

精心構造的輸入樣本能讓機器學習模型產生錯誤判斷,這些樣本與正常數據的差異微小到人眼無法察覺,卻能讓模型以極高置信度輸出錯誤預測。這類特殊構造的輸入在學術界被稱為對抗樣本(adversarial examples)。

模型將右側圖像判定為長臂猿,置信度高達99.3%。
人眼看不出這兩張熊貓圖像有任何區別,而模型對左圖的預測是熊貓,置信度57.7%顯得不太確定。中間那張看起來像噪聲的圖案其實是經過精心設計的擾動掩碼,將其乘以一個很小的係數0.007後疊加到原圖上。肉眼完全察覺不到變化,但卻可以讓模型以99.3%的置信度認定右圖是長臂貓的圖像。
這個現象説明模型並未真正理解圖像的本質結構。模型構建的是一種內部表徵來描述自然圖像,但分佈外的數據點就能輕易突破這種表徵的侷限。
2014年Christian Szegedy做過一個有趣的實驗:他從CIFAR-10數據集選了幾張圖片,試圖用反向傳播把它們逐步轉換成飛機,想觀察圖像是如何一步步接近飛機的樣子。

結果的圖像幾乎沒什麼變化,但右下角這張在視覺上依然是輛車的圖片,模型卻近乎百分百確信它是架飛機。
視覺模型的輸入維度通常很高,每個像素的微小改變累積起來會在表徵向量中產生顯著變化,用L₂範數可以直觀看出這種累積效應。
幾乎所有機器學習模型都存在對抗攻擊的脆弱性:邏輯迴歸、softmax迴歸、支持向量機這類線性模型特別容易被精心設計的樣本誤導;相比之下徑向基函數(RBF)這種高度非線性的模型抵抗力要強一些。
多數機器學習模型的線性特性恰恰為生成對抗樣本做了最好的理論鋪墊,RNN和LSTM用加法操作來捕捉時序數據的流動,加法本質上是線性的;而ReLU、maxout這些激活函數讓深度神經網絡的輸入輸出關係呈現分段線性特徵。
進一步看這個過程:
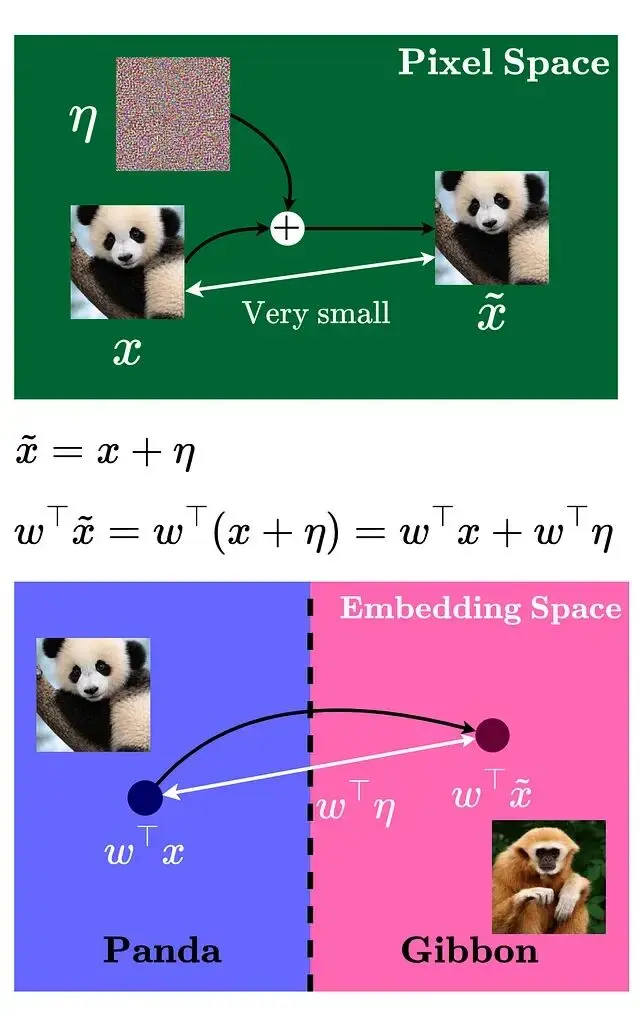
像素空間裏的擾動雖小,但經過權重矩陣的放大在嵌入空間產生的效應就明顯了,嵌入空間的變化量取決於權重向量與擾動向量的點積。
要讓這個點積最大化,就得沿着特定方向移動,或者準確説是沿着權重向量的符號方向。
快速梯度符號法(FGSM)
優化函數可以這樣定義,把損失函數改寫成泰勒級數的一階展開形式:
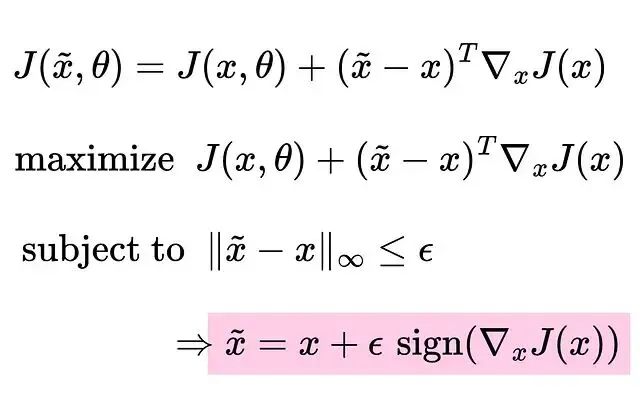
為什麼要最大化損失?因為我們的目標是欺騙模型,所以要反着優化的方向走,ε sign()給出了能產生最大更新的方向。
為什麼用最大範數而不是別的範數?因為我們的目的是稍微改變輸入,並且要控制在人能夠感知閾值之下。最大範數讓擾動的控制變得精確,這跟真實傳感器的情況比較接近。
將最大範數約束在ε以內,就能保證改變幅度不被肉眼發現。這就是快速梯度符號法(Fast Gradient Sign Method, FGSM)的核心思路:利用梯度的符號信息來確定移動方向。
FGSM的可視化分析
畫出數據點周圍的決策邊界能直觀展示FGSM的工作機制。
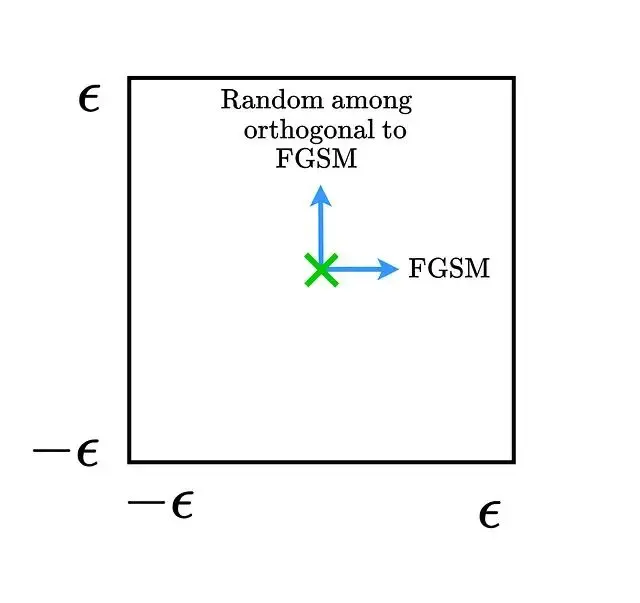
假設沿着FGSM方向和它的正交方向移動,移動範圍限制在ε最大範數邊界內,用這兩個向量把決策空間切成一個二維子空間。
取幾個數據點把它們周圍的決策邊界畫出來,白色區域代表正確類別,有色區域對應錯誤標籤。

沿FGSM方向移動會進入錯誤標籤的區域。然後加入隨機噪聲相當於往隨機方向移動:
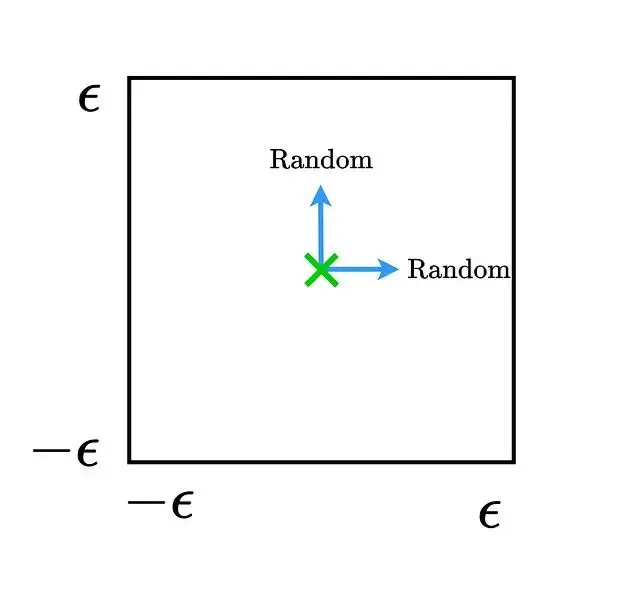
隨機方向的移動並不改變數據點的類別歸屬,這證明了一點:對抗樣本不等於隨機噪聲。
對抗子空間的維度是可以計算的,它表示能用來生成對抗樣本的正交方向數量。這些向量和梯度向量之間有較大的點積。
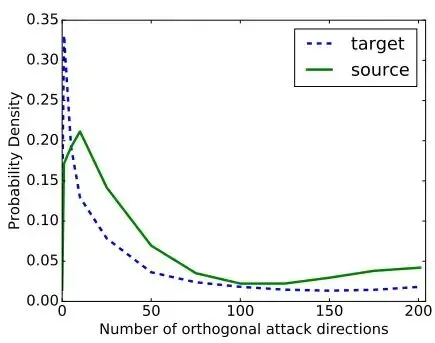
平均下來這些子空間大約有25個正交向量。
目標類別的一步攻擊
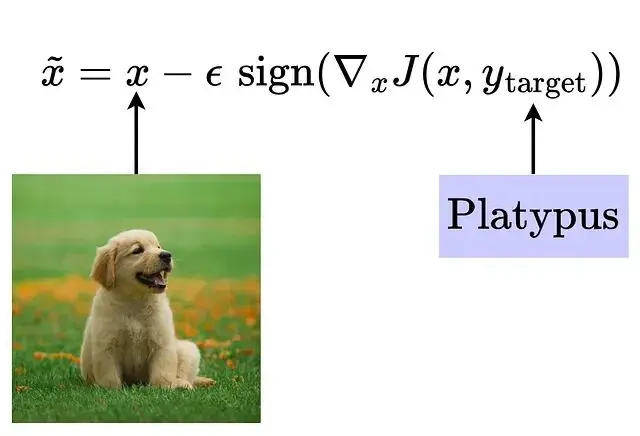
另一種思路是直接最大化某個特定目標類別的概率:讓輸入朝着能夠最小化目標標籤損失的方向移動。換句話説就是強迫模型認為損失最小的標籤就是目標標籤,從而輸出這個標籤。
更新規則寫成這樣:
MNIST數據集上的實驗
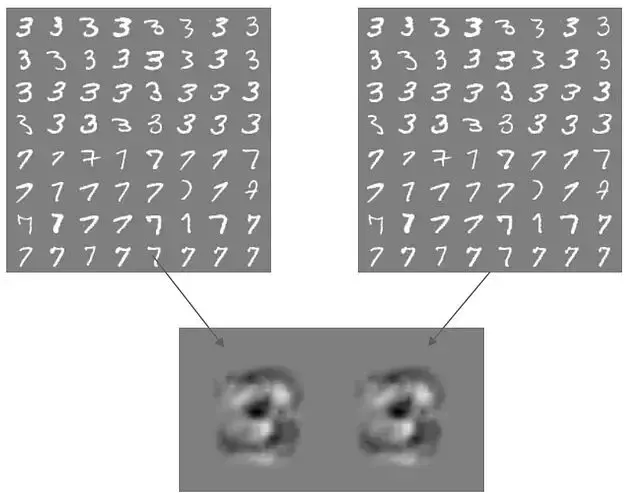
訓練一個模型來區分MNIST數據集裏的數字3和7。

這是個單層權重的簡單線性分類器,權重本身就可以當作梯度用。接下來取權重的符號。

這些權重決定了分類結果。把權重的符號加到樣本上或者從樣本中減去。
人眼能輕鬆過濾掉這些圖像的背景噪聲,但模型會認真對待每一個權重。權重為正時輸出7,權重為負時輸出3。這些生成的對抗樣本徹底瓦解了分類器的判別能力。
對抗樣本的遷移性
機器學習追求的是模型在不同數據集上都能保持穩定表現,這要求模型權重具備泛化能力。既然權重要泛化那基於這些權重生成的對抗樣本自然也會泛化。
不同數據集應該產生相似的權重分佈,可以量化模型間的遷移能力:
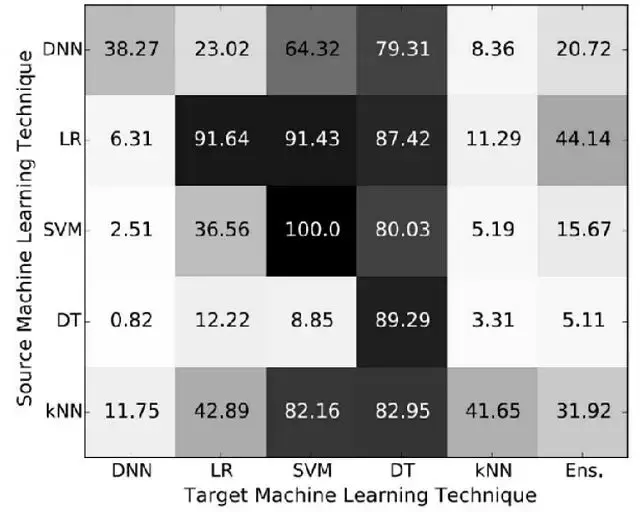
SVM依賴數據特性所以用一個SVM生成的對抗樣本很容易攻擊另一個SVM,而邏輯迴歸生成的對抗樣本有87.42%的概率能欺騙決策樹。
作為攻擊者,如果不清楚目標模型的具體架構,可以用模型集成的方式來生成對抗樣本。就算拿不到模型的訓練數據標籤,也能利用模型的輸出來構造對抗樣本。
有意思的是,人腦也會遭遇類似的"對抗攻擊"。下面這個例子挺經典:

這些其實是同心圓,但因為方塊的排列方向大腦會把它們解讀成螺旋。
對抗訓練提升泛化性
用對抗樣本訓練深度神經網絡能起到正則化的作用,還能改善性能。
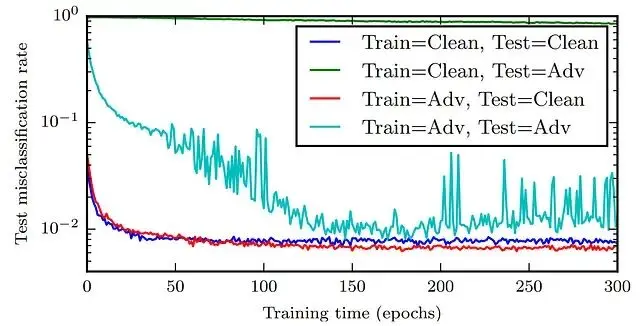
對抗訓練確實能提升DNN的表現,損失函數可以重新表述成這種形式:
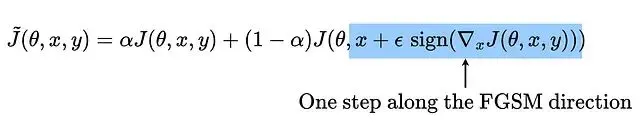
不過嚴格的線性模型用對抗樣本訓練不會有什麼改進。還可以修改損失函數,給對抗樣本分配更高的權重:
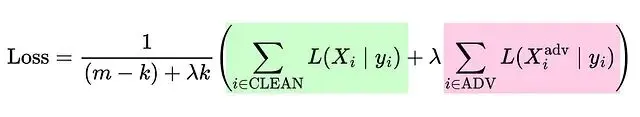
需要明確一點,這些做法都是在和對抗攻擊做鬥爭。要降低對抗攻擊的成功率,需要強大的優化算法配合嚴格的非線性模型架構。
參考文獻
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and Harnessing Adversarial Examples. ArXiv. /abs/1412.6572
Goodfellow, I. J., Mirza, M., Xu, B., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. ArXiv. /abs/1406.2661
Tramèr, F., Papernot, N., Goodfellow, I., Boneh, D., & McDaniel, P. (2017). The Space of Transferable Adversarial Examples. ArXiv. /abs/1704.03453
https://avoid.overfit.cn/post/815495f184a049389d702becdb972067
作者:Kavishka Abeywardana