

簡介: 阿里雲AHAS Chaos:應用及業務高可用提升工具平台之故障演練
應用高可用服務AHAS及故障演練AHAS Chaos
應用高可用服務(Application High Availability Service)是阿里雲一款專注於提高應用及業務高可用的工具平台,目前主要提供應用架構探測感知、故障注入式高可用能力評測和流控降級高可用防護三大核心能力,通過各自的工具模塊可以快速低成本地在營銷活動場景、業務核心場景全面提升業務穩定性和韌性。
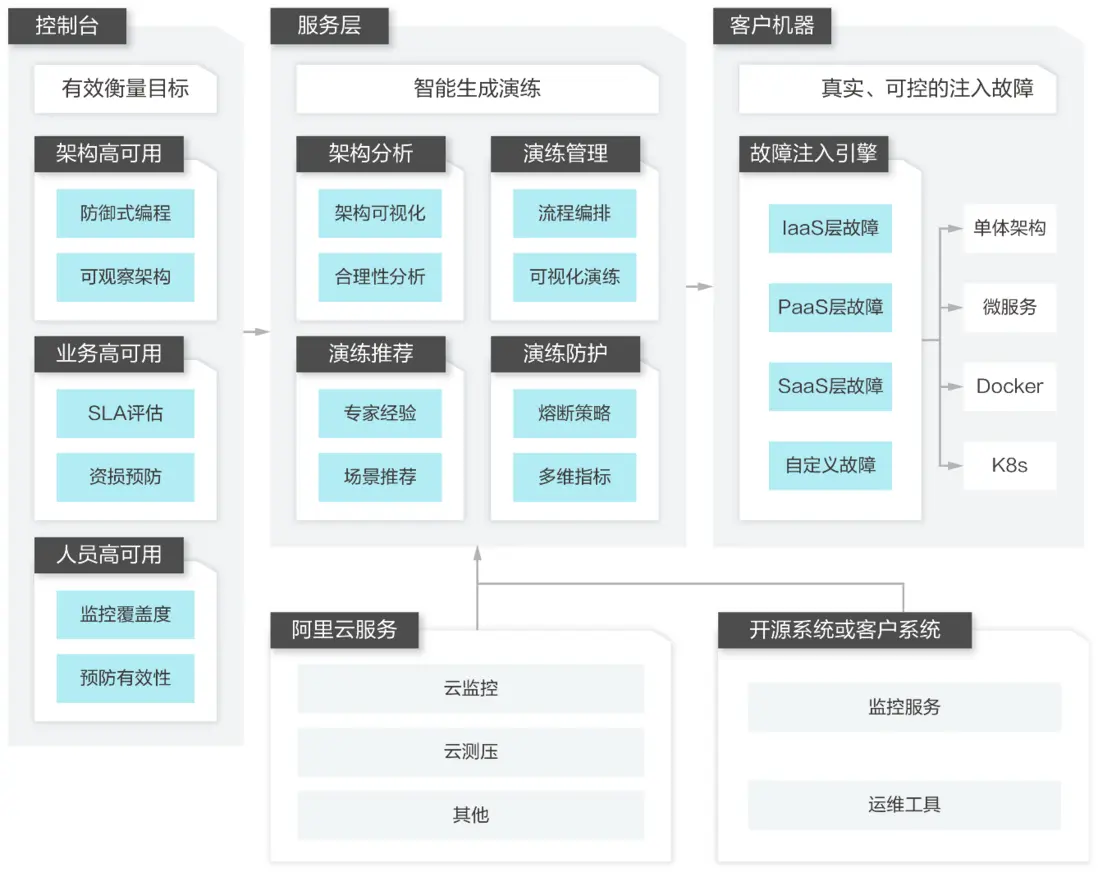
圖1:AHAS服務體系
故障演練AHAS Chaos是一款遵循混沌工程實驗原理並融合了阿里巴巴內部實踐的產品,提供豐富的故障場景實現,能夠幫助分佈式系統提升容錯性和可恢復性。故障演練建立了一套標準的演練流程,包含準備階段、執行階段、檢查階段和恢復階段。通過四階段的流程,覆蓋用户從計劃到還原的完整演練過程,並通過可視化的方式清晰地呈現給用户。
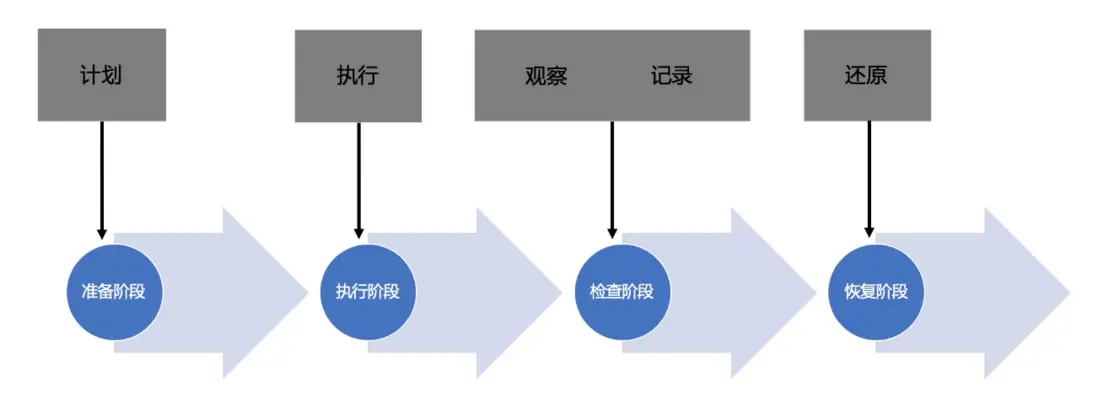
圖2:故障演練流程
AHAS Chaos的適用場景
衡量微服務的容錯能力
通過模擬調用延遲、服務不可用、機器資源滿載等,查看發生故障的節點或實例是否被自動隔離、下線,流量調度是否正確,預案是否有效,同時觀察系統整體的QPS或RT是否受影響。在此基礎上可以緩慢增加故障節點範圍,驗證上游服務限流降級、熔斷等是否有效。最終故障節點增加到請求服務超時,估算系統容錯紅線,衡量系統容錯能力。
驗證容器編排配置是否合理
通過模擬殺服務Pod、殺節點、增大Pod資源負載,觀察系統服務可用性,驗證副本配置、資源限制配置以及Pod下部署的容器是否合理。
測試PaaS層是否健壯
通過模擬上層資源負載,驗證調度系統的有效性;模擬依賴的分佈式存儲不可用,驗證系統的容錯能力;模擬調度節點不可用,測試調度任務是否自動遷移到可用節點;模擬主備節點故障,測試主備切換是否正常。
驗證監控告警的時效性
通過對系統注入故障,驗證監控指標是否準確,監控維度是否完善,告警閾值是否合理,告警是否快速,告警接收人是否正確,通知渠道是否可用等,提升監控告警的準確性和時效性。
定位與解決問題的應急能力
通過故障突襲,隨機對系統注入故障,考察相關人員對問題的應急能力,以及問題上報、處理流程是否合理,達到以戰養戰,鍛鍊人定位與解決問題的能力。
AHAS Chaos的功能優勢
靈活的流程編排
AHAS Chaos將故障演練的環節分為了準備、注入、檢查以及恢復四個階段,每個階段除了系統初始化完成的必要節點之外,用户也可以根據需要添加自己的流程節點。
AHAS Chaos支持一次演練定義包含多個故障場景,同時用户可以定製這些場景的運行方式,選擇依次進行故障注入或同時注入多個場景,通過不同的策略配置來達到不同的故障注入效果。
豐富的故障場景
豐富的故障場景也是AHAS Chaos的一大特色,包括以下場景:
- 常見的基礎設施資源例如CPU、內存、磁盤等。
- 應用級別的故障注入,目前支持Java應用,後續將陸續推出對於NodeJs和C++的應用故障注入。
- 雲原生領域的演練場景。
無論用户是需要設置集羣級別的大規模故障還是應用級別的請求級別細粒度故障,都可以在AHAS Chaos找到適合的場景,下圖是AHAS Chaos提供的部分故障場景。
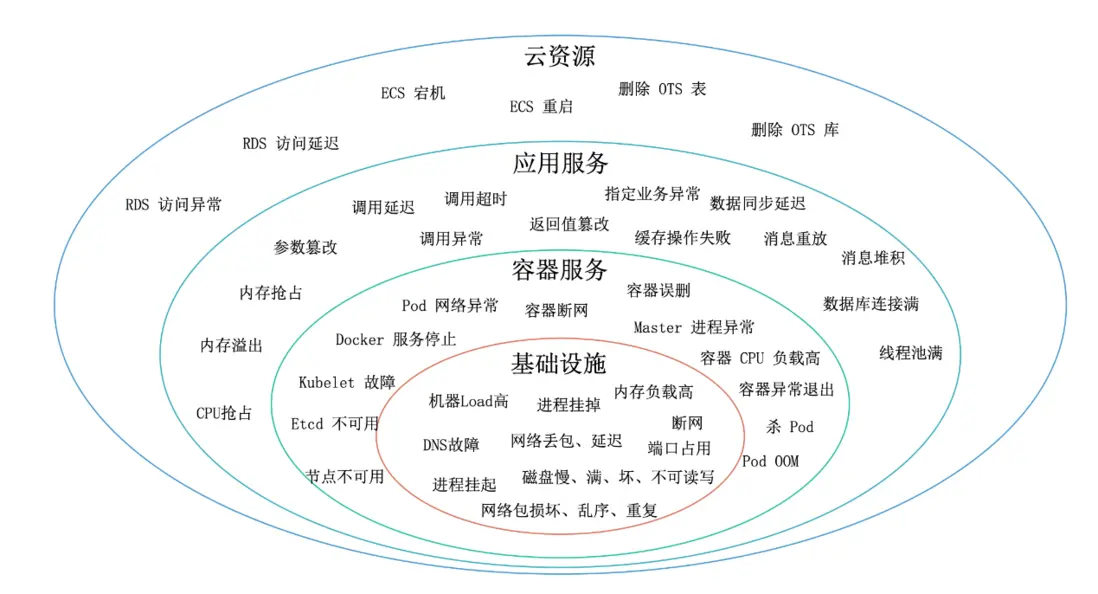
圖3:AHAS Chaos提供的部分故障場景
多樣的專家經驗
AHAS Chaos將阿里內部多年的故障演練經驗濃縮成了專家經驗,專家經驗具有以下優點:
- 專家經驗都來自於阿里內部經常演練的場景,保證了演練場景的真實性以及實用性。
- 專家經驗不但包括了可執行的演練流程,還描述了專家經驗試圖解決的問題以及針對的系統架構弱點。
- 專家經驗極大地提升了演練創建的效率,用户可以基於專家經驗配置好的流程一鍵生成自己的演練。
安全的演練防護
在保護用户的演練安全性上AHAS Chaos也做了非常多的防護措施:
- 在演練的任意一個環節,用户都可以隨時終止演練,每一個終止操作都會自動恢復注入的場景。
- 用户可以一鍵終止所有正在運行當中的演練。
- 用户可以配置演練的自動恢復時間,防止因演練時間過長而忘記恢復演練引發不必要的問題。
- 用户可以通過全局恢復功能來配置自動恢復的策略,當某個指標符合某個要求時自動恢復演練。
深度集成的阿里雲產品
AHAS Chaos和阿里雲的許多產品如ARMS、SLS、EDAS、OTS以及架構感知服務等做了深度集成,通過授權用户可以實現以下功能:
- 對依賴的阿里雲組件進行故障注入。
- 基於接入的阿里雲監控系統數據如ARMS來豐富演練檢查和恢復的手段。
- 通過RAM服務來授權不同賬號的演練權限,提升演練的安全性。
演練實踐
網絡不穩定對業務系統的影響
經驗描述:通過注入多種網絡故障,來檢測網絡不穩定對系統造成的影響,以及系統的應對情況。
背景:網絡環境不好,可能會對業務造成比較大的影響,特別是系統依賴較多的外部服務,比如緩存Redis、消息中間件等,因此需要通過網絡層面的故障注入來考察系統的超時處理能力。
架構弱點:1.對第三方系統的調用超時設置不合理;2.缺乏對依賴超時時候的重試能力;3.缺乏對依賴超時問題的兜底策略,比如異常處理、功能降級等措施。
評測:1.系統設置了合理的超時時間,不會因為依賴系統的網絡不穩定導致請求超時;2.針對第三方調用超時或者失敗的情況,系統配置了監控,並且具備一定的重試能力。
java應用發生oom異常
經驗描述:1.通過填滿jvm的內存空間,來觸發fullgc和oom異常,使得應用的響應時間變長,甚至無響應,來觀察業務的處理效率以及監控的發現情況;2.oom存在一定風險無法自動恢復,需要重啓應用。
背景:新生代是jvm內部一塊重要的內存區域,由於新建對象過多等因素導致該區域內存被佔用到一定額度,會觸發MiniGc操作進行回收,但是如果新建的對象一直被引用,那麼會導致MiniGc無法回收,進而上升到老年代,如果老年代也被佔用滿,那麼就會觸發fullgc,頻繁的gc操作會導致應用的cpu以及請求響應都變得很高,對業務應用造成比較大的影響。
架構弱點:1.監控缺失,當應用發生fullgc之後,無法及時定位問題,特別是現在很多的jvm監控系統都採用了metric的規範,通過應用提供的http接口來獲取監控數據,一旦應用無響應,那麼會導致監控數據無法及時獲取,進而不能觸發報警;2.不能及時下線問題機器,由於頻繁的gc,應用已經無法響應業務請求,因此需要及時下線掉問題機器。
評測:1.當應用發生了fullgc,問題機器迅速被隔離掉,不再接受業務請求。2.當應用發生了fullgc,監控系統可以迅速報警並且定位問題。
總結
故障演練AHAS Chaos作為AHAS的一部分,在其中承擔了問題發現、問題驗證、高可用經驗沉澱的作用,並與AHAS其他功能組成了一套完善的高可用保障服務,可以幫助用户實現包括架構、業務、人員的全面高可用提升。
作者:SRE團隊技術小編-小蘭
原文鏈接
本文為阿里雲原創內容,未經允許不得轉載


