

視頻演示
基於深度學習的學生上課行為檢測系統
1. 前言
大家好,歡迎來到 Coding 茶水間!
今天要為大家介紹的是一款已落地的成品項目 —— 基於 YOLO 算法的學生上課行為檢測系統。在教育數字化轉型中,課堂行為分析是提升教學質量的關鍵,但傳統人工觀察效率低、主觀性強,而算法開發與系統集成又面臨專業門檻高、調試周期長的痛點。本項目精準解決這一需求,提供從模型訓練、算法復現到系統集成的全流程服務。本次展示的 Web 端系統(前端 Bootstrap、後端 Django),不僅集成了 YOLO V5/V8/V11/12 多模型加載、圖片 / 視頻 / 文件夾批量檢測、攝像頭實時流分析等核心功能,還加入了類別過濾、檢測數據 Excel 導出、識別歷史追溯及用户管理模塊,同時支持腳本化無界面檢測與模型自主訓練,旨在提供開箱即用、可定製化的教育場景檢測解決方案。接下來,讓我們通過詳細的功能演示,一同探索這套系統的技術細節與應用價值。
2. 項目演示
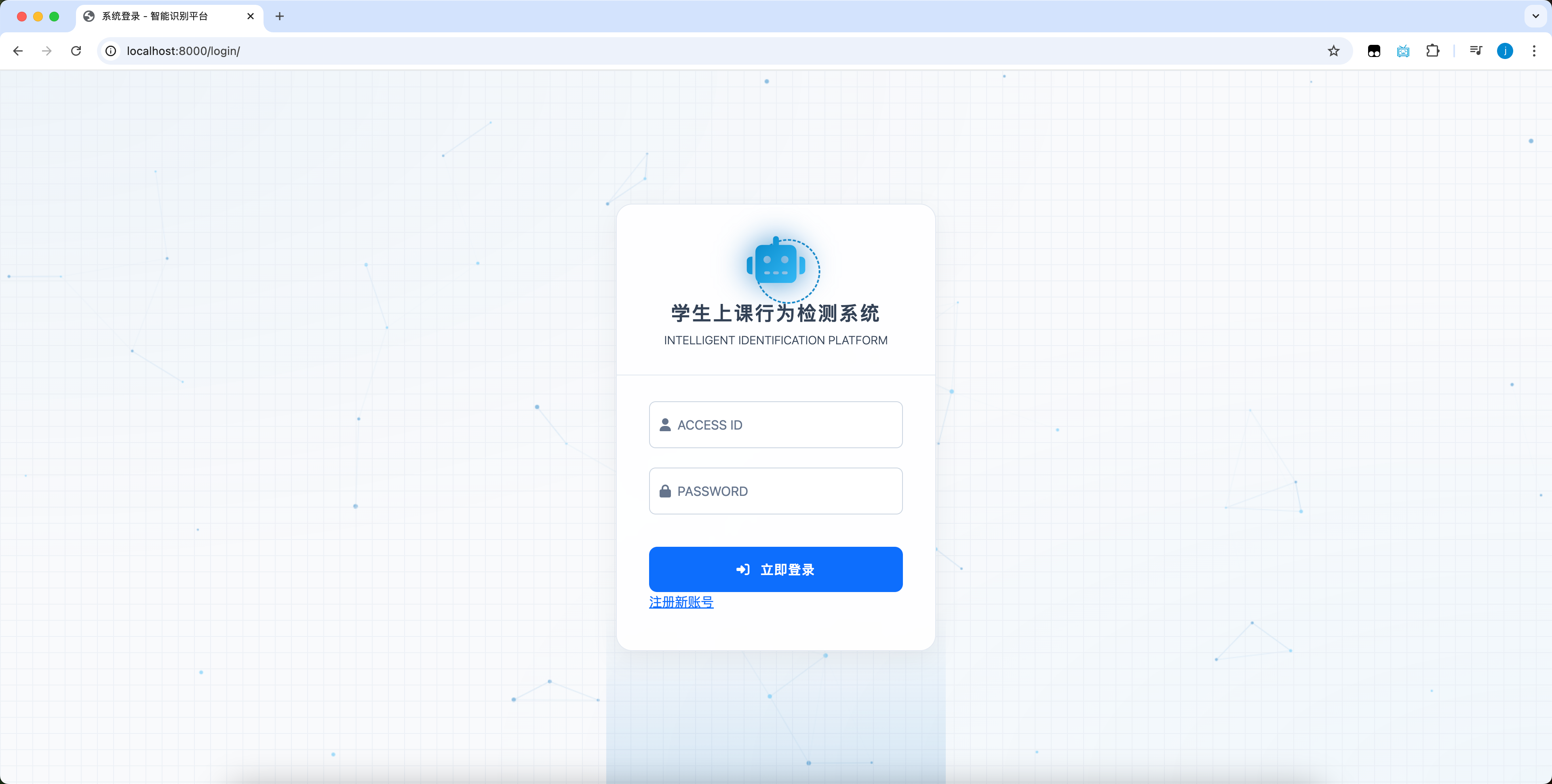
2.1 用户登錄界面
登錄界面佈局簡潔清晰,用户需輸入用户名、密碼驗證後登錄系統。
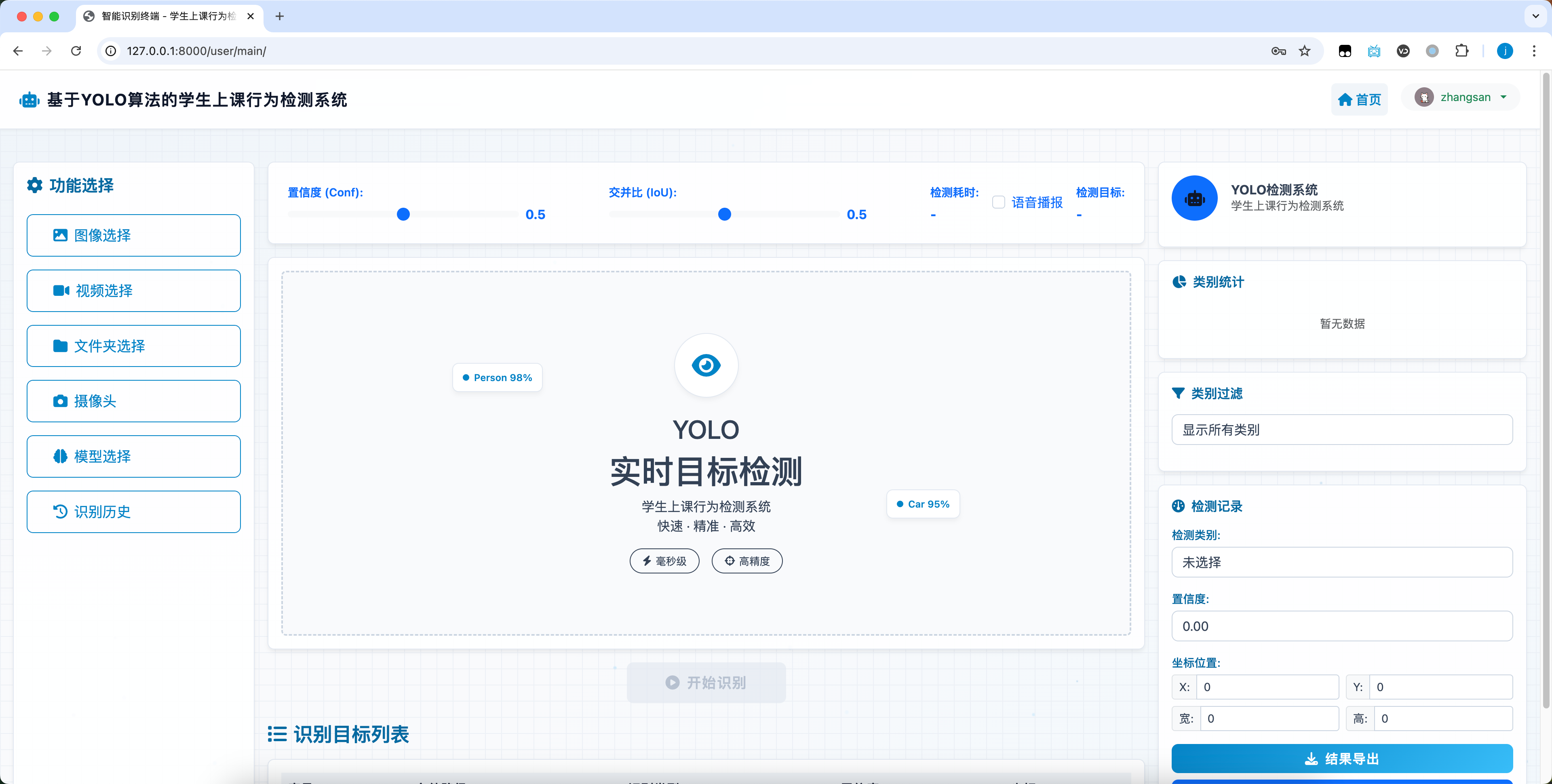
2.2 主界面佈局
主界面採用三欄結構,左側為功能操作區,中間用於展示檢測畫面,右側呈現目標詳細信息,佈局合理,交互流暢。
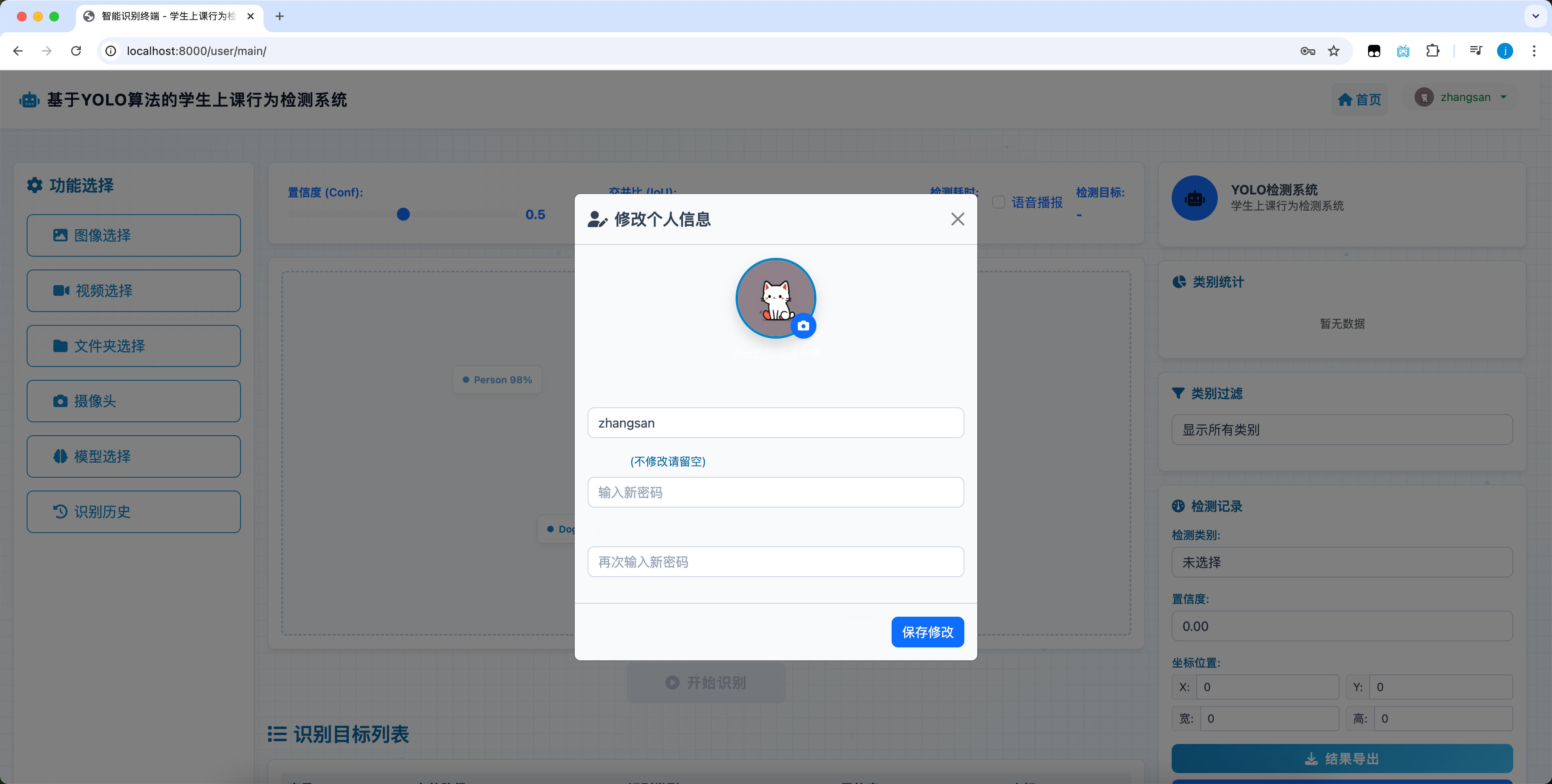
2.3 個人信息管理
用户可在此模塊中修改密碼或更換頭像,個人信息支持隨時更新與保存。
2.4 多模態檢測展示
系統支持圖片、視頻及攝像頭實時畫面的目標檢測。識別結果將在畫面中標註顯示,並且帶有語音播報提醒,並在下方列表中逐項列出。點擊具體目標可查看其類別、置信度及位置座標等詳細信息。

2.5 檢測結果保存
可以將檢測後的圖片、視頻進行保存,生成新的圖片和視頻,新生成的圖片和視頻中會帶有檢測結果的標註信息,並且還可以將所有檢測結果的數據信息保存到excel中進行,方便查看檢測結果。

2.6 多模型切換
系統內置多種已訓練模型,用户可根據實際需求靈活切換,以適應不同檢測場景或對比識別效果。
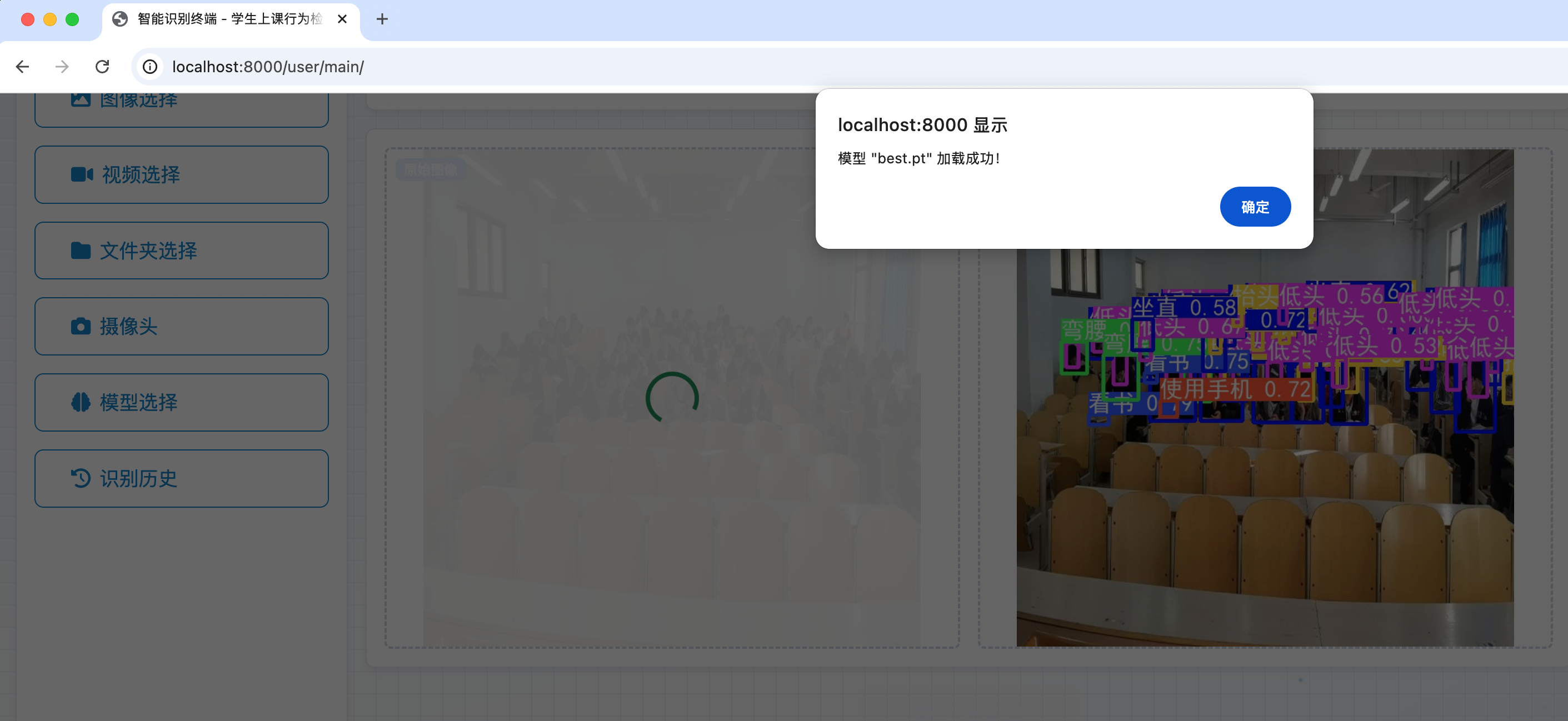
2.7 識別歷史瀏覽
系統內支持用户對識別歷史進行瀏覽,以方便用户查看歷史識別記錄,可以對識別歷史的結果圖片進行一個點擊放大。

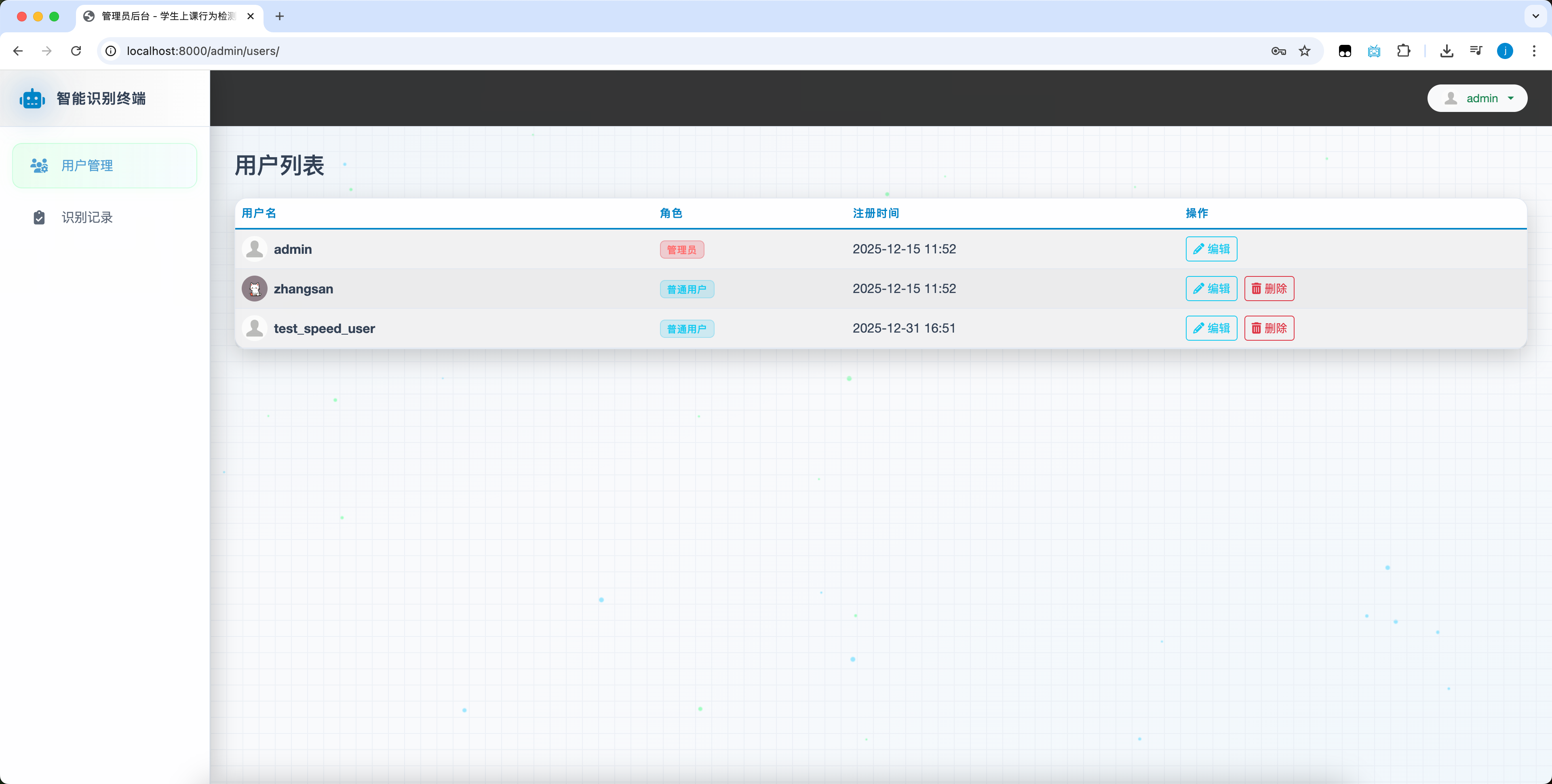
2.8 管理員管理用户信息
系統內支持管理員端的登錄操作,登錄以後可以對用户信息進行編輯修改和刪除,以方實現對用户信息的管理操作。
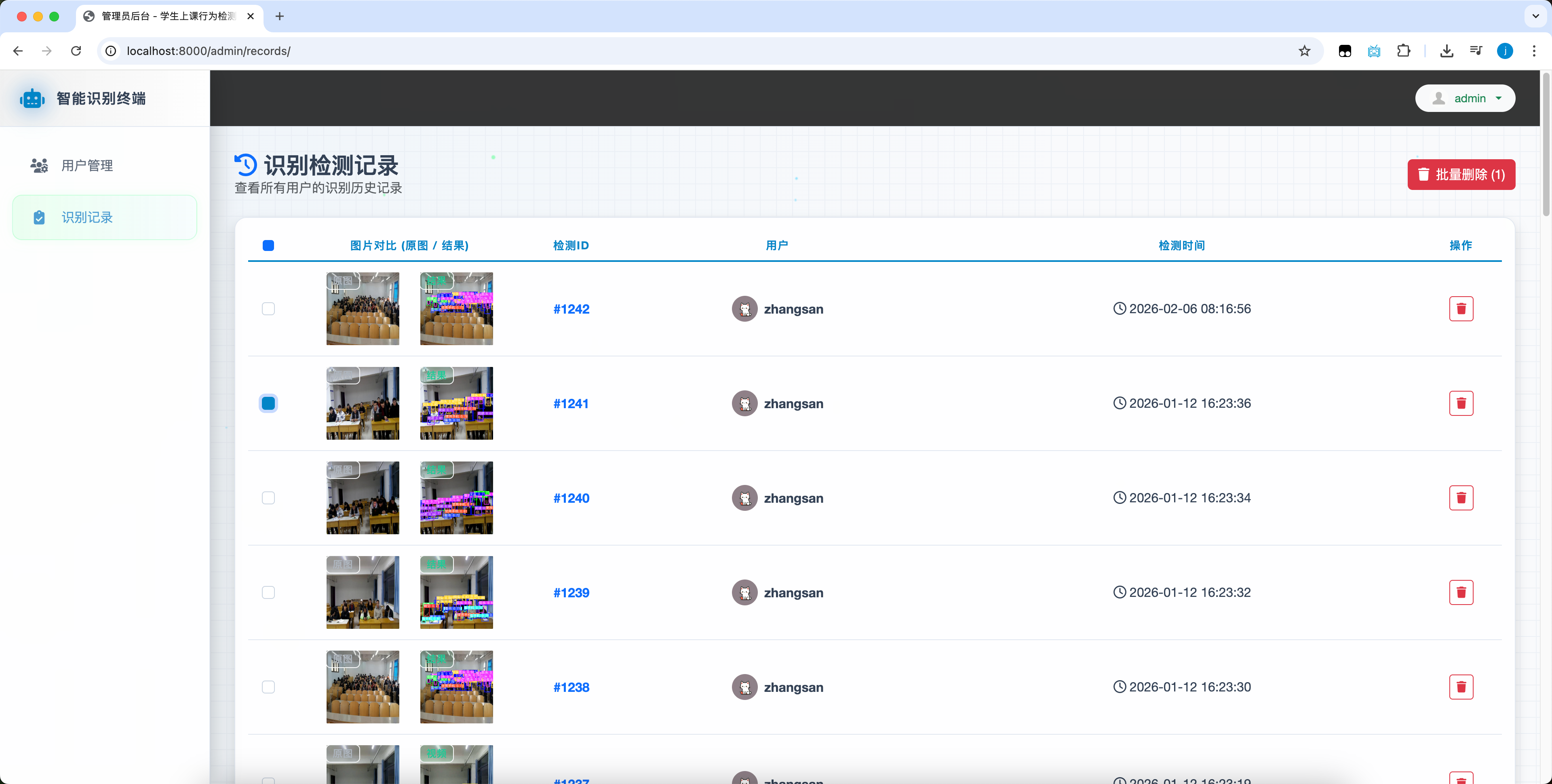
2.9 管理員管理識別歷史
系統內支持管理員對識別歷史的單條和多條歷史記錄的一個瀏覽和刪除操作,以方便管理員對識別歷史進行管理。
3.模型訓練核心代碼
本腳本是YOLO模型批量訓練工具,可自動修正數據集路徑為絕對路徑,從pretrained文件夾加載預訓練模型,按設定參數(100輪/640尺寸/批次8)一鍵批量訓練YOLOv5nu/v8n/v11n/v12n模型。
# -*- coding: utf-8 -*-
"""
該腳本用於執行YOLO模型的訓練。
它會自動處理以下任務:
1. 動態修改數據集配置文件 (data.yaml),將相對路徑更新為絕對路徑,以確保訓練時能正確找到數據。
2. 從 'pretrained' 文件夾加載指定的預訓練模型。
3. 使用預設的參數(如epochs, imgsz, batch)啓動訓練過程。
要開始訓練,只需直接運行此腳本。
"""
import os
import yaml
from pathlib import Path
from ultralytics import YOLO
def main():
"""
主訓練函數。
該函數負責執行YOLO模型的訓練流程,包括:
1. 配置預訓練模型。
2. 動態修改數據集的YAML配置文件,確保路徑為絕對路徑。
3. 加載預訓練模型。
4. 使用指定參數開始訓練。
"""
# --- 1. 配置模型和路徑 ---
# 要訓練的模型列表
models_to_train = [
{'name': 'yolov5nu.pt', 'train_name': 'train_yolov5nu'},
{'name': 'yolov8n.pt', 'train_name': 'train_yolov8n'},
{'name': 'yolo11n.pt', 'train_name': 'train_yolo11n'},
{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}
]
# 獲取當前工作目錄的絕對路徑,以避免相對路徑帶來的問題
current_dir = os.path.abspath(os.getcwd())
# --- 2. 動態配置數據集YAML文件 ---
# 構建數據集yaml文件的絕對路徑
data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml')
# 讀取原始yaml文件內容
with open(data_yaml_path, 'r', encoding='utf-8') as f:
data_config = yaml.safe_load(f)
# 將yaml文件中的 'path' 字段修改為數據集目錄的絕對路徑
# 這是為了確保ultralytics庫能正確定位到訓練、驗證和測試集
data_config['path'] = os.path.join(current_dir, 'train_data')
# 將修改後的配置寫回yaml文件
with open(data_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
# --- 3. 循環訓練每個模型 ---
for model_info in models_to_train:
model_name = model_info['name']
train_name = model_info['train_name']
print(f"\n{'='*60}")
print(f"開始訓練模型: {model_name}")
print(f"訓練名稱: {train_name}")
print(f"{'='*60}")
# 構建預訓練模型的完整路徑
pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)
if not os.path.exists(pretrained_model_path):
print(f"警告: 預訓練模型文件不存在: {pretrained_model_path}")
print(f"跳過模型 {model_name} 的訓練")
continue
try:
# 加載指定的預訓練模型
model = YOLO(pretrained_model_path)
# --- 4. 開始訓練 ---
print(f"開始訓練 {model_name}...")
# 調用train方法開始訓練
model.train(
data=data_yaml_path, # 數據集配置文件
epochs=100, # 訓練輪次
imgsz=640, # 輸入圖像尺寸
batch=8, # 每批次的圖像數量
name=train_name, # 模型名稱
)
print(f"{model_name} 訓練完成!")
except Exception as e:
print(f"訓練 {model_name} 時出現錯誤: {str(e)}")
print(f"跳過模型 {model_name},繼續訓練下一個模型")
continue
print(f"\n{'='*60}")
print("所有模型訓練完成!")
print(f"{'='*60}")
if __name__ == "__main__":
# 當該腳本被直接執行時,調用main函數
main()4. 技術棧
-
語言:Python 3.10
-
前端界面:bootstrap
- 後端:django
-
數據庫:SQLite(存儲用户信息)
-
模型:YOLOv5、YOLOv8、YOLOv11、YOLOv12
5. YOLO模型對比與識別效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型對比
基於Ultralytics官方COCO數據集訓練結果:
|
模型 |
尺寸(像素) |
mAPval 50-95 |
速度(CPU ONNX/毫秒) |
參數(M) |
FLOPs(B) |
|---|---|---|---|---|---|
|
YOLO12n |
640 |
40.6 |
- |
2.6 |
6.5 |
|
YOLO11n |
640 |
39.5 |
56.1 ± 0.8 |
2.6 |
6.5 |
|
YOLOv8n |
640 |
37.3 |
80.4 |
3.2 |
8.7 |
|
YOLOv5nu |
640 |
34.3 |
73.6 |
2.6 |
7.7 |
關鍵結論:
-
精度最高:YOLO12n(mAP 40.6%),顯著領先其他模型(較YOLOv5nu高約6.3個百分點);
-
速度最優:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,適合實時輕量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu參數量均為2.6M,FLOPs較低(YOLO12n/11n僅6.5B);YOLOv8n參數量(3.2M)與計算量(8.7B)最高,但精度優勢不明顯。
綜合推薦:
-
追求高精度:優先選YOLO12n(精度與效率兼顧);
-
需高速低耗:選YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣勢,無特殊需求時不建議首選。
5.2 數據集分析
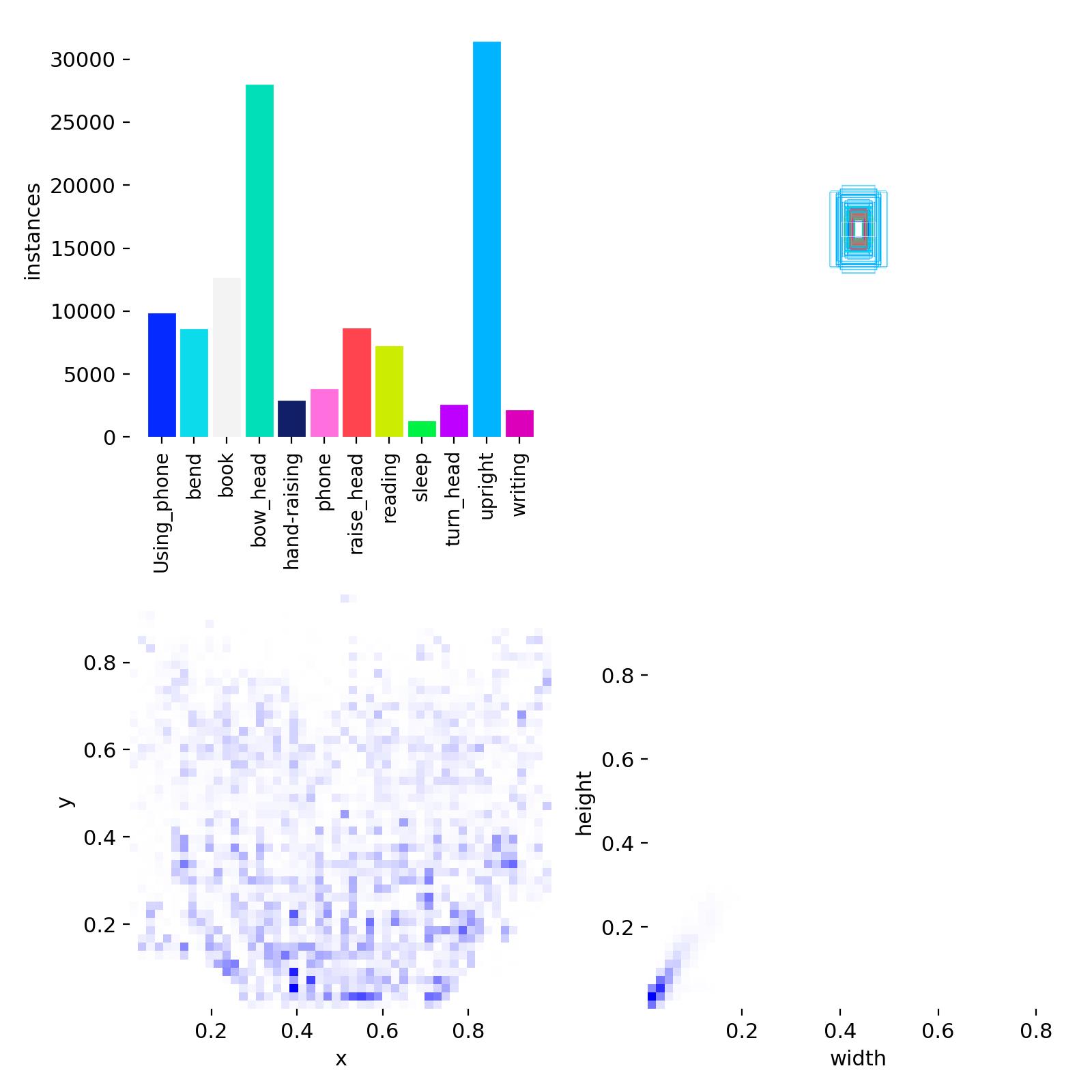
數據集中訓練集和驗證集一共3700+張圖片,數據集目標類別12種,數據集配置代碼如下:



上面的圖片就是部分樣本集訓練中經過數據增強後的效果標註。
5.3 訓練結果
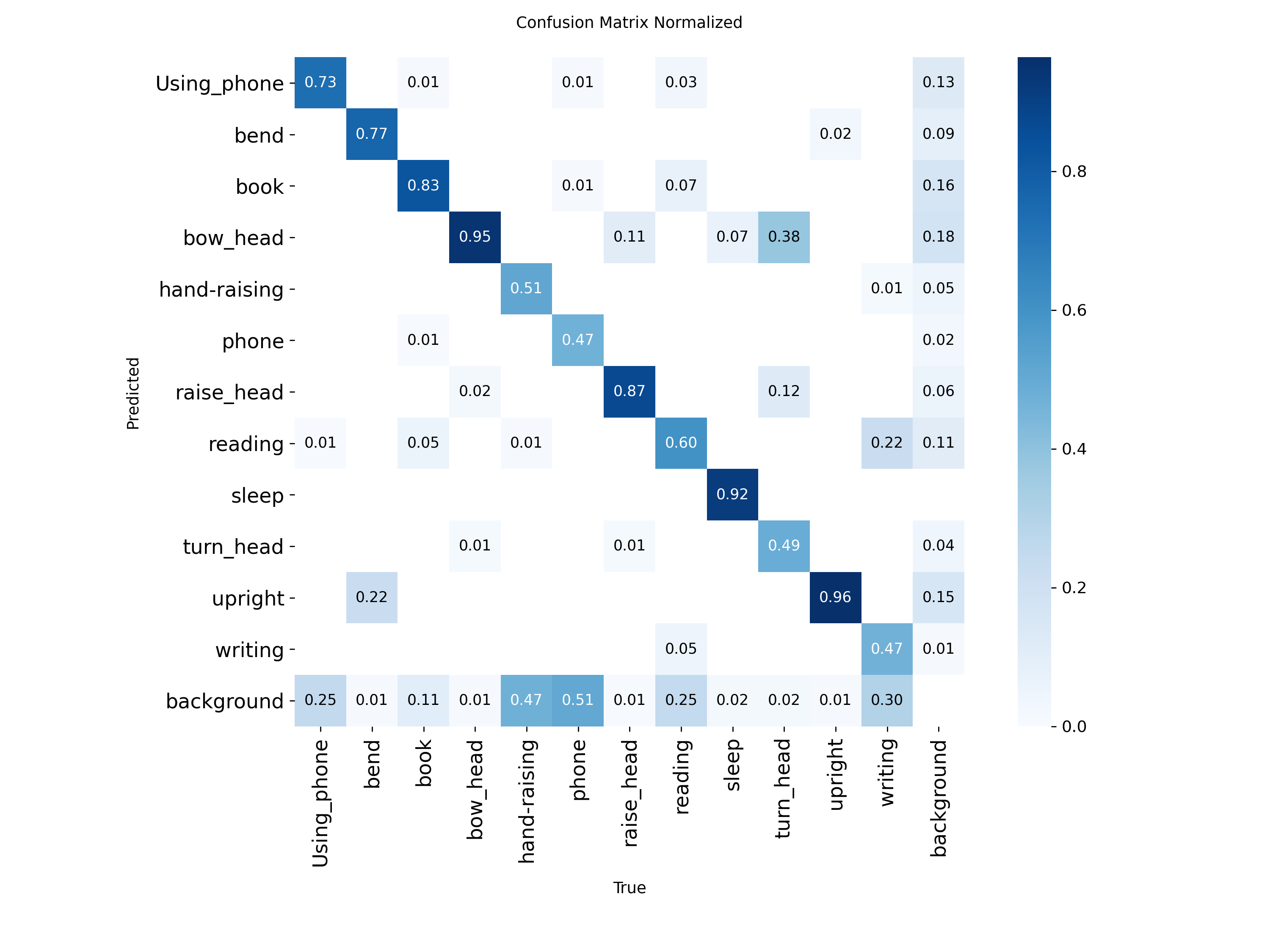
混淆矩陣顯示中識別精準度顯示是一條對角線,方塊顏色越深代表對應的類別識別的精準度越高。
F1指數(F1 Score)是統計學和機器學習中用於評估分類模型性能的核心指標,綜合了模型的精確率(Precision)和召回率(Recall),通過調和平均數平衡兩者的表現。
當置信度為0.353時,所有類別的綜合F1值達到了1.0(藍色曲線)。
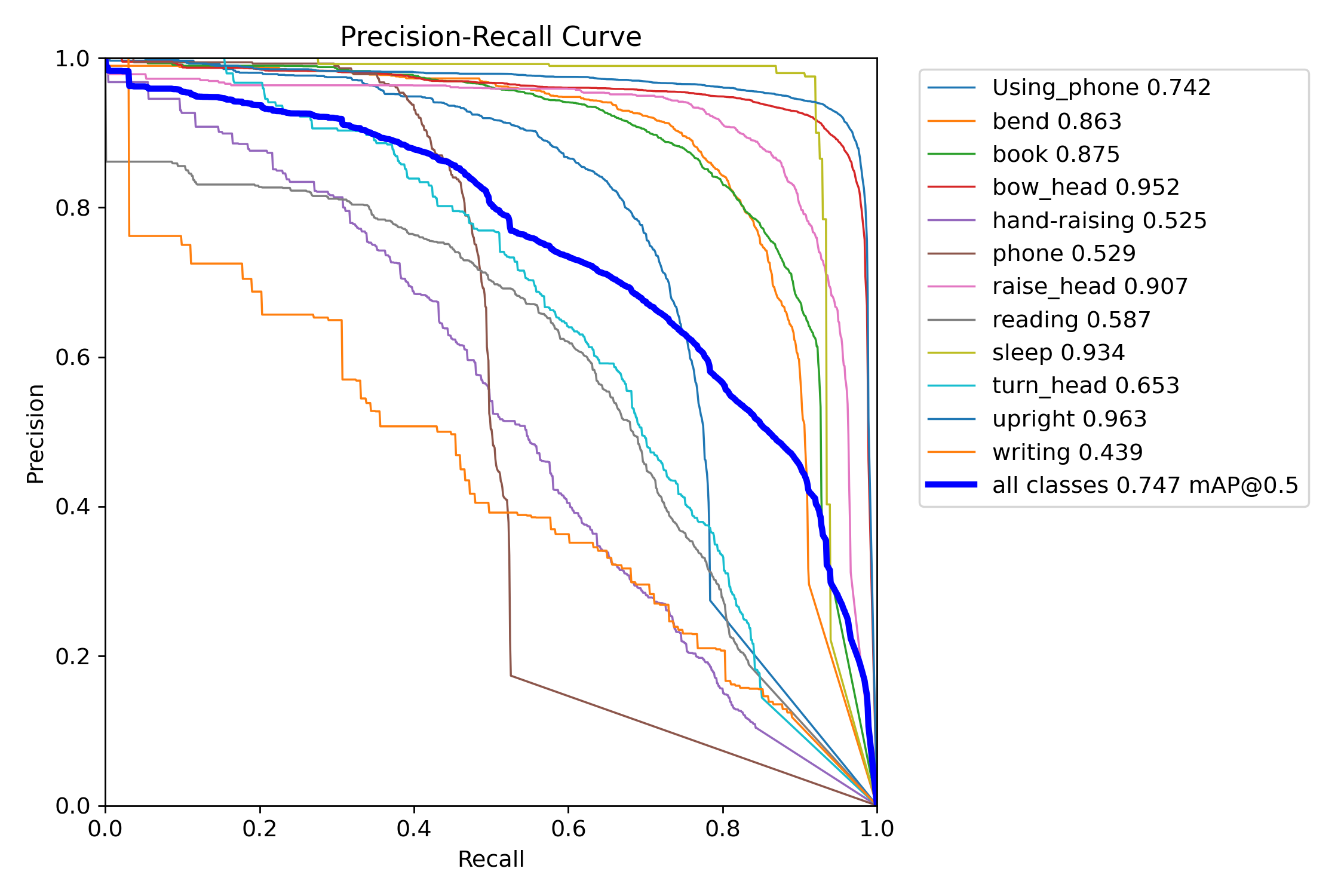
mAP@0.5:是目標檢測任務中常用的評估指標,表示在交併比(IoU)閾值為0.5時計算的平均精度均值(mAP)。其核心含義是:只有當預測框與真實框的重疊面積(IoU)≥50%時,才認為檢測結果正確。
圖中可以看到綜合mAP@0.5達到了0.747(74.7%)。
6. 源碼獲取方式
源碼獲取方式:https://www.bilibili.com/video/BV1ZAkTBQEUx/