

本文節選自《計算機是怎樣跑起來的(第2版)》第 3 章“體驗彙編語言”的草稿。在翻譯本章時,我們發現原書所使用的軟件僅提供日文界面,並且介紹的是主要用於日本計算機相關考試的 CASLⅡ 彙編語言,其通用性相對較低。為了讓內容更廣泛適用,並便於讀者實踐操作,與作者及編輯老師商議後,決定採用更為通用的NASM 彙編語言重新編寫本章,以提升學習體驗。

通過前面的學習(用匯編語言編寫計算兩整數之和的程序(上)),我們知道,雖然同屬於低級語言,但彙編語言的程序需要先轉換成機器語言的程序才能由 CPU 解釋執行。那“計算 1+2”這段代碼對應着怎樣的機器語言的代碼呢?
查看彙編語言對應的機器語言
在彙編語言的開發調試工具 SASM 中,可以通過 GDB 命令來查看彙編語言對應的機器語言的代碼。
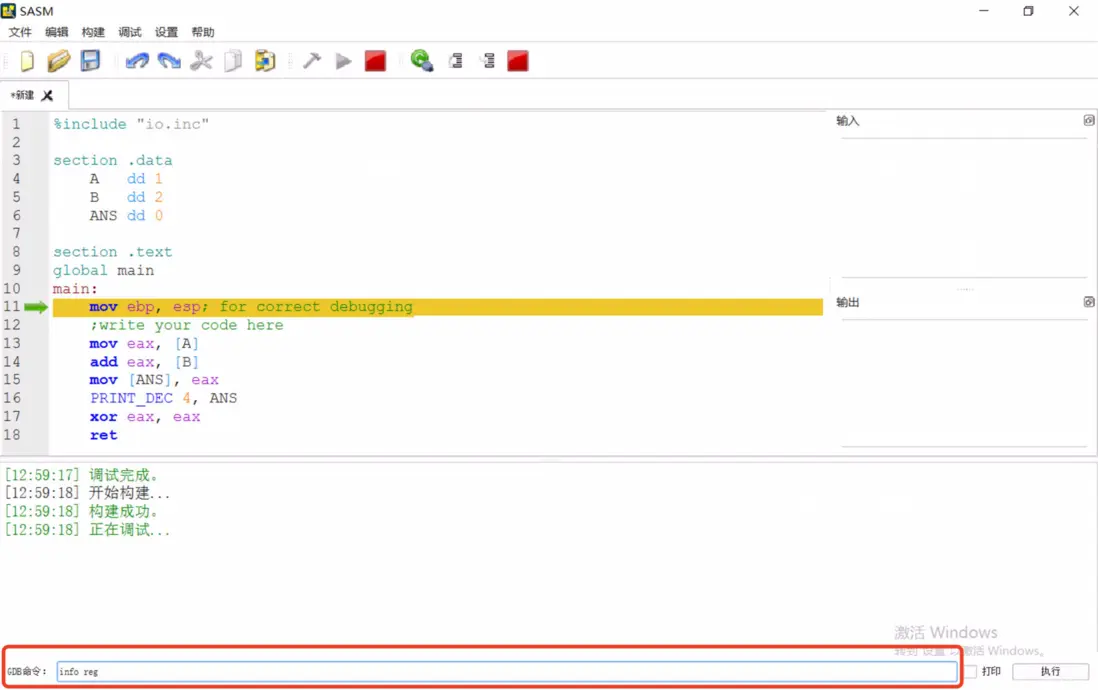
點擊工具欄中的“調試”按鈕(圖標是右下角有一隻藍色甲蟲的綠色三角形)就會進入調試模式。此時,SASM 窗口底部的窗格中會出現一行綠色的文字“正在調試...”。同時,最底部還會出現一個名為“GDB 命令:”的輸入框。
另外,進入調試模式後,SASM 會插入一行代碼 mov ebp, esp。這行代碼後面的註釋 ;for correct debugging(為了正確的調試)説明這行代碼僅用於輔助調試,並不會影響程序的運行,可以忽略,如下圖所示。
我們依次輸入如下兩條 GDB 命令:
set disassembly-flavor inteldisassemble /r
按下回車鍵後,就會看到在底部的窗格中輸出了大量信息:
> set disassembly-flavor intel
> disassemble /r
Dump of assembler code for function main:
=> 0x00401390 <+0>: 89 e5 mov ebp,esp
0x00401392 <+2>: a1 00 20 40 00 mov eax,ds:0x402000
0x00401397 <+7>: 03 05 04 20 40 00 add eax,DWORD PTR ds:0x402004
0x0040139d <+13>: a3 08 20 40 00 mov ds:0x402008,eax
0x004013a2 <+18>: e8 02 00 00 00 call 0x4013a9 <main+25>
(略)輸出信息中中間部分的十六進制數就是機器語言的代碼,例如,第一行中間部分的 89 e5 就是 mov ebp,esp 對應的機器語言的代碼。那麼,mov 指令對應的十六進制數就是 89 嗎?為什麼這條 mov 指令明明有兩個操作數,應該對應兩個十六進制數才對,卻只對應了一個 e5?這些問題只能通過查詢 CPU 的指令手冊才能得知。
mov ebp,esp 對應的機器語言的代碼
我們打開X86 Opcode and Instruction Reference(http://ref.x86asm.net/coder32.html),然後搜索 mov。

可以看到,同一條 mov 指令,卻對應了 88~8C 等多個十六進制數(這樣的十六進制數稱為Primary Opcode)。那 mov ebp, esp 中的 mov 到底對應哪個十六進制數呢?這就取決於操作數的類型了。操作數 ebp 和 esp 都是 32 位的寄存器,匹配 r/m16/32 r16/32 這個模式(第 1 個操作數是寄存器或 16/32 位的內存地址,第 2 個操作數是 16/32 位寄存器),所以這一行代碼中的 mov 應該對應 89。【TODO 為什麼不是 8B?】
那 e5 又是如何對應 ebp, esp 這兩個寄存器的呢?這就又涉及到稱為 ModR/M byte(https://en.wikipedia.org/wiki/ModR/M)的指令編碼方式了。
+-------+---+---+---+---+---+---+---+---+
| Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
+-------+---+---+---+---+---+---+---+---+
| Usage | MOD | REG | R/M |
+-------+---+---+---+---+---+---+---+---+
| e5 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
+-------+---+---+---+---+---+---+---+---+0xe5 = 1110 0101,如圖所示,從左往右數,前兩位的二進制數 11 是 MOD,MOD = 11 表示該指令的兩個操作數都是寄存器。之後的連續三位二進制數 100 對應寄存器 esp,最後的三位二進制數 101 對應寄存器 ebp(參考http://ref.x86asm.net/coder32.html#modrm_byte_32)。這樣一來,一個十六進制數就可以對應兩個操作數了。
mov eax, [A]對應的機器語言代碼
我們再來看下一行彙編語言的代碼 mov eax, [A] 對應的機器語言的十六進制數
a1 00 20 40 00 mov eax,ds:0x402000繼續在 X86 Opcode and Instruction Reference(http://ref.x86asm.net/coder32.html)中搜索 a1,可以看到
A1 MOV eAX moffs16/32mov 指令(這次對應a1)的兩個操作數分別是 eax 寄存器和 16/32 位的內存地址的偏移量(offset)。結合後面的 ds:0x402000 來看,00 20 40 00 就是內存地址偏移量(採用小端序),這裏的 ds 是數據段 data segment 的縮寫。另外,這個內存地址就是標籤 A 對應的內存地址,可以通過 GDB 命令 p &A 驗證這一點。
add eax, [B]對應的機器語言代碼
最後再來看一下 add 指令對應的機器語言代碼。
03 05 04 20 40 00 add eax,DWORD PTR ds:0x402004繼續查詢上述手冊可知:
03 ADD r16/32 r/m16/32add 指令對應 03,後續的 05 又是ModR/M byte,表示該指令的第一個操作數是寄存器 eax(REG=000),第二個操作數是內存地址(R/M=101)。
+-------+---+---+---+---+---+---+---+---+
| Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
+-------+---+---+---+---+---+---+---+---+
| Usage | MOD | REG | R/M |
+-------+---+---+---+---+---+---+---+---+
| 05 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
+-------+---+---+---+---+---+---+---+---+05 之後的四個字節 04 20 40 00 是標籤 B 對應的內存地址。
現在諸位應該能深切地感受到為什麼要發明彙編語言了吧,因為使用機器語言編程時不得不記憶毫無規律的數字,實在是太不方便了。
上一篇文章的結尾處提出了一個問題:
在高級語言中,計算兩整數之和可以只用兩個變量a += b,但在彙編語言中,為什麼不能寫成add [A], [B]呢?
其實答案很簡單,因為沒有兩個操作數都是內存地址這樣的進行加法運算的指令。彙編語言的指令和機器語言的指令是一一對應的,如果某種機器語言的指令不存在,自然也就沒有與之對應的彙編語言的指令了。或者説,如果找不到對應的機器語言的指令,這樣的彙編語言的指令就是無效的。
在下一篇文章中,我們再來看一看如何查看寄存器和內存存儲單元中的數據,以及如何進行逐行調試。
