

隨着低代碼概念和產品的流行,很多人都在考慮在自己的項目中引入邏輯編排的概念,將傳統上通過手工硬編碼生產的邏輯卸載到某個可以靈活配置的邏輯編排引擎上。在本文中,我將介紹一下Nop平台中的邏輯編排引擎NopTaskFlow的設計思想,分析一下NopTaskFlow的設計在數學層面的必然性。在文章的最後我會解釋一下為什麼NopTaskFlow是下一代邏輯編排引擎,這個所謂的下一代具有什麼典型特徵。
一. 邏輯編排到底在編排什麼?
當我們使用傳統的編程語言和編程框架進行編程時,本質上是在遵循語言所定義的某種約束規範,也可以看作是某種最佳實踐。但是當我們自己從零開始編寫一個非常靈活、非常底層的邏輯組織框架時,很容易就會打破此前語言內置的形式規範,從而偏離隱含的最佳實踐模式。
可以靈活組織的最小邏輯單元是什麼?傳統編程語言的回答現在很標準:函數。那麼函數有什麼本質性特徵?
- 函數具有明確定義的輸入和輸出
- 函數可以進行嵌套調用
- 函數中使用的變量具有複雜的詞法作用域
如果更進一步的研究函數的結構,我們還會發現更加複雜的特徵,例如
- 函數參數是傳值還是傳引用?callByValue? callByRef?callByName?
- 是否支持函數式參數,也就是所謂的高階函數?
- 是否存在獨立於返回值的異常處理機制?
- 是否支持異步返回?
當然,還有最最重要的,函數不僅僅是認知和組織邏輯的最小單元,還是我們進行抽象的最小單元。我們可以複用已有的函數來定義的新的函數。
那麼為什麼函數會成為編程語言中最基本的邏輯組織單元,我們現在編寫一個邏輯編排引擎的時候還需要基於函數抽象嗎?有沒有更好的抽象形式?為了搞清楚這個問題,我們有必要懂一點歷史。
首先,我們需要清醒的意識到,計算機編程語言中最初並沒有函數概念,函數概念的建立是一件不平凡的事情。
==== 以下為智譜清言AI的創作=====
早期編程語言(1950s-1960s):
- 彙編語言:在彙編語言中,函數的概念並不明顯,程序員通常使用跳轉指令來執行代碼塊。
- Fortran:在1955年發佈的Fortran語言中,引入了子程序(subroutine)的概念,這可以看作是函數的早期形式。但是Fortran中的子程序不支持返回值。
高級編程語言的興起(1960s-1970s):
- ALGOL 60:在1960年發佈的ALGOL 60中,引入了現代函數概念,支持返回值,並提出了塊結構(局部變量作用域),這是編程語言發展中的一個重要里程碑。
- Lisp:在1958年開發的Lisp語言中,函數被視為一等公民,這意味着函數可以作為數據傳遞、存儲和返回,這是函數式編程語言的核心特性。
結構化編程(1970s):
- 結構化編程的概念最早由Edsger W.Dijkstra在1968年的論文《Go To Statement Considered Harmful》中提出,他主張通過限制或消除goto語句的使用來改善程序的結構。結構化編程的核心理念是將程序分解為模塊化的部分,使用順序、選擇(if-then-else)和循環(while、for)等結構來控制程序的流程。
- C語言:1972年發佈的C語言,深受Algol 68的影響,其函數定義簡潔,支持遞歸調用,是第一批原生支持結構化編程概念的高級編程語言之一。C語言的流行極大地推動了結構化編程範式的普及。
==== 智譜清言的創作結束=====
後續的1980年代是面向對象的天下,函數的地位下降,變得從屬於對象,在Java中我們甚至不能在類的外部單獨定義函數。而在2000年以後函數式編程逐漸復興,推動了不可變性和所謂無副作用的純函數概念的普及。隨着多核並行編程、分佈式消息系統和大數據處理系統的盛行,函數的概念也在不斷地擴展和深化,現代程序語言現在普遍標配async/await機制。
下面我們來分析一下函數概念所帶來的隱含假定是什麼。
首先,函數是信息隱藏的一種必然結果。信息隱藏必然導致世界被區分為內部和外部
,內部的小環境如果可以獨立於外部存在(也就是説同樣的函數可以在不同的外部環境中被調用,函數內部不需要感知到環境的變化),那麼內部和外部的關聯一定被限制為只發生在邊界上。內部從外部獲取的信息被稱為Input,而外部從內部獲取的信息被稱為Output。邊界的維度一般遠小於系統整體結構的維度(類比三維球體的邊界是二維的球面),這使得函數能提供降低外在複雜度的價值。
- 如果在函數內部總是在讀寫全局變量,那麼我們實際是在使用procedure抽象,而不是函數抽象。
- 服務化相當於是約定了Input和Output都是可序列化的值對象。
第二,函數自動引入瞭如下因果順序關係:
- 對錶達式求值得到函數的Input參數
- 執行函數
- 接收到函數輸出Output
在調用函數之前,Input的值就會確定下來,而函數成功執行之後才會產生Output
。如果函數調用失敗,我們根本不會得到輸出變量。特別的,如果一個函數具有多個輸出的情況下,我們總是要麼得到全部Output,要麼沒有得到Output,不會出現得到只觀察到部分Output的情況。
現在有些邏輯編配框架會在步驟執行的過程中將一些中間結果暴露出來作為Output
Endpoint,例如將循環過程中的循環下標暴露為一個Endpoint,在循環的過程中不斷輸出這種臨時的Output,這種做法相當於是偏離了函數抽象。
第三,函數內部擁有獨立的變量作用域(名字空間)。不管一個變量在函數外部叫做什麼名字,它作為參數傳遞給函數之後,我們在函數內部總是使用局部的輸入變量名來指向它。同時,函數內部使用的臨時變量並不會被外部觀測到。有名,萬物之母。任何一種大規模的、系統化的複用,第一個要求就是避免名字衝突,必須使用局部名稱。
第四,函數組合調用的時候,是通過當前的scope來間接實現信息傳遞。例如
output = f(g(input))
// 實際對應於
output1 = g(input)
output = f(output1)一個變量必須存在於一個scope中。當函數g返回的時候,它內部的scope在概念層面就被銷燬了,而執行函數f之前,它內部的scope還不存在,所以函數g的返回值一定是先被存放在外部的scope中,然後再轉發給函數f。
第五,函數意味着配對的雙向信息流。我們都知道goto是有害的,因為goto往往是一去不復返,只有天知道它什麼時候才會goback,會goback到哪裏。但是函數是一種非常自律的、可預測性極強的信息流組織。Input向函數傳遞信息,然後Output一定會返回,而且會在原先的調用點返回(也就是説goto和goback是在數學意義上嚴格配對的)。傳統程序語言中函數調用是同步調用,它帶有阻塞語義,會自動阻塞當前的執行指令流(相當於是程序世界的時間線)。對於異步調用而言,函數調用返回並不意味着Output可用,因此只能使用回調函數來處理邏輯依賴關係,導致出現所謂的嵌套回調地獄。現代編程語言中的async/await語法相當於是為異步函數也補充了阻塞語義,使得源碼中的函數調用順序仍然可以被看作是時間線演進的順序。
在分佈式架構下最靈活的組織方式無疑是事件發送和監聽,本質上它是單向信息傳遞,與goto有異曲同工之妙。靈活是靈活了,但是代價是什麼?
迷失在歷史中的先賢真言
正所謂人類從歷史中學到的唯一教訓就是人類無法從歷史中學到任何教訓。二十年就是一代人,下一代人面對新的問題時會忘記前人的智慧,一切仍然從拍腦袋開始。
goto是不好的,結構化編程是好的,這是我們從學習編程就被灌輸的理念,但是為什麼?如果在面試中問起,相信很多程序員都能侃侃而談,甚至援引到圖靈獎得主Dijkstra的經典論文《Go To Statement Considered Harmful》 (這也是Dijkstra最著名的論文)。但是有多少人真正認真的讀過這篇論文?反正我自己是很早就知道這篇論文,但從未認真讀過。直到最近我真的去讀了,才發現Dijkstra反對goto的理由與我們自己腦補的根本不一樣,我們早已經把Dijkstra的智慧遺忘得乾乾淨淨。
在這篇論文的一開始,Dijkstra開宗明義的就説到自己早就觀察到goto語句會損害軟件質量,但直到最近他才找到一個科學意義上能夠解釋為何如此的原因。
The unbridled use of the go to statement has an immediate consequence that it becomes terribly hard to find a
meaningful set of coordinates in which to describe the process progress.a programmer independent coordinate system can be maintained to describe the process in a helpful and manageable way.
Dijkstra論文的核心思想是如果我們按照結構化編程的思想去寫代碼,那麼我們的代碼文本就會構成一個客觀存在的座標系統(獨立於Programmer),藉助於這個座標系統,我們可以在思維中直觀的將靜態程序(在文本空間中展開)和動態過程(在時間中展開)之間建立對應關係,而goto會破壞這種可以自然存在的座標系統。
==== 以下是KimiChat AI的總結===
這個所謂座標系的座標指的是用來唯一確定程序執行狀態的一組值。
- 文本索引(Textual Index) 。當程序僅由一系列指令串聯組成時,可以通過指向兩個連續動作描述之間的某個點來確定一個“文本索引”。這個索引可以看作是程序文本中的位置,指向程序中的一個具體語句。在沒有控制結構(如條件語句、循環語句等)的情況下,文本索引足以描述程序的執行進度。
- 動態索引(Dynamic Index)。 當程序中引入了循環(如
while或repeat語句)時,單一的文本索引就不再足夠了。循環可能導致程序重複執行相同的代碼塊,因此需要額外的信息來追蹤當前循環的迭代次數,這就是所謂的“動態索引”。動態索引是一個計數器,記錄當前循環迭代的次數。 - 程序執行的描述。 程序的執行狀態不僅取決於程序文本中的位置(文本索引),還取決於程序執行的動態深度,即當前嵌套調用的層數。因此,程序的執行狀態可以通過一系列文本索引和動態索引的組合來唯一確定。
== KimiChat AI的創作結束===
可逆計算理論可以看作是對Dijkstra這個座標系思想的進一步深化。使用領域特定語言(DSL)我們可以建立領域特定的座標系(而不僅僅是一個通用的、客觀存在的座標系),而且不僅僅是用於理解,我們可以更進一步,在這個座標系統上定義可逆差量運算,真正的把這個座標系統利用起來,將它用於軟件構造過程。
NopTaskFlow的設計遵循了Nop平台XDSL的通用設計,每個step/input/output都具有name屬性作為唯一標識,從而形成一個完全領域座標化的邏輯描述。我們可以使用x:extends 算子繼承一個這樣的描述,然後利用Delta差量機制對它進行定製修改。
需要指出的是,NopTaskFlow中假定了Input和Output都是單個的具有確定性的值,而不是可以不斷產生item的流(Flow)對象。流的問題要更加複雜,與上一節的函數概念分析也存在衝突之處,在Nop平台的規劃中是通過NopStream框架來完成建模。
如果從座標系的角度去考慮,我們可以認為流系統引入了一種特殊的假定:空間座標凍結,而時間座標在流動(空間座標確定了流系統的拓撲)。這種特殊的假定帶來一種特殊的簡化,因此它也值得寫一個特殊的框架去充分發掘這個假定的價值。
二. 最小邏輯組織單元 TaskStep
NopTaskFlow的設計目標是提供一種支持差量運算的結構化邏輯分解方案,貼近編程語言中的函數概念無疑是一種最省心的選擇,而且如果未來需要高性能編譯執行,也更容易將編排邏輯翻譯為普通的函數實現代碼。
NopTaskFlow中的最小邏輯組織單元是所謂的TaskStep,它的執行邏輯如下圖所示:

for each inputModel
inputs[inputModel.name] = inputModel.source.evaluate(parentScope)
outputs = await step.execute(inputs);
for each outputModel
parentScope[outputModel.exportAs] = outputs[outputModel.name]在概念層面上非常類似於一般程序語言中的函數調用:
var { a: aName, b: bName} = await fn( {x: exprInput1, y: exprInput1} )我們來看一個順序調用的具體實例:
<sequential name="parentStep">
<input name="a"/>
<steps>
<xpl name="step1">
<!-- 步驟中使用的變量信息需要通過input傳入,子步驟並不會直接使用父步驟中的變量 -->
<input name="a"/>
<!-- source段的返回值類型如果不是Map,則會被認為是RESULT變量 -->
<source>
return a + 1
</source>
<!-- 輸出變量可以動態計算得到。如果不指定source,則返回當前scope中對應名稱的變量 -->
<output name="a2">
<source>a*2</source>
</output>
</xpl>
<call-step name="step2" libName="test.MyTaskLib" stepName="myStep">
<!-- 通過source段可以動態計算得到輸入參數。RESULT對應於父scope中名為RESULT的變量 -->
<input name="a">
<source>RESULT + 1</source>
</input>
<!-- 返回到父scope的結果被重命名為b2 -->
<output name="b" exportAs="b2"/>
</call-step>
</steps>
<output name="b2"/>
</sequential>TaskFlow內置了sequential/parallel/loop/choose/xpl/call-step等多種步驟類型,相當於是一種圖靈完備的函數式編程語言。
具體步驟定義可以查看task.xdef元模型定義
上面的示例等價於如下代碼
var { RESULT, a2 } = function step1(a){
return { RESULT : a + 1, a2: a*2}
}(a);
var { b: b2} = test.MyTaskLib.myStep({a: RESULT+1})
return { b2 }- 步驟具有name屬性,它在局部具有唯一性,但是並不要求全局唯一。這種局部名稱是複雜步驟可以被複用的前提。
- xpl相當於是一種函數調用,它的source段執行結果如果不是Map結構,則被設置為RESULT變量
- output變量如果指定了source段,則表示動態執行表達式來構建返回值,否則按照名稱從當前scope中獲取返回值
- 成功調用step之後,會把output返回的結果設置到當前scope中
- 通過
call-step可以複用已有的步驟定義 - input變量如果指定source段,則相當於是動態計算變量值,否則就按照name屬性從當前scope獲取
- output如果指定exportAs屬性,則設置到父scope中時會重命名
TaskStep對應的接口定義如下所示:
interface ITaskStep {
String getStepType();
List<ITaskInputModel> getInputs();
List<ITaskOutputModel> getOutputs();
CompletionStage<Map<String, Object>> execute(
Map<String, Object> inputs, Set<String> outputNames,
ICancelToken cancelToken, ITaskRuntime taskRt);
}- TaskStep具有inputs和outputs的模型信息,相當於是一種反射元數據,可以通過它們獲知函數的參數名和參數類型,返回變量名和返回變量類型等。
- 作為一種通用編排元件,TaskStep強制約定了多輸入和多輸出結構,所以inputs和outputs都是Map對象。
- outNames提供了一種類似於GraphQL的結果數據選擇能力
。在調用Step的時候我們就指定是否需要用到哪些返回變量。這樣在步驟內部實現時,可以選擇性的進行性能優化,對於不需要返回的複雜計算可以直接跳過。 - TaskStep缺省支持異步執行,同時通過cancelToken提供了運行時取消的能力。TaskFlow在運行的時候會自動添加await語義,自動等待前一個step結束。
- ITaskRuntime是整個任務執行過程中共享的全局信息,包括TaskScope等。
如果需要擴展TaskFlow,最簡單的方式是在NopIoC容器中註冊一個ITaskStep接口的bean,然後通過如下語法調用
<simple bean="myStepBean">
<input name="a1"/>
<input name="a2"/>
<output name="b1"/>
<output name="b2"/>
</simple>如果真的查看一下ITaskStep接口的定義,會發現它的實現要更加複雜一些:
interface ITaskStep {
// ...
TaskStepReturn execute(ITaskStepRuntime stepRt);
}- TaskStepReturn的作用是優化同步調用時的性能,並增加了步驟跳轉和步驟掛起的能力。
- ITaskStepRuntime則是把函數參數統一管理起來,便於向下傳遞。
interface ITaskStepRuntime {
IEvalScope getEvalScope();
ITaskStepState getState();
ITaskRuntime getTaskRuntime();
ICancelToken getCancelToken();
Set<String> getOutputNames();
default boolean needOutput(String name) {
Set<String> names = getOutputNames();
return names == null || names.contains(name);
}
default Object getValue(String name) {
return getEvalScope().getValue(name);
}
default void setValue(String name, Object value) {
getEvalScope().setLocalValue(name, value);
}
default Object getResult() {
return getLocalValue(TaskConstants.VAR_RESULT);
}
}ITaskStepRuntime除了包含所有步驟外部傳入的參數之外,還暴露了內部的狀態信息
,額外提供了IEvalScope和ITaskStepState變量。其中ITaskStepState是步驟實例的持久化狀態信息,可以用於實現實現類似Coroutine的suspend/resume機制。
IEvalScope是步驟內部的變量作用域,它通過父子關係構成了類似詞法作用域的作用域鏈。當從scope中讀取變量的時候,如果在當前scope中沒找到,就會自動向上到父scope中去找。一般情況下stepScope的父是TaskScope,也就是説在當前步驟的變量作用域中查找不到的話,會在共享的任務級別的變量作用域中查找,並不會在父步驟的scope中查找,除非步驟實例上設置了useParentScope=true。useParentScope允許在父步驟的scope中查找,從而實現類似函數閉包的效果。
<sequential name="parentStep">
<input name="a"/>
<steps>
<!-- 如果設置了useParentScope=true,則不需要聲明input
就可以直接讀取父scope中的變量a
-->
<xpl name="step1" useParentScope="true">
<source>
return a + 1
</source>
</xpl>
</steps>
</sequential>三. 比函數更強的是包裝後的函數
如果邏輯編排的對象就是普通的函數,那它和手寫代碼有什麼區別?除了把AST抽象語法樹可視化之外,邏輯編排還能做點更有價值的事情嗎?可以,我們可以升級一下編排的對象。
參與編排的可以不是一窮二白的裸函數(Naked Function),而是被重重修飾過的富函數(Rich Function)。
在我們的宇宙中,基本粒子如夸克和電子本身並沒有靜止質量,但是它們浸泡在無處不在的希格斯場中,被希格斯場所拖拽(修飾),從而使得我們觀測到的重整化電子產生了所謂的有效質量。
在現代的面向對象程序語言中,註解(Annotation)機制基本已經成為標配,甚至發展到了某種近乎氾濫的程度。很多程序框架的主要工作就是不辭辛苦的將執行邏輯都搬遷到註解處理器中。
// 示例函數由智譜清言AI生成
@GetMapping("/example/{id}")
@Cacheable(value = "examples", unless = "#result == null") // 緩存響應結果
@Retryable(value = {Exception.class}, maxAttempts = 3, backoff = @Backoff(delay = 1000)) // 重試策略
@Transactional(readOnly = true) // 聲明事務為只讀
@Secured({"ROLE_ADMIN", "ROLE_USER"}) // 權限註解,限制訪問權限
@RateLimiter(key = "exampleService", rate = "5/minute") // 限流注解
@Fallback(ExampleServiceFallback.class) // 服務降級註解
@AuditTrail // 自定義註解,用於記錄操作日誌
public Example getExampleById(@PathVariable("id") Long id) {
// 業務邏輯處理
return exampleRepository.findById(id);
}函數註解的作用本質上就是利用類似AOP的機制對原始函數進行增強,在框架中,我們最終使用的一般都是經過Interceptor包裹的增強函數。實際上,在服務層,我們很少會使用一個沒有任何註解的裸函數。
在函數式編程領域,也存在一種類似AOP增強的函數增強機制,稱為代數效應(Algebraic Effect)。
// 示例代碼由智譜清言AI生成
def log(message):
perform print(message)
def handlePrint(effect):
if effect == "print":
return lambda message: println(message)
withHandler handlePrint:
log("Hello, world!")在log函數中,perform print(message)表示產生一個print效應,但是它不會立即執行打印操作。相反,它將這個效應請求委託給當前作用域內的處理程序。
withHandler將處理程序handlePrint綁定到當前的代碼塊上。當我們調用log("Hello, world!")時,它會產生一個print效應,這個效應會被handlePrint處理程序攔截,並執行打印操作。perform print的作用相當於是定義了一個定位座標,然後withHandler會定位到這個座標處,將它替換為增強後(往往帶有副作用)的函數。
NopTaskFlow中所有Step的元模型都繼承自如下基礎結構,相當於是允許添加一些共性的修飾。
<xdef:define xdef:name="TaskStepModel" executor="bean-name" timeout="!long=0"
name="var-name" runOnContext="!boolean=false" ignoreResult="!boolean=false"
next="string" nextOnError="string">
<input name="!var-name" xdef:name="TaskInputModel" type="generic-type" mandatory="!boolean=false"
fromTaskScope="!boolean=false" xdef:unique-attr="name">
<source xdef:value="xpl"/>
</input>
<output name="!var-name" xdef:name="TaskOutputModel" toTaskScope="!boolean=false" type="generic-type"
xdef:unique-attr="name" exportAs="var-name">
<source xdef:value="xpl"/>
</output>
<when/>
<validator/>
<retry/>
<catch/>
<finally/>
<throttle/>
<rate-limit/>
<decorator name="!string"/>
</xdef:define>- executor: 在指定的線程池上執行
- timeout: 整個步驟的超時時間,如果超時在自動取消,拋出NopTimeoutException
- runOnContext: 投遞到IContext的任務隊列中執行,可以確保不會並行處理
- ignoreResult: 忽略RESULT返回值,不把它更新到父步驟的scope中。有時需要加入一些日誌步驟,設置這個屬性可以避免影響原先的運行上下文
- next: 執行完本步驟之後會自動跳轉到指定步驟
- nextOnError: 執行本步驟失敗的時候跳轉到指定步驟
- when: 滿足判斷條件之後才會執行本步驟,否則直接跳過
- validator:對Inputs變量進行驗證
- retry: 如果步驟失敗,可以按照指定的重試策略進行重試
- catch/finally:捕獲步驟異常進行一些額外處理
- throttle/rate-limit:控制執行速率
- decorator: 在NopIoC中可以註冊自定義的decorator
interface ITaskStepDecorator {
ITaskStep decorate(ITaskStep step, TaskDecoratorModel config);
}decorator如果是節點的父節點,會導致節點的座標(從父節點開始的唯一路徑)不穩定。例如假設當前路徑為 main/step1/sub-step1,如果僅僅是做一些局部調整,增加了一個裝飾器decorator1,則路徑就可能變成了 /main/step1/decorator1/sub-step1。如果將decorator獨立出來,將它們作為步驟節點的屬性節點,則可以使得我們在業務層面認知的座標更加穩定。
四. 考不上三本也能實現Coroutine
SpringBatch是Spring生態中用於批處理任務的一個邏輯編排框架。它針對批處理任務的可恢復(recoverable)的要求提供了從失敗點重啓的功能。在概念層面上,SpringBatch支持如下調用:
try {
JobExecution execution = jobLauncher.run(job, jobParameters);
} catch (Exception e) {
e.printStackTrace();
}
// 修復報錯問題之後,如果job尚未執行完畢,我們可以再次用同樣的參數去執行job,
// 它會自動從上次中斷處繼續執行
jobLauncher.run(job, jobParameters);Job執行報錯時會拋出異常,中斷執行。如果我們修復了報錯的問題,則可以重新執行Job,它會自動定位到上次中斷的地方,繼續向下執行。在概念層面上,SpringBatch中的Job可以被看作是一種“可以暫停和恢復執行”的函數。在學術領域,對於具有暫停(中斷)和恢復(繼續執行)的能力的函數有一個專門的術語,這就是所謂的協程(Coroutine)。只不過,SpringBatch中的Job是因為發生異常被動暫停的,而一般化的協程概念支持程序在執行過程中主動暫停,讓出控制權。
現代的程序語言,如JavaScript/Python/Kotlin/C#/Go/Swift/Lua/Ruby/Rust等,都內置了協程或者等價的概念。async/await語法本質上就是一種協程,它是出現異步調用的時候主動暫停。
JDK21中也已正式加入了協程支持
有些人將協程理解為輕量化的用户空間的線程,但實際上這只是協程概念的一種具體應用而已。根據維基百科的定義
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing
multiple entry points for suspending and resumingexecution at certain locations.
顯然協程是一個比線程概念應用更廣泛、更加細粒度的概念。
JavaScript中的Coroutine
下面我們來看一下JavaScript語法中的Generator函數,它本質上就是一種協程機制。
=== 以下是智譜清言AI的創作====
下面是一個使用 JavaScript Generator 函數演示循環的最簡單示例。這個示例中的 Generator 函數將遍歷一個數字數組,並在每次迭代中產生一個數字。使用 yield 關鍵字,我們可以在每次迭代後暫停函數的執行,並在下次調用 next() 方法時繼續執行。
// 定義一個 Generator 函數
function* generateNumbers() {
// 使用 for 循環遍歷數字數組
for (let i = 0; i < 5; i++) {
// 使用 yield 關鍵字暫停函數執行,併產生當前的數字 i
yield i;
}
}
// 調用 Generator 函數,得到一個遍歷器對象
const iterator = generateNumbers();
// 使用 next() 方法手動遍歷 Generator 函數的每個狀態
console.log(iterator.next()); // { value: 0, done: false }
console.log(iterator.next()); // { value: 1, done: false }
console.log(iterator.next()); // { value: 2, done: false }
console.log(iterator.next()); // { value: 3, done: false }
console.log(iterator.next()); // { value: 4, done: false }
console.log(iterator.next()); // { value: undefined, done: true }在上面的代碼中,generateNumbers 是一個 Generator 函數,它包含一個 for 循環,循環從 0 到 4。在每次迭代中,yield i 會產生當前的數字 i,並暫停函數的執行。
當我們調用 generateNumbers() 時,它並不立即執行,而是返回一個遍歷器對象。我們可以通過調用這個對象的 next() 方法來手動遍歷 Generator 函數的每個狀態。每次調用 next(),Generator 函數都會從上次 yield 表達式的地方繼續執行,直到遇到下一個 yield 或函數結束。
next() 方法的返回值是一個對象,其中 value 屬性是當前 yield 表達式的值,done 屬性是一個布爾值,表示是否已經遍歷完成。當 done 為 true 時,表示 Generator 函數已經執行完畢,value 屬性將是 undefined。
通過這個示例,我們可以看到 Generator 函數的暫停和繼續執行的概念。yield 關鍵字用於暫停函數的執行,並將一個值傳遞給 next() 方法的調用者。調用 next() 方法時,函數會從上次暫停的地方繼續執行。這個過程可以重複進行,直到 Generator 函數執行完畢。
====智譜清言的創作結束===
TaskFlow對Coroutine的實現
“可以暫停和恢復執行的函數”這一概念,表面上看起來非常簡單,實際實現起來那也是一點都不復雜。根據vczh(梅啓銘)的研究,考不上三本也能給自己心愛的語言加上Coroutine。
仔細回想一下Dijkstra的論文,他指出結構化編程會自動引入一個座標系,在這個座標系中只需要知道少數幾個座標值,就可以精確定位到程序運行時空間中的一個執行狀態點。那麼,如果要實現函數的暫停和恢復,只需要想辦法把這幾個座標記下來,然後再提供一個跳轉到指定座標處的機制就可以了。
一般程序語言內置的Coroutine需要最大化運行性能,必須充分利用語言運行時的執行堆棧信息等,所以實現邏輯看起來有些雲山霧繞,貌似很高級,實則是因為所處層次太低級(更接近機器碼層級)導致的。
NopTaskFlow內置了類似Coroutine的機制,利用它可以實現批處理任務的失敗重啓。因為是使用高級語言結構實現,也不用特別考慮極限性能,所以具體的實現方案非常簡單,考不上高中都可以理解。首先我們來看一個循環如何實現suspend和resume。
for (let i = 0; i < 5; i++) {
executeBody();
}中斷/重啓的困難在於這個循環中用到了一些臨時的狀態變量,比如上面的i。當我們中斷執行的時候會丟失這些臨時狀態信息,那自然也就無法恢復執行。所以,實現Coroutine的第一步是將所有的臨時變量都蒐集起來,轉換成某個類的成員變量。這樣就可以把這些內部的狀態信息暴露給某個外部的管理者。
class LoopNTaskStep extends AbstractTaskStep{
public TaskStepReturn execute(ITaskStepRuntime stepRt) {
LoopStateBean stateBean = stepRt.getStateBean(LoopStateBean.class);
if (stateBean == null) {
stateBean = new LoopStateBean();
// 初始化循環變量
int begin = ConvertHelper.toPrimitiveInt(beginExpr.invoke(stepRt), NopException::new);
int end = ConvertHelper.toPrimitiveInt(endExpr.invoke(stepRt), NopException::new);
int step = stepExpr == null ? 1 : ConvertHelper.toPrimitiveInt(stepExpr.invoke(stepRt), NopException::new);
if (step == 0)
throw TaskStepHelper.newError(getLocation(), stepRt, ERR_TASK_LOOP_STEP_INVALID_LOOP_VAR)
.param(ARG_BEGIN, begin).param(ARG_END, end).param(ARG_STEP, step);
stateBean.setCurrent(begin);
stateBean.setEnd(end);
stateBean.setStep(step);
stepRt.setStateBean(stateBean);
}
do {
if (!stateBean.shouldContinue()) {
return TaskStepReturn.RETURN_RESULT(stepRt.getResult());
}
if (varName != null) {
stepRt.setValue(varName, stateBean.getCurrent());
}
if (indexName != null) {
stepRt.setValue(indexName, stateBean.getIndex());
}
TaskStepReturn stepResult = body.execute(stepRt);
if (stepResult.isSuspend())
return stepResult;
// 處理同步返回的情況
if (stepResult.isDone()) {
stateBean.incStep();
stepRt.setBodyStepIndex(0);
stepRt.saveState();
stepResult = stepResult.resolve();
if (stepResult.isEnd())
return stepResult;
if (stepResult.isExit())
return RETURN_RESULT(stepRt.getResult());
} else {
// 處理異步返回的情況,這裏省略一些實現代碼
}
} while (true);
}上面是NopTaskFlow中對於loop-n步驟的實現,大致上相當於做如下改造:
while(state.index < state.end)
executeBody(state.bodyStepIndex, state)
state.index += state.step
}除了index,end等臨時變量(動態座標)之外,stateBean中還需要記錄當前body執行到哪一行這樣的靜態座標信息。總之,只要記錄下足夠多的座標信息,支持我們唯一確定當前執行狀態點即可。
在NopTaskFlow的實現中,“跳轉到指定座標點”的做法也非常簡單。就是從根節點開始執行,發現不是目標座標點就直接跳過,直到找到目標座標點為止。
單點定位可以被實現為掃描+過濾。
五. 數據驅動的圖模式
NopTaskFlow的sequential、loop等步驟相當於是模擬了過程式編程語言中的函數運行過程。此時,函數之間是通過位置關係形成隱式關聯,也就是説當一個步驟執行完畢之後,我們會找到它的後續位置處的步驟繼續執行。這裏所説的位置,就是在源碼層面可以確定的一組座標,所以過程式的執行可以看作是一種座標驅動的運行模式。
雖然NopTaskFlow提供了parallel步驟,可以實現一種結構化的並行處理(這裏所謂的結構化指的是並行執行的步驟在執行完畢後會自動執行join操作得到最終彙總後的返回結果),但是這種結構化也帶來一些組織形式上的限制,使得我們不能榨取系統的最大價值,實現最大限度的並行化。如果我們編寫的本來就是一個數據處理系統,此時我們可以把關注的重點轉移到數據對象上來,想象一下跟隨着數據對象在系統中傳播(專注於數據流而不是控制流)。只有計算中確實需要用到某個數據時,我們才需要建立連接管道,把相應的數據傳播過去。
NopTaskFlow提供了一種稱為圖模式(graphMode)的運行模式。在這種運行模式下,執行器不會像過程式編程那樣依次選擇下一個執行步驟,而是會對TaskStep的Input和Output進行依賴關係分析,根據實際數據使用情況來建立依賴圖,再根據依賴圖確定步驟的調度順序。
<graph name="test" enterSteps="enter1,enter2" exitSteps="exit">
<input name="x">
<source>1</source>
</input>
<steps>
<xpl name="enter1" executor="myExecutor">
<input name="x"/>
<source>
return x + 1
</source>
</xpl>
<xpl name="enter2" executor="myExecutor">
<input name="x"/>
<source>
return x + 2
</source>
</xpl>
<xpl name="process">
<input name="a">
<source>
STEP_RESULTS.enter1.outputs.RESULT
</source>
</input>
<input name="b">
<source>
STEP_RESULTS.enter2.outputs.RESULT
</source>
</input>
<source>
return a + b
</source>
</xpl>
...
</steps>
</graph>- 圖模式的graph步驟從enterSteps開始執行,執行到任意一個exitStep結束。
- GraphStepAnalyzer會自動對Input配置的source表達式進行抽象語法樹分析,提取其中的
STEP_RESULTS.{stepName}.outputs.{ouputVar}變量信息來構建DAG依賴關係圖,如果發現循環依賴則會拋出異常。STEP_RESULTS是graph步驟的scope中定義的一個Map變量,用於統一管理所有步驟的輸出。Input是在父步驟的scope中執行,所以可以通過STEP_RESULTS獲取到其他步驟的輸出。 -
GraphTaskStep執行時自動為子步驟增加了等待語義:只有當子步驟的Input變量都計算完畢之後,才會執行該子步驟。所以上面的process子步驟會在enter1和enter2兩個步驟都執行完畢後才會被啓動。
數據驅動只有在流處理的應用場景中才可以發揮最大效用。NopTaskFlow在定位上還是專注於邏輯步驟的組織,所以只提供了一種最簡單的DAG(有向無環圖)的運行模式。
退化的數據管道:
完整的流處理必然要求對數據連接管道進行建模,比如一定的暫存能力,窗口劃分能力等,管道容量被佔滿時還需要處理背壓(BackPressure)問題等。但是在NopTaskFlow中,因為已經假定了不支持流處理,同時限定了圖不會出現循環(DAG),所以我們可以推理得到一個結論:每個步驟最多隻會被觸發一次。
- 只有所有的Input都計算完畢的時候,才會執行步驟,一次執行只會產生一次Output。
- 所有的Input要麼來自於此前步驟的Output,要麼來自於外部輸入,所以如果前面的步驟只執行一次,產生一次輸出,則本步驟也只會執行一次。
- enterStep只受外部輸入影響,它只會執行一次。
在NopTaskFlow的設計中,每一個步驟都有一個唯一的座標(步驟名稱)。再考慮到每個步驟最多隻會被觸發一次,由此可以推論得到:每一個Input和每一個Output在運行時也都具有唯一的座標。Input和Output的連接可以看作是Input座標和Output座標之間的引用匹配。
例如 STEP_RESULTS.step1.outputs.a 表示子步驟step1的輸出變量a
在這種情況下,連接輸入和輸出的數據管道處於一種退化的狀態,它的設計容量為1,最多 只需要暫存一個元素即可,也就是説用一個Promise對象來表示就可以。在NopTaskFlow的GraphTaskStep實現中,我們的做法非常簡單:
- 註冊所有步驟的Promise,並通過Promise.waitAll建立依賴關係。
- 啓動所有enterStep
這裏並不需要建立複雜的任務隊列管理和調度機制,通過Promise建立依賴鏈條就足夠了。
步驟級別的依賴
表面上看起來Input和Output之間的依賴是變量級別,比步驟依賴要更細化一下。但是因為NopTaskFlow採用的是函數抽象,且不支持流式輸出,這導致步驟的Output只能在步驟結束之後才能被使用,而且多個Output要麼同時產生要麼同時不產生(步驟失敗的時候不會產生任何輸出)。這種情況下,我們依賴一個步驟的Output就是在依賴這個 步驟本身。
另外一個需要考慮的現實情況是,在實踐中我們實現的很多函數都不是純函數,它們都帶有沒有被輸出變量明確表達的副作用。如果不同的步驟相互協作的時候不僅僅依賴明確表達的輸入輸出關係,還需要依賴隱式存在的副作用,那麼我們也必然需要明確指定步驟級別的依賴關係。所以,NopTaskFlow在輸入輸出分析之外,還增加了waitSteps和next、nextOnError步驟依賴關係配置。
<xpl waitSteps="step1,step2" next="step4">
</xpl>區分正常和異常輸出
Java中的CompletionStage/CompletableFuture異步結果對象提供了thenApply/exceptionally/whenComplete等多種回調機制,可以分別在執行成功、執行異常以及執行結束(無論是否成功)時觸發回調函數,這使得我們可以針對自己的需求選擇性的識別成功和失敗路徑。
類似的,在NopTaskFlow的圖模式中,每個步驟的輸出結果都對應一個StepResultBean對象,它包含error和outputs兩個部分。
class StepResultBean {
ErrorBean error;
Map<String,Object> outputs;
}在Input表達式中如果引用了error屬性,則表示應該在前驅步驟異常時觸發。如果同時引用了error和outputs中的變量,則表示在前驅步驟結束時觸發。
<xpl name="process">
<input name="step1Error">
<source> STEP_RESULTS.step1.error </source>
</input>
<input name="step2Result">
<source> STEP_RESULTS.step2.outputs.RESULT </source>
</input>
</xpl>上面的示例表明,process步驟只會在step1出錯、step2成功的情況下才會被觸發。
六. TaskFlow與行為樹(Behavior Tree)的區別
行為樹是遊戲AI領域常用的一種邏輯編排方案。著名的遊戲設計引擎Unity就支持行為樹插件。應該説,NopTaskFlow的設計也受到了行為樹的直接影響,以至於它可以直接表達行為樹的邏輯。
關於行為樹的介紹可以參考如下文章:
- 行為樹入門教程
- 行為樹的理論與實踐入門
我們也可以利用AI快速學習一下。如果你問智譜清言AI: 什麼是行為樹?回答限制在100個字以內。它會回覆:
行為樹是一種用於模擬和控制人工智能(AI)行為的圖形化編程範式,它將複雜的行為分解為一系列簡單的任務和條件,並通過樹狀結構組織這些任務。每個節點代表一個動作或條件判斷,AI通過從根節點遍歷至葉節點來選擇和執行行為。
AI每次回覆的內容是隨機的,需要自己從中進行挑選。也可以一次性讓它返回五個不同的回覆。
然後可以要求它進行更詳細的介紹,並舉例説明
===以下為智譜清言AI的創作===
行為樹(Behavior Tree)是人工智能領域中使用的一種用於描述和控制機器人或虛擬角色行為的算法。它是一種層次化的圖形化工具,能夠清晰地表示覆雜的決策邏輯,並易於理解和修改。
行為樹由節點組成,主要分為以下幾種類型:
- 控制節點(Control Nodes):控制節點的子節點的執行邏輯。常見的控制節點包括:
- 選擇節點(Selector):它的子節點會被順序評估,直到找到一個可以成功執行的孩子節點。
- 順序節點(Sequence):它的子節點會按順序執行,如果某個子節點執行失敗,整個順序節點就會失敗。
- 並行節點(Parallel):它的子節點會同時執行,根據需要的條件(如所有子節點成功或只需部分成功)來決定整個並行節點的成功或失敗。
- 執行節點(Action Nodes):執行節點代表具體的行為或動作。例如,移動到一個位置,攻擊敵人等。
- 條件節點(Condition Nodes):條件節點用於檢查某個特定的條件是否滿足,它通常返回成功或失敗。
行為樹通過組合這些節點來構建決策邏輯。它具有以下優點: - 模塊化:行為樹的結構允許開發者將複雜的行為分解成小的、可重用的模塊。
- 靈活性和可擴展性:可以很容易地通過添加或修改節點來調整行為。
- 清晰性:行為樹提供了一種直觀的方式來觀察和理解角色的行為邏輯。
- 易於調試:在執行過程中,可以清楚地看到每個節點的狀態,便於調試和優化。
行為樹廣泛應用於遊戲AI、機器人控制、自動化系統等領域。
以下是一個簡單的行為樹例子,用於控制一個虛擬角色在遊戲中尋找並收集資源的行為。
Selector
├── Sequence
│ ├── Condition: "檢查資源列表是否為空"
│ ├── Action: "選擇最近的資源"
│ └── Sequence
│ ├── Action: "移動到資源位置"
│ └── Action: "收集資源"
│
└── Action: "巡邏"在這個行為樹中,我們有一個選擇節點(Selector)作為根節點,它包含兩個子節點:一個順序節點(Sequence)和一個動作節點(Action)。
- 選擇節點(Selector):首先評估第一個子節點(順序節點),如果該子節點失敗,則評估第二個子節點(巡邏動作)。
- 順序節點(Sequence):這個節點包含三個子節點,它們會按順序執行:
- 條件節點:檢查當前資源列表是否為空。如果資源列表為空,條件失敗,整個順序節點失敗,進而導致選擇節點評估下一個子節點。
- 動作節點:選擇最近的資源,並將其設置為當前目標。
-
順序節點:這個內部順序節點包含兩個動作節點:
- 移動到資源位置:角色移動到選定的資源位置。
- 收集資源:角色執行收集資源的動作。
- 動作節點(巡邏):如果順序節點失敗(比如沒有找到資源),角色將執行巡邏動作。
這個行為樹的基本邏輯是:如果角色知道有資源可以收集,它會嘗試移動到資源位置並收集它;如果沒有資源可收集,角色將執行巡邏動作。通過這種方式,行為樹可以確保角色始終有事情做,並根據當前遊戲狀態動態調整行為。
===智譜清言創作結束===
使用NopTaskFlow我們可以用一種一比一的方式實現以上行為樹的邏輯。
<task>
<steps>
<selector name="actions">
<steps>
<sequential name="step1">
<steps>
<exit name="檢查資源列表是否為空">
<when>
<agent:檢查資源列表是否為空/>
</when>
</exit>
<xpl name="選擇最近的資源">
<source>
<agent:選擇最近的資源/>
</source>
</xpl>
<sequential>
<steps>
<xpl name="移動到資源位置">
<source>
<agent:移動到資源位置/>
</source>
</xpl>
<xpl name="收集資源">
<source>
<agent:收集資源/>
</source>
</xpl>
</steps>
</sequential>
</steps>
</sequential>
<xpl name="巡邏">
<source>
<agent:巡邏/>
</source>
</xpl>
</steps>
</selector>
</steps>
</task>- 行為樹要求它的節點總是返回當前執行狀態,它具有三個可能的值:成功(Success)、失敗(Failure)和運行中(Running)。NopTaskFlow的步驟節點返回類型為TaskStepReturn,它提供了判斷函數可以區分出行為樹所要求的三種狀態。同時,TaskStepReturn還支持返回
CompletionStage異步對象,可以觸發異步回調。 - NopTaskFlow內置了
selector步驟,可以直接表達行為樹的選擇節點功能。 - NopTaskFlow的
exit步驟用於退出當前順序執行序列,結合when判斷條件,可以起到行為樹的Condition節點的作用。 - NopTaskFlow的parallel步驟可以表達行為樹中的Parallel節點的功能。同時,parallel步驟還提供了aggregator配置,可以實現最簡單的並行任務分解合併。
原則上使用行為樹能夠表達的邏輯,使用NopTaskFlow都可以表達,而且因為NopTaskFlow的步驟內置了timeout/retry等修飾功能,在表達常見邏輯的時候嵌套層級數比行為樹要更少,表達更加緊湊。
行為樹的一個優點是所有邏輯都直觀可見。NopTaskFlow可以考慮使用類似腦圖的方式去顯示,使用腦圖中常用的圖標、標籤等表達各種步驟修飾功能,而不必一定要把這些信息展現為一個節點。
行為樹主要應用於單個Agent的決策和行動過程,相當於是將決策樹和行動序列編織在一起。在概念層面上,Sequence相當於AND(與)邏輯,而Selector相當於OR(或)邏輯。行為樹的步驟更接近於Predicate抽象,只返回True/False(一般還會更新全局上下文),並不支持更通用的返回值類型。NopTaskFlow建立在更一般化的函數抽象上,包含了行為樹的功能,但是在實現層面上,它並沒有針對遊戲AI應用場景進行優化。
七. TaskFlow與工作流(Workflow)的區別
工作流是普通程序員比較熟悉的一類可視化編排工具,那麼工作流與本文所介紹的邏輯編排有什麼區別?能不能用工作流引擎來實現邏輯編排?
在Nop平台中,NopTaskFlow和NopWorkflow是兩個獨立設計的編排引擎。因為兩者都是圖靈完備的,所以實際上可以用任何一個來完成邏輯編排工作。內部結構上,NopWorkflow與NopTaskFlow的圖模式也有些接近。但是另一方面,NopTaskFlow和NopWorkflow內置了不同的設計假定,要解決的具體問題實際上有比較大的差異,面對不同的業務場景時我們會選擇使用不同的編排引擎。
首先來看一下工作流引擎的核心概念。
====以下是智譜清言AI對工作流的介紹===
軟件開發中常用的工作流引擎通常涉及以下幾個核心概念:
-
流程定義(Process Definition):
- 這是對業務流程的模型化表示,通常通過流程圖來展現。流程定義包含了流程中的各個步驟、決策點、任務分配以及流轉規則等。
-
節點(Node)或任務(Task):
- 節點或任務是工作流中的基本單元,代表了流程中的一個步驟或活動。每個節點可以指派給不同的角色或個人去執行。
-
流轉(Transition):
- 流轉定義了從一個節點到另一個節點的路徑和條件。條件可以是自動的(如時間到達、某個事件發生)或需要人工判斷的。
-
事件(Event):
- 事件是在特定條件下觸發的,可以導致流程中的特定操作,如開始一個新任務、結束一個任務或改變流程的方向。
-
網關(Gateway):
- 網關用於控制流程的分支和合並。例如,排他網關(Exclusive Gateway)在流程中實現決策,並行網關(Parallel Gateway)允許流程中的多個分支併發執行。
-
變量(Variable):
- 變量用於存儲流程執行過程中的數據,可以是業務數據也可以是流程控制數據,如用户輸入、系統數據等。
-
任務分配(Task Assignment):
- 任務分配定義瞭如何將任務分配給執行者,可以基於角色、個人、技能或其他業務規則。
-
業務規則(Business Rule):
- 業務規則用於指導和約束流程的流轉,通常用於複雜的決策邏輯。
-
工作項(Work Item):
- 當流程執行到某個節點時,會生成一個工作項,它代表了需要執行的具體任務。
-
歷史記錄(History):
- 工作流引擎通常會記錄流程實例的執行歷史,包括哪個節點被誰在何時執行,以及執行的結果等。
-
用户界面(User Interface):
- 用户界面允許最終用户與工作流引擎交互,執行任務、查看流程狀態等。
-
集成(Integration):
- 工作流引擎通常需要與企業中的其他系統(如ERP、CRM等)集成,以便於交換數據和觸發流程。
這些核心概念在不同的工作流引擎中可能有不同的稱呼和實現方式,但基本原理是相似的。工作流引擎通過這些核心概念為業務流程提供自動化、監控和管理的能力。
====智譜清言的創作結束====
從上面的描述可以看出,在概念層面上,工作流引擎主要編排的是業務流程,也就是有多種人員參與的、更高層(貼近人和實際的業務)的、時間跨度更長的邏輯。而一般我們説的邏輯編排是應用在比較局部的、更加底層的技術邏輯。
在工作流引擎中,參與者(Participant)和工作分配(Assignment)是一個核心概念。在國內的應用中,更是特化成了所謂的審批流,全部邏輯都是關於任務指派與分配。邏輯編排的任務一般都是自動執行,不會直接涉及到人機交互。
在Nop平台的設計中,NopWorkflow的Step的執行內容可以用NopTaskFlow去表達。總的來説,NopTaskFlow要更輕量級,比如説NopTaskFlow可以複用單個步驟,而且可以不對執行狀態進行持久化,而NopWorkflow只能複用整個子流程,同時所有執行狀態都要求持久化。
一個有趣的事情是,國外的工作流引擎的設計原理也是源於流程自動化,也就是説不需要人工介入的場景,當它應用於人機交互頻繁的場景時天然的會顯現出一種不適應性。NopWorkflow為此對基礎結構進行了補充調整,因此偏離了目前業內主流的BPMN(Business Process Model and Notation,業務流程模型與符號)建模語言,但是更容易映射到界面操作上。更有意思的事情是,NopWorkflow的設計在形式上反而更接近於工作流理論鼻祖之一的Petri網的結構。下面簡單介紹一下Petri網。
- 詳細介紹可以參考Hello,工作流
====以下是智譜清言AI對Petri網的介紹====
Petri網是一種用於描述和分析併發系統、分佈式系統、通信協議以及其他各種信息處理系統的數學模型。它由卡爾·亞當·佩特里(Carl Adam Petri)在1962年首次提出,並以他的名字命名。Petri網提供了一種圖形化的表示方法,通過一組節點和連接這些節點的有向弧來表示系統的狀態和狀態變化。
Petri網的主要元素包括:
- 位置(Place):用圓圈表示,代表系統中的資源或條件。位置可以包含令牌(Token),令牌的數量代表資源的數量或條件的滿足程度。
- 變遷(Transition):用條形或矩形表示,代表系統中的事件或操作。變遷的觸發會導致令牌在位置之間移動。
- 弧(Arc):用有向線段表示,連接位置和變遷。弧上可以標記權重,表示觸發變遷所需的令牌數量。
Petri網的工作原理基於令牌的流動。當一個變遷的所有輸入位置都包含足夠數量的令牌時,這個變遷被稱為“可觸發的”。觸發變遷後,輸入位置中的令牌會被消耗,而輸出位置則會根據弧的連接產生新的令牌。這個過程代表了系統狀態的變化。
Petri網的特性使其適用於多種領域的建模和分析,包括:
- 併發性和並行性
- 同步和通信
- 資源分配和死鎖分析
- 性能評估和優化
- 軟件工程和業務流程管理
Petri網的一個重要特性是它的數學基礎,這使得可以通過形式化的方法來分析和驗證系統的性質,如可達性、活性、安全性等。此外,Petri網還可以擴展為有色Petri網、時間Petri網等多種變體,以適應更復雜的建模需求。
====智譜清言的創作結束====
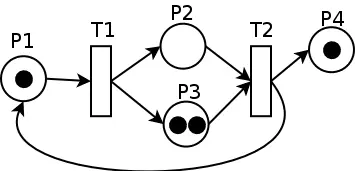
Petri網在形式上的一個明顯特徵是它是一個二部圖(Bipartite Graph)。在狀態節點之間遷移的時候必須經過一個明確標記出來的操作節點,而且這兩類節點之間都直接支持多對一和一對多連接,這使得Petri網在映射到具體應用時可以非常靈活。
NopWorkflow的基本結構也是step和action所構成的一個二部圖。
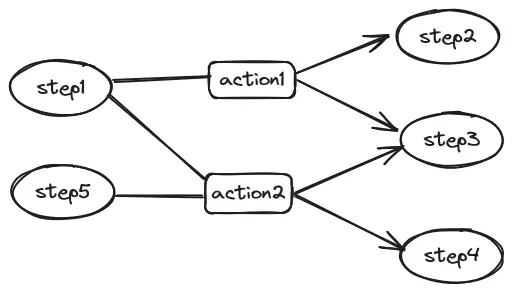
<workflow>
<actions>
<action name="action1" forActivated="true">
<when> 動態顯示條件</when>
<transition>
<to-step stepName="step2" />
<to-step stepName="step3" />
</transition>
</action>
...
</actions>
<steps>
<step name="step1">
<ref-actions>
<ref-action name="action1" />
<ref-action name="action2" />
</ref-actions>
</step>
...
</steps>
</workflow>action可以直接映射到界面上顯示的操作按鈕,並且可以通過forActivated/forHistory/forReject/forWithdraw等開關屬性控制在不同的步驟狀態下是否允許執行此action,也可以由此來控制按鈕的顯隱。如果需要更加動態化的業務判斷條件,還可以配置action的when代碼段。明確定義出action節點使得人工操作界面和工作流模型的映射更加自然、直接。
八. 為什麼説是下一代
説NopTaskFlow是下一代邏輯編排引擎,可能有些人會不服氣:我看這個設計平平無奇,都是早已被反覆實現過的東西,創新點在哪?別急,這裏的下一代指的不是它的功能多,也不是性能高,而是它基於下一代軟件構造理論:可逆計算理論所構建,從而呈現出與現有的軟件架構設計迥然不同的典型特徵。這些特徵是與邏輯編排本身無關的。這裏的邏輯是這樣的:
- 可逆計算是下一代軟件構造理論
- Nop平台是可逆計算指導下從零開始構建的下一代低代碼開發平台
- NopTaskFlow是Nop平台的一個組成部分,它自動繼承了這個所謂下一代的特徵
這是一件真正有趣的事情。一般情況下,對於規則引擎、工作流引擎、報表引擎、邏輯編排引擎、ORM引擎、IoC引擎、GraphQL引擎等這些應用場景存在本質性差異的各類引擎框架,我們在開發的時候都是分別去分析、實現的,它們之間也很少共享底層設計和代碼(除了一些幫助類和通用的腳本引擎等)。Nop平台所提出的一個核心問題是:如何同時設計並實現所有可設想到的引擎?如果這個問題存在答案,那麼它一定不是一種業務層面的解決方案,也不可能是靠經驗積累而產生的設計技巧,必然只能是基於某種普適的數學原理。
如果我們仔細觀察一下現有的各類引擎框架,會發現每個有價值的引擎背後都存在一個特定的模型結構,而所有這些模型結構的構建存在着大量共性的要求:
- 如何實現模型的構建?如何驗證模型的有效性?
- 有沒有IDE中的編輯插件?能不能進行斷點調試?
- 模型能不能動態更新?如何動態更新?
- 能不能進行可視化設計?怎麼實現可視化設計器?
- 能不能擴展已有的模型?如何進行擴展?
- 不同的模型如何無縫嵌入並協同工作?
- 越來越多針對特定需求的假定被引入模型,如何保證運行時性能?
- 如何在已有模型的基礎上提供二次抽象機制?
很多人其實意識到了共性問題的存在,但是總結得到的只是一些抽象的設計原則和設計模式,並無法得到一個可複用的基礎技術底座。Nop平台則不同,它在可逆計算理論的指導下為DSL(Domain Specific Language)的設計和實現提供了一個標準化的套路,併為這個套路的實施配套建立了可複用的基礎技術設施。沿着這個套路去操作,無需編程即可自動實現很多功能。因此,Nop平台中的引擎實現代碼量往往要比類似的開源軟件框架要小一個數量級。詳細介紹參見:
- XDSL:通用的領域特定語言設計
- 通用的Delta差量化機制
- 低代碼平台中的元編程(Meta Programming)
具體到NopTaskFlow的實現,它的基本邏輯結構如下:
TaskFlowModel taskFlowModel = resourceComponentManager.loadComponentModel(taskFlowPath);
ITask task = taskFlowModel.getTask(new TaskFlowBuilder());
ITaskRuntime taskRt = new TaskRuntimeImpl(taskStateStore);
taskStepReturn = task.execute(taskRt);- 實現NopTaskFlow的第一步也是最重要的一步是定義元模型task.xdef。然後平台就會根據元模型自動推導得到大量功能,包括生成解析器、驗證器、IDE插件、可視化設計器,實現動態模型緩存、差量合併、元編程等,解決前面提到的眾多共性問題。所有這些功能都被封裝在Loader抽象之下,loadComponentModel函數返回的就是經過可逆計算處理的模型對象。
- 描述式結構與運行時結構分離。描述式模型TaskFlowModel採用最小化信息表達,可以獨立分析並從中反向提取信息。可執行的運行時模型 ITask獨立於描述式結構,它由TaskFlowModel編譯得到,編譯結果可以緩存下來。一些邏輯編排引擎在設計時和運行時採用同樣的模型結果,就無法實現性能的最優化,同時會導致運行時的實現細節侵入到模型定義層面,無法實現最小化信息表達。關於最小化信息表達,可以參見業務開發自由之路:如何打破框架束縛,實現真正的框架中立性
-
運行時結構採用無狀態設計,通過ITaskRuntime這種上下文對象來傳遞狀態。一些邏輯編排引擎會採用比較傳統的面向對象結構,比如
class MyStep extends AbstractStep{ public void process(){ ... } }這種方式依賴於通過成員變量來傳播上下文信息或者強制要求使用ThreadLocal等全局對象,會導致不必要的結構依賴,難以實現動態模型更新,也難以實現性能的最優化。
- 通過元編程和Xpl模板語言實現擴展。在Nop平台中無需額外進行插件設計和擴展點設計,Nop平台內置的Delta定製機制自動支持對於任意模型屬性和節點的定製修改,並且每個模型節點都支持擴展屬性和擴展子節點,配合
x:gen-extends和x:post-extends元編程機制,可以在現有模型基礎上實現二次抽象封裝。可以同故宮Xpl模板語言的自定義標籤實現無限擴展。比如在NopTaskFlow中嵌入對於規則引擎的調用。
<xpl name="ruleStep" extType="rule-step">
<source>
<rule:ExecuteRule ruleName="test.MyRule" />
</source>
</xpl>在可視化設計器層面,我們可以識別extType屬性,然後將xpl節點的source段視為固定的XML配置格式,從而實現可視化編輯。
NopPlatform整體已經開源,可以在官網https://nop-platform.gitee.io 獲取相關資料。
目前NopTaskFlow的核心代碼只有3000多行,很容易集成在其他項目中使用。在下週六DDD和微服務系統設計在線研討會中我會詳細講解NopTaskFlow設計中的一些細節,歡迎參加。
https://shaogefenhao.com/libs/webinar-notes/
會議主題:Webinar for Java Common Solutions
會議時間:2024/04/13 21:00-22:00 (GMT+08:00) 中國標準時間 - 北京
重複週期:2022/12/03-2024/10/26 21:00-22:00, 每週 (週六)
點擊鏈接入會,或添加至會議列表:
騰訊會議:https://meeting.tencent.com/dm/FteBhNgMeyuu
騰訊會議:835-4748-1185