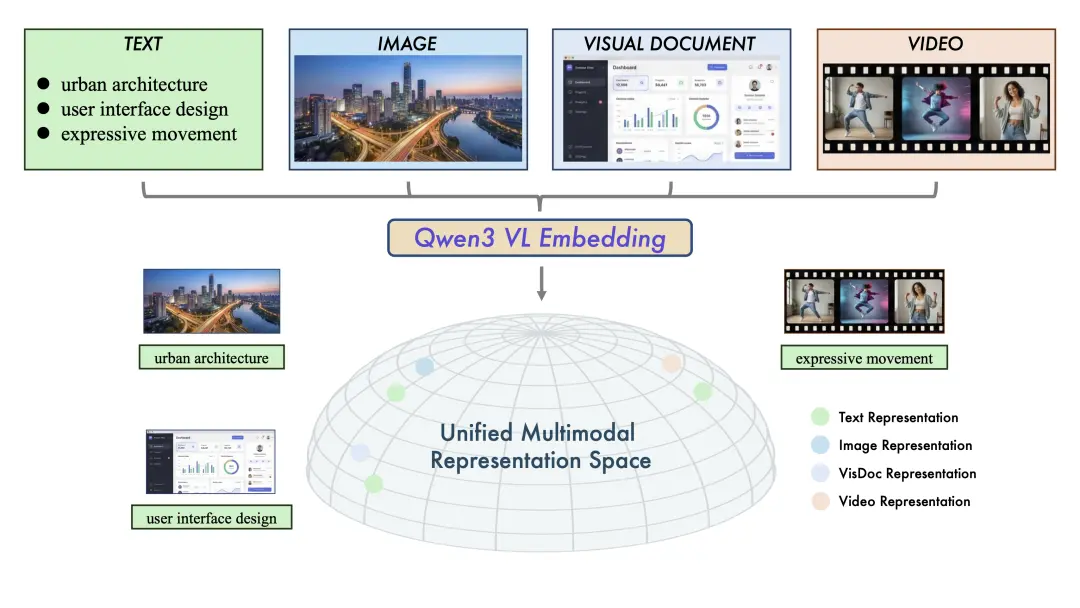
圖1:統一多模態表示空間示意圖。Qwen3-VL-Embedding模型系列將多源數據(文本、圖像、視覺文檔和視頻)映射到共同的高維語義空間。
- 高精度重排序(Reranker)
作為 Embedding 模型的補充,Qwen3-VL-Reranker 接收任意模態組合的查詢與文檔對(eg:圖文查詢匹配圖文文檔),輸出精確的相關性分數。在實際應用中,二者常協同工作:Embedding 負責快速召回,Reranker 負責精細化重排序,構成“兩階段檢索流程”,顯著提升最終結果精度。
- 卓越的實用性
該系列繼承了 Qwen3-VL 的多語言能力,支持超過 30 種語言,適合全球化部署。模型提供靈活的向量維度選擇、任務指令定製,以及量化後仍保持的優秀性能,便於開發者集成到現有系統中。
Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 採用了不同的架構設計,分別針對檢索流程的不同階段進行優化。
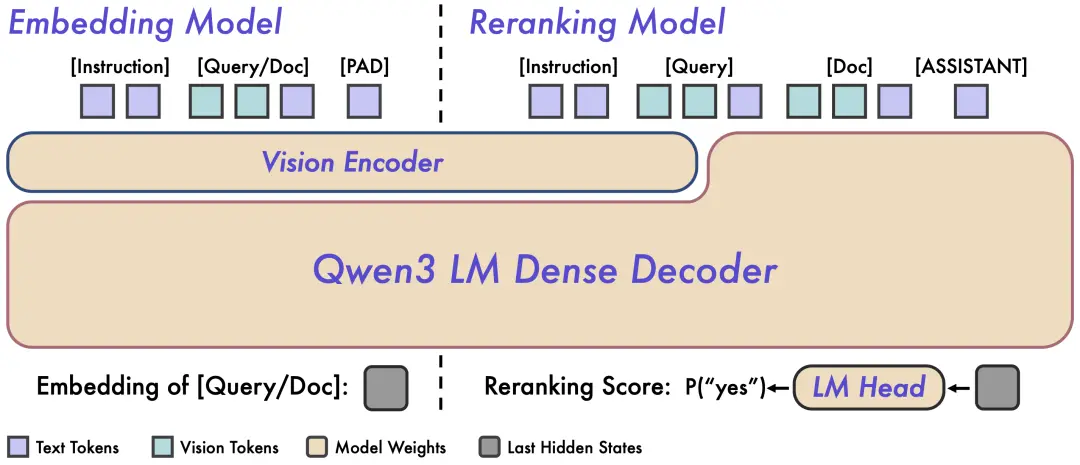
圖 2:Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 架構概覽。左側為 Embedding 模型的雙塔獨立編碼架構,右側為 Reranker 模型的單塔交叉注意力架構。
Qwen3-VL-Embedding 採用雙塔架構,可以高效地將不同模態的內容獨立編碼為統一的向量表示,特別適合處理海量數據的並行計算。
Embedding 模型接收單模態或混合模態輸入,並將其映射為高維語義向量。我們提取基座模型最後一層中對應 [EOS] token 的隱藏狀態向量,作為輸入的最終語義表示。這種方法確保了大規模檢索所需的高效獨立編碼能力。
Qwen3-VL-Reranker 採用單塔架構,通過內部的交叉注意力機制,深度分析查詢與文檔之間的語義關聯,從而輸出精確的相關性分數。
在實際工作中,Reranking 模型接收輸入對 (Query, Document) 並進行聯合編碼。它利用基座模型內的交叉注意力機制,實現 Query 和 Document 之間更深層、更細粒度的跨模態交互和信息融合。模型最終通過預測兩個特殊 token(yes 和 no)的生成概率來表達輸入對的相關性分數。
GitHub 倉庫:
https://github.com/QwenLM/Qwen3-VL-Embedding
魔搭 ModelScope:
https://modelscope.cn/collections/Qwen/Qwen3-VL-Embedding
https://modelscope.cn/collections/Qwen/Qwen3-VL-Reranker
