

用LLM給LLM打分,這個看起來很聰明的做法正在讓AI評估變得不可靠。KRAFTON AI的這個工作直指當前LLM評估體系的軟肋:作為評判者的語言模型本身就帶有系統性偏差,而這種偏差在Chatbot Arena等主流基準測試中可以達到30%左右。也就是説排行榜上那些令人興奮的性能提升,有相當一部分可能是評估方法的偏差。
評判機制的運作方式
LLM-as-a-judge就是讓一個語言模型去評價另一個模型的輸出,典型的prompt類似於"這個回答正確嗎"或者"兩個回答哪個更好"。評判者返回分數或偏好,彙總後得到準確率、勝率之類的指標。
這套流程看着非常完美:人工標註既慢又貴,尤其對話、摘要、創意寫作這類開放式任務更是如此,而LLM評判者成本低、速度快、輸出穩定,還能給出看起來很有説服力的理由。
所以LLM-as-a-judge已經成了事實上的行業標準,Chatbot Arena用它、無數論文也用它。
偏差從何而來
語言模型做評估時會犯錯,但問題不在於犯錯本身而在於錯誤不是隨機的它們有規律可循。
論文用兩個經典統計指標來刻畫這一點:敏感性(q₁)表示正確識別好輸出的概率,特異性(q₀)表示正確識別差輸出的概率,理想情況下兩者都等於1而實際卻從來不是。
多數評估直接把評判者標記的"正確"比例當作真實性能,但除非評判者是完美的否則這個觀察值就是有偏估計。
我們舉個例子:假設評判者對好答案和差答案各有20%的錯誤率,即便誤差對稱估計出的準確率也會是真實值的扭曲版本。這樣差模型被高估而好模型被低估,而且不同論文用不同評判者,比較就徹底失去意義。
論文裏面説在Chatbot Arena數據集上未經校正的偏差接近30%,這個量級足以把一個真正的進步變成看起來的退步或者反過來。
無標籤數據也不是免費午餐
我們都會認為觀點認為:只要評判者夠強,無標籤數據就能替代標註數據,這樣測試集規模上去了就會消除這個誤差。
而這篇論文對此給出了乾脆的否定:如果沒有標籤來直接測準確率就必須有標籤來校準評判者。真實值繞不開,只是換了個使用方式。
如果不做校準模型質量和評判者偏差就分不開,只有做了校準才能分離二者。於是就有了一個實際的資源分配問題:如果給定固定的標註預算,是全部用於直接評估模型還是拿一小部分校準評判者、然後在大規模無標籤集上評估?
適用邊界在哪裏
這個問題可以清晰的通過統計學進行回答:
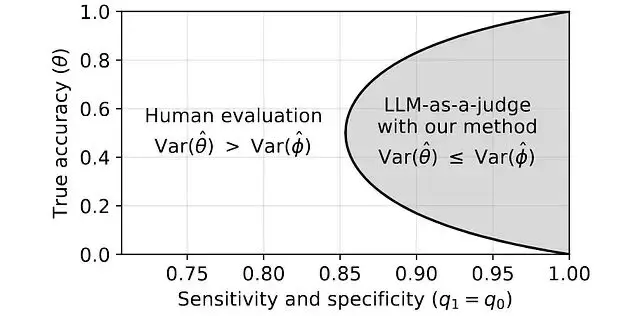
當系統真實準確率在50%附近時直接人工評估的方差最大,需要大量標籤才能得到可靠估計。這時候校準過的LLM評判者配合海量無標籤數據效率確實更高。
但當系統已經很強或很弱,比如準確率接近0或1那麼直接評估反而更好,估計極端概率本身就容易,評判者校準只會引入額外不確定性。
所以説:LLM-as-a-judge是條件性工具,並且只在特定區間有效盲目套用則適得其反。
校正方法
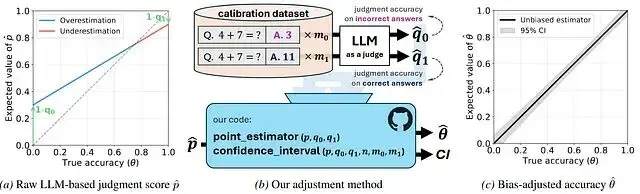
論文借鑑了流行病學中的Rogan-Gladen估計器。原理如下:先在一小批有標籤的樣本上測出評判者與人類的一致率得到敏感性和特異性的估計值;然後用這兩個參數對觀察到的分數做數學校正剝離評判者的系統性誤差。
結果得到了無偏估計,跨多個模型和基準的實驗顯示校正後大幅偏差基本消失,並且在某些在樸素評估下看起來穩定的排名校正後發生了逆轉。
不確定性量化
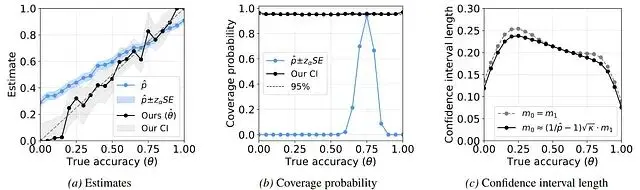
校正偏差只是第一步,正確的評估還需要報告評估的不確定性。論文給出的置信區間構造方法考慮了兩個方差來源:測試集評估的隨機性,以及校準集估計誤差率的隨機性。
採用帶穩定性調整的修正Wald方法後,模擬實驗中實現了接近名義的覆蓋率——報告95%區間時,真值落在其中的頻率確實約為95%。
大量AI論文隱含地宣稱確定性而實際上並不存在。兩個百分點的改進,如果置信區間重疊哪就什麼都不是。嚴格的區間能遏制過度宣稱給炒作降温。
自適應校準策略
論文還有個微妙的發現:不同位置的校準標籤價值不等。
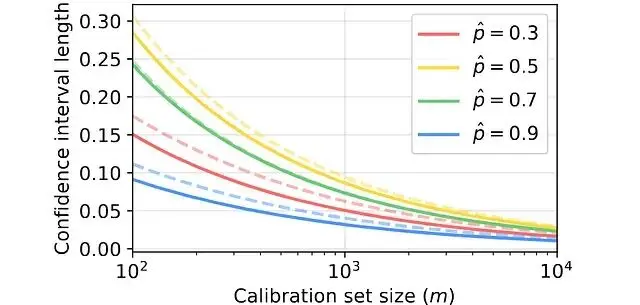
錯誤率在0.5附近時方差最大需要更多樣本才能估準。作者提出自適應方案是先跑小規模試點校準,定位不確定性最高的區域,再把剩餘標註預算集中投向那裏。
實測效果是置信區間縮短10%到20%,好的評估是數據量和數據質量的平衡。
分佈偏移下的表現
現實中校準數據和測試數據往往存在差異,很多現有方法比如prediction-powered inference依賴嚴格的同分布假設,如果假設破了保證也就沒了。
論文框架只要求評判者的混淆矩陣保持穩定,在模擬的分佈偏移場景下,它維持了無偏性而對照方法失效。
這種泛化性對快速迭代的基準測試尤其有價值:分佈漂移是常態不是例外。
總結
LLM-as-a-judge是個好想法但它的統計基礎一直沒跟上,而這項工作證明自動化評估可以既可擴展又可靠,但是前提是要承認侷限、校正偏差。
評估方法應該和模型架構得到同等重視:縮放定律再漂亮、訓練技巧再巧妙,測量本身出了問題就全白搭。校準不是可選項而是基礎設施級別的需求,如果打算用自動評判者就得為正確使用它分配資源。
而且並非所有任務都適合LLM評判,比如創意性、模糊性強的任務可能從校準後的自動化中獲益;數學推理、事實核查這類精確領域,黃金標準標籤仍然是剛需。
論文:
https://avoid.overfit.cn/post/17bc4cc132b4453daed96e931c74b6b8