

Flink中的序列化應用場景
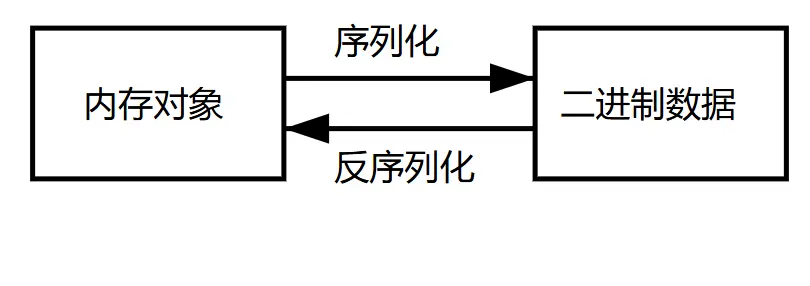
程序通常使用(至少)兩種不同的數據表示形式[2]:
1. 在內存中,數據保存在對象、結構體、列表、數組、哈希表和樹等結構中。
2. 將數據寫入文件或通過網絡發送時,必須將其序列化為字節序列。從內存中的表示到字節序列的轉化稱為序列化,反之稱為反序列化。
Flink中,下述的場景需要進行序列化和反序列化[1]
1. F1ink中上下游算子之間可能分佈在不同的節點上,不同算子的subTask會通過網絡傳輸數據
2. Flink的Source和sink算子消費和寫入Kafka Topic
3. F1ink中進行checkPoint將內存中的狀態持久化到HDFs和從checkPoint恢復時從HDFS上加載狀態數據Flink未直接使用Java序列化,而是自研了一套高效的序列化機制。
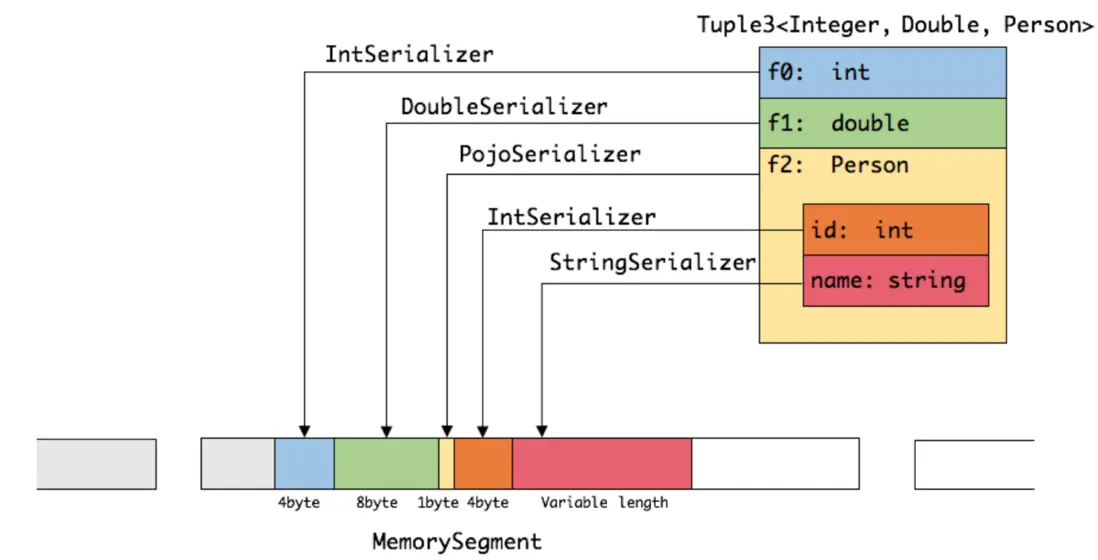
比如我們要在算子間傳遞一個Tuple3<Integer, Long, Person>的數據(其中Preson為由id和name組成的pojo類),則subTask對其進行序列化的關鍵步驟如下。
1. 分析識別算子間傳輸數據的數據類型
2. 根據數據類型創建對應的序列化器
3. 使用序列化器將數據寫入到內中(即內存段MemorySegment中)
Flink支持的類型有以下幾種[3],基本覆蓋了大部分的用户使用場景,所以一般不用再自定義序列化器。

序列化方案的選擇
如上節所述,很多場景(比如下面的場景)中數據在內存和文件/網絡間傳遞時需要考慮序列化。
1. [數據庫] 將數據寫入到數據庫需要進行序列化,從數據庫讀取的時候需要進行反序列
2. [服務調用(REST和遠程調用RPC)] 客户端對請求進行序列化,服務器端對請求就行反序列化並將響應進行序列化,客户端最終對響應進行反序列化
3. [消息傳遞(消息代理Kafka和分佈式Actor框架)] 節點之間通過互發消息進行通信,消息由由發送者進行序列化並由接收者反序列化。生產環境中,許多服務需要支持滾動升級,即每次將新版本部署到幾個節點,而非所有節點。
這種情況下,必須假設不同的節點正在運行應用代碼的不同版本。
這意味着新舊版本的代碼,以及新舊數據格式,可能會同時在系統內共存。
為了使系統繼續順利運行,需要保持雙向的兼容性。
向後兼容:較新的代碼可以讀取由舊代碼編寫的數據。
向前兼容:較舊的代碼可以讀取由新代碼編寫的數據。這種情況下,需要選擇合適的序列化方案以支持雙向兼容性就比較重要。
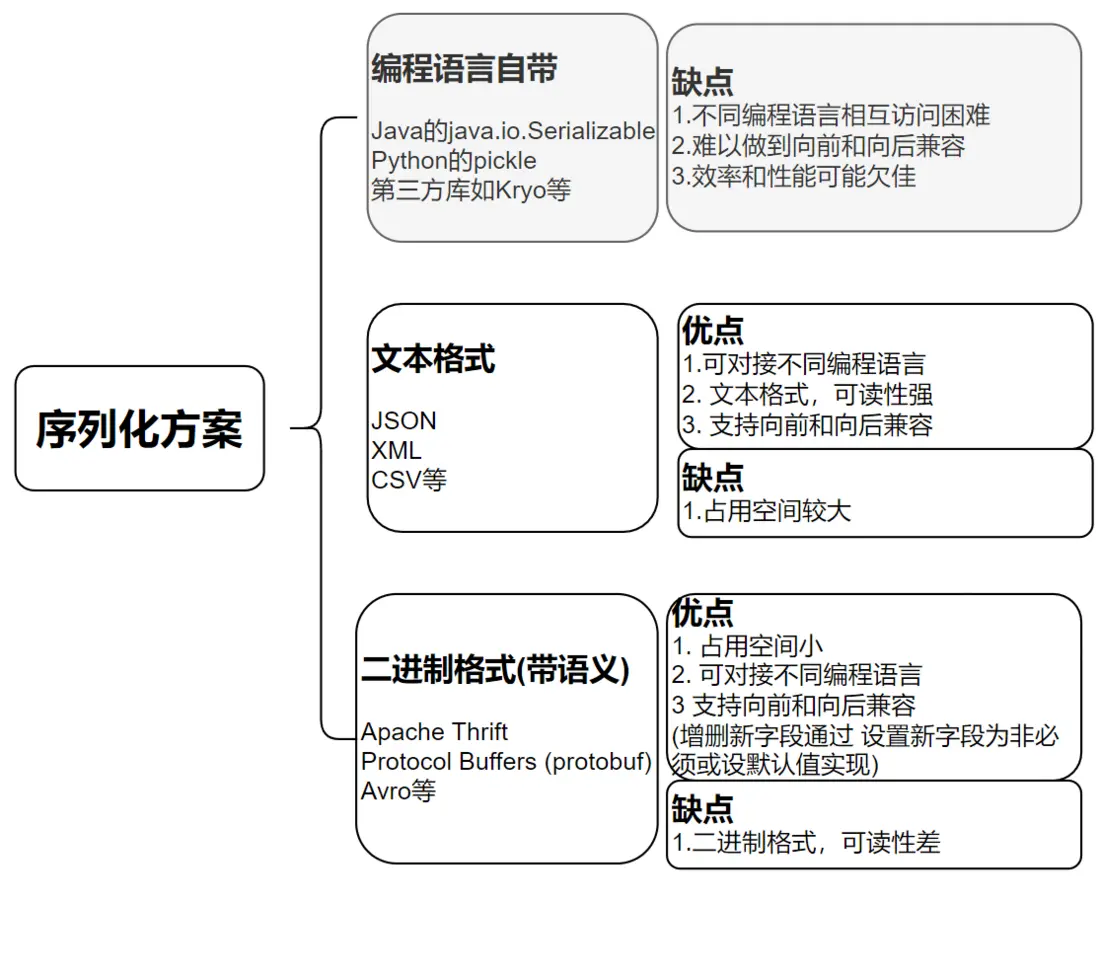
很多系統會選擇Json/XML等文本格式和Avro等二進制格式的方案[2]。
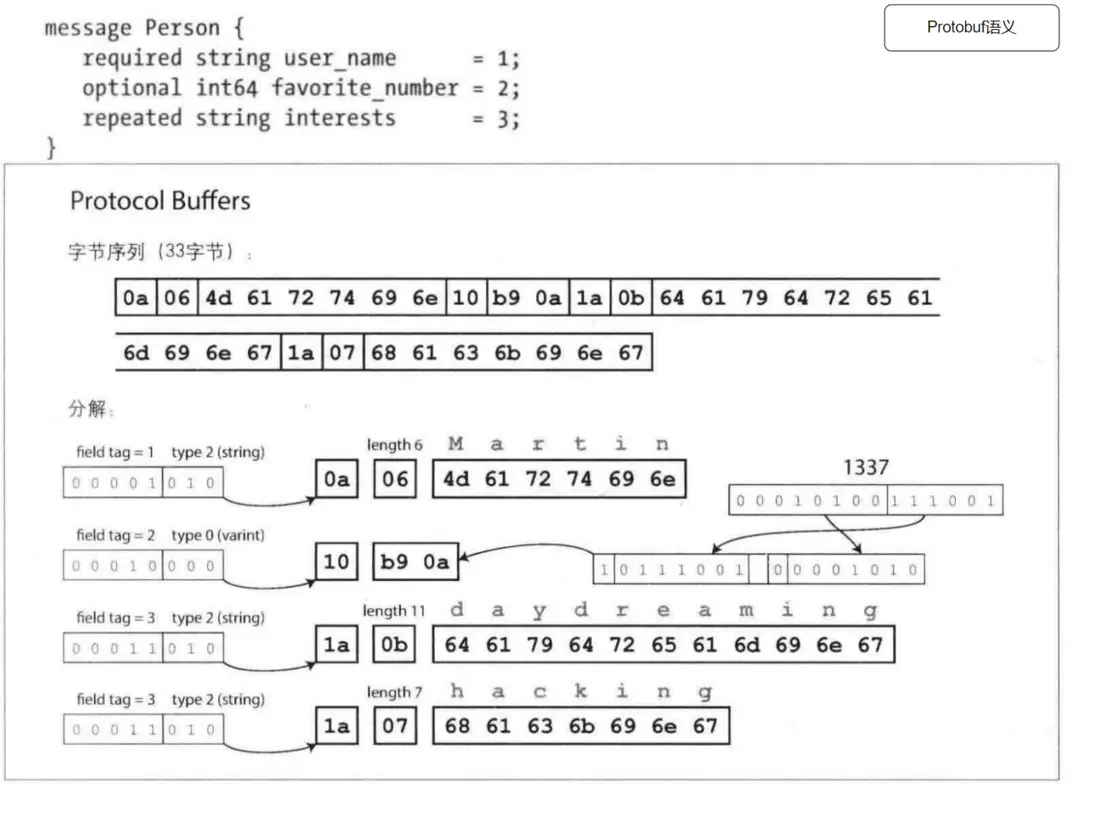
此處以一條json數據為例,看到json的文本格式和Protobuf&Avro兩種二進制格式的區別。

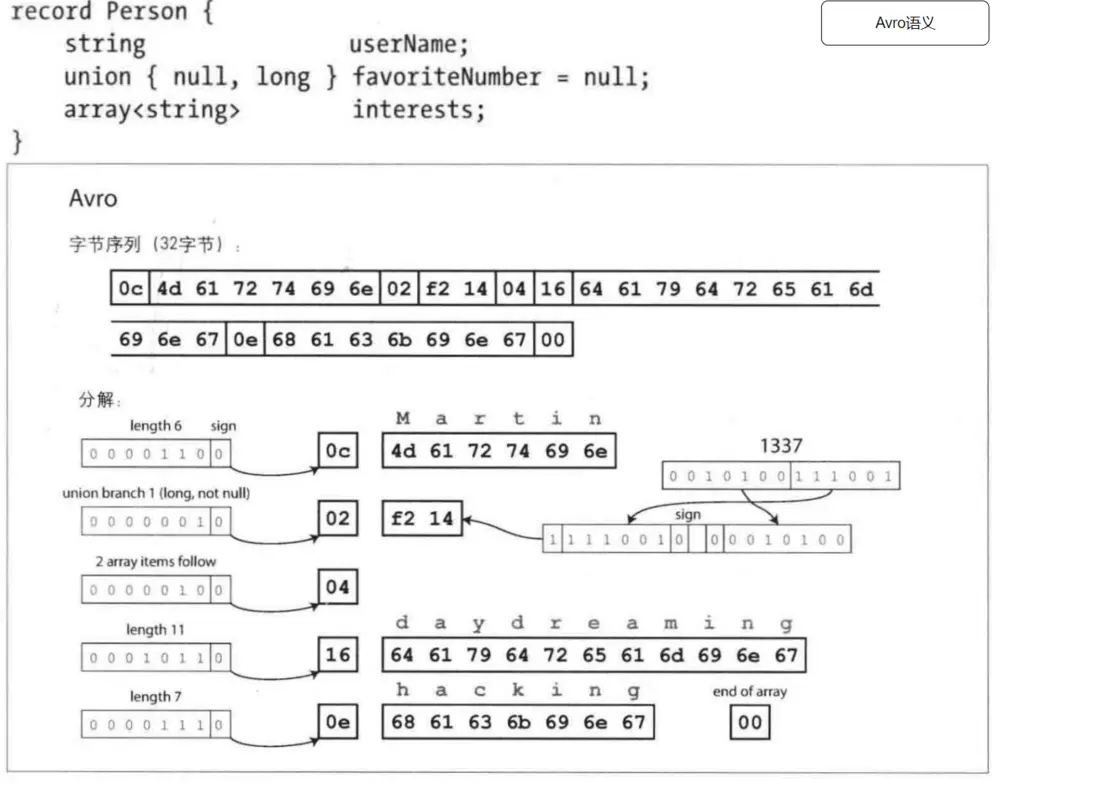
參考
1.《Flink SQL與DataStream 入門、進階與實踐》 羊藝超著 P121-P127
2.《數據密集型應用系統設計》 Martin Kleppmann 著 P109-P134
3. 數據類型以及序列化 https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/types_serialization.html