KubeSphere 正式推出 v4.2.1 版本,圍繞網關平滑升級、多集羣治理、節點精細化調度等方面進行針對性提升。在 v4.2.1 中,KubeSphere 重構網關全生命週期管理能力,從運維效率、權限治理等方面做出重大改進。
-
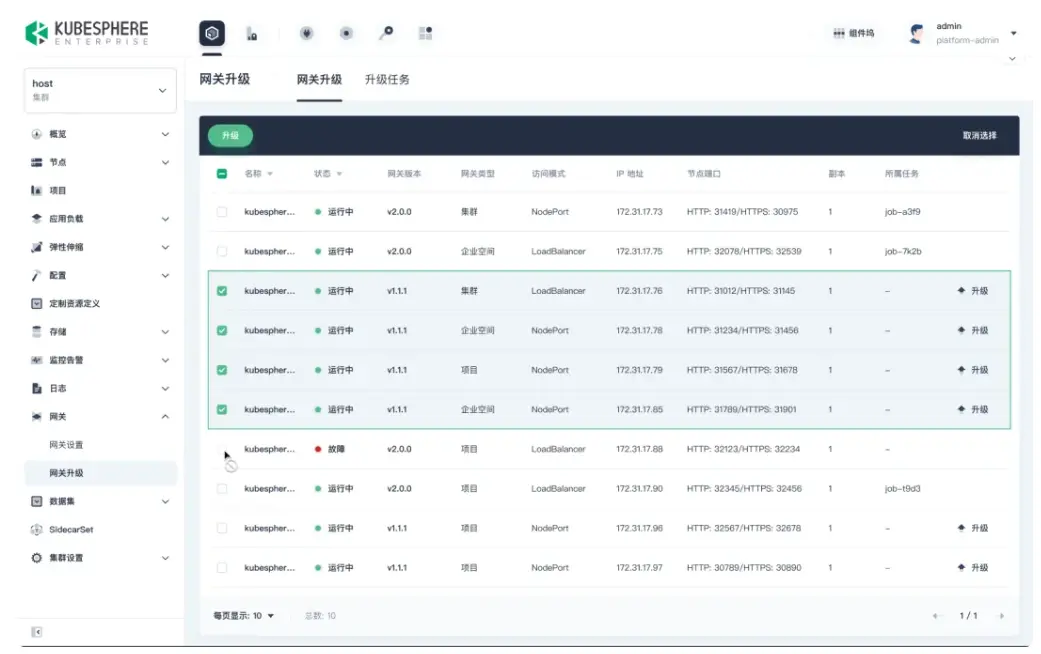
無感平滑升級
支持管理員在控制枱一鍵發起網關升級操作,系統將自動按照滾動更新策略逐步替換網關實例,全程無需停機或中斷業務流量。該能力顯著提升了網關升級的成功率與執行效率,大幅降低了因版本迭代、安全補丁或配置變更帶來的業務抖動風險,真正實現 “靜默升級、無感運維”,為生產環境中的高可用服務網關提供堅實保障。
-
故障秒級定位
摒棄 “依賴日誌擴展組件” 的傳統模式,運維人員即可直接查看網關工作負載狀態與運行日誌,故障定位時長從 “分鐘級” 縮短至 “秒級”,顯著降低問題排查成本。
-
分級流量管控
平台管理員可在集羣視角統一配置企業空間級與項目級網關,實現分級部署與權限管控,滿足不同業務對流量隔離、入口管理和權限控制的差異化需求,滿足企業精細化運維規範。
v4.2.1 針對多集羣場景,從 升級管理、狀態同步 等方面持續優化平台能力。
-
成員集羣在線升級
通過界面對成員集羣版本升級提供可視化便捷操作,降低多集羣升級過程中的操作複雜度與人為失誤風險;同時支持查看升級日誌,實時掌握升級進展。
-
多集羣狀態精準同步
優化多集羣狀態同步機制,增加成員集羣狀態的主動探測能力,完善多種集羣狀態的判斷邏輯,確保狀態數據的準確性與一致性。
KubeSphere v4.2.1 新增節點組(Node Group能力,可將物理或虛擬節點邏輯劃分為多個節點組,並支持節點組和企業空間綁定。基於該能力,企業可實現在不同場景對資源調度的精細化管理。例如:
-
在多團隊共享集羣、信創環境隔離、AI 與普通業務混部等複雜場景中,保障關鍵業務獨佔高性能或專用硬件資源,避免租户間資源爭搶。
-
基於節點組歸屬自動歸集資源消耗,實現部門 / 項目級成本核算。
-
支持將公有云、私有云、邊緣節點分別納入不同節點組,構建統一調度平面下的異構資源池。
KubeSphere v4.2.1 通過 KubeEye 提供靈活且可擴展的 K8s 集羣巡檢框架。KubeEye 支持通過自定義巡檢規則和計劃,對集羣中的節點、工作負載及服務進行全面的自動化健康檢查與合規性掃描,並自動採集結果、生成詳細的巡檢報告,幫助管理員提前發現潛在風險與配置缺陷。
KubeSphere v4.2.1 通過集成垂直 Pod 自動擴縮(VPA)、事件驅動的彈性伸縮機制,並增強傳統 HPA 策略,實現更精準、更敏捷、多維度的資源彈性調度能力。
容器垂直伸縮(VPA)
基於資源實際需求進行智能調度:
- 基於歷史 CPU 和內存使用數據,自動分析並推薦每個容器的
requests和limits最優值,避免資源浪費或 OOM、CPU 節流問題。 - 在 Auto 模式下,VPA 可自動修改工作負載(如 Deployment、StatefulSet)中 Pod 的資源請求,並通過滾動重建 Pod 應用新配置。
注意:建議避免同時對同一工作負載使用多種伸縮策略,防止策略衝突、伸縮混亂。
事件驅動伸縮(KEDA)
將外部事件轉化為 K8s 的彈性伸縮信號:
- 支持 80+ 信號源(Scalers),覆蓋消息隊列、數據庫、監控系統、雲服務及自定義伸縮器等全場景。
- 當事件源無待處理任務時,可將 Pod 副本數縮至 0,徹底釋放資源,顯著降低成本,尤其適用於低頻、突發型任務。
- 對同一伸縮目標使用多個觸發器(target),實現精準伸縮。
容器水平伸縮(HPA)增強
對擴縮容行為進行更精細的控制:
-
支持擴容 scaleUp 和縮容 scaleDown 分別配置策略參數,支持穩定窗口、擴縮容速率限制,避免指標瞬時波動導致頻繁擴縮容。
-
針對 CPU 和內存,支持多種目標值類型,如百分比、平均值、絕對值。
注意:升級後的 HPA V2 無法直接從舊版本 HPA V1 自動升級,需手動調整 YAML;兩者不可同時應用於同一工作負載,否則會產生衝突。
KubeSphere v4.2.1 一站式集成 VPA、HPA 與 KEDA,實現縱向調優、橫向擴縮與事件驅動彈性的三位一體智能伸縮體系,兼顧資源效率、成本優化與業務敏捷性。
在 v4.2.1 中,KubeSphere 聚焦異構基礎設施的統一納管與數據訪問效率,面向工程仿真、工業數字孿生、高併發數據處理等多樣化業務負載,推出三大核心基礎能力,為上層調度平台提供穩定、標準化的算力支撐。
-
GPU / vGPU 異構算力統一納管與適配
支持對物理 GPU 與虛擬化 GPU 資源的統一識別、註冊與基礎分配,適配通用圖形渲染、工業計算等場景的硬件需求,實現異構算力資源的規範化管理,提升資源可視性與可管理性。
-
深度集成 Volcano 批量調度引擎
提供通用批量計算任務的基礎編排能力,支持隊列管理、基礎資源分配等策略,為上層專業調度平台提供任務編排適配支撐,保障通用複雜工作負載的穩定執行。
-
NFS 與對象存儲本地緩存加速
集成 Fluid 雲原生數據編排引擎,實現 NFS 與對象存儲的智能本地緩存加速,通過數據預取與邊緣緩存機制,降低遠程存儲訪問延遲,顯著提升 I/O 密集型應用的數據讀寫吞吐量,確保業務高併發場景下穩定高效運行。
這些能力共同構建了一個更高效、更靈活、更貼近企業生產實際的雲原生基礎設施平台,助力企業在不改變現有架構的前提下,為上層各類調度平台提供標準化的異構算力底座,保障算力資源穩定供給,提升整體資源運營效率。
其他重要更新
- 應用管理:優化操作超時控制、日誌查看及命名空間配置,支持歷史部署清理,整體體驗更流暢。
- 可觀測性:支持指標告警、事件告警的持久化存儲;支持採用 Doris 作為審計、事件、日誌、通知歷史的後端存儲;開放租户級網絡可觀測功能權限。
- 資源管理:容器健康檢查支持 HTTP 請求頭探針配置;支持 Pod 事件滾動更新。
