

簡介: 本文由 Bigo 計算平台負責人徐帥分享,主要介紹 Bigo 實時計算平台建設實踐的介紹
本文由 Bigo 計算平台負責人徐帥分享,主要介紹 Bigo 實時計算平台建設實踐的介紹。內容包括:
- Bigo 實時計算平台的發展歷程
- 特色與改進
- 業務場景
- 效率提升
- 總結展望
一、Bigo 實時計算平台的發展歷程
今天主要跟大家分享 Bigo 實時計算平台的建設歷程,我們在建設過程中解決的一些問題,以及所做的一些優化和改進。首先進入第一個部分,Bigo 實時計算平台的發展歷程。
先簡單介紹一下 Bigo 的業務。它主要有三大 APP,分別是 Live, Likee 和 Imo。其中,Live 為全球用户提供直播服務。Likee 是短視頻的創作與分享的 App,跟快手和抖音都非常相似。Imo 是一個全球免費的通訊工具。這幾個主要的產品都是跟用户相關的,所以我們的業務要圍繞着如何提高用户的轉化率和留存率。而實時計算平台作為基礎的平台,主要是為以上業務服務的,Bigo 平台的建設也要圍繞上述業務場景做一些端到端的解決方案。

Bigo 實時計算的發展歷程大概分為三個階段。
- 在 2018 年之前,實時作業還非常少,我們使用 Spark Streaming 來做一些實時的業務場景。
- 從 18 年到 19 年,隨着 Flink 的興起,大家普遍認為 Flink 是最好的實時計算引擎,我們開始使用 Flink,離散發展。各個業務線自己搭一個 Flink 來簡單使用。
- 從 2019 年開始,我們把所有使用 Flink 的業務統一到 Bigo 實時計算平台上。通過兩年的建設,目前所有實時計算的場景都運行在 Bigo 平台上。

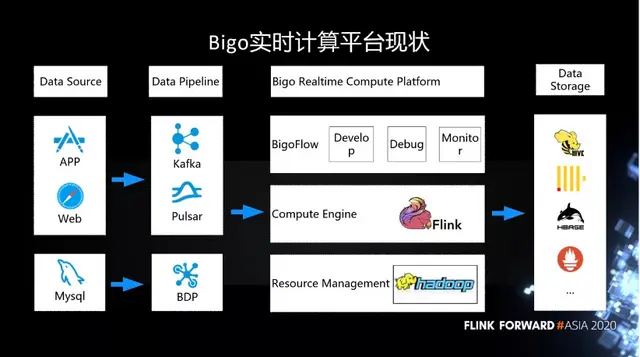
如下圖所示,這是 Bigo 實時計算平台的現狀。在 Data Source 端,我們的數據都是用户的行為日誌,主要來自於 APP 和客户端。還有一部分用户的信息存在 MySQL 中。
這些信息都會經過消息隊列,最終採集到我們的平台裏。消息隊列主要用的是 Kafka,現在也在逐漸的採用 Pulsar。而 MySQL 的日誌主要是通過 BDP 進入實時計算平台。在實時計算平台這塊,底層也是基於比較常用的 Hadoop 生態圈來做動態資源的管理。在上面的引擎層,已經統一到 Flink,我們在上面做一些自己的開發與優化。在這種一站式的開發、運維與監控的平台上,我們內部做了一個 BigoFlow 的管理平台。用户可以在 BigoFlow 上開發、調試和監控。最終在數據存儲上,我們也是對接了 Hive、ClickHouse、HBase 等等。
二、Bigo 實時計算平台的特色與改進
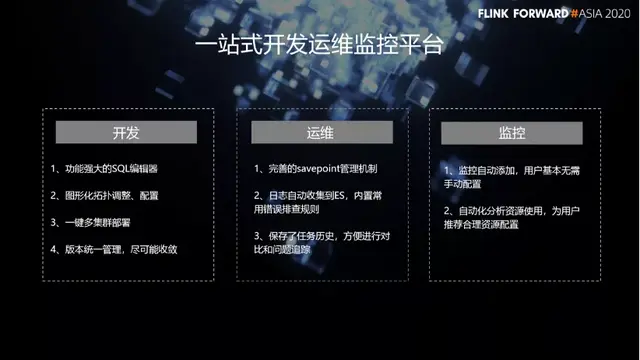
接下來我們看一下 Bigo 計算平台的特色,以及我們做的改進。作為一個發展中的公司,我們平台建設的重點還是儘可能的讓業務人員易於使用。從而促進業務的發展,擴大規模。我們希望建設一個一站式的開發、運維、監控平台。
首先,在 BigoFlow 上面,用户可以非常方便的開發。我們在開發這一塊的特色與改進包括:
- 功能強大的 SQL 編輯器。
- 圖形化拓撲調整、配置。
- 一鍵多集羣部署。
- 版本統一管理,儘可能收斂。
另外,在運維這一塊,我們也做了許多改進:
- 完善的 savepoint 管理機制。
- 日誌自動收集到 ES,內置常 用錯誤排查規則。
- 保存了任務歷史,方便進行對比和問題追蹤。
最後是監控這一塊,我們的特色有:
- 監控自動添加,用户基本無需手動配置。
- 自動化分析資源使用,為用户推薦合理資源配置。
我們元數據的存儲主要有三個地方。分別是 Kafka、Hive 和 ClickHouse。目前我們能夠把所有的存儲系統的元數據全面打通。這會極大的方便用户,同時降低使用成本。
- Kafka 的元數據打通之後,就可以一次導入,無限使用,無需 DDL。
- Flink 與 Hive 也做到了完全打通,用户在使用 Hive 表的時候,無需 DDL,直接使用即可。
- ClickHouse 也類似,可自動追蹤到 Kafka 的 topic。

其實,我們今天提供的不僅僅是一個平台,還包括在通用場景提供了端到端的解決方案。在 ETL 場景,我們的解決方案包括:
- 通用打點完全自動化接入。
- 用户無需開發任何代碼。
- 數據進入 hive。
- 自動更新 meta。
在監控這一塊,我們的特色有:
- 數據源自動切換。
- 監控規則不變。
- 結果自動存入 prometheus。
第三個場景是 ABTest 場景,傳統的 ABTest 都是通過離線的方式,隔一天之後才能產出結果。那麼我們今天將 ABTest 轉為實時的方式去輸出,通過流批一體的方式大大提高了 ABTest 的效率。

對 Flink 的改進主要體現在這幾個方面:
- 第一,在 connector 層面,我們自定義了很多的 connector,對接了公司用到的所有系統。
- 第二,在數據格式化層面,我們對 Json,Protobuf,Baina 三種格式做了非常完整的支持。用户無需自己做解析,直接使用就可以。
- 第三,公司所有的數據都直接落到 Hive 裏面,在 Hive 的使用上是領先於社區的。包括流式的讀取,EventTime 支持,維表分區過濾,Parquet 複雜類型支持,等等。
- 第四,在 State 層面我們也做了一些優化。包括 SSD 支持,以及 RocksDB 優化。

三、Bigo 典型的業務場景
傳統的打點入庫,都是通過 Kafka 到 Flume,然後進入到 Hive,最後到 ClickHouse。當然 ClickHouse 裏面大部分是從 Hive 導進去的,還有一部分是通過 Kafka 直接寫進去的。
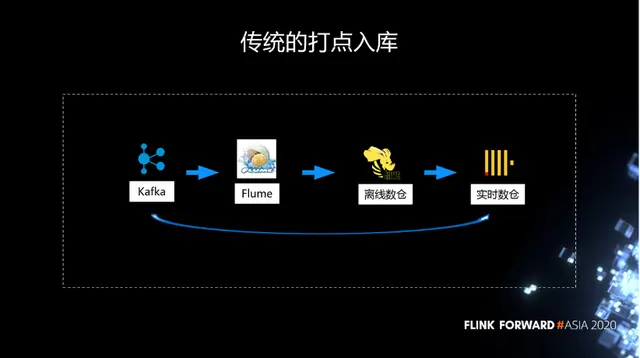
這個鏈路是一個非常老的鏈路,它存在以下問題:
- 第一,不穩定,flume 一旦有異常,經常會出現數據丟失和重複。
- 第二,擴展能力差。面對突然到來的流量高峯,很難去擴展。
- 第三,業務邏輯不易調整。

所以我們在建設 Flink 之後,做了非常多的工作。把原先 Flume 到 Hive 的流程替換掉,今天所有的 ETL 都是通過 Kafka,再經過 Flink,所有的打點都會進入到 Hive 離線數倉,作為歷史的保存,使數據不丟失。同時,因為很多作業需要實時的分析,我們在另外一個鏈路,從 Flink 直接進入 ClickHouse 實時數倉來分析。
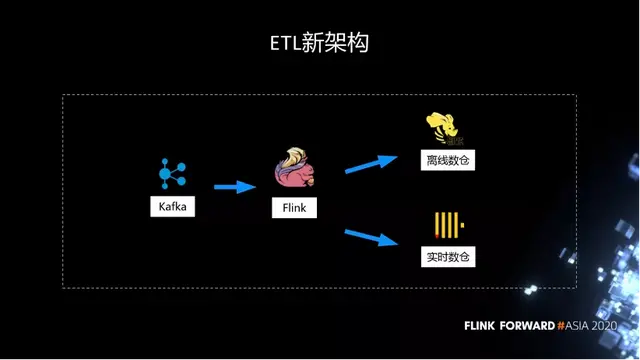
在這個過程中,我們做了一些核心改造,分為三大塊。首先,在用户接入這一塊,我們的改造包括:
- 儘可能簡單。
- 通用打點全自動。
- 元信息打通,無需 DDL。
另外,在 Flink 自身這一塊,我們的改造有:
- Parquet 寫優化。
- 併發度調整。
- 通過 SSD 盤,支持大狀態的作業。
- RocksDB 優化,更好控制內存。
最後,在數據 Sink 這一塊,我們做了非常多的定製化的開發,不僅支持 Hive,也對接了 ClickHouse。

四、Flink 為業務帶來的效率提升
下面主要介紹 ABTest 場景下,我們做的一些改造。比如説,數據全部落到 Hive 之後,就開始啓動離線的計算,可能經過無數個工作流之後,最終產出了一張大寬表。表上可能有很多個維度,記錄了分組實驗的結果。數據分析師拿到結果之後,去分析哪些實驗比較好。
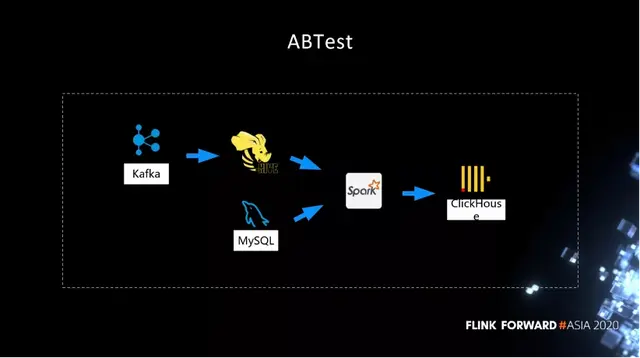
雖然這個結構很簡單,但是流程太長,出結果晚,並且不易增加維度。主要問題其實在 Spark 這塊,這個作業有無數個工作流去執行,一個工作流要等到另外一個執行完才能去調度。而且離線資源沒有非常好的保證。我們之前最大的問題是 ABTest 上一天的結果要等到下一天的下午才能輸出,數據分析師經常反饋上午沒法幹活,只能下午快下班的時候才能開始分析。

所以我們就開始利用 Flink 實時計算能力去解決時效性的問題。不同於 Spark 任務要等上一個結果才能輸出,Flink 直接從 Kafka 消費。基本上可以在上午出結果。但是當時因為它最終產出的結果維度非常多,可能有幾百個維度,這個時候 State 就非常大,經常會遇到 OOM。
因此我們在第一步的改造過程中取了一個折中,沒有直接利用 Flink 在一個作業裏面把所有的維度 join 起來,而是把它拆分成了幾個作業。每個作業計算一部分維度,然後把這些結果先利用 HBase 做了一個 join,再把 join 的結果導入到 ClickHouse 裏面。
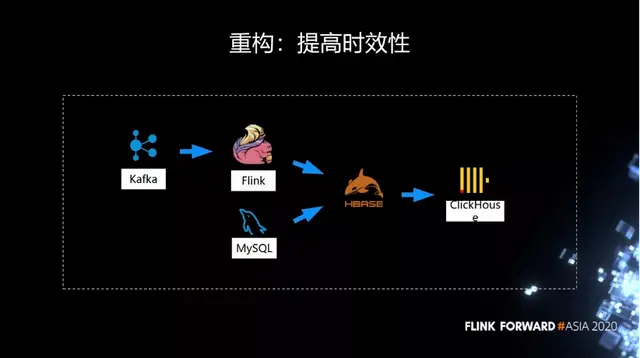
在改造的過程中,我們發現了一個問題。可能作業需要經常的調整邏輯,調完後要去看結果對不對,那麼這需要 1 天的時間窗口。如果直接讀歷史數據,Kafka 就要保存很久的數據,讀歷史數據的時候,要到磁盤上去讀,對 Kafka 的壓力就非常大。如果不讀歷史數據,因為只有零點才能觸發,那麼今天改了邏輯,要等到一天之後才能夠去看結果,會導致調試迭代非常慢。

前面提到我們的所有數據在 Hive 裏面,當時還是 1.9 的版本,我們就支持了從 Hive 裏面流式的去讀取數據。因為這些數據都是用 EventTime 去觸發,我們在 Hive 上支持了用 EventTime 去觸發。為了流批統一,這裏沒有用 Spark,因為如果用 Spark 去做作業驗證,需要維護兩套邏輯。
我們在 Flink 上面用流批一體的方式去做離線的補數據,或者離線的作業驗證。而實時的這條用於日常作業的產生。
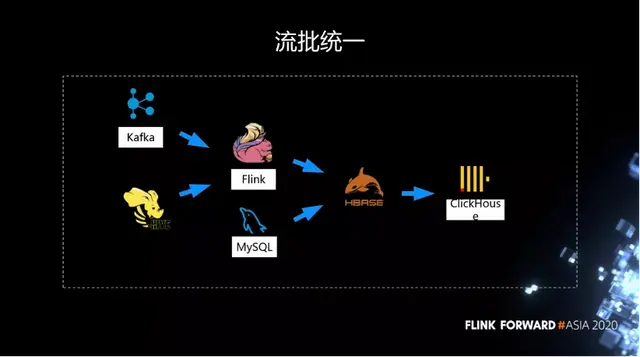
剛才説了這其實是一個折中的方案,因為對 HBase 有依賴,也沒有充分發揮 Flink 的能力。所以我們進行了第二輪的改造,徹底去除對 HBase 的依賴。
經過第二輪迭代之後,我們今天在 Flink 上已經能夠扛住大表的天級別的窗口交易。這個流批統一的方案已經上線了,我們直接通過 Flink 去計算完整個大寬表,在每天的窗口觸發之後,將結果直接寫到 ClickHouse 裏面,基本上凌晨就可以產出結果。
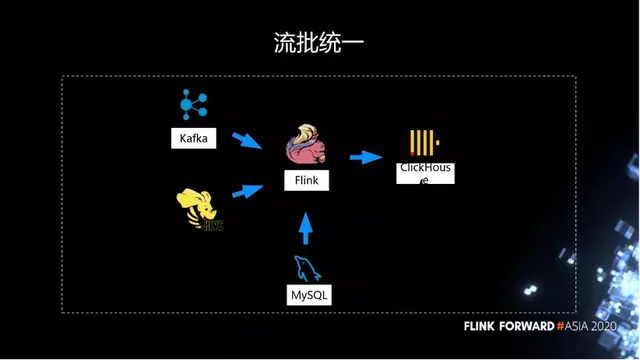
在整個過程中間,我們對 Flink 的優化包括:
- State 支持 SSD 盤。
- 流式讀取 Hive,支持 EventTime。
- Hive 維表 join,支持 partition 分區 load。
- 完善的 ClickHouse Sinker。
優化之後,我們的小時級任務再也不延遲了,天級別完成時間由下午提早到上班前,大大加速了迭代效率。

五、總結與展望
總結一下實時計算在 Bigo 的現狀。首先,非常貼近業務。其次,跟公司裏用到的所有生態無縫對接,基本上讓用户不需要做任何的開發。另外,實時數倉已現雛形。最後,我們的場景跟大廠相比還不夠豐富。一些比較典型的實時場景,由於業務需求沒有那麼高,很多業務還沒有真正的切換到實時場景上來。

我們的發展規劃有兩大塊。
- 第一塊是拓展更多的業務場景。包括實時機器學習,廣告,風控和實時報表。在這些領域,要更多的去推廣實時計算的概念,去跟業務對接好。
- 另外一塊就是在 Flink 自身上面,我們內部有很多場景要做。比如説,支持大 Hive 維表 join,自動化資源配置,CGroup 隔離,等等。以上就是我們在未來要做的一些工作。

作者:徐帥
原文鏈接
本文為阿里雲原創內容,未經允許不得轉載

