

零、釋義
- milvus:向量數據庫
- langchain:python提示工程框架
一、背景
- 本篇文章基於一個BUG的排查和解決過程,試圖還原在某些場景下多進程編程的【陷阱】,達到前車之鑑的效果。
- 程序基於python,但結論和道理適用於所有語言
二、BUG問題表現
-
最近的一段提示工程相關的python代碼,在不同操作系統的情況下,表現不一樣
- 在macos系統與linux系統的單進程、macos系統的多進程情況下均可以正常運行:
-
在linux的多進程情況下會卡在與milvus交互的地方,如下圖
三、假設
- milvus服務端導致(磁盤滿了、內存滿了、服務繁忙等)
- 網絡異常導致
- 操作系統導致
- 連接milvus所用的底層調用包導致
四、假設驗證和BUG排查思路
-
❌【milvus服務端導致】
- 單獨測試了milvus的讀寫,服務本身沒有問題,milvus所在服務器也是健康狀態,不存在資源缺乏的情況。排除1
-
❌【網絡異常導致】
- telnet端口通,ping通且穩定,網絡是OK的。排除2
-
✅【操作系統導致】✅【連接milvus所用的底層調用包導致】
- 初步判斷為多進程導致的問題,那麼為何macos中的多進程正常,linux系統的多進程就有問題呢?
-
排查思維鏈(Chain-of-Thought)
-
於是翻閲python關於多進程模塊的官方文檔,直到看到了這樣一段話
- python多進程在不同操作系統,默認啓動子進程的方式是不一樣的,在windows和macos上,默認使用【spawn】,而在linux上,默認是用【fork】,那麼問題很有可能出在這兩種不同的啓動方式上。
- 本着控制變量法的debug方式,我在linux上將子進程的啓動方式指定為了【spawn】,✅問題解決,程序成功運行
-
至此,雖然表面上問題解決了, 但我對解決此BUG的收穫只有:【spawn】大法好,對其他稍深層次的細節一無所知,遺留有一些關鍵問題:
- spawn是什麼
- fork是什麼
- 為什麼針對此BUG,spawn可以,fork不行
- 如果我們偏要用fork來做,行不行,怎麼做?
-
於是,又回過頭仔細看了官方文檔介紹以及 python官方issue討論區,(如下圖)
-
spawn與fork概念如下
- spawn:從頭構建一個子進程,父進程的數據等拷貝到子進程空間內,擁有自己的Python解釋器,所以需要重新加載一遍父進程的包,因此啓動較慢,由於數據都是自己的,安全性較高
- fork:除了必要的啓動資源外,其他變量,包,數據等都繼承自父進程,並且是copy-on-write的,也就是共享了父進程的一些內存頁,因此啓動較快,但是由於大部分都用的父進程數據,所以是不安全的進程
- fork有可能導致不安全的進程,是因為fork用到copy-on-write技術,會繼承父進程的數據和堆棧,由此導致一些不安全的問題。
-
那麼針對此BUG,具體是哪個地方導致了不安全呢?
- 既然是milvus連接出了錯,那先從連接下手,排查發現,
-
首先,主進程所在文件在import模塊的時候,其中一個模塊(文件)發起了一次milvus的連接,如下圖
-
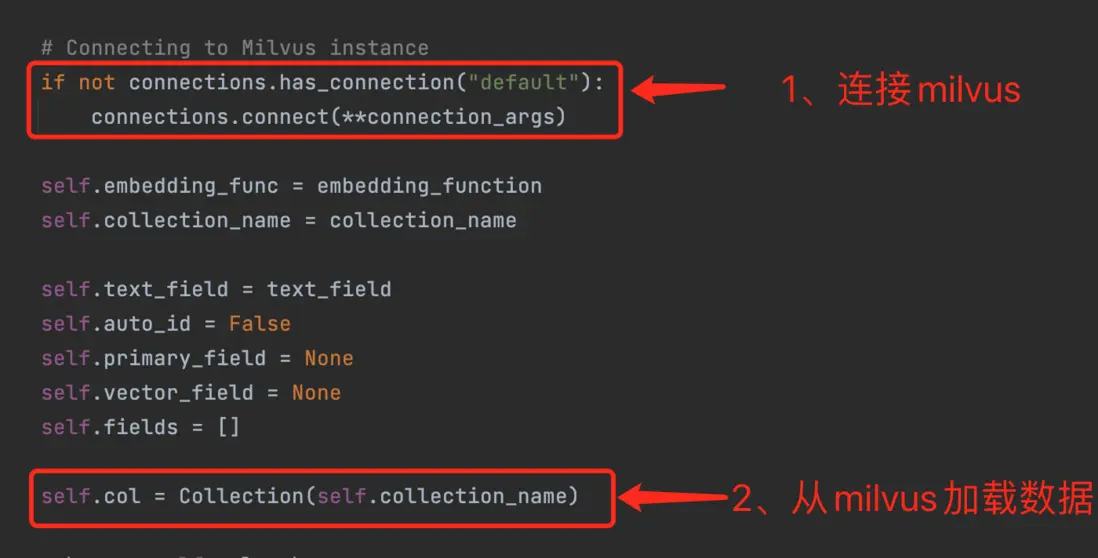
然後,主進程開始啓動子進程(fork),子進程調用langchain的milvus模塊,langchain中milvus連接初始化的代碼是這樣寫的
- 子進程在上圖中的步驟2的時候卡住,經排查是因為子進程根本沒有連上milvus,但是步驟1明明已經判斷過,如果沒有連接,則創建。
-
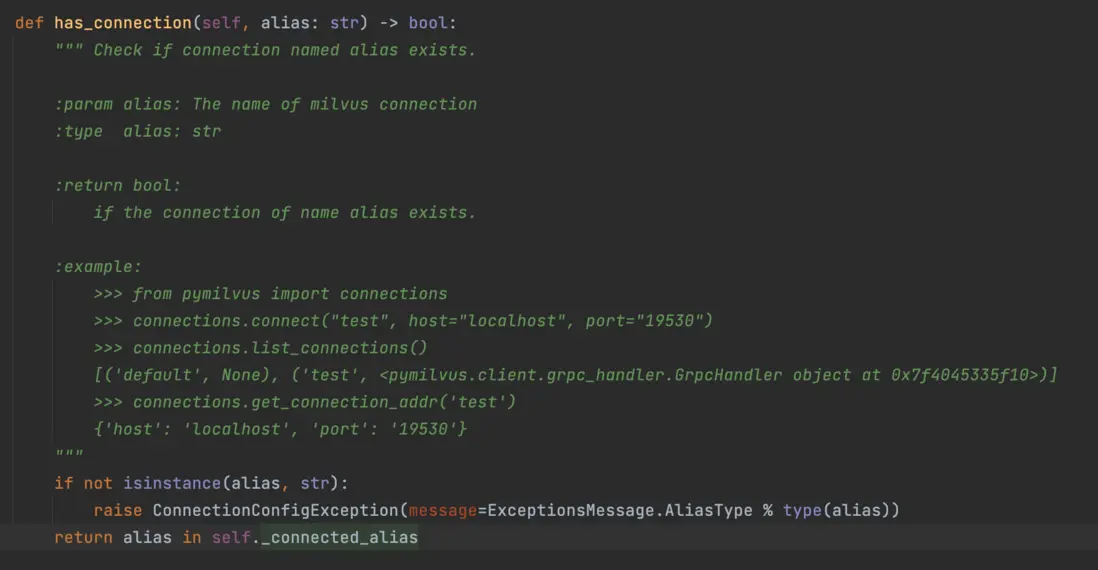
再進一步看看connections.has_connection("default")這個函數,如下圖
-
函數會判斷self._connected_alias變量中是否有記錄,進一步看看這個變量怎麼來的
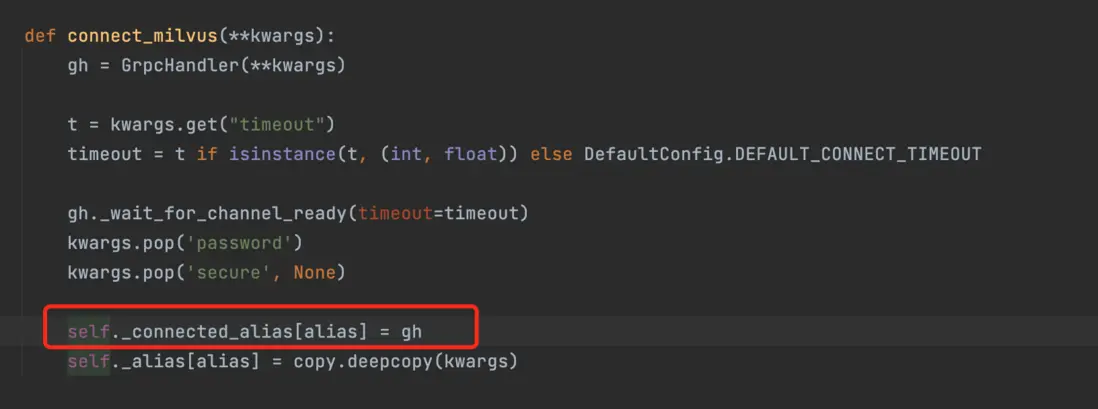
- 在連接milvus時,程序維護一個self._connected_alias變量來記錄是否存在連接,connections.has_connection("default")函數只是去self._connected_alias中檢查是否有連接記錄,
- 至此發現問題關鍵所在,父進程在第一次連接milvus的時候,程序在self._connected_alias變量中記錄了連接信息,當fork子進程的時候,self._connected_alias變量被一併繼承給了子進程,而當子進程使用connections.has_connection("default")函數判斷與milvus的連接狀態的時候,發現了從父進程繼承過來的self._connected_alias變量的已連接信息,於是判斷為已有連接,導致子進程在實際沒有連接milvus的情況下直接加載milvus的數據,引發錯誤。
-



五、解決方案
解決方案1
方案
- 採用spawn方式啓動子進程
優點
- 簡單粗暴,子進程和父進程獨立,數據隔離,進程安全
- 拓展和維護相對方便,不用擔心類似的BUG
不足
- spawn方式,會老老實實地copy父進程的數據(即使不需要),比較佔內存空間,啓動會慢一些
解決方案2
方案
-
採用fork方式啓動子進程,需要對代碼做如下修改
-
如果可以刪除主進程中連接milvus的代碼
- 將milvus連接工作都放到子進程中做
-
如果不能刪除主進程中連接milvus的代碼
- 在子進程判斷與milvus是否已連接的時候,不採用connections.has_connection("default")函數,而是查看本進程自身的套接字連接,避免來自父進程繼承髒數據的污染,需要新增have_socket函數,做法如下
def have_socket(): have_socket = False process_netstat = psutil.Process(os.getpid()) for _socket in process_netstat.connections(): if _socket.raddr.port == MILVUS_PORT: have_socket = True return have_socket if not have_socket(): connections.connect(**connection_args) -
優點
- 採用fork,子進程啓動快,通過優化代碼邏輯,避免進程不安全的情況
不足
- 後續的代碼拓展和維護都要注意代碼邏輯,避免類似BUG
六、總結
- 寫多線程/多進程代碼的時候,需要注意具體代碼邏輯,避免繼承的髒數據導致線程/進程不安全
- 對於資源約束不大,性能要求不高的場景,多進程一律用spawn
七、號外
-
【python開發組消息】將spawn在所有平台上設置為默認選項已經提上日程 ,計劃3.14版本正式上線
- https://discuss.python.org/t/switching-default-multiprocessin...
-
【fork的優點和應用場景】fork也不是一無是處,對於只讀數據需要共享的情況,還是非常省內存資源,
- 比如編寫模型預測的併發服務,fork只加載1份模型到內存,而spawn會加載N份,gunicorn的-preload參數就是基於fork的copy-on-write技術,達到模型只加載一次的目的
In general, fork is bad, but it's also convenient and people rely on it to prepare data in a main process and then "duplicate" the process to inherit cooked data. -Victor Stinner
版本信息
- python3.11.4
- langchain==0.0.146
References
- Python crashes on macOS after fork with no exec
- multiprocessing's default posix start method of 'fork' is broken: change to 'spawn’
- Multiprocessing causes Python to crash and gives an error may have been in progress in another thread when fork() was called
- 機器學習模型API多進程內存共享
- 寫時複製
- https://docs.python.org/3/library/multiprocessing.html
- https://discuss.python.org/t/switching-default-multiprocessin...