

簡介: 目前有贊實時計算平台對於 Flink 任務資源優化探索已經走出第一步。
隨着 Flink K8s 化以及實時集羣遷移完成,有贊越來越多的 Flink 實時任務運行在 K8s 集羣上,Flink K8s 化提升了實時集羣在大促時彈性擴縮容能力,更好的降低大促期間機器擴縮容的成本。同時,由於 K8s 在公司內部有專門的團隊進行維護, Flink K8s 化也能夠更好的減低公司的運維成本。
不過當前 Flink K8s 任務資源是用户在實時平台端進行配置,用户本身對於實時任務具體配置多少資源經驗較少,所以存在用户資源配置較多,但實際使用不到的情形。比如一個 Flink 任務實際上 4 個併發能夠滿足業務處理需求,結果用户配置了 16 個併發,這種情況會導致實時計算資源的浪費,從而對於實時集羣資源水位以及底層機器成本,都有一定影響。基於這樣的背景,本文從 Flink 任務內存以及消息能力處理方面,對 Flink 任務資源優化進行探索與實踐。
一、Flink 計算資源類型與優化思路
1.1 Flink 計算資源類型
一個 Flink 任務的運行,所需要的資源我認為能夠分為 5 類:
- 內存資源
- 本地磁盤(或雲盤)存儲
- 依賴的外部存儲資源。比如 HDFS、S3 等(任務狀態/數據),HBase、MySQL、Redis 等(數據)
- CPU 資源
- 網卡資源
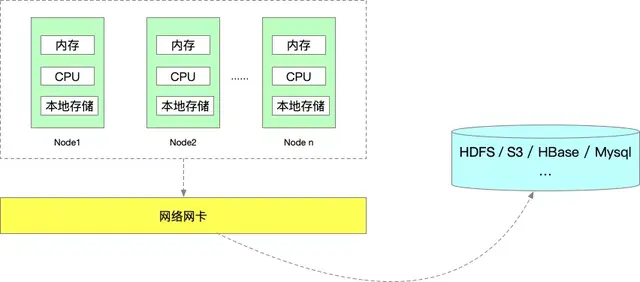
目前 Flink 任務使用最主要的還是內存和 CPU 資源,本地磁盤、依賴的外部存儲資源以及網卡資源一般都不會是瓶頸,所以本文我們是從 Flink 任務的內存和 CPU 資源,兩個方面來對 Flink 實時任務資源進行優化。
1.2 Flink 實時任務資源優化思路
對於 Flink 實時任務資源分析思路,我們認為主要包含兩點:
- 一是從任務內存視角,從堆內存方面對實時任務進行分析。
- 另一方面則是從實時任務消息處理能力入手,保證滿足業務方數據處理需求的同時,儘可能合理使用 CPU 資源。
之後再結合實時任務內存分析所得相關指標、實時任務併發度的合理性,得出一個實時任務資源預設值,在和業務方充分溝通後,調整實時任務資源,最終達到實時任務資源配置合理化的目的,從而更好的降低機器使用成本。
■ 1.2.1 任務內存視角
那麼如何分析 Flink 任務的堆內存呢?這裏我們是結合 Flink 任務 GC 日誌來進行分析。GC 日誌包含了每次 GC 堆內不同區域內存的變化和使用情況。同時根據 GC 日誌,也能夠獲取到一個 Taskmanager 每次 Full GC 後,老年代剩餘空間大小。可以説,獲取實時任務的 GC 日誌,使我們進行實時任務內存分析的前提。
GC 日誌內容分析,這裏我們藉助開源的 GC Viewer 工具來進行具體分析,每次分析完,我們能夠獲取到 GC 相關指標,下面是通過 GC Viewer 分析一次 GC 日誌的部分結果:
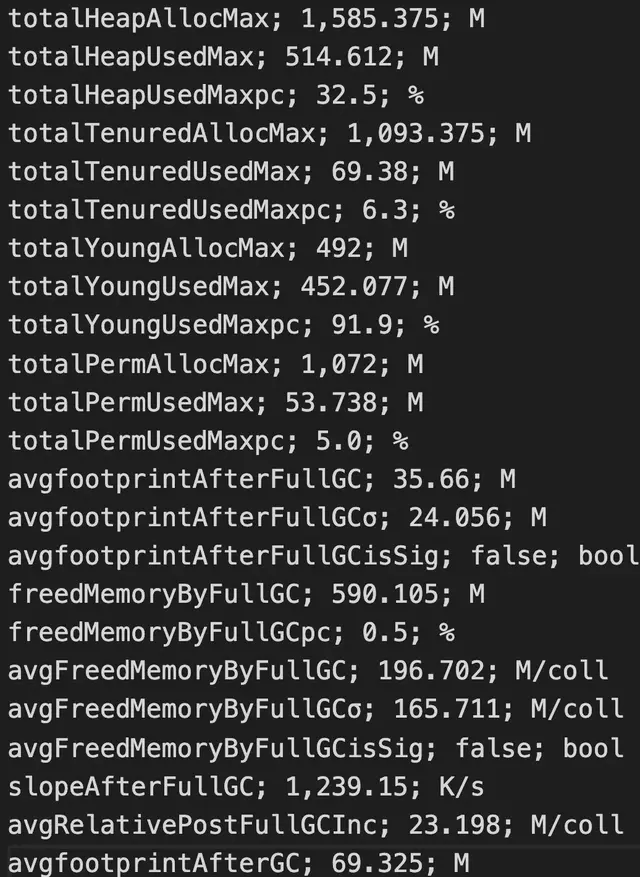
上面通過 GC 日誌分析出單個 Flink Taskmanager 堆總大小、年輕代、老年代分配的內存空間、Full GC 後老年代剩餘大小等,當然還有很多其他指標,相關指標定義可以去 Github 具體查看。
這裏最重要的還是Full GC 後老年代剩餘大小這個指標,按照《Java 性能優化權威指南》這本書 Java 堆大小計算法則,設 Full GC 後老年代剩餘大小空間為 M,那麼堆的大小建議 3 ~ 4倍 M,新生代為 1 ~ 1.5 倍 M,老年代應為 2 ~ 3 倍 M,當然,真實對內存配置,你可以按照實際情況,將相應比例再調大些,用以防止流量暴漲情形。
所以通過 Flink 任務的 GC 日誌,我們可以計算出實時任務推薦的堆內存總大小,當發現推薦的堆內存和實際實時任務的堆內存大小相差過大時,我們就認為能夠去降低業務方實時任務的內存配置,從而降低機器內存資源的使用。
■ 1.2.2 任務消息處理能力視角
對於 Flink 任務消息處理能力分析,我們主要是看實時任務消費的數據源單位時間的輸入,和實時任務各個 Operator / Task 消息處理能力是否匹配。Operator 是 Flink 任務的一個算子,Task 則是一個或者多個算子 Chain 起來後,一起執行的物理載體。
數據源我們內部一般使用 Kafka,Kafka Topic 的單位時間輸入可以通過調用 Kafka Broker JMX 指標接口進行獲取,當然你也可以調用 Flink Rest Monitoring 相關 API 獲取實時任務所有 Kafka Source Task 單位時間輸入,然後相加即可。不過由於反壓可能會對 Source 端的輸入有影響,這裏我們是直接使用 Kafka Broker 指標 JMX 接口獲取 Kafka Topic 單位時間輸入。
在獲取到實時任務 Kafka Topic 單位時間輸入後,下面就是判斷實時任務的消息處理能力是否與數據源輸入匹配。一個實時任務整體的消息處理能力,會受到處理最慢的 Operator / Task 的影響。打個比方,Flink 任務消費的 Kafka Topic 輸入為 20000 Record / S,但是有一個 Map 算子,其併發度為 10 ,Map 算子中業務方調用了 Dubbo,一個 Dubbo 接口從請求到返回為 10 ms,那麼 Map 算子處理能力 1000 Record / S (1000 ms / 10 ms * 10 ),從而實時任務處理能力會下降為 1000 Record / S。
由於一條消息記錄的處理會在一個 Task 內部流轉,所以我們試圖找出一個實時任務中,處理最慢的 Task 邏輯。如果 Source 端到 Sink 端全部 Chain 起來的話,我們則是會找出處理最慢的 Operator 的邏輯。在源碼層,我們針對 Flink Task 以及 Operator 增加了單條記錄處理時間的自定義 Metric,之後該 Metric 可以通過 Flink Rest API 獲取。我們會遍歷一個 Flink 任務中所有的 Task , 查詢處理最慢的 Task 所在的 JobVertex(JobGraph 的點),然後獲取到該 JobVertex 所有 Task 的總輸出,最終會和 Kafka Topic 單位時間輸入進行比對,判斷實時任務消息處理能力是否合理。
設實時任務 Kafka Topic 單位時間的輸入為 S,處理最慢的 Task 代表的 JobVertex 的併發度為 P,處理最慢的 Task 所在的 JobVertex 單位時間輸出為 O,處理最慢的 Task 的最大消息處理時間為 T,那麼通過下面邏輯進行分析:
- 當 O 約等於 S,且 1 second / T * P 遠大於 S 時,會考慮減小任務併發度。
- 當 O 約等於 S,且 1 second / T * P 約等於 S 時,不考慮調整任務併發度。
- 當 O 遠小於 S,且 1 second / T * P 遠小於 S 時,會考慮增加任務併發度。
目前主要是 1 這種情況在 CPU 使用方面不合理,當然,由於不同時間段,實時任務的流量不同,所以我們會有一個週期性檢測的的任務,如果檢測到某個實時任務連續多次都符合 1 這種情況時,會自動報警提示平台管理員進行資源優化調整。
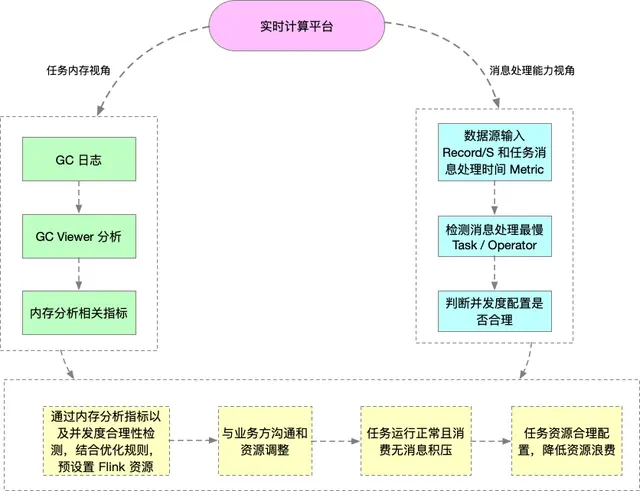
下圖是從 Flink 任務的內存以及消息處理能力兩個視角分析資源邏輯圖:
二、從內存視角對 Flink 分析實踐
2.1 Flink 任務垃圾回收器選擇
Flink 任務本質還是一個 Java 任務,所以也就會涉及到垃圾回收器的選擇。選擇垃圾回收器一般需要從兩個角度進行參考:
- 吞吐量,即單位時間內,任務執行時間 / (任務執行時間 + 垃圾回收時間),當然並不是説降低 GC 停頓時間就能提升吞吐量,因為降低 GC 停頓時間,你的 GC 次數也會上升。
- 延遲。如果你的 Java 程序涉及到與外部交互,延遲會影響外部的請求使用體驗。
Flink 任務我認為還是偏重吞吐量的一類 Java 任務,所以會從吞吐量角度進行更多的考量。當然並不是説完全不考慮延遲,畢竟 JobManager、TaskManager、ResourceManager 之間存在心跳,延遲過大,可能會有心跳超時的可能性。
目前我們 JDK 版本為內部 JDK 1.8 版本,新生代垃圾回收器使用 Parallel Scavenge,那麼老年代垃圾回收器只能從 Serial Old 或者 Parallel Old 中選擇。由於我們 Flink k8s 任務每個 Pod 的 CPU 限制為 0.6 - 1 core ,最大也只能使用 1 個 core,所以老年代的垃圾回收器我們使用的是 Serial Old ,多線程垃圾回收在單 Core 之間,可能會有線程切換的消耗。
2.2 實時任務 GC 日誌獲取
設置完垃圾回收器後,下一步就是獲取 Flink 任務的 GC 日誌。Flink 任務構成一般是單個 JobManager + 多個 TaskManger ,這裏需要獲取到 TaskManager 的 GC 日誌進行分析。那是不是要對所有 TaskManager 進行獲取呢。這裏我們按照 TaskManager 的 Young GC 次數,按照次數大小進行排序,取排名前 16 的 TaskManager 進行分析。YoungGC 次數可以通過 Flink Rest API 進行獲取。
Flink on Yarn 實時任務的 GC 日誌,直接點開 TaskManager 的日誌鏈接就能夠看到,然後通過 HTTP 訪問,就能下載到本地。Flink On k8s 任務的 GC 日誌,會先寫到 Pod 所掛載的雲盤,基於 k8s hostpath volume 進行掛載。我們內部使用 Filebeat 進行日誌文件變更監聽和採集,最終輸出到下游的 Kafka Topic。我們內部會有自定義日誌服務端,它會消費 Kafka 的日誌記錄,自動進行落盤和管理,同時向外提供日誌下載接口。通過日誌下載的接口,便能夠下載到需要分析的 TaskManager 的 GC 日誌。
2.3 基於 GC Viewer 分析 Flink 任務內存
GC Viewer 是一個開源的 GC 日誌分析工具。使用 GC Viewer 之前,需要先把 GC Viewer 項目代碼 clone 到本地,然後進行編譯打包,就可以使用其功能。
在對一個實時任務堆內存進行分析時,先把 Flink TaskManager 的日誌下載到本地,然後通過 GC Viewer 對日誌進行。如果你覺得多個 Taskmanager GC 日誌分析較慢時,可以使用多線程。上面所有這些操作,可以將其代碼化,自動化產出分析結果。下面是通過 GC Viewer 分析的命令行:
java -jar gcviewer-1.37-SNAPSHOT.jar gc.log summary.csv
上面參數 gc.log 表示一個 Taskmanager 的 GC 日誌文件名稱,summary.csv 表示日誌分析的結果。下面是我們平台對於某個實時任務內存分析的結果:
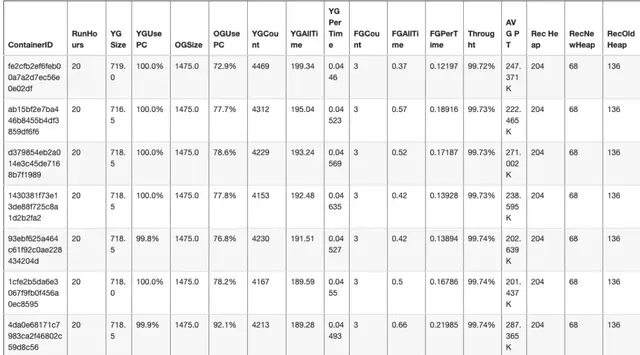
下面是上面截圖中,部分參數説明:
- RunHours,Flink 任務運行小時數
- YGSize,一個 TaskManager 新生代堆內存最大分配量,單位兆
- YGUsePC,一個 TaskManager 新生代堆最大使用率
- OGSize,一個 TaskManager 老年代堆內存最大分配量,單位兆
- OGUsePC,一個 TaskManager 老生代堆最大使用率
- YGCoun,一個 TaskMnager Young GC 次數
- YGPerTime,一個 TaskMnager Young GC 每次停頓時間,單位秒
- FGCount,一個 TaskMnager Full GC 次數
- FGAllTime,一個 TaskMnager Full GC 總時間,單位秒
- Throught,Task Manager 吞吐量
- AVG PT(分析結果 avgPromotion 參數),平均每次 Young GC 晉升到老年代的對象大小
- Rec Heap,推薦的堆大小
- RecNewHeap,推薦的新生代堆大小
- RecOldHeap,推薦的老年代堆大小
上述大部分內存分析結果,通過 GC Viewer 分析都能得到,不過推薦堆大小、推薦新生代堆大小、推薦老年代堆大小則是根據 1.2.1 小節的內存優化規則來設置。
三、從消息處理視角對 Flink 分析實踐
3.1 實時任務 Kafka Topic 單位時間輸入獲取
想要對 Flink 任務的消息處理能力進行分析,第一步便是獲取該實時任務的 Kafka 數據源 Topic,目前如果數據源不是 Kafka 的話,我們不會進行分析。Flink 任務總體分為兩類:Flink Jar 任務和 Flink SQL 任務。Flink SQL 任務獲取 Kafka 數據源比較簡單,直接解析 Flink SQL 代碼,然後獲取到 With 後面的參數,在過濾掉 Sink 表之後,如果 SQLCreateTable 的 Conector 類型為 Kafka,就能夠通過 SQLCreateTable with 後的參數,拿到具體 Kafka Topic。
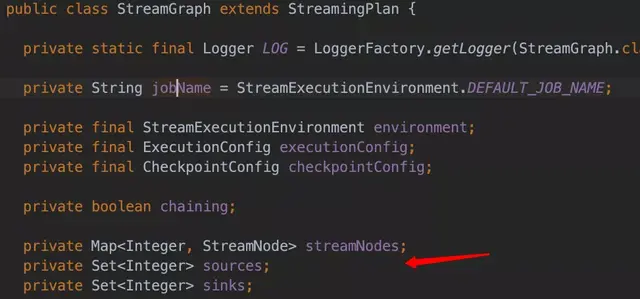
Flink Jar 任務的 Kafka Topic 數據源獲取相對繁瑣一些,我們內部有一個實時任務血緣解析服務,通過對 Flink Jar 任務自動構建其 PackagedProgram,PackagedProgram 是 Flink 內部的一個類,然後通過 PackagedProgram ,我們可以獲取一個 Flink Jar 任務的 StreamGraph,StreamGraph 裏面有 Source 和 Sink 的所有 StreamNode,通過反射,我們可以獲取 StreamNode 裏面具體的 Source Function,如果是 Kafka Source Sunction,我們就會獲取其 Kafka Topic。下面是 StreamGraph 類截圖:
獲取到 Flink 任務的 Kafka Topic 數據源之後,下一步便是獲取該 Topic 單位時間輸入的消息記錄數,這裏可以通過 Kafka Broker JMX Metric 接口獲取,我們則是通過內部 Kafka 管理平台提供的外部接口進行獲取。
3.2 自動化檢測 Flink 消息處理最慢 Task
首先,我們在源碼層增加了 Flink Task 單條記錄處理時間的 Metric,這個 Metric 可以通過 Flink Rest API 獲取。接下來就是藉助 Flink Rest API,遍歷要分析的 Flink 任務的所有的 Task。Flink Rest Api 有這樣一個接口:
base_flink_web_ui_url/jobs/:jobid這個接口能夠獲取一個任務的所有 Vertexs,一個 Vertex 可以簡單理解為 Flink 任務 JobGraph 裏面的一個 JobVertex。JobVertex 代表着實時任務中一段執行邏輯。
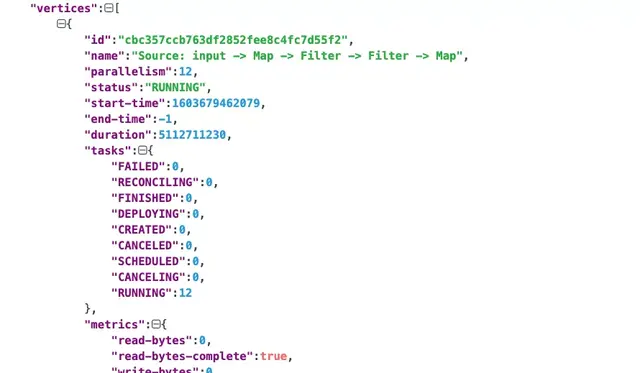
獲取完 Flink 任務所有的 Vertex 之後,接下來就是獲取每個 Vertex 具體 Task 處理單條記錄的 metric,可以使用下面的接口:

需要在上述 Rest API 鏈接 metrics 之後添加 ?get=(具體meitric ),比如:metrics?get=0.Filter.numRecordsOut,0 表示該 Vertex Task 的 id,Filter.numRecordsOut 則表示具體的指標名稱。我們內部使用 taskOneRecordDealTime 表示Task 處理單條記錄時間 Metric,然後用 0.taskOneRecordDealTime 去獲取某個 Task 的單條記錄處理時間的指標。上面接口支持多個指標查詢,即 get 後面使用逗號隔開即可。
最終自動化檢測 Flink 消息處理最慢 Task 整體步驟如下:
- 獲取一個實時任務所有的 Vertexs
- 遍歷每個 Vertex,然後獲取這個 Vertex 所有併發度 Task 的 taskOneRecordDealTime,並且記錄其最大值
- 所有 Vertex 單條記錄處理 Metric 最大值進行對比,找出處理時間最慢的 Vertex。
下面是我們實時平台對於一個 Flink 實時任務分析的結果:

四、有贊 Flink 實時任務資源優化實踐
既然 Flink 任務的內存以及消息處理能力分析的方式已經有了,那接下來就是在實時平台端進行具體實踐。我們實時平台每天會定時掃描所有正在運行的 Flink 任務,在任務內存方面,我們能夠結合 實時任務 GC 日誌,同時根據內存優化規則,計算出 Flink 任務推薦的堆內存大小,並與實際分配的 Flink 任務的堆內存進行比較,如果兩者相差的倍數過大時,我們認為 Flink 任務的內存配置存在浪費的情況,接下來我們會報警提示到平台管理員進行優化。
平台管理員再收到報警提示後,同時也會判定實時任務消息能力是否合理,如果消息處理最慢的 Vertex (某段實時邏輯),其所有 Task 單位時間處理消息記錄數的總和約等於實時任務消費的 Kafka Topic 單位時間的輸入,但通過 Vertex 的併發度,以及單條消息處理 Metric ,算出該 Vertex 單位時間處理的消息記錄數遠大於 Kafka Topic 的單位輸入時,則認為 Flink 任務可以適當調小併發度。具體調整多少,會和業務方溝通之後,在進行調整。整體 Flink 任務資源優化操作流程如下:
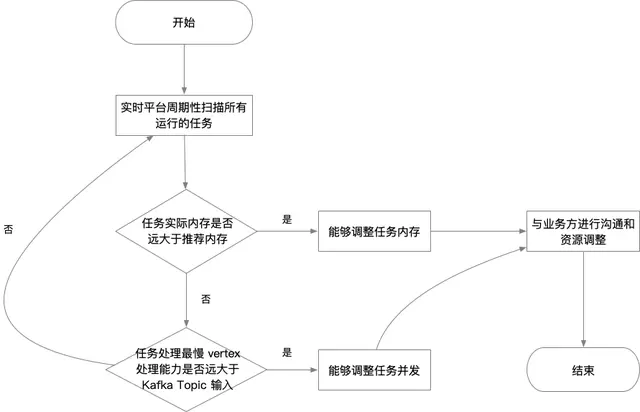
五、總結
目前有贊實時計算平台對於 Flink 任務資源優化探索已經走出第一步。通過自動化發現能夠優化的實時任務,然後平台管理員介入分析,最終判斷是否能夠調整 Flink 任務的資源。在整個實時任務資源優化的鏈路中,目前還是不夠自動化,因為在後半段還需要人為因素。未來我們計劃 Flink 任務資源的優化全部自動化,會結合實時任務歷史不同時段的資源使用情況,自動化推測和調整實時任務的資源配置,從而達到提升整個實時集羣資源利用率的目的。
同時未來也會和元數據平台的同學進行合作,一起從更多方面來分析實時任務是否存在資源優化的可能性,他們在原來離線任務資源方面積攢了很多優化經驗,未來也可以參考和借鑑,應用到實時任務資源的優化中。
當然,最理想化就是實時任務的資源使用能夠自己自動彈性擴縮容,之前聽到過社區同學有這方面的聲音,同時也歡迎你能夠和我一起探討。
作者:沈磊
原文鏈接
本文為阿里雲原創內容,未經允許不得轉載
