中國信息通信研究院近日組織完成 2025 年第四季度多模態大模型專項測試工作,最新體系和測試結果如下:
2025年11月至12月測試涵蓋多模態理解、文生圖與文生視頻三項任務,共評估30個模型,其中包括10個多模態理解大模型、10個視頻生成模型和10個圖像生成模型。
1、多模態理解任務測試結果
多模態理解任務測試旨在考察模型對圖像、文本、圖表等信息的深層解析與邏輯推理能力,涵蓋函數求解、幾何分析、表格分析、身份分析、色彩分析、未來預測、關係分析、物理推理、IQ問題維度
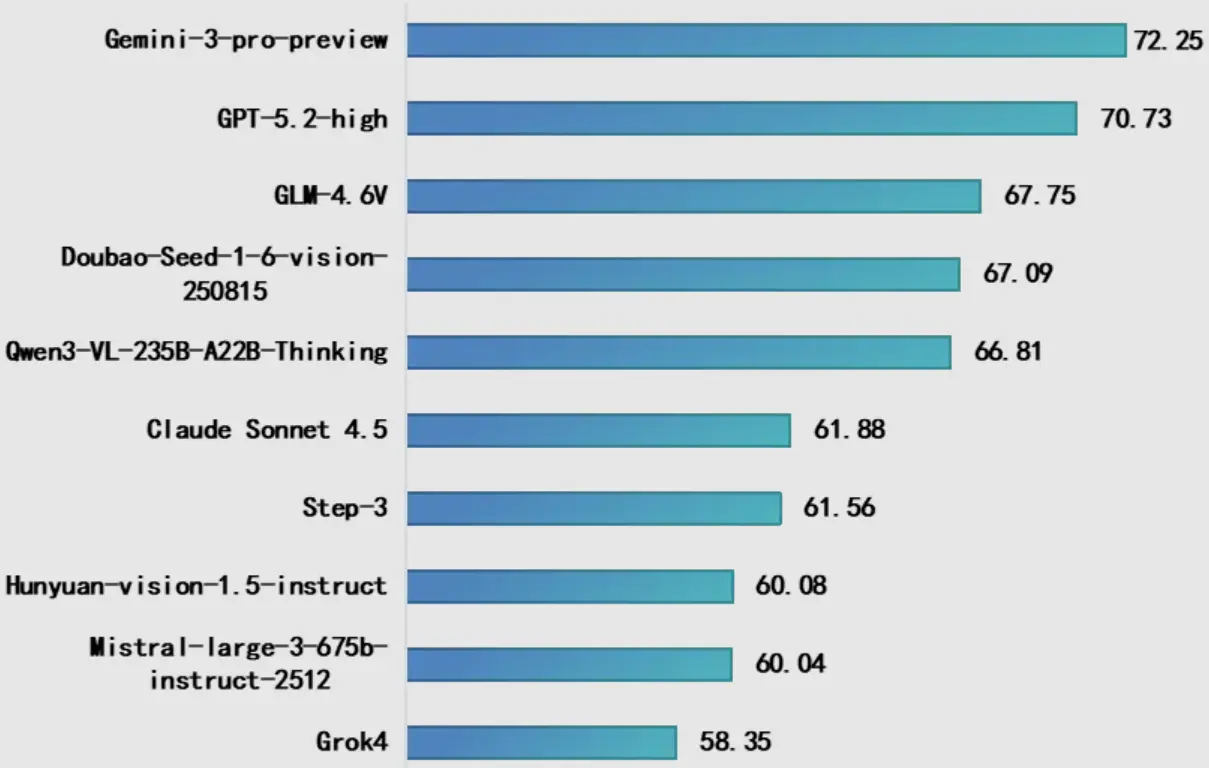
本此測試10個多模態理解大模型,其中國內模型5個,國外模型5個,包括Google Gemini-3-pro-preview、OpenAI GPT-5.2-high、智譜GLM-4.6V、字節跳動Doubao-Seed-1-6-vision-250815等代表性模型。測試結果顯示:一是谷歌Gemini-3-pro-preview綜合得分位居榜首,其表現小幅領先於 GPT-5.2-High,並顯著優於 GLM-4.6V。二是國內模型之間差距較小,GLM-4.6V、Doubao-Seed-1-6-vision與 Qwen3-VL-235B-A22B-Thinking得分高度集中,體現出國內模型在核心能力上的緊追態勢。
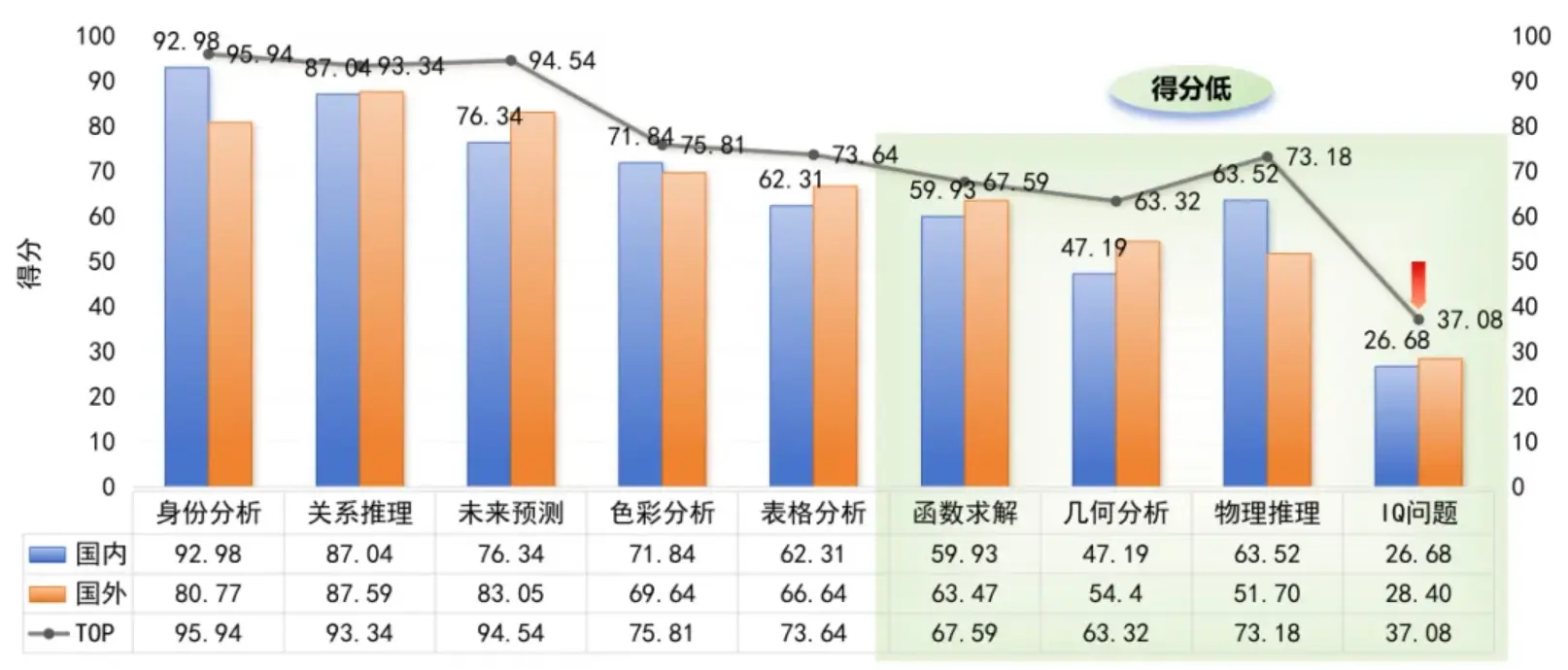
本期測試9類指標,不同維度能力差異明顯:從全球模型的整體水平來看,其在身份分析、未來預測、色彩分析等基礎任務達到較高能力水平,而函數求解、幾何分析和IQ問題等複雜學科、高強度推理任務上仍存在瓶頸。從國內模型的表現來看,其在身份分析、色彩分析、物理推理這類規則明確的任務中表現突出;但未來預測、IQ問題這類涉及開放推理、長程邏輯或場景推演的任務上,仍有較大提升空間。
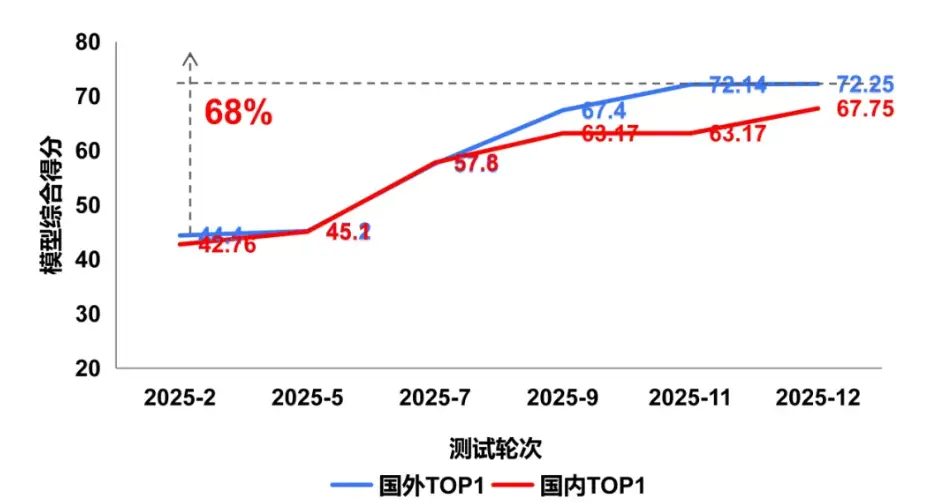
從 2025年2月至12月的持續監測結果看,國內外多模態大模型在圖像理解能力均呈現穩步上升態勢,反映出多模態理解能力已成為技術競爭的關鍵賽道。值得關注的是,國內模型視覺理解能力呈現追趕態勢,但面向複雜物理世界的理解與推理仍存在一定性能差距。
2、文生圖任務測試結果
文生圖任務測試考察模型將文本指令轉換為高質量圖像的能力,核心考察生成圖像的色彩表現力、空間構建能力、中國文化表達、主體刻畫能力、要素還原能力、色彩表現力、文字創作能力和數量生成能力。
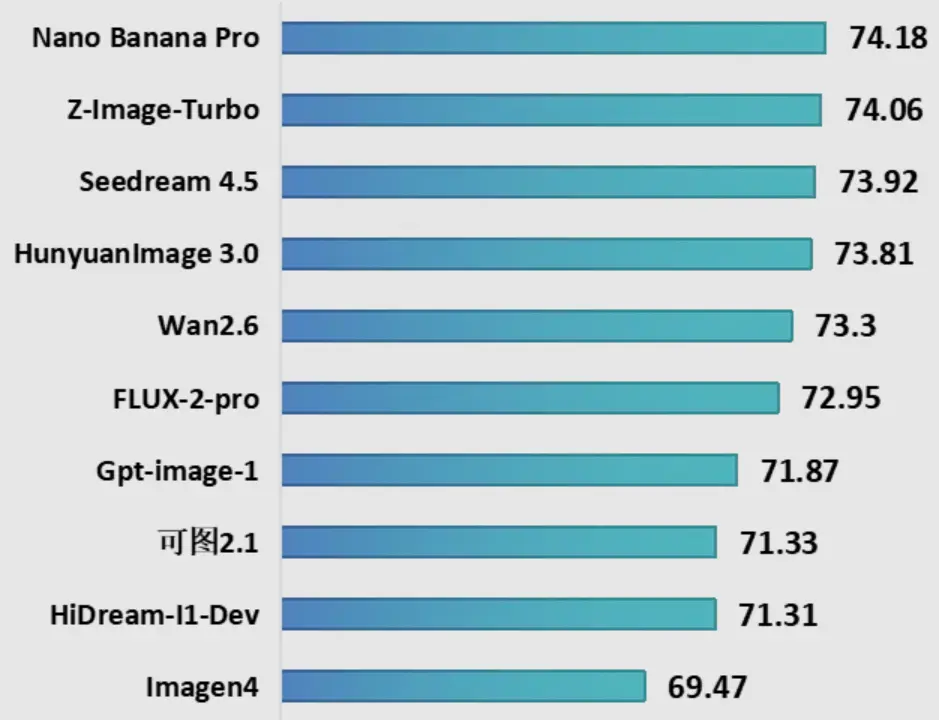
本輪測試10個圖像生成模型,其中國內模型6個與國外模型4個,包括字節跳動Seedream 4.5、谷歌Nano Banana Pro、阿里巴巴Wan2.6、Z-Image-Turbo等代表性模型。測試結果顯示,一是國外模型暫居領先,谷歌Nano Banana Pro綜合得分居榜首,阿里巴巴Z-Image-Turbo以微弱差距緊隨其後。二是國內大模型圖像生成能力得分接近,字節跳動Seedream 4.5、騰訊HunyuanImage3.0、阿里巴巴Wan2.6能力差距較小,展現出強勁競爭力。
在圖像生成能力方面,國內模型在色彩表現、要素還原能力和中國文化表達維度優於國外模型。這一結果表明國內模型在高精度控生成的技術沉澱,也體現出其深耕本土市場數據、適配文化審美偏好的訓練路徑。然而,當前模型在文字內容生成、數量一致性保持及空間構建等方面仍存在侷限,如文字生成易出現細節偏差、數量控制穩定性不足、空間佈局與物體關係構建能力亦有欠缺。整體來看,模型對單一元素類指令的執行效果較好,但在“數量-空間位置-物體關聯”等複合指令的處理上,仍有較大提升空間。

從2025年2月至12月的連續測試結果看,國內外模型文生圖能力水平十分接近,期間整體能力均有明顯進步。當前,國內模型在物理空間模擬、複雜要素還原、多輪圖像編輯等高階生成能力方面仍有提升空間。
3、文生視頻任務測試結果
文生視頻任務測試考察模型從文本指令生成連貫視頻的能力,涵蓋視頻畫質渲染、要素搭建能力、動態塑造能力、空間模擬、影視素材、超現實內容生成和中國文化適配能力。
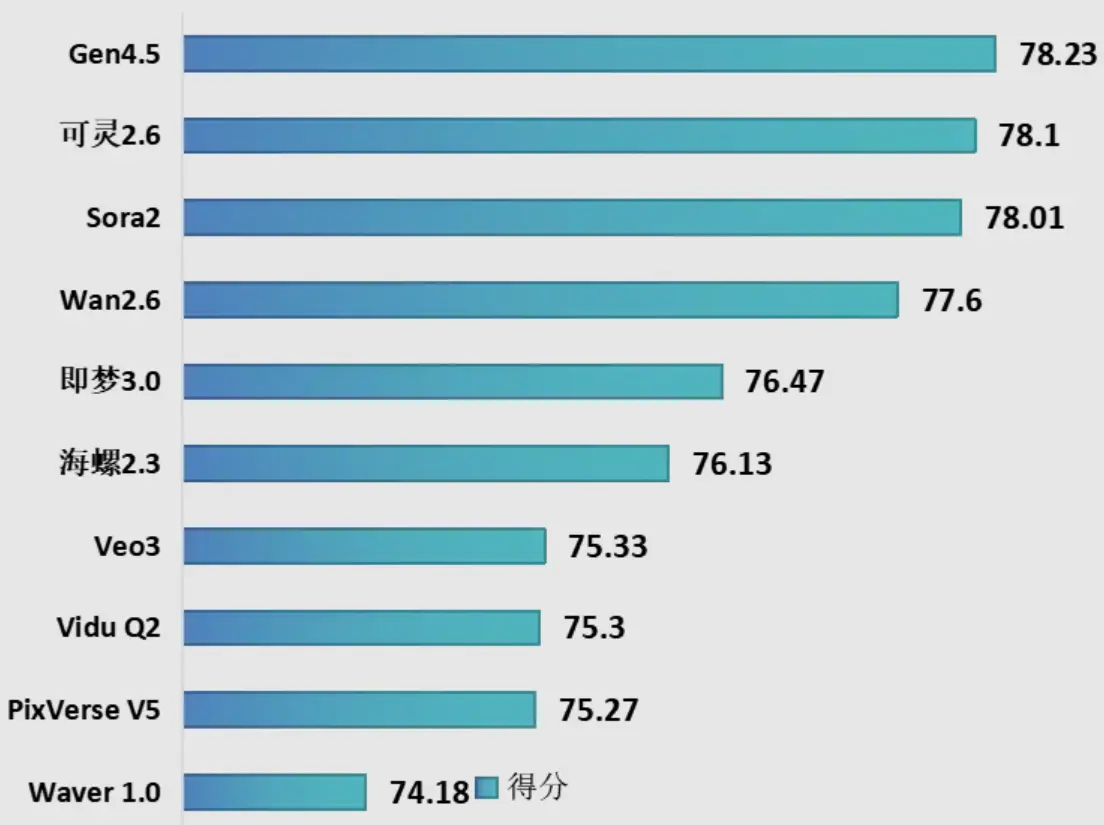
本輪評測10個視頻生成模型,其中國內模型7個,國外模型3個,包括Runway Gen-4.5、OpenAI Sora2、快手可靈2.6、阿里巴巴Wan-2.6等主流模型。測試結果顯示,一是Runway Gen-4.5在本輪評測中綜合排名第一,以微弱優勢領先快手可靈2.6。二是國內模型在本次評測前五名中佔據三席,分別為快手可靈2.6、阿里巴巴Wan-2.6與字節跳動即夢3.0,在視頻生成關鍵技術指標上達到國際較好水平。三是國內模型的迭代與發佈節奏更快,快手可靈從1.0到2.6,在約18個月內進行了超過7次版本迭代,而OpenAI 從Sora到Sora 2的大版本迭代間隔約20個月。
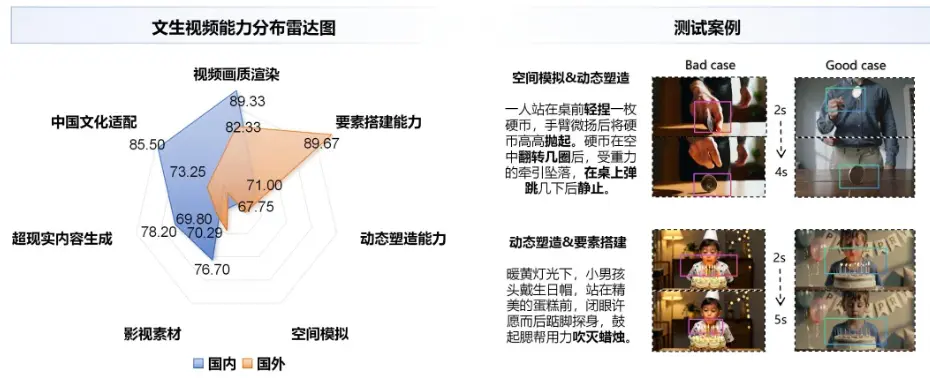
在視頻生成能力方面,國內模型在中國文化適配及影視素材生成兩個維度的表現顯著由於國外模型,體現出其在本土文化內容適配、影視級風格還原上的定向優化成果。國外模型則在空間模擬與要素組織等生成能力上保持一定優勢。整體來看,當前模型在動作合理性、過程連貫性以及細節完整性等方面時常出現偏差,尤其在“物理邏輯-動態塑造-場景細節”等複合維度的融合生成能力上,有待進一步加強。
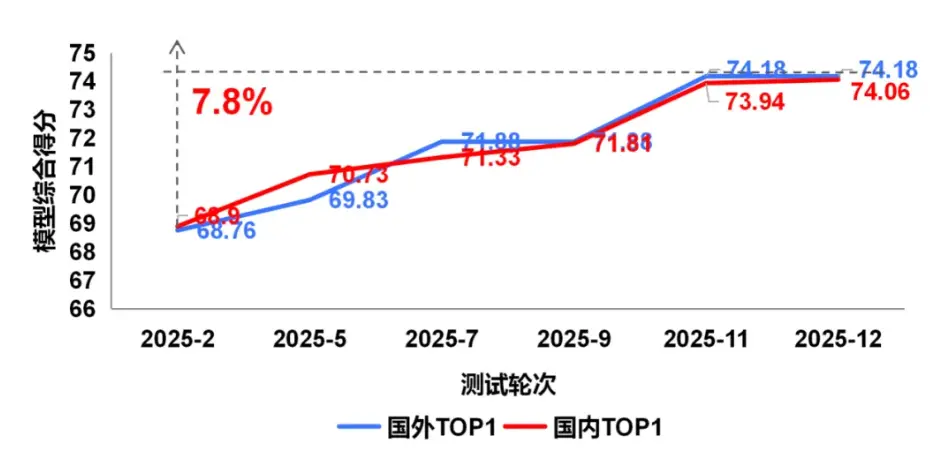
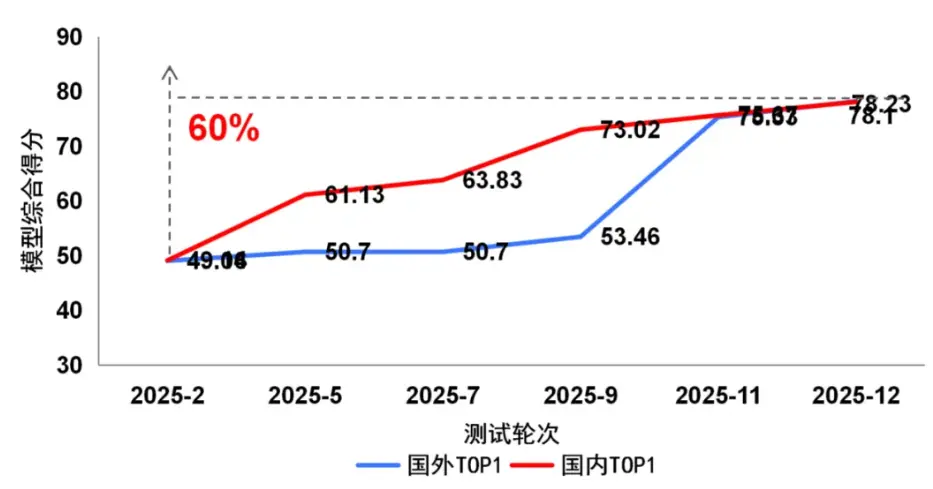
2025年度的持續測試表明,國內頭部模型展現出了強勁的迭代能力,在上半年與國際頂尖水平存在差距,至年底已在綜合性能上實現並跑。然而,在物理空間模擬、複雜要素搭建等高階生成能力上,國內外模型仍需持續突破。
“方升-多模態”大模型基準測試體系,構建了覆蓋評估指標、數據構建、評測方法、測試工具四大核心層面的全維度評估框架。評估指標設計上,圍繞多模態理解與多模態生成兩大核心方向,涵蓋函數推理、幾何分析、圖表解析,以及視頻流暢性、物理邏輯、圖像美學等方面。測試數據集方面,自建累計超20萬條多模態數據,視覺理解類數據側重選擇、判斷與問答推理能力,文生圖、文生視頻類數據則聚焦複合提示詞的指令遵循效果,為模型的高效評估與優化提供全面支撐。測試方法方面,形成以大模型測試與定量測試相融的多模態協調測試方法,支持多模態交互一致性的高效評估。測試工具方面,緊扣多模態統一評估框架要求,實現對理解、生成及協調能力的一體化自動化評測。
