

編者按: 我們今天為大家帶來的文章,作者的觀點是:GPU 工程的核心不在於手寫內核的能力,而在於構建系統設計思維 —— 理解從模型定義到硬件層的完整技術棧如何協同工作。
作者提出了一個五層漸進式調試框架:從模型定義(Model Definition)入手,識別計算與內存瓶頸;進入並行化(Parallelization)階段,解決多卡同步問題;深入運行時編排(Runtime Orchestration),優化集羣資源利用率;通過編譯與優化(Compilation & Optimization)提升生產環境性能;最終觸及硬件層的物理極限。文章闡釋了每一層級的典型瓶頸與解決思路,強調 80% 的問題可通過前三層的系統設計解決,內核工程僅在邊緣場景中才真正發揮作用。
作者 | Abi Aryan
編譯 | 嶽揚
最近有條推文在 X 平台爆火——
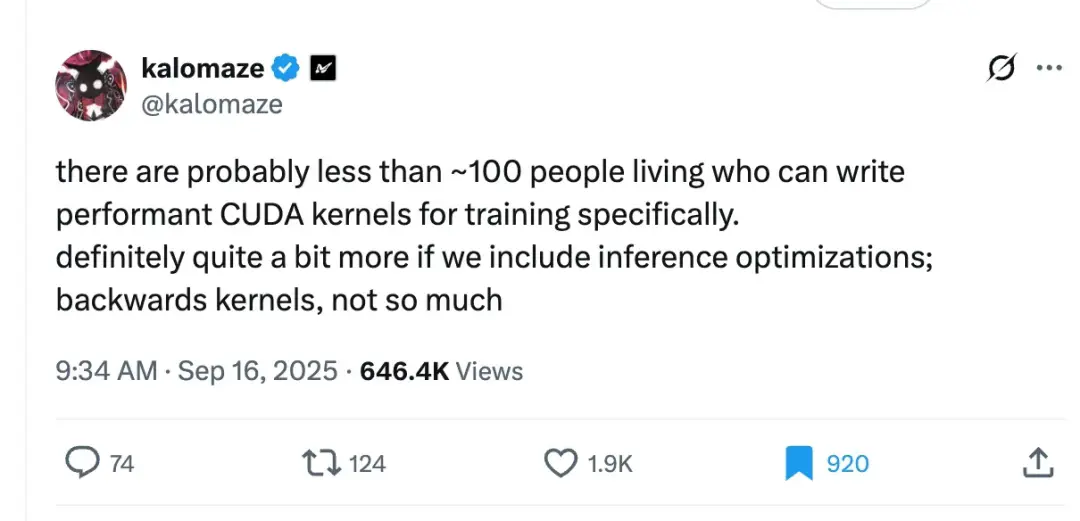
大多數人看到後的想法是:我得學會 CUDA 內核開發才能體現自身價值。
但事實並非如此。
即便投入畢生精力,你大概率也擠不進那個百人左右的精英圈子。
內核開發固然重要,但不應作為入門起點。首要的是理解整個系統應該如何協同運作。
你或許讀過無數關於 Triton 內核、將 PCIe 與 NVLink 進行對比、或是 DeepSpeed ZeRO 的帖子,但作為 GPU 工程師,真正的核心問題不是“我能手寫內核嗎”,而是“這些模塊如何銜接?何時需要關注哪個環節?”因為行業真正的短板並非工具使用能力,而是系統設計能力。
極少有人能真正將模型視為硬件中流動的字節,將張量看作內存中的佈局排列 —— 這正是內核工程師的思維境界。但若想進入這個精英羣體,你首先得理解一切是如何映射的。
今天這篇文章,我就來幫你建立這種系統設計的認知框架。
當你的模型分佈在幾十甚至上百塊 GPU 上時,你問的就不再只是“我的代碼對不對?”,而是“我的 GPU 們是否高效協同工作,還是在互相拖後腿?”
真正的瓶頸往往出現在同步、通信、調度和資源利用率上。
為了理解這一點,我們先退一步,看看所有模型都會經歷的系統工作流程(從左向右):
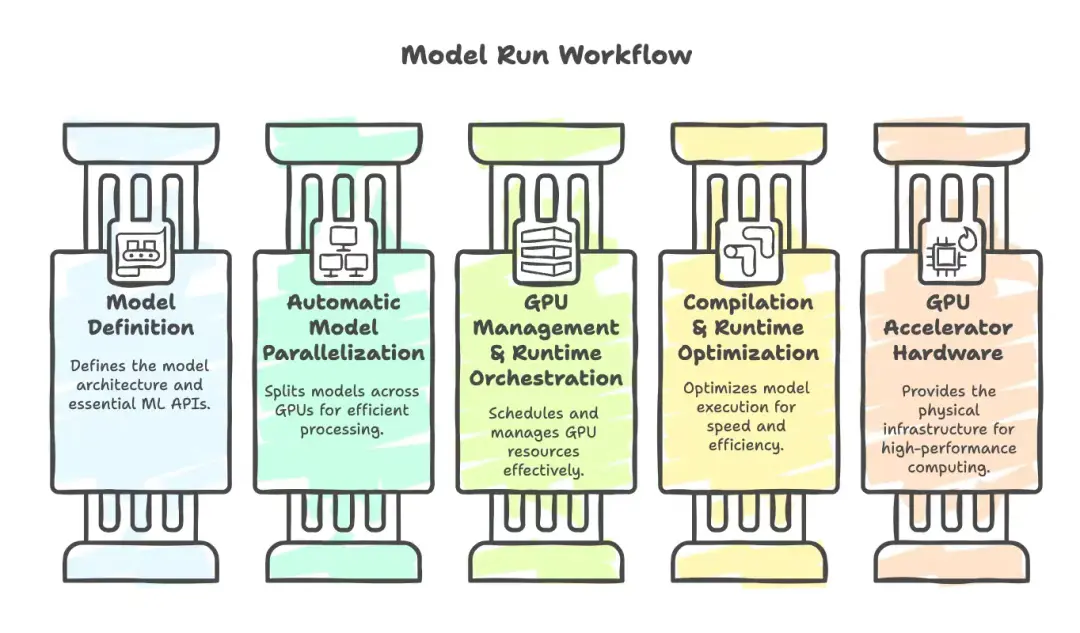
我們總是從模型定義層(Model Definition)入手。這一步更快速、更簡單,且槓桿效應更高。只有當你無法在此層解決問題時,才需要逐級深入後續環節。
01 第一層:模型定義(Model Definition)
這是大多數機器學習工程師起步並投入最多時間的地方:定義 Transformer 層、將其接入 PyTorch、依賴自動微分系統,並將一系列張量運算串聯起來。

這一階段出現問題,通常源於:
- 稠密矩陣乘法受計算限制,使 GPU 算術邏輯單元達到或接近最大工作負荷。
- 注意力層受內存帶寬制約,卡在等待數據傳輸,而非計算本身。
- 啓動了過多的小型計算內核,導致調度開銷過大。
在這一階段調試,意味着使用 PyTorch 或 JAX 工具進行性能分析,並思考: “這屬於計算問題、內存問題,還是框架效率問題?”
現在讓我們看個實例——
當你的大語言模型規模暴增時,限制訓練速度的不只是計算能力,更關鍵的是內存帶寬。
當 GPT 這類模型的參數規模變得極其龐大時,限制訓練速度的主要因素不再是 GPU 的計算能力,而是數據搬運的速度(即內存帶寬)。特別是在計算自注意力機制中的 Q(查詢)、K(鍵)、V(值)矩陣時,需要頻繁地在顯存中存取海量數據,這個“搬運數據”的過程成為了整個系統的瓶頸。解決方案是什麼?FlashAttention —— 一種通過重新組織計算順序來減少內存延遲的融合核函數。若不理解系統原理,你根本無法解釋 GPU 為何處於閒置狀態。
你的職責是確保模型運行,嘗試優化,繼而進行調試。
掌握每層對應的工具和框架,能幫你解決 80% 的問題,kernel engineering 則能幫你榨取剩下的 20%。但若妄想繞過基礎直接攻克那 20%,很遺憾,我的結論依然成立。
即便投入畢生精力,你大概率也擠不進那個百人左右的精英圈子。
在調試過程中,你會循着下圖所示的層級鏈條,依次逐層深入排查問題。
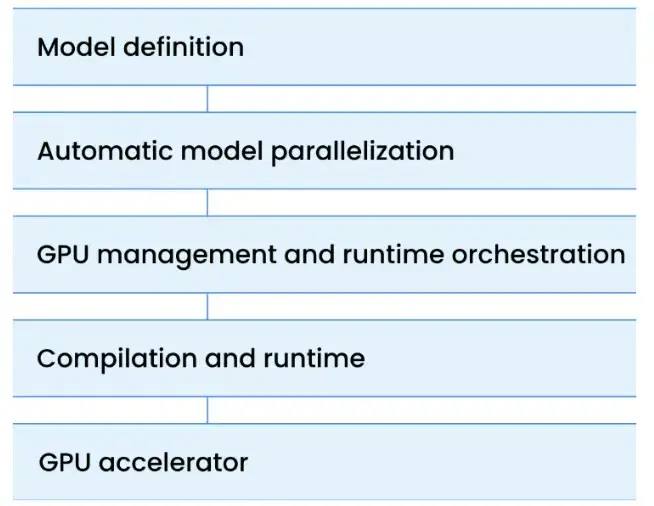
請將 GPU 協同調度工作想象成樓梯。每一級台階都對應技術棧中的不同層級,每層都對應着獨特的性能瓶頸與故障模式。只要某一層沒處理好,整體性能就會下降。請從最頂層開始,僅在必要時才向下深入。
接下來,讓我們看向下一層級——
02 第二層:並行化(Parallelization)
假設單塊 GPU 已無法滿足你的大語言模型(LLM)訓練需求——這幾乎是常態。於是你開始橫向擴展,這時你就進入了並行化(Parallelization)階段。這時,核心挑戰往往不再是單卡的計算能力,而是多卡間的同步問題:梯度必須在 GPU 之間流動,模型參數需要分片,優化器狀態也得拆分。
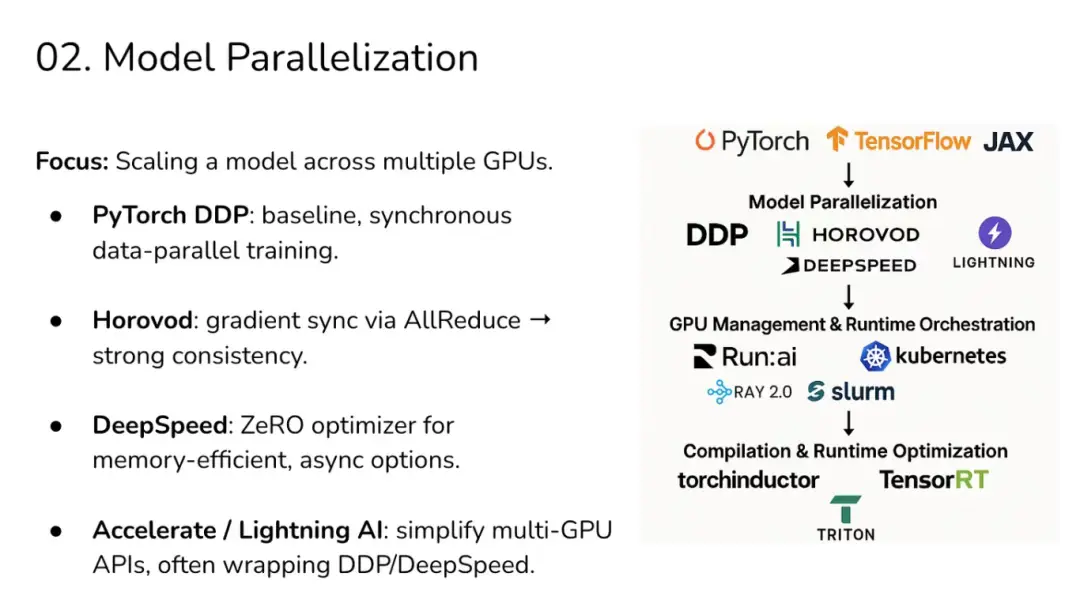
在這一層,瓶頸通常來自於:
- 同步式全規約核函數因少數幾個速度慢的 GPU 而陷入等待。
- PCIe 或 NVLink 帶寬限制,或是
- 異步更新雖提升了吞吐量,卻可能引入過時梯度(stale gradients)的風險。
到了這一層,你的核心問題就從“我的計算內核是否高效?”轉變為“我的 GPU 集羣是否在高效交換信息?” 。DeepSpeed ZeRO 能幫助你對狀態和梯度進行分片,但同時也會引入通信開銷。
此時,瓶頸不再是 GPU 計算核心,而是網絡互聯架構(network fabric)。你需要在強同步(穩定但較慢)和寬鬆的異步更新(更快但有風險)之間做權衡。
如果性能分析顯示通信與計算的重疊程度不佳,或許可採用融合核函數(fused kernels)或自定義核函數來降低傳輸期間的計算開銷,但這類情況較為罕見,通常 DeepSpeed ZeRO 或 Megatron-LM 已經內置了這類優化。
接下來我們繼續深入下一層級——
03 第三層:運行時編排(Runtime Orchestration)
當你從單一模型訓練任務擴展到大規模任務集羣時,就進入了運行時編排(Runtime Orchestration)階段。此時,你不再糾結於“我的注意力核函數高效嗎?”,轉而追問:“為什麼我有 30% 的 GPU 處於空閒狀態?”

在這一層,問題通常表現為:
- 半數 GPU 因某個計算節點延遲而集體閒置。
- 因調度策略不公導致任務在隊列中阻塞。
- 大量零散小任務導致資源碎片化,造成集羣資源浪費。
在此層級調試,意味着你要問: “我是否有效地編排了資源,讓 GPU 把時間花在訓練上,而不是等待上?”
來看一個例子 —— 我們在演講中討論過的 DeepMind 案例:

TLDR:DeepMind 報告稱,即使擁有數千塊 GPU,分佈式訓練仍會卡頓,因為少數慢節點拖慢了全局同步。在數據並行訓練中,整個任務必須等待最慢的那個工作節點。Ray 和 Kubernetes 通過彈性管理(節點故障時重新分配任務)和調度優化(避免 GPU 在隊列中閒置)來緩解這類問題。
但編排系統無法憑空修復糟糕的同步邏輯——你必須同時調優編排策略和並行化設計。
一旦這些基礎工作到位,你才可能去寫融合核函數(fused kernels),或是優化集合通信核函數(比如自定義的 all-reduce 實現),以略微減少 GPU 在等待通信時的計算空窗期;或者預取張量、對齊數據來適配 DMA 傳輸;又或者實現能感知調度的自定義核函數,在 Ray/Kubernetes 等編排器調度任務的同時,更充分地利用 GPU 流水線。
但再次強調:kernel engineering 僅適用於邊緣場景,且是否需要它,完全取決於調試過程中遇到的具體問題類型。
04 第四層:編譯與優化 (Compilation & Optimization)
訓練完成後,大語言模型(LLMs)需要服務數百萬請求,此時你關注的是生產環境中的延遲(latency)和吞吐量(throughput)。在這個階段,每一毫秒都至關重要。編譯器通過融合核函數、優化數據在內存中的存放和訪問方式以及降低精度等方式來解決這些問題。

因此,該層級的主要挑戰在於:
- 過多小型操作導致的核函數啓動開銷。
- 程序運行時間主要被內存數據傳輸所佔據(例如嵌入向量查詢)。
- 缺乏融合或量化技術導致性能潛力未被釋放。
此時的瓶頸已不再是訓練速度,而是在真實流量下的吞吐量與延遲表現。在此層級調試,意味着你要對推理負載進行性能分析,並思考: “我是否在每一塊 GPU 算力上榨取了最大吞吐收益?”
以 ChatGPT 推理為例:其推理過程通常涉及大量小型操作(即逐 token 生成)。如果每個操作都單獨啓動一個核函數,那麼核函數啓動開銷就會成為性能瓶頸。
像 TorchInductor 這樣的編譯器會將多個操作融合成更大的核函數,而 TensorRT 則通過將模型量化為 FP16 或 INT8 來節省計算和內存開銷。隨後,Triton Server 對多個推理請求進行動態批處理(batching),從而讓 GPU 能夠高效地同時處理成千上萬的請求。
正是在這一層,kernel engineering 才真正變得重要。與 Layer 1–3 不同,Layer 4 是手寫調優或編譯器級干預能顯著影響延遲和吞吐的階段。不過,通常只有在現有編譯器能力已被充分挖掘之後,你才會考慮編寫自定義核函數。自定義核函數適用於那些在單次推理或訓練步驟中被調用數百萬甚至數十億次的高頻率操作。
因此,核心要旨在於——
Layers 1–3:聚焦系統設計、資源編排與並行化策略,核函數編寫在此層面基本無關緊要。
Layer 4:運用編譯器優化、批處理、量化與融合技術,大多數現實場景的瓶頸在此即可解決。
而定製核函數僅當性能分析證實現有優化仍不足,且存在值得手工調優的高槓杆操作時才能真正派上用場。
05 第五層:硬件層
這是整個系統的基石。所有核函數、同步操作與分片策略,最終都受限於 GPU 及互聯硬件的物理極限。

這一層級的瓶頸表現為:
- 模型並行時達到 NVLink 帶寬上限。
- 跨節點擴展時 PCIe 成為性能瓶頸。
- GPU 顯存容量不足,被迫將數據卸載(offload)到 NVMe 存儲。
這些問題無法通過框架層面的優化來“修復”。你只能通過重構工作負載、降低精度(如使用 FP16/INT8),或直接升級硬件來規避。
在大規模訓練中,當數千塊 GPU 同步梯度時,InfiniBand 網絡鏈路常常會被打滿。這種瓶頸無法靠寫代碼繞過去——PCIe 和 NVLink 的帶寬是有限的。也正是在這裏,AI 工程開始與硬件工程深度融合。
唯一的解決方案來自架構層面:採用更先進的互聯技術、降低同步頻率,或重新設計算法以減少通信量。
此處引入我們討論過的另一個案例研究——
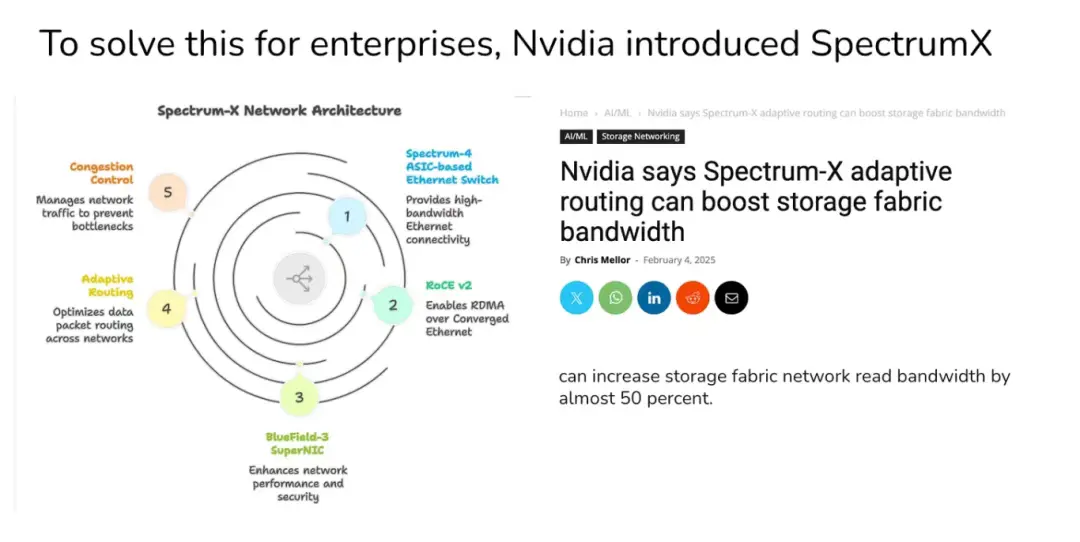
Spectrum X 能夠分析 GPU 顯存使用率、互聯帶寬(NVLink/PCIe/InfiniBand)及核函數執行情況,精準定位瓶頸所在。
06 The Key Lesson
每一層都是模塊化的,但又相互依賴:
- 如果在模型定義層(Model Definition)內存管理不當,就會在並行化層(Parallelization)引發通信瓶頸。
- 如果在並行化層(Parallelization)同步配置錯誤,就會導致運行時編排層(Runtime Orchestration)GPU 大量閒置。
- 如果在編譯層(Compilation)忽視核函數融合(kernel fusion),就會在生產環境中因延遲過高而白白燒錢。
因此,當你的模型:
受計算限制(Compute-bound) → 通過模型或核函數優化來解決。
受內存限制(Memory-bound) → 通過分片(sharding)、重計算(recomputation)和核函數融合來緩解。
受通信限制(Communication-bound) → 依靠並行化(parallelization)和運行時編排(orchestration)來應對。
一旦你掌握了這張系統地圖,那些零散的博客文章、論文和爭論就不再雜亂無章 —— 它們會立刻各歸其位,成為整個大系統中清晰可辨的組成部分。
END
本期互動內容 🍻
❓你在訓練或推理中遇到的性能瓶頸,更多來自計算、內存,還是通信?是怎麼發現的?
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯繫獲取授權。
原文鏈接:
https://modelcraft.substack.com/p/fundamentals-of-gpu-enginee...




