

點擊網頁上的“搜索”按鈕,加載圈轉了數秒才出現結果,這種體驗對於用户來説並不友好。查看後台日誌時,往往會發現這是由慢查詢 SQL 引起的。
很多時候,慢查詢的根源在於沒有建立索引(Index),導致數據庫被迫進行“全表掃描”。
到底什麼是索引?為什麼增加索引能顯著提升速度?它又帶來了什麼代價?本文將摒棄枯燥的計算機教材定義,通過“逛超市”的直觀案例,深入淺出地解析數據庫索引原理。
一、 為什麼查詢會慢?(全表掃描的噩夢)
設想一家沒有任何管理的混亂超市。
這裏沒有貨架分類,洗髮水旁邊可能壓着薯片,薯片下面埋着醬油,所有商品都按照進貨時間隨意堆放在地上。
這是一篇調整後的博客文章。全文已去除第一人稱(“我”、“我們”),採用客觀的敍述視角,並明確標註了圖片的插入位置。
拒絕慢查詢!像逛超市一樣看懂數據庫索引
點擊網頁上的“搜索”按鈕,加載圈轉了數秒才出現結果,這種體驗對於用户來説並不友好。查看後台日誌時,往往會發現這是由慢查詢 SQL 引起的。
很多時候,慢查詢的根源在於沒有建立索引(Index),導致數據庫被迫進行“全表掃描”。
到底什麼是索引?為什麼增加索引能顯著提升速度?它又帶來了什麼代價?本文將摒棄枯燥的計算機教材定義,通過“逛超市”的直觀案例,深入淺出地解析數據庫索引原理。
一、 為什麼查詢會慢?(全表掃描的噩夢)
設想一家沒有任何管理的混亂超市。
這裏沒有貨架分類,洗髮水旁邊可能壓着薯片,薯片下面埋着醬油,所有商品都按照進貨時間隨意堆放在地上。
現在,任務目標是:買一瓶“海天醬油”。
在這種情況下,顧客別無選擇,只能推着購物車,從超市入口的第一堆商品開始,一件一件地查看。
- 拿起一件:是拖鞋,不是醬油。
- 拿起下一件:是蘋果,不是醬油。
- ……
- 直到翻遍了幾萬件商品,終於在角落裏找到了目標。

在數據庫中,這被稱為全表掃描(Full Table Scan)。如果沒有索引,為了尋找一條數據,數據庫必須遍歷幾百萬行數據。這不僅效率極低,還會消耗大量的服務器資源。
二、 什麼是索引?(超市的指示牌)
為了解決混亂問題,超市管理者(數據庫管理員 DBA)會對超市進行整頓,主要做兩件事:
- 分類擺放:將商品按生鮮、零食、調味品等類別分開。
- 懸掛指示牌:在顯眼位置設置層級分明的指引。
現在,再次尋找“海天醬油”的過程變為:
- 進門查看根目錄指示牌:[生鮮區] | [日用品區] | [調味品區]。
- 直接前往 [調味品區](瞬間排除了大部分無關區域)。
- 到達貨架查看二級標籤:[食鹽] | [醋] | [醬油]。
- 在 [醬油] 貨架上,直接鎖定目標並取走。

這就是索引的作用。
在技術層面,這種層級分明的指示牌結構通常採用 B+樹(B+ Tree) 數據結構。
- 根節點/中間節點:對應懸掛的指示牌,只負責指引方向,不存儲實際數據。
- 葉子節點:對應最底層的貨架,存放着真正的數據行。
索引的本質,是將低效的“逐行查找”轉化為了高效的“二分查找”(排除法)。
三、 為什麼要建索引?(收益與代價)
既然索引能提升效率,為什麼不給每一列數據都建立索引?
這是因為索引是一把雙刃劍,天下沒有免費的午餐。
1. 索引的收益(Pros)
- 極速查詢:將查找海量數據的複雜度,從線性掃描(O(N))降低到對數級別(O(LogN))。通常只需 3-4 次磁盤 I/O 即可定位數據。
- 保證唯一性:通過“唯一索引”,強制保證某列數據不重複(如身份證號、User ID)。
- 加速排序:索引本身是有序存儲的,執行
ORDER BY時,數據庫無需重新計算排序,直接按索引順序讀取即可。
2. 索引的代價(Cons)
- 佔用存儲空間:指示牌和目錄需要物理空間,索引文件同樣會佔用磁盤空間。
- 降低寫入速度(關鍵弊端):
- 場景:超市進貨(Insert)或修改價格(Update)。
- 無索引時:商品隨意堆放即可,速度極快。
- 有索引時:必須找到對應的分類貨架;如果貨架已滿,需要移動周邊商品騰出位置,甚至重新制作目錄。
- 結論:索引越多,增、刪、改操作的速度越慢。
四、 實戰案例解析:非唯一字段需要索引嗎?
開發者常有的疑問是:“索引是為了唯一性嗎?如果數據重複,建索引還有用嗎?”
案例分析:
假設有一張微信羣成員表 wx_group_member,包含字段 group_id(羣ID)和 wxid(個人微信號)。
問題在於:“wxid 對於每個人是唯一的,但在羣成員表中,一個用户可能加入多個羣,導致 wxid 重複出現。此時還需要給 wxid 建索引嗎?”
場景模擬:
- 張三 (
wxid_001) 在 “工作羣”。 - 張三 (
wxid_001) 在 “家庭羣”。 - 張三 (
wxid_001) 在 “摸魚羣”。
如果不建立索引,當查詢 “張三加入了哪些羣?” 時:
- 無索引:數據庫必須掃描全表(假設 1 億行),逐行檢查是否為張三。
- 有索引:數據庫通過索引直接定位到
wxid_001的位置。由於 B+ 樹的葉子節點是鏈表結構,張三的 3 條記錄是物理相鄰或邏輯相連的,系統可以直接一次性取出。
結論:只要字段頻繁作為 WHERE 查詢條件(如 WHERE wxid = '...'),無論其值是否唯一,建立索引通常都能大幅提升查詢效率。
五、 什麼時候該建立索引?(黃金法則)
建立索引不應盲目,建議遵循以下原則:
✅ 建議建立索引的情況:
- 高頻查詢字段:經常出現在
WHERE子句中的字段。 - 連接字段:經常用於表連接(
JOIN)的字段(如外鍵)。 - 排序字段:經常用於
ORDER BY的字段。
❌ 不建議建立索引的情況:
- 極小表:如果數據僅有幾十行,全表掃描往往比查索引目錄更快。
- 頻繁更新的字段:維護索引的成本過高。
- 區分度低的字段:
- 例如“性別”字段,僅有“男”和“女”。
- 如果在“性別”上建索引,相當於將超市商品僅分為“紅色區”和“藍色區”。要找某個商品時,仍然需要在半個超市的範圍內查找,索引基本失效。
六、 進階概念:聚簇索引與“回表”
在數據庫面試或性能優化中,常提到“回表”的概念。
- 聚簇索引(Clustered Index):
- 對應超市的實體貨架。數據行是嚴格按照主鍵 ID 排列的。找到了主鍵,也就直接拿到了商品實體。
- 非聚簇索引(Secondary Index):
- 對應超市門口的自助查詢終端。
- 如果通過“商品名”查找(非主鍵),終端會顯示:“海天醬油的 ID 是 9527”。
- 回表(Look up):拿到 ID 9527 後,還需要跑回實體貨架去取商品。這個“查完目錄再去拿貨”的過程,就叫回表。
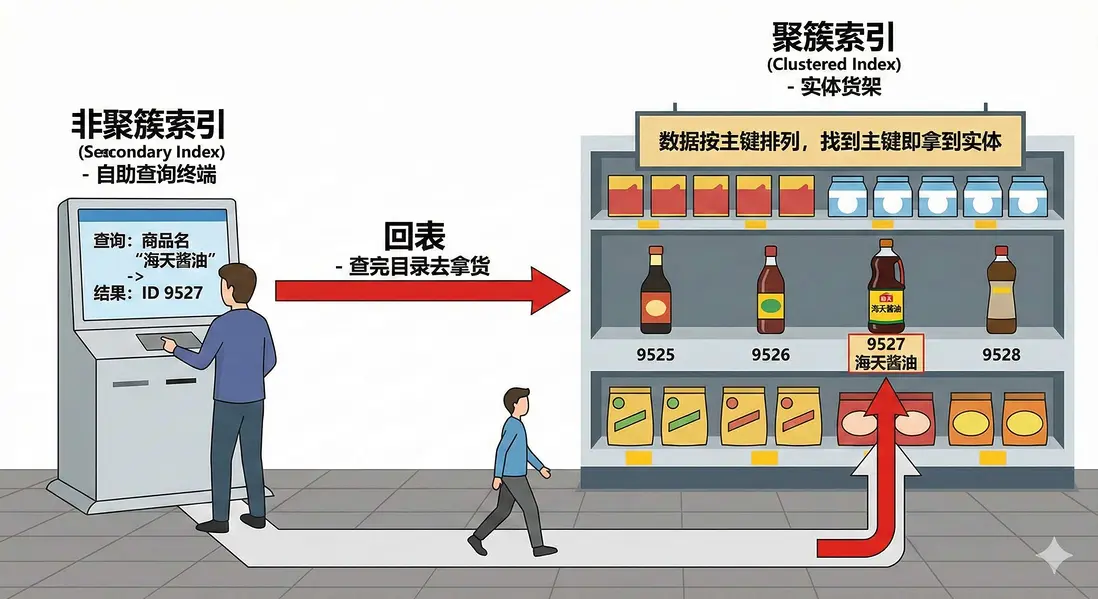
優化建議:編寫 SQL 時,應儘量只 SELECT 真正需要的列。如果查詢所需的所有列都包含在索引中(覆蓋索引),就不需要“回表”,查詢速度會更快。
總結
數據庫索引並不神秘,它就是為了解決“查找慢”而設計的“目錄”和“指示牌”。
- 追求查詢速度:建立索引。
- 追求寫入速度:減少索引。
- 決策依據:根據
WHERE條件頻率和數據區分度進行權衡。
遇到慢查詢時,建議使用 EXPLAIN 命令分析執行計劃,檢查 SQL 語句是在“混亂市場”中漫遊,還是在“現代超市”中高效直達。
本文由mdnice多平台發佈