

導讀
本文介紹了優化大數據計算中多維度用户數統計的方法,通過數據打標的方式避免數據膨脹,提高性能並減少計算成本。首先分析了大數據計算中遇到的多維度數據統計問題,然後提出了利用數據打標進行處理的解決方案,詳細闡述了優化方案的實施步驟和效果。通過對比實驗結果,驗證了優化方案在提升性能和降低成本方面的顯著效果。最後,總結了優化方案的優勢和適用場景。
01 背景
Feed是百度App的一個重要業務組成部分,日均DAU(活躍用户數)規模在億級別。在做數據分析和統計的時候,常常需要從不同日誌維度去看對應的用户數。由於用户數不同維度不可累加的特性,基本上所有維度的用户數都需要單獨計算,維度少的時候可以直接 count(distinct xx) 計算,維度多的話這種計算就相當痛苦了。
一個典型的場景如下:業務方需要從產品線、付費類型、資源類型、頻道類型、頁面類型等維度來看Feed的消費用户數。除了計算各個維度組合的用户數外,每個維度還需要看到整體的用户數。所需的結果數據表格如下(其中維度與指標均為虛構):
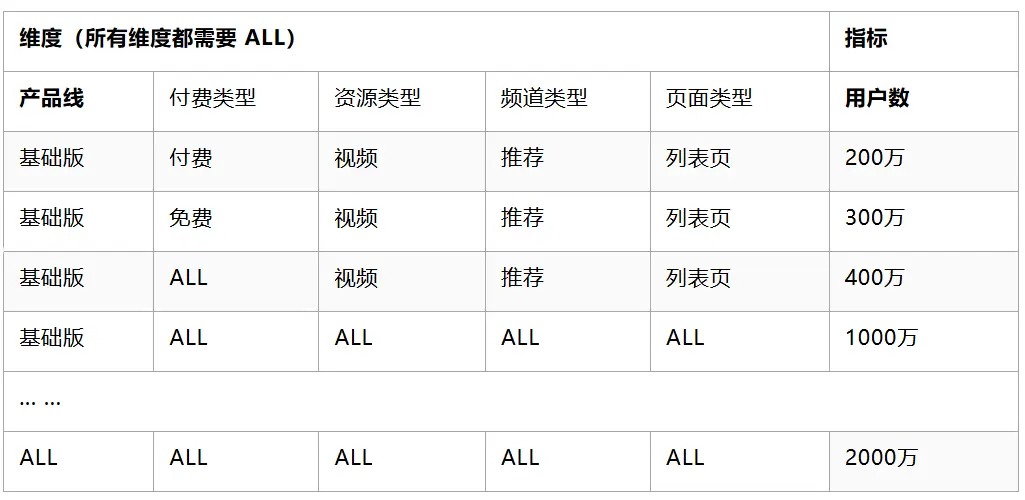
02 通用實現方式
常見的實現方式是直接計算,單獨計算每個維度的用户數指標。
將原始數據按 cuid+初始維度 去重後,使用 lateral view explode 將數據從一行膨脹成多行,然後直接 distinct 的數據計算方式。
2.1 核心思路

2.2 代碼實現
-- 表名:feed_dws_kpi_dau_1d
-- 字段名及註釋:appid##產品線,pay_type##付費類型,r_type##資源類型,tab_type##頻道類型,page_type##頁面類型,cuid##用户標識
select
appid_all, -- 產品線
pay_type_all, -- 付費類型
r_type_all, -- 資源類型
tab_type_all, -- 頻道類型
page_type_all, -- 頁面類型
count(distinct cuid) as feed_dau
from(
select
cuid,
appid,
pay_type,
r_type,
tab_type,
page_type
from feed_dws_kpi_dau_1d
group by 1,2,3,4,5,6
) tab
lateral view explode(array(appid, 'all')) B as appid_all
lateral view explode(array(pay_type, 'all')) B as pay_type_all
lateral view explode(array(r_type, 'all')) B as r_type_all
lateral view explode(array(tab_type, 'all')) B as tab_type_all
lateral view explode(array(page_type, 'all')) B as page_type_all
group by 1,2,3,4,5
03 優化方式
新的優化思路可以理解為在數據處理過程中採用一種“數據打標”策略,通過在數據去重的基礎上生成用户粒度的中間數據,並在此基礎上動態附加所需的結果維度信息。這樣做的好處是可以將數據處理的重點集中在用户粒度的中間數據上,避免數據膨脹和冗餘傳輸,同時通過編號化結果維度信息,採用更小的數據結構進行存儲,從而降低數據處理的計算成本。
這種優化方法實際上是在數據處理過程中引入了一種“增量式”計算思想,即隨着計算的進行,數據量逐漸收斂而不會無限增加。通過在中間數據上動態附加結果維度信息,可以避免在計算過程中重複傳輸和處理大量冗餘數據,提高數據處理的效率和性能。
總的來説,這種優化思路旨在通過精細化數據處理流程,減少不必要的數據傳輸和計算成本,從而提升整體數據處理的效率和性能。
3.1 核心思路

核心計算思路如上圖,普通的數據膨脹計算用户數的方法,中間需要對數據進行膨脹,再聚合,其中數據膨脹的倍數是維度數的平方(只擴展“整體”的情況),如上兩個維度預計數據膨脹 2^2=4 倍,三個維度的話就是膨脹 8倍。
而新的數據聚合方法,通過一定的策略方法將維度組合拆解為維度小表並進行編號,然後將原始數據聚合至用户粒度的中間過程數據,其中各類組合維度轉換為數字標記錄至用户維度的數據記錄上,理論上整個計算過程數據量是呈收斂聚合的,不會膨脹。
3.2 邏輯分析
3.2.1 原創數據樣例
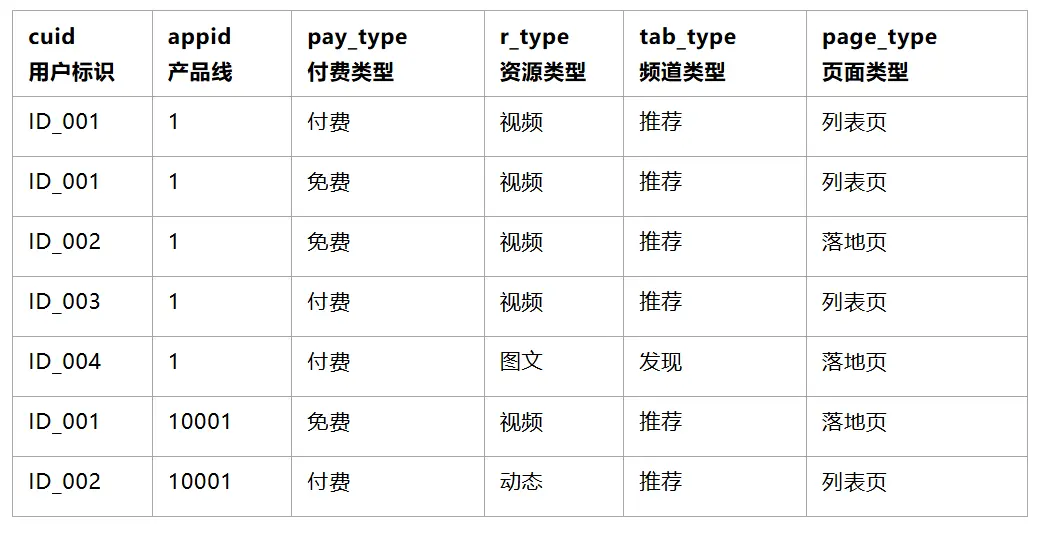
3.2.2 基於明細數據產出維度結果數據,並進行編碼(可使用窗口函數 DENSE_RANK() )
PS:基於可讀性,只列舉兩個字段(appid,pay_type)
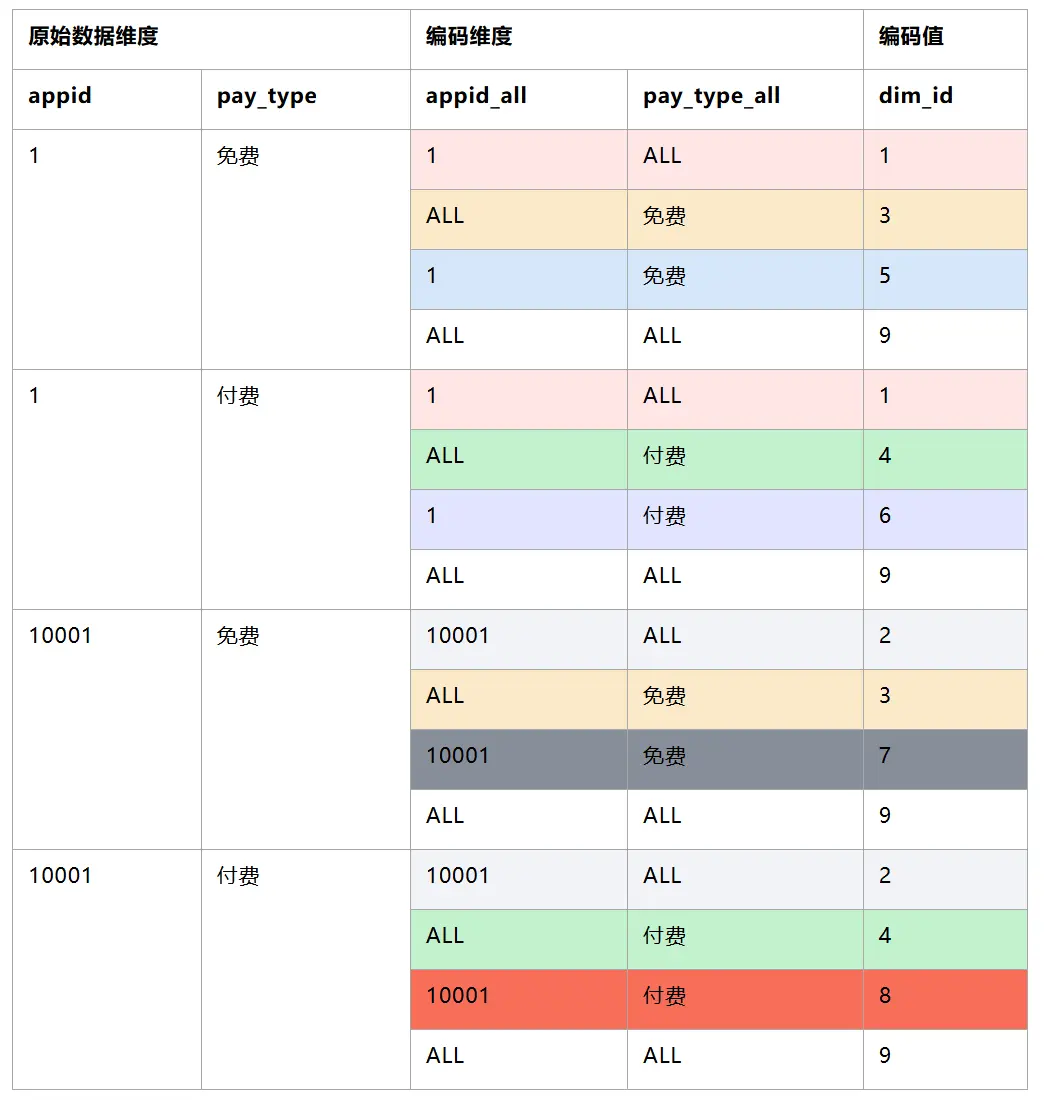
3.2.3 將1產出的編碼表,通過原始數據維度關聯,寫回到用户明細上(可使用 MAPJOIN)
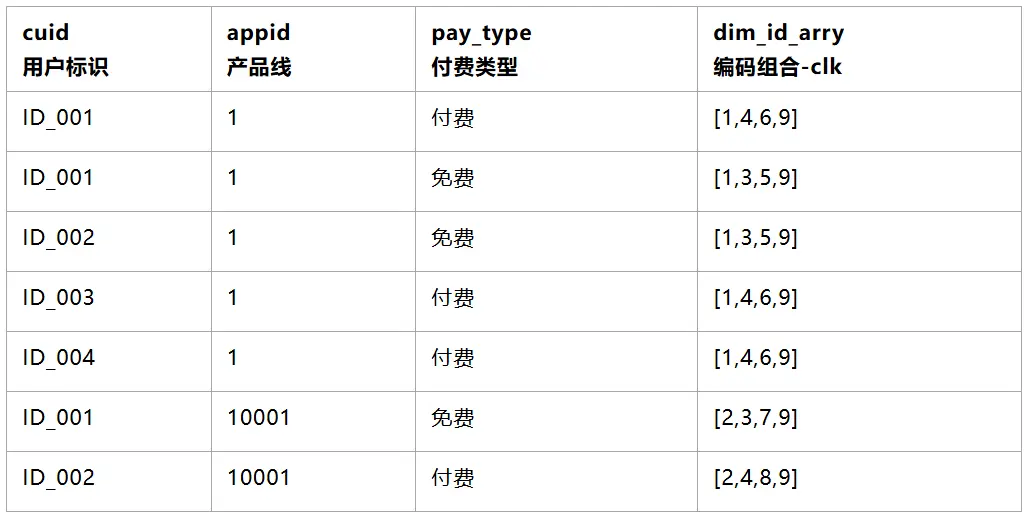
3.2.4 編碼彙總到用户粒度上(可使用array_distinct)
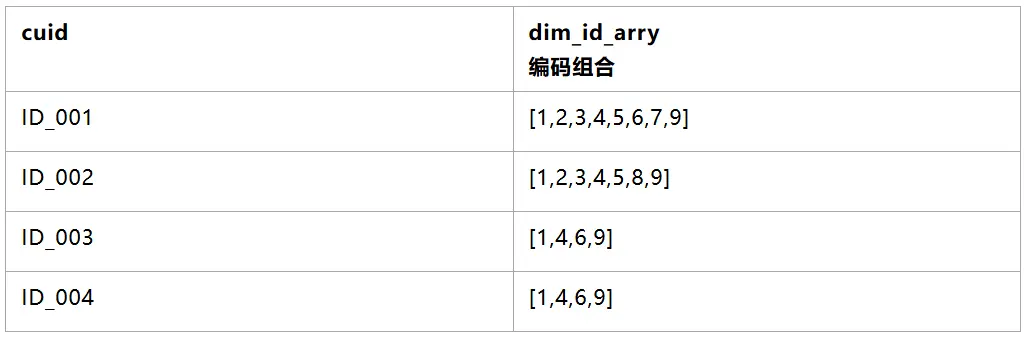
3.2.5 統計每個編碼id出現的次數,並關聯產出編碼原始維度
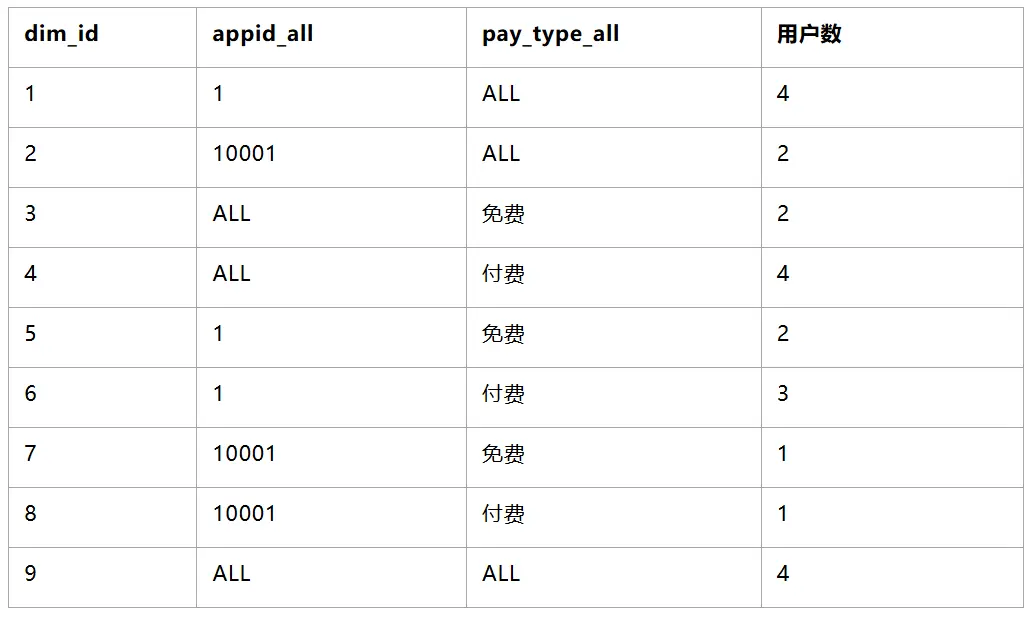
3.3 代碼實現
-- 基於明細數據產出維度結果數據,並進行編碼
with dim_res as (
select
distinct
appid_all, -- 產品線
pay_type_all, -- 付費類型
r_type_all, -- 資源類型
tab_type_all, -- 頻道類型
page_type_all, -- 頁面類型
dim_key,
DENSE_RANK() OVER(ORDER BY appid_all,pay_type_all,r_type_all,tab_type_all,page_type_all) AS dim_id
from(
select
appid,
pay_type,
r_type,
tab_type,
page_type,
concat_ws(
'#',
coalesce(appid,'unknow'),
coalesce(pay_type,'unknow'),
coalesce(r_type,'unknow'),
coalesce(tab_type,'unknow'),
coalesce(page_type,'unknow')
) as dim_key
from feed_dws_kpi_dau_1d
group by 1,2,3,4,5,6
) t0
lateral view explode(array(appid, 'all')) B as appid_all
lateral view explode(array(pay_type, 'all')) B as pay_type_all
lateral view explode(array(r_type, 'all')) B as r_type_all
lateral view explode(array(tab_type, 'all')) B as tab_type_all
lateral view explode(array(page_type, 'all')) B as page_type_all
),
-- 生成cuid聚合數據+對應的維度編碼組合
cuid_dim as(
select /*+ MAPJOIN(t1) */
cuid,
array_distinct(split(concat_ws(',',collect_set(concat_ws(',',dim_id_arry))),',')) as click_dim_id_arry
from(
select
cuid,
concat_ws(
'#',
coalesce(appid,'unknow'),
coalesce(pay_type,'unknow'),
coalesce(r_type,'unknow'),
coalesce(tab_type,'unknow'),
coalesce(page_type,'unknow')
) as dim_key
from feed_dws_kpi_dau_1d
group by 1,2
) t0
join (
-- 生成每個維度原始值對應的編碼數組,減少shuffle過程的數據量
select
dim_key,
collect_set(dim_id) as dim_id_arry
from dim_res
group by dim_key
) t1 on t0.dim_key = t1.dim_key
group by cuid
)
-- 將維度編碼回寫為原始日誌
select /*+ MAPJOIN(t1) */
appid_all, -- 產品線
pay_type_all, -- 付費類型
r_type_all, -- 資源類型
tab_type_all, -- 頻道類型
page_type_all, -- 頁面類型
feed_dau
from(
select
-- 基於維度編碼進行計數
dim_id,
sum(feed_dau) as feed_dau
from(
-- 將維度數組轉為字符串直接求和
select
concat_ws(',',click_dim_id_arry) as dim_id_str,
count(1) as feed_dau
from cuid_dim
group by 1
) tab
lateral view explode(split(dim_id_str,',')) B as dim_id
group by dim_id
) t0
join (
select
distinct
appid_all, -- 產品線
pay_type_all, -- 付費類型
r_type_all, -- 資源類型
tab_type_all, -- 頻道類型
page_type_all, -- 頁面類型
dim_id
from dim_res
) t1 on t0.dim_id = t1.dim_id
order by 1,2,3,4,5,6
3.4 實現案例分析
本部分展示的是我們業務過程中的實際案例,原始日誌 4.5 億條,業務多維分析所需維度 9 個,每個維度都需要保留“整體”項。以下列出了不同方式的實際執行情況,任務運行基於相同的運行隊列與資源配置,經驗證數據產出的結果一致。
3.4.1 lateral view + distinct 方式
結論:整體運行時間 49分鐘,最耗時的stage為數據擴展階段,stage shuffle量達16TB,不具備優化空間。

△Stage執行情況

△lateral view將數據從 3.3億條擴展到 1707億條
3.4.2 維度編碼方式
結論:整體運行時間 14 分鐘,耗時主要集中在對所需維度進行編碼排序的過程(Job 1/2),這部分如果例行的話,可以提前進行緩存,可優化。最大shuffle量 800GB,是針對cuid對應的維度編碼進行聚合,去重的過程。

△Job執行情況,Job 1/2為維度編碼排序階段

△Stage執行情況
3.4.3 當所需維度增加
後續,業務所需維度增加至12個,lateral view + distinct 預計shuffle量會達到 120TB 左右,執行失敗不出來。
採用維度編碼的方案可以順利執行,耗時主要集中在對所需維度進行編碼排序的過程(Job 1/2)。

△Stage執行情況
04 方案總結&後續跟進
常見的基於數據膨脹的用户數計算方法,數據計算大小和過程數據傳輸量將隨着維度的數量呈指數爆炸增長,維度數越多,花費在數據膨脹與Shuffle傳輸的資源和耗時佔比越高。
為了解決數據膨脹過程中產生的大量過程數據,基於數據標籤的思路反向操作,先對數據聚合為cuid+日誌維度粒度,過程中將需要的維度組合轉化編碼數字並賦予cuid數據上,整個計算過程數據呈收斂聚合狀,數據計算過程較為穩定,數據條數、shuffle量不會隨着維度組合的進一步增加而大幅增加。
綜上,當前的方案整體性能相較於以往有大幅度的提升,運行成本不會隨着維度組合的增加而指數增加。但當前的方案也有不足之處,即代碼的可理解性和可維護性。另外,當維度較少的時候,兩者的性能差異不大;但當維度增加時,可以改用這種數據打標的思路進行壓縮,此時的性能優勢開始凸顯,並且維度數越多,此方案的性能優勢越大。
目前,這種計算方案已經落地應用到Feed核心場景以及短劇業務多維用户數計算。支持Feed業務 10+維度、億級用户數的計算。
後續,我們計劃針對維度編碼的方案進一步優化。將代碼裏一些複雜的功能邏輯封裝成udf,包括數組字段聚合、數據字段聚合去重等功能函數;同時針對例行任務,提前將維度組合進行排序編碼。進一步加強代碼的可讀性與運行成本。
———— END ————
推薦閲讀
數據湖系列之四 | 數據湖存儲加速方案的發展和對比分析
大模型時代,雲原生數據底座的創新和實踐
百度滄海·存儲統一技術底座架構演進
計算不停歇,百度滄海數據湖存儲加速方案 2.0 設計和實踐
AI 原生時代,更要上雲:百度智能云云原生創新實踐