

編者按: 我們今天為大家帶來的文章,作者的核心觀點是:2025 年大語言模型的真正突破不在於參數規模的擴張,而在於訓練範式、智能形態與應用架構的深層轉變 —— 尤其是基於可驗證獎勵的強化學習(RLVR)、AI 作為“幽靈”而非“動物”的認知重構,以及面向垂直場景的新型 LLM 應用層的崛起。
文章系統回顧了 2025 年 LLM 領域的六大關鍵趨勢:首先,RLVR 成為新訓練核心,通過可自動驗證的獎勵信號,模型自發演化出類推理行為;其次,作者提出“召喚幽靈”隱喻,強調 LLM 智能與生物智能在底層邏輯上的根本差異,並解釋了其“鋸齒狀智能”——在某些任務上超人,在另一些任務上卻異常脆弱;第三,以 Cursor 為代表的新型 LLM 應用層,通過上下文工程、多調用編排與“自主性滑塊”,正在重塑人機協作範式;此外,Claude Code 展示了本地化 AI 智能體的潛力,vibe coding 讓編程走向大眾化,而 Google Gemini Nano banana 則預示了 LLM 圖形用户界面(GUI)的未來方向。
作者 | Andrej Karpathy
編譯 | 嶽揚
2025 年是大語言模型(LLM)發展勢頭強勁、進步顯著的一年。以下是我個人認為值得關注且略感意外的幾項“範式轉變”,這些改變技術格局的概念性突破讓我印象深刻。
01 基於可驗證獎勵的強化學習(Reinforcement Learning from Verifiable Rewards, RLVR)
2025 年初,各大實驗室的 LLM 生產訓練流程大致如下:
1)預訓練(GPT-2/3,~ 2020 年)
2)監督微調(InstructGPT,~ 2022 年)以及
3)基於人類反饋的強化學習(RLHF,~ 2022 年)
這套成熟方案曾長期被視為生產級 LLM 的訓練標準。然而到了 2025 年,基於可驗證獎勵的強化學習(RLVR) 成為被廣泛接受和採用的新核心訓練階段。通過在多種環境中(例如數學題或編程題這類場景)讓 LLM 針對可自動驗證的獎勵進行訓練,模型會自發地發展出一些在人類看來像是“推理”的策略 —— 它們學會將問題求解過程拆解為一系列中間計算步驟,並掌握多種來回試探、逐步釐清問題的解題策略(參見 DeepSeek R1 論文中的示例)。在原有範式下,這類策略極難實現,因為 LLM 並不清楚“最優的推理路徑”或“對錯誤的修正方式”究竟長什麼樣 —— 它必須通過針對獎勵信號的優化過程,自己摸索出對自己有效的方法。
與 SFT 和 RLHF 這兩個計算量相對較小、訓練週期較短的階段不同,RLVR 依賴於客觀(不可作弊)的獎勵函數,因此支持更長時間的優化。事實證明,RLVR 在單位算力下的能力提升(capability / $)非常高,導致原本用於預訓練的計算資源被大量轉移至此。 因此,2025 年大部分模型能力的提升,主要來自於各大 LLM 實驗室集中算力“消化”這一新訓練階段(RLVR)所釋放出的潛力。總體來看,我們看到的模型參數規模大致相當,但強化學習(RL)的訓練時長顯著增加。此外,這一新階段還帶來了一個全新的“調節旋鈕”(以及與之對應的縮放規律):通過生成更長的推理軌跡、增加“思考時間”,即可在推理時以更多計算換取更強能力。OpenAI 的 o1 模型(2024 年底)首次展示了 RLVR 的效果,但真正讓人直觀感受到質變的拐點,是 2025 年初發布的 o3 版本。
02 Ghosts vs. Animals / Jagged Intelligence
2025 年是我(而且我認為整個行業也是如此)第一次開始以更直覺、更切身的方式,理解 LLM 智能的“形態”。我們並非在“進化/培育動物”,而是在“召喚幽靈”。LLM 技術棧的方方面面 —— 包括神經網絡架構、訓練數據、訓練算法,尤其是目標函數對模型行為的塑造力(Optimization pressure)都與生物智能截然不同,因此我們所獲得的智能體在智能空間中自然也大不相同,用動物的視角去理解它們是不恰當的。 如果從監督信號的底層信息單位來看,人類的神經網絡是為了在叢林中保障部落生存而優化的,而 LLM 的神經網絡則是為了模仿人類文本、在數學難題中獲取可驗證獎勵,以及在 LM Arena 上贏得人類的一個點贊而優化的。隨着可驗證的領域支持 RLVR,大語言模型在這些領域及其周邊任務上的能力會出現“尖峯式”躍升,從而整體呈現出一種令人忍俊不禁的、起伏劇烈的鋸齒狀性能特徵,它們可能同時是一位通曉萬物的天才,又是一個充滿困惑且認知能力受限的小學生,甚至在幾秒內就被越獄攻擊(jailbreak)誘騙,導致你的數據被竊取。
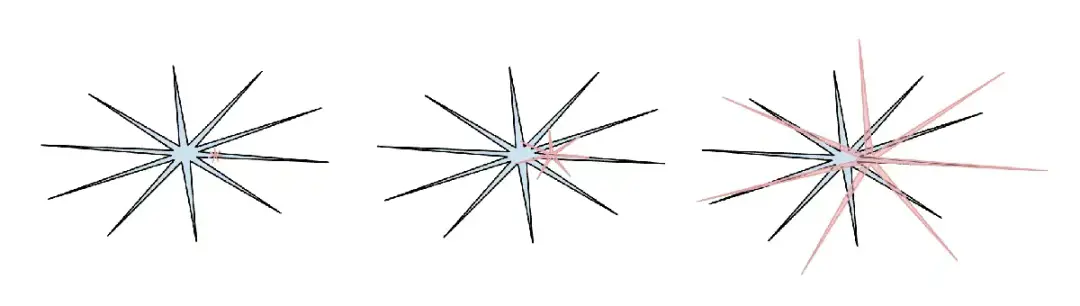
(人類智能:藍色,AI 智能:紅色。我很喜歡這個梗圖(很抱歉我找不到了它最初在 X 上的原始出處),因為它指出人類智能本身也以自己獨特的方式呈現出“鋸齒狀”。)
與上述現象密切相關的是,我在 2025 年對各類基準測試(benchmarks)普遍感到冷漠,並且不再信任它們。核心問題在於,基準測試(benchmarks)在設計上幾乎天然就是可驗證的環境,因此很容易被 RLVR(以及通過合成數據生成的較弱形式)進行針對性優化。現在的 LLM 團隊為了刷高 benchmark 分數,會圍繞那些測試題在模型“理解空間”裏的位置,大量生成類似題目來訓練模型,讓它只在這些點上變得超強,別的地方先不管。結果就是模型能力像鋸齒一樣 —— 榜單上分數爆表,實際用起來漏洞百出。而“變相在測試集上訓練”這件事,已經玩出了花,成了行業潛規則。
如果在碾壓所有基準測試(benchmark)的同時,卻仍未實現通用人工智能(AGI),那將會是一種什麼景象?
03 Cursor / 新的 LLM 應用層
關於 Cursor(除了它今年以火箭般的速度崛起之外),我覺得最值得注意的是:Cursor 不僅自己成功了,更重要的是它開創了一種新模式,大家突然意識到:“哦,原來 LLM 應用可以這樣做!”於是開始設想各行各業的“Cursor”。正如我今年在 Y Combinator 演講中所強調的(附有文字稿[1]和視頻[2]),像 Cursor 這樣的 LLM 應用,會為特定垂直領域(如編程、法律、設計等)將多次 LLM 調用打包並編排成一個整體工作流:
- 它們負責 “上下文工程”(context engineering)
- 它們在後台將多次 LLM 調用編排成日益複雜的 DAG(有向無環圖) ,並在此過程中精細權衡性能與計算成本
- 它們為“human-in-the-loop”中提供面向特定應用場景的圖形界面(GUI)
- 它們提供一個 “自主性滑塊”(autonomy slider) —— 允許用户動態調節 AI 的決策自由度
2025 年,業界大量討論都圍繞着這個新出現的應用層的“厚度”,LLM 實驗室(如 OpenAI、Anthropic 等)會吃掉所有上層應用,還是説 LLM 應用領域仍是廣闊天地,大有作為?我個人認為,LLM 實驗室會傾向於培養出一個“通才型的大學生”,而 LLM 應用則會通過注入私有數據、傳感器、執行器和反饋迴路,對這些“大學生”進行組織、微調,並真正激活成部署在具體垂直領域的“專業從業者”。
04 Claude Code / 駐守在我們計算機的 AI
Claude Code(CC)成為首個令大家信服的 LLM 智能體(Agent)範例 —— 它以循環迭代方式將工具使用與推理串聯起來,用於解決需要長時間、多步驟的複雜問題。此外,對我而言,CC 的另一個特點是:它運行在我們的本地計算機上,並直接利用我們本地的私有環境、數據和上下文。我認為 OpenAI 在這一點上判斷有誤,因為他們早期在 Codex / 智能體(agent)方面的嘗試,聚焦於通過 ChatGPT 編排雲端容器中的智能體,而不是直接在用户的本地機器(localhost)上運行。儘管雲端運行的智能體集羣(agent swarms)聽起來像是“AGI 的最終形態,但我們正處在一個能力“鋸齒狀”、演進緩慢的中間階段,在這種背景下,讓智能體直接運行在開發者本機上反而更合理。
需要注意的是,真正關鍵的區別並不在於“AI 運算”(AI ops)到底跑在哪兒(雲端、本地,或其他地方),而在於其他因素 —— 那台已經開機並運行着的電腦,以及它上面已安裝的軟件、當前上下文、數據、密鑰、配置,還有低延遲的交互體驗。
Anthropic 正確把握了這一優先級,並將 Claude Code(CC)打造成一個精巧的、極簡的命令行(CLI)形態,這種形態徹底改變了人們對 AI 的認知:它不再只是一個像 Google 那樣需要你主動打開瀏覽器去訪問的網站,而更像是一個“寄居”在你電腦裏的小精靈(或幽靈)。這是一種與 AI 交互的全新且截然不同的範式。
05 Vibe coding
2025 年,AI 的能力達到了一個質變的臨界點:人們現在能僅通過自然語言就構建出各種令人為之驚歎的程序,甚至完全不用去想“代碼”本身的存在。説來好笑,我是在一條思緒如泉涌的推文[3]中隨口創造了 “vibe coding”(氛圍編程)這個詞,當時根本沒想到它居然火了 :)。通過 vibe coding,編程就不再是經過大量訓練的專業人士的專屬領域,而是任何人都能上手的事情。從這個角度看,它再次印證了我在《Power to the people: How LLMs flip the script on technology diffusion》[4]中寫到的觀點:與迄今為止幾乎所有其他技術都不同,普通大眾從 LLM 中的獲益遠大於專業人士、企業和政府。
但 vibe coding 的意義不僅在於幫助普通人接觸編程 —— 它也讓受過專業訓練的開發者能夠寫出大量原本根本不會被實現的(vibe coded)軟件。
在 nanochat 中,我用 vibe coding 自己寫了一個高度定製的、高效的 Rust 版 BPE tokenizer,且無需依賴現成的庫,也無需深入學習 Rust。今年我用 vibe coding 快速做出了許多小應用原型,只為實現我腦中那些一閃而過的想法(例如:menugen[5]、llm-council[6]、reader3[7]、HN time capsule[8])。我甚至用 vibe coding 寫過一整個臨時應用,只為定位一個 bug —— 為什麼不呢?畢竟代碼突然變得成本極低(free)、短暫(ephemeral)、可塑(malleable)、用完即可丟棄(discardable after single use)。Vibe coding 將重塑軟件生態,並徹底改變開發相關崗位的職責描述。
06 Nano banana / LLM GUI
Google Gemini Nano banana 是 2025 年最具顛覆性、最能推動範式變革的模型之一。在我的世界觀中,大語言模型(LLMs)是繼 1970、80 年代計算機之後的下一個重大計算範式。因此,出於本質上相似的原因,我們將會見證類似類型的創新。我們將看到類似於“個人計算”、“微控制器”(認知核心)或“互聯網”(智能體網絡)等事物在 AI 時代的對應形態。
尤其是在 UI/UX 方面,“與 LLM 對話”有點像在 1980 年代向計算機終端輸入命令。文本是計算機(以及 LLM)的原始/首選數據表示形式,卻並非人類偏好的交互格式 —— 尤其是在輸入端。事實上,人們並不喜歡閲讀大段文字,因為這既慢又費力。相反,人們更傾向於以視覺化、空間化的方式接收信息,這正是傳統計算(traditional computing)中圖形用户界面(GUI)被髮明的原因。
同理,LLM 也應該用我們偏好的格式與我們對話 —— 比如:圖片、信息圖、幻燈片、白板、動畫/視頻、網頁應用等。
當然,這種理念的早期形態和當前版本,是像 emoji 和 Markdown 這樣的東西 —— 它們本質上是通過標題、加粗、斜體、列表、表格等方式對文本進行“視覺裝飾”和排版,來提升可讀性。
但究竟誰會真正構建出 LLM 的 GUI(圖形用户界面)?
在這一世界觀下,Nano banana 是對此未來形態的一次早期預示。更重要的是,Nano Banana 的意義,不在於它能進行圖像生成,而在於文本生成、圖像生成與世界知識在模型權重中深度融合所產生的聯合能力。
END
本期互動內容 🍻
❓如果像 Nano Banana 預示的那樣,未來的 AI 不再只用文字回覆你,而是自動生成圖表、流程圖、甚至交互界面 —— 你最希望它在哪種場景下以“非文字”的方式與你協作?
文中鏈接
[1]https://www.donnamagi.com/articles/karpathy-yc-talk
[2]https://www.youtube.com/watch?v=LCEmiRjPEtQ
[3]https://x.com/karpathy/status/1886192184808149383
[4]https://karpathy.bearblog.dev/power-to-the-people/
[5]https://karpathy.bearblog.dev/vibe-coding-menugen
[6]https://github.com/karpathy/llm-council
[7]https://github.com/karpathy/reader3
[8]https://github.com/karpathy/hn-time-capsule
原文鏈接:
https://karpathy.bearblog.dev/year-in-review-2025/