

導讀
在數字化時代,企業對用户數據的挖掘和分析能力直接影響業務增長和競爭力。圖靈數據洞察平台(TDF) 是一款面向企業的數據分析與用户增長平台,提供一站式的行為數據生產、用户行為分析、及廣告效果評估等功能。它能夠利用多維分析模型深入洞察用户行為,助力精細化運營。圖靈數據洞察平台還支持數據可視化和智能分析,幫助企業優化營銷策略,提高用户轉化和留存率。本文將詳細介紹圖靈數據洞察平台的核心功能、應用場景及其在提升數據決策效率和驅動業務增長方面的優勢,為企業提供數據智能化運營的最佳實踐。
01 平台背景
1.1 背景
百度MEG上一代大數據產品存在平台多、質量參差不齊和易用性差的問題。這些問題導致開發人員面臨較高的研發依賴、開發效率低下和高昂的學習成本;業務部門則感知需求支持遲緩、數據產出延遲及數據質量低的問題。
圖靈3.0旨在解決舊有大數據產品使用分散且技術相對落後的問題。
圖靈3.0是一個覆蓋數據全生命週期的強大生態系統,支持全鏈路的數據操作,包括數據計算引擎、數據開發和數據分析三個核心部分:
- TDE(Turing Data Engine):圖靈生態的計算引擎,包含Spark計算引擎和ClickHouse。
- TDS(Turing Data Studio):一站式數據開發治理平台。
- TDA(Turing Data Analysis):新一代可視化BI產品。

△圖靈3.0生態
1.2 問題
- 目前圖靈生態內的可視化BI產品TDA聚焦於宏觀分析,依賴用户自建的聚合後的數據集,缺乏對產品用户明細行為的關注分析。
- 宏觀的數據報表基於固定的分析目標建模,建設週期長,關注點相對固定,分析新視角的更新依賴於數據開發工程師,且存在計算資源重複消耗。
- TDA下分析模式關注宏觀趨勢,分析與圖表也以宏觀趨勢為主,缺少漏斗用户路徑之類明細視角的深度分析即相關方法論落地能力,對增長中用户留存、流失等問題的深層次歸因缺乏整體的解決方案,依賴分析師的經驗預建模,無法靈活快捷分析。
- 新產品和營銷活動很難及時看到留存、轉化等效果,難以複用過往沉澱的分析模型,依賴數據開發工程師全程跟進,響應週期長。
- 業界對增長分析普遍關注有很多成熟產品,如Mixpanel、Google Analytics、Amplitude、字節火山引擎等,需要快速跟進完善分析能力。
基於以上問題,我們建設了數據洞察平台(增長分析平台Turing Data Finder), 以下簡稱TDF。
1.3 與TDA平台的差異
有相關同學可能瞭解過TDA平台,它屬於meg下的可視化數據分析產品,TDA與TDF在分析的數據、數據存儲使用、關注的問題等方面都有較大的區別。
TDA的產品定位是一個可以實現用户一站式自助查詢的BI平台,用户可以自由拖拽數據集,進行可視化數據分析,並進行核心儀表盤的搭建。分析模型如留存分析數據模型一般在數據生產階段完成,然後在TDA平台多樣化展示。
TDF更專注於數據增長分析,是一站式用户分析與運營平台,旨在為增長場景的數據分析帶來全自動、全流程的解決方案,提升全流程迭代效率和分析深度,內部聚合多種高級分析模型,靈活洞察用户全生命週期的行為表現,從而發現指標背後增長的可能。分析模型在分析階段打造,平台基於明細數據和用户選擇的分析場景生成分析數據模型後展示查詢結果。

△功能對比
02 平台整體架構介紹
TDF平台致力於打造全自動的、全流程的解決方案用於提升用增場景數據分析的深度,適配核心業務增長需求。
整體架構如下:

整體流程為數據開發工程師產出固定格式的ck明細日誌後,用户在明細日誌的基礎上進行用户行為分析和用户分析,分析結果可保存至儀表盤。接下來從數據接入與管理、增長分析、儀表盤等方面對TDF功能進行詳細的描述。
03 數據接入與管理
3.1 數據接入
日誌中台數據接入流程如下:
- 用户在TDF選擇需要從日誌中台同步的頁面;
- TDF定時同步頁面對應的事件meta數據;
- TDF定時輸出同步的meta數據給數據rd;
- 數據rd根據meta數據處理日誌中台日誌輸出數據到ck;
對於非日誌中台的日誌,用户需要給TDF平台提供固定格式的事件meta信息。
3.2 標明細數據規範
因為增長分析場景複雜,很難針對不同的業務線的不同的用户行為表結構做定製化的sql模版開發,所以定義統一的明細數據規範,用户按照規範生成固定格式的數據,表模版字段如下:
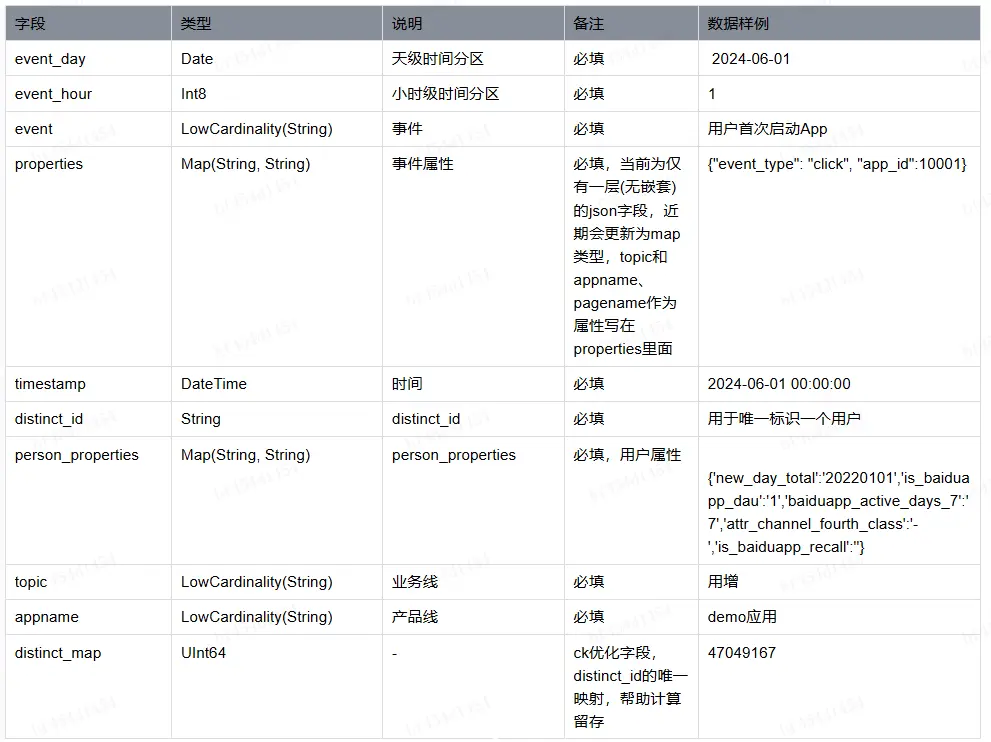
3.3 數據管理
事件管理:事件管理支持新建事件、刪除事件、支持設置必要屬性(對於日誌中台事件,必要屬性不符合需求的事件會過濾)。
虛擬事件管理:用户可基於已有的元事件及事件屬性建設虛擬事件,在分析時可選擇虛擬事件進行分析。

屬性管理:可管理屬性、管理屬性枚舉值、為屬性綁定事件。
04 增長分析
4.1 事件分析
事件分析支持用户進行屬性篩選以及分組後計算不同的指標,,對用户行為進行多維分析,並提供多樣化的可視化圖表。也可以選擇人羣包查看人羣在不同事件中的表現。事件分析方便用户掌握產品不同功能的使用情況,可以快速展開多維下鑽分析,配置出業務相關的分析指標。

△配置填寫

△圖展示

△表格展示
- 支持的指標:pv、uv、人均次數、按任意屬性去重、按任意屬性求和。

△指標選擇
- 支持多種圖表類型,對於分天數據包括折線圖、柱狀圖、面積圖等,對於總數包括餅圖、柱狀圖等。
- 支持多個自定義公式,可按照數值和百分比展示。

△多公式支持
- 支持與上期日期對比。
4.2 留存分析
留存分析用於衡量用户在一段時間內持續使用產品或服務的情況。它能幫助企業評估用户粘性、產品價值以及優化用户體驗,以提高用户的留存率和忠誠度。方便對升級或活動所影響用户羣體的留存率進行監控分
用户通過在頁面選擇起始事件(是指用户在特定時間段內完成的某個事件),回訪事件(是指在起始事件之後,用户在特定時間段內再次完成的某個事件),以及篩選事件的屬性和分組,查看在不同維度下回訪事件相對於起始事件的n天(可選是當日留存還是累計留存)。

△條件篩選

△結果展示
- 不同位置的篩選作用於不同的事件,右側的篩選作用於兩個事件。
- 支持累計留存,累計留存是n天內回訪事件的回訪人羣累計相對於起始事件的留存率。
4.3 漏斗分析
分析概述
漏斗模型通過分析用户流程中轉化流失情況,反映用户行為狀態以及從起點到終點各階段用户轉化情況,通過分析整個過程的轉化率以及每一層的轉化率,可以幫助我們明確優化的方向,找到轉化率低的節點,進而可以定位用户流失的環節和原因。
用户通過按順序選擇漏斗中參與的事件、對事件屬性進行篩選、添加分組,可查看不同維度下用户在一系列事件中的轉化情況。

△條件篩選

△結果展示
- 可查看轉化步驟,也可查看轉化趨勢,轉化趨勢是看選定的事件中事件a到事件b每天的轉化情況。
- 轉化率計算時可與前一事件相比也可與起始時間相比。
3)分析主體切換,配置後支持切換分析主體,默認分析視角是用户數查看用户的流向,在左上角切換後可選擇比如商户、訂單等查看這些主體的流轉情況。

△分析主體切換
4.4 用户路徑
用於記錄和分析用户在各個事件之間的流轉過程,通過可視化的用户流量流轉圖高效查看分析用户在各個頁面中的行為分佈,用户路徑通過分析這些事件的序列和流向,可以洞察用户的行為模式、偏好以及在不同頁面或功能間的轉換效率。
用户通過選擇起始事件和參與的事件、對事件屬性進行篩選,可查看用户在所選的一系列事件中的流轉情況和轉化率。

△條件篩選

△結果展示
1)用户選擇起始時間後可選擇參與分析也可不選擇,不選擇參與分析的時間則能流轉到任意事件,否則只能流向起始時間和參與分析的時間以及others
2)通過限制但級別最大節點數來限制每層級的最大node數據,顯示的node表示這一層級流向的top事件。
3)通過日期組件旁邊的步數選擇來控制層級數量。最少2步、最多5步。
4.5 成分分析
查看目標羣體(通過用户做過的事和固定屬性確認)的屬性分佈和對比, 成分分析通過分析一些典型屬性如手機品牌、用户年齡、新老用户等場景,可以幫助我們全盤掌握用户公共屬性的分佈情況,輔助我們進一步優化運營策略。
用户在左側選擇需要查看的成分,右側通過篩選用户做過的事件和其他固定屬性值確認分析的目標羣體,可查看目標羣體在不同成分下的用户量對比。

△條件篩選

△結果展示
1)可選多個屬性(最多5個)查看分析,非交叉分析時每個屬性的結果單獨顯示,交叉分析時顯示屬性的多個組合結果
2)可選擇人羣對照組(最多5個),對照結果並排顯示
3)可切換柱狀圖顯示比例
4.6 分佈分析
分佈分析指在整體或某一維度下,按照計算結果劃分出一些區間,查看對應人數在各區間內的分佈情況。分佈分析有很多種類,比如按事件發生頻次查看人數分佈、按屬性值計算結果查看人數分佈、按一段時間內累計發生的時長或天數查看人數分佈等,可用於分析用户的頁面功能的滿意度情況。
用户通過選擇想要查看的事件、屬性篩選,選擇分佈區間算法和間隔後,可以從不同的分組查看用户實現該事件次數的分佈狀況。

△條件篩選

△結果展示
1)分佈區間可以按照sturges算法計算,也可以自定義區間。自定義區間可以自由定義幾等分、按多少間隔分隔總共多少組,也可以完全自由定義,用户自由限制每個區間範圍。

△自定義等分

△自定義區間

△自定義組數和間隔
2)是否整體用於計算在這段時間內用户整體的分佈,這段時間內的用户整體去重。
3)展示結果圖表右上角可選pv和佔比,與默認展示的用户數自由組合。
4)可切換分析主體,默認分析視角是用户數,在左上角切換後可選擇比如商户、訂單等。
5)可選其他指標的去重分佈,默認為次數。
4.7 歸因分析
歸因分析主要用於查看用户選擇的多個待歸因事件對最終結果事件的轉化貢獻,通過歸因分析也可查看事件發生與目標事件發生之間的相關性。
用户選擇目標事件和待歸因事件,添加篩選條件後,可查看每個事件和目標事件的相關性,以及對整體目標出發的貢獻。

△條件選擇及結果展示
1)用户可選擇是否添加過程事件,添加過程事件表示用户在放生目標事件前必須發生過程事件才算做一次轉化。
2)相關係數採用皮爾森相關係數算法計算。
3)同時計算其他歸因節點默認不選擇時只計算歸因事件的轉化,選擇時則計算所有目標事件的轉化,將非待歸因事件彙總為others事件。
4)歸因方法可選首次歸因、末次歸因、線性歸因。
5)歸因窗口可調整,在歸因窗口期內即發生目標事件又發生待歸因事件切符合歸因算法,則算做一次待歸因事件對歸因事件的轉化。
05 增長分析效率優化
增長分析關注的是用户行為明細數據數據量大,同時留存、漏斗、用户路徑等分析場景模型複雜涉及到多層sql嵌套和長時間跨度的數據,平台會面臨較大的查詢壓力。我們從多個方面對查詢效率進行了優化。
1. 數據模型簡化
1)合併用户數據和事件明細數據將關聯前置到數據生成階段,避免查詢時大表關聯
2)拆分業務線不同活動數據至不同分區,最小化查詢數據集。
2. 分析模型邏輯優化
1)切分分析邏輯至查詢最小粒度,多線程獲取查詢結果,在內存中合併獲取最終結果。如事件分析中不同事件結果並行獲取、成分分析中不同成分和對照組交叉時並行獲取。
2)業界高效方案應用。如留存場景取用户羣交集時使用Roaringbitmap方案,按位計算,極大提升查詢效率。
3. 複雜字段物化與數據緩存
1)由於明細數據必須使用固定模版,所以對於多樣化的事件屬性、用户屬性需求,這些屬性統一存放在map字段中,查詢時會拉低查詢的效率。目前依據業務經驗,對常用的部分屬性進行物化,後期會根據查詢日誌獲取高頻查看屬性列表,自動物化高頻屬性。
2)觸發緩存和定時緩存結合,優化高頻報表查詢效率。用户觸發緩存:按照用户查詢條件緩存數據查詢結果。定時緩存:對於高頻的慢查詢報表,根據明細數據表是否發生變更決定緩存更新頻率,未發生變更時拉長緩存更新頻率,發生變更則立即更新緩存。
06 總結與展望
TDF平台作為圖靈3.0系統的新成員,作為一個全新的平台,功能已基本對齊業界競品, 目前在用增、搜索等數據團隊推廣使用中。目標是通過平台基礎數據分析能力,以數據為驅動為用户增長提供有效的線索,給產品、運營和分析師等提供新的增長分析思路。
展望未來,TDF平台有望在以下幾個方面進一步發展和完善:
- 智能化助力數據分析:AI交互,探索數據智能洞察
- 多平台分析聯通與交互:與TDA平台儀表盤打通,在同一儀表盤內數據從宏觀分析深入到日誌級別增長分析;與其他平台(如人機平台)交互,擴大人羣分析能力和使用範圍。
- 分析場景拓展:接入更多的數據源,支持更多的業務場景;拓展分析場景如ahamoment、LTV等,多角度為增長分析提供線索;提升分析效率,高效服務用户
總體而言,TDF平台將持續完善自身能力,通過不斷的技術創新和功能完善,提升增長分析的深度、適配業務增長的需求,在增長分析中發揮重要作用。
----------END----------
推薦閲讀
兩連發!文心大模型4.5及X1,上線千帆!
百度百舸萬卡集羣的訓練穩定性系統設計和實踐
LLM增強語義嵌入的模型算法綜述
持續推進“人工智能+”行動,百度智能雲+DeepSeek為何成為國有企業首選?
