

在數據分析工作中,我們經常需要處理來自多個來源的數據集。當合並來自20個不同地區的銷售數據時,可能會發現部分列意外丟失;或在連接客户數據時,出現大量重複記錄。如果您曾經因數據合併問題而感到困擾,本文將為您提供系統的解決方案。
Pandas庫中的merge和join函數提供了強大的數據整合能力,但不恰當的使用可能導致數據混亂。基於對超過1000個複雜數據集的分析經驗,本文總結了10種關鍵技術,幫助您高效準確地完成數據合併任務。

1、基本合併:數據整合的基礎工具
應用場景:合併兩個包含共享鍵的DataFrame(如訂單數據與客户信息)。
merged_df=pd.merge(orders_df, customers_df, on='customer_id')技術原理:
on='customer_id'參數指定用於對齊的公共鍵- 默認
how='inner'參數確保只保留匹配的行
實用技巧:使用
how='outer'可保留所有行並便於發現不匹配數據潛在問題:當
customer_id存在重複值時,可能導致行數意外增加。建議先驗證鍵的唯一性:
print(customers_df['customer_id'].is_unique) # 理想情況下應返回True2、左連接:保留主表完整性的操作
應用場景:需要保留左側DataFrame的所有記錄,即使部分記錄在右側表中沒有匹配項(例如,保留所有客户記錄,包括無訂單的客户)。
left_merged=pd.merge(customers_df, orders_df, on='customer_id', how='left')技術原理:
- 保留左側表的所有行,對於無匹配的記錄,在來自右側表的列中填充
NaN - 對於需要保持分析對象完整性的場景尤為重要
3、右連接:關注補充數據的方法
應用場景:優先保留右側DataFrame的完整記錄(例如,列出所有產品,包括未產生銷售的產品)。
right_merged=pd.merge(products_df, sales_df, on='product_id', how='right')技術原理:
- 展示所有銷售記錄,包括產品目錄中不存在的商品,適用於數據質量審計
實用建議:為保持代碼一致性,可考慮將DataFrame位置調換並使用左連接實現相同效果。
4、外連接:數據一致性檢測工具
應用場景:識別數據集之間的不匹配記錄(例如,查找沒有對應訂單的客户或沒有對應客户的訂單)。
outer_merged=pd.merge(df1, df2, on='key', how='outer', indicator=True)
outer_merged['_merge'].value_counts()輸出示例:
both 8000
left_only 1200
right_only 500技術原理:
indicator=True參數添加一個標識列,顯示每行數據的來源
概念類比:可將外連接視為維恩圖的完整實現,突顯兩個數據集的交集與差集。
5、基於索引連接:高效的合併方式
應用場景:使用索引而非列來合併DataFrame(如時間序列數據的合併)。
joined_df=df1.join(df2, how='inner', lsuffix='_left', rsuffix='_right')技術原理:
- 基於索引對齊的連接操作,通常比
merge()執行效率更高 lsuffix/rsuffix參數用於解決列名衝突問題
使用限制:當索引不具有實際業務意義(如隨機生成的行號)時,應選擇基於列的合併方式。
6、 多鍵合併:精確匹配的數據整合
應用場景:通過多個列進行合併操作(例如,同時通過
name和
signup_date匹配用户記錄)。
multi_merged=pd.merge(
users_df,
logins_df,
left_on=['name', 'signup_date'],
right_on=['username', 'login_date']
)技術原理:
- 通過多列匹配減少因單列重複值導致的不準確匹配
實施建議:數據合併前應先進行數據清洗,確保格式一致性,避免日期格式不統一(如
2023-01-01與
01/01/2023)導致的匹配失敗。
7、數據拼接:縱向數據整合技術
應用場景:垂直堆疊具有相同列結構的DataFrame(例如,合併多個月度報表)。
combined=pd.concat([jan_df, feb_df, mar_df], axis=0, ignore_index=True)技術原理:
axis=0參數指定按行進行堆疊;ignore_index=True重置索引編號
常見問題:不一致的列順序會導致生成包含NaN值的數據。建議使用
pd.concat(..., verify_integrity=True)參數及時捕獲此類問題。
8、交叉連接:全組合數據生成方法
應用場景:生成所有可能的組合(如測試每種產品在不同價格區域的組合方案)。
cross_merged=pd.merge(
products_df,
regions_df,
how='cross'
)技術原理:
- 生成兩個DataFrame的笛卡爾積,需謹慎使用以避免數據量爆炸
9、後綴管理:解決列名衝突的技術
應用場景:處理合並後的重名列(如區分
revenue_x與
revenue_y)。
merged_suffix=pd.merge(
q1_df,
q2_df,
on='product_id',
suffixes=('_q1', '_q2')
)技術原理:
- 自定義後綴(如
_q1和_q2)明確標識列的來源DataFrame
實用建議:使用具有業務含義的描述性後綴(如
_marketing與
_sales)增強數據可解釋性。
10、合併驗證:數據完整性保障機制
應用場景:避免一對多關係合併帶來的意外結果(如重複鍵導致的數據異常)。
pd.merge(
employees_df,
departments_df,
on='dept_id',
validate='many_to_one' # 確保departments_df中的dept_id是唯一的
)技術原理:
validate='many_to_one'參數會在右側DataFrame的鍵存在重複值時拋出錯誤,提供數據質量保障
驗證選項:
'one_to_one':要求兩側的鍵都是唯一的'one_to_many':左側鍵唯一,右側鍵可重複'many_to_one':要求右側鍵唯一,左側鍵可重複
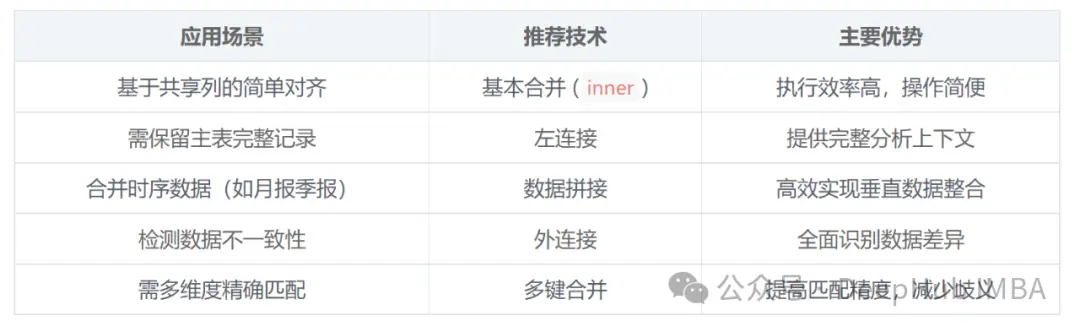
不同場景的技術選擇指南
預先驗證鍵的質量:
print(df['key_column'].nunique()) # 檢測潛在的重複值處理缺失值:
df.fillna('N/A', inplace=True) # 防止因缺失值導致的合併不完整優化內存使用:在處理大型數據集前調整數據類型:
df['column'] =df['column'].astype('int32') # 將64位數據類型降為32位實踐練習(可選)
- 驗證合併質量:檢查現有項目中的數據合併邏輯,應用
validate='one_to_one'進行驗證。 - 交叉連接實踐:嘗試合併產品與地區數據表,並通過邏輯篩選獲取有價值的組合。
- 列名衝突處理:優化已合併DataFrame中的重名列,提高數據可解釋性。
總結
在Pandas中進行數據合併操作需要精確理解數據結構、清晰掌握各種合併方法的特性,並注意驗證合併結果的正確性。掌握本文介紹的技術,可以顯著提高數據整合效率,減少調試時間,將更多精力投入到數據分析與洞察發現中。
關鍵建議:當對合並結果有疑慮時,建議使用帶有
validate參數和
indicator=True的
pd.merge()函數,這將提供額外的安全保障和問題定位能力。
https://avoid.overfit.cn/post/d96beae806b14e1fa5f9c161fd49c015
