

標準 RAG 流水線有個根本性的毛病:檢索到的文檔一旦與用户意圖對不上號,模型照樣能面不改色地輸出一堆看似合理的胡話,既沒有反饋機制也談不上什麼糾錯能力。
而Agentic RAG 的思路截然不同,它不急着從檢索結果裏硬擠答案,而是先判斷一下拿回來的東西到底有沒有用,如果沒用則會重寫查詢再來一輪。這套機制實際上構建了一條具備自我修復能力的檢索鏈路,面對邊界情況也不至於直接崩掉。
本文要做的就是用 LangGraph 做流程編排、Redis 做向量存儲,搭一個生產可用的 Agentic RAG 系統。涉及整體架構設計、決策邏輯實現,以及狀態機的具體接線方式。
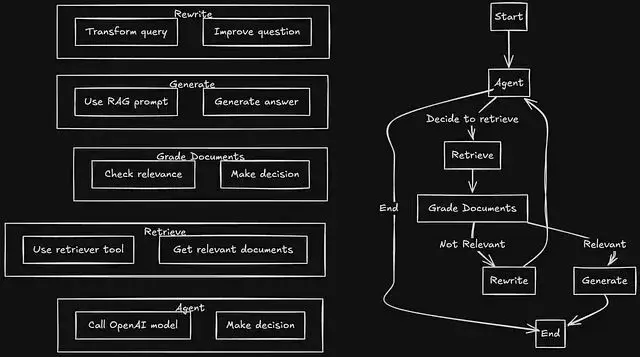
傳統 RAG 的"一錘子買賣"
假設知識庫裏有一篇《大語言模型的參數高效訓練方法》,用户問的是"怎麼微調 LLM 效果最好"。
語義相似度確實存在但不夠強。檢索器拉回來的可能是模型架構相關的內容雖然沾邊但答非所問,LLM 本身沒法意識到上下文是錯的,照樣能生成一段貌似專業實則離題萬里的回答。
傳統 RAG 對這種失敗模式完全沒有辦法。查詢文檔、生成答案,整個過程是單向的沒有任何質量把關環節。
Agentic RAG 的解法是在流程中插入檢查點:智能體先判斷要不要檢索;檢索完了有評分環節確認相關性;不相關就重寫查詢再試;如此循環直到拿到合格的上下文,或者把重試次數耗盡為止。
系統架構拆解
整個系統拆成六個模塊:
配置層負責環境變量和 API 客户端的初始化工作。Redis 連接串、OpenAI 密鑰、模型名稱全部歸攏到這裏統一管理。
檢索器模塊承擔文檔攝取的全套流程,文檔經過
WebBaseLoader加載後用
RecursiveCharacterTextSplitter切塊,再通過 OpenAI Embedding 向量化,最後存進
RedisVectorStore。檢索器本身會被包裝成 LangChain 工具供智能體調用。
智能體節點是決策入口。拿到用户問題後先做判斷:這個問題需要查資料還是直接能答?需要查就調檢索器,不需要就直出答案。
評分(Grade Edge)決定檢索結果的去向。相關性夠就往生成環節走;不夠就觸發重寫。這是整個系統裏最關鍵的質量關卡。
重寫節點把原始問題改寫成更適合檢索的形式,用户表述太口語化、缺少關鍵詞,這些問題都在這裏修正。
生成節點只有在評分環節確認上下文合格後才會執行,基於檢索到的文檔產出最終答案。
流程圖和代碼
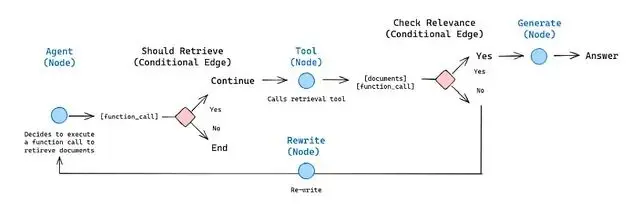
關鍵在於從"重寫"回到"智能體"這條反饋路徑。系統不會因為一次檢索失敗就直接給出一個牽強附會的答案,它會調整策略重新嘗試。
src/
├── config/
│ ├── settings.py # 環境變量
│ └── openai.py # 模型名稱和 API 客户端
├── retriever.py # 文檔攝取和 Redis 向量存儲
├── agents/
│ ├── nodes.py # 智能體、重寫和生成函數
│ ├── edges.py # 文檔評分邏輯
│ └── graph.py # LangGraph 狀態機
└── main.py # 入口點職責劃分很清晰:配置歸
config/,智能體相關的都在
agents/,向量存儲操作全在
retriever.py。這種結構調試起來方便,單測也好寫。
配置模塊設計
配置層解決兩個問題:環境變量加載和 API 客户端複用。
settings.py集中讀取 Redis 連接信息、OpenAI API Key、索引名稱,不用滿項目找配置。
openai.py負責實例化 Embedding 模型和 LLM 客户端。切換到別的模型、調整 Embedding 維度等等配置也只要一處
這個設計在生產環境裏很實用,因為模型會迭代、Key 會輪換、服務商可能換掉,集中管理意味着改動成本可控。
檢索器實現
檢索器負責整條數據攝取鏈路:抓文檔、切塊、向量化、入庫。
語料選的是 Lilian Weng 關於 Agent 和 Prompt Engineering 的博客文章。
WebBaseLoader負責抓取,
RecursiveCharacterTextSplitter切分成適當大小的塊,OpenAI Embedding 完成向量化。
向量存儲用
RedisVectorStore。檢索器通過
create_retriever_tool封裝成 LangChain 工具形態。這一步的意義在於讓智能體能夠"調用"檢索而不是被動觸發,意味着它有權決定什麼時候需要查資料、什麼時候直接回答。
為什麼用Redis?因為夠快,夠簡單。向量相似度搜索本身 Redis 就能做,不用額外引入專門的向量數據庫。對於已經跑着 Redis 的技術棧來説,加 RAG 能力幾乎零額外運維負擔。
智能體節點
nodes.py裏有三個核心函數。
智能體函數接收當前狀態(用户問題、歷史對話等),判斷下一步怎麼走。它能調用包括檢索器在內的工具集。問題需要外部知識就調檢索,不需要就直接生成回答。
重寫函數處理那些被評分環節打回來的查詢。它會讓 LLM 把原始問題改寫成檢索友好的形式,用詞更精準、關鍵信息更突出。改寫後的查詢再交回智能體重新發起檢索。
生成函數產出最終答案。輸入是原始問題加上已確認相關的文檔,輸出是基於這些上下文的回答。
三個函數都是無狀態的。狀態走圖,不走函數內部變量。這對測試和排查問題都有好處。
文檔評分邏輯
edges.py裏的
grade_documents是整個 Agentic 機制的核心。
檢索完成後它會逐個審視返回的文檔:這東西跟用户問的相關不相關?能不能幫上忙?
評分本身是通過一次 LLM 調用完成的,Prompt 設計成要求模型返回二元判斷——相關或者不相關。
判定相關就返回
"generate",流程走向答案生成;判定不相關則返回
"rewrite",觸發查詢改寫。
這個環節的價值在於攔截那些本會導致標準 RAG 胡説八道的情況,與其硬着頭皮從不靠譜的上下文裏編答案,不如給系統一次修正查詢的機會。
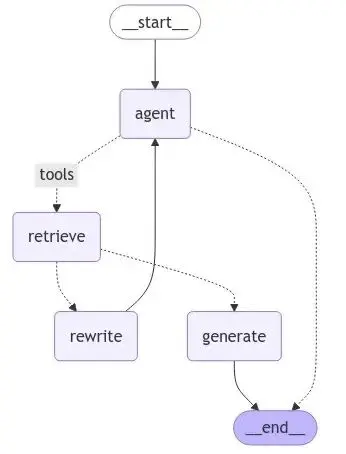
狀態機接線
graph.py用 LangGraph 的狀態機原語把所有節點串起來。
圖結構定義了節點(智能體、檢索、生成、重寫)和邊(節點間的連接關係,包括基於評分結果的條件路由)。
接線邏輯如下:查詢先到智能體節點,智能體決定調檢索器的話流程就到檢索節點,檢索完進評分,評分過了走生成,沒過走重寫,重寫完的查詢再回智能體重新來過。生成節點執行完流程結束。
LangGraph 接管狀態流轉的細節。每個節點只管接收當前狀態、返回狀態更新,具體消息怎麼路由由圖引擎根據邊的條件邏輯處理。
運行時流程
main.py是入口,做三件事:構建圖、接收問題、流式輸出結果。
build_graph()在啓動時執行一次,完成 LangGraph 狀態機的構建和檢索器工具的初始化.
問題進來之後的流轉過程:智能體接收問題決定調檢索 → Redis 返回文檔 → 評分環節判斷相關性 → 相關就生成答案,不相關就重寫查詢繼續循環。
腳本會把各節點的輸出實時打到控制枱,方便觀察決策過程——什麼時候觸發了檢索、評分結果如何、有沒有走到重寫環節,一目瞭然。
架構的優勢
自校正能力:檢索質量差能發現並修復,不會悶頭輸出一個基於垃圾上下文的錯誤答案然後假裝沒事發生。
決策透明:狀態機讓每個分支點都是顯式的。路由決策可以全量記錄,想排查為什麼系統選擇了重寫而不是直接生成,日誌裏全有。
模塊解耦:每個組件職責單一。想把 Redis 換成 Pinecone?改檢索模塊。想把 OpenAI 換成 Anthropic?改配置層。其他部分不受影響。
總結
標準 RAG 把檢索當黑盒,查詢丟進去、文檔出來,至於相不相關全憑運氣。Agentic RAG 打開這個黑盒在關鍵位置加了質量控制。
LangGraph 加 Redis 的組合提供了一個可以直接上生產的骨架。流程編排的複雜度 LangGraph 消化掉了,向量檢索的性能 Redis 兜住了,剩下的評分和重寫邏輯負責兜底那些簡單系統搞不定的邊角案例。
代碼:
https://avoid.overfit.cn/post/a45e19af576a4826a605807d8fcfe298
作者:Kushal Banda