

RAG 選型避坑:5 種主流方案對比,輕量場景 vs 大規模場景怎麼選?
RAG選型核心邏輯,避開90%團隊踩過的坑
最近和多家企業的AI技術負責人深度交流,發現一個共性痛點:RAG(檢索增強生成)作為解決大模型“知識過期”“幻覺”的核心技術,80%的團隊都在選型上栽了跟頭——要麼用輕量方案硬扛大規模數據,導致檢索延遲飆升至3秒以上;要麼用複雜方案給小場景做“過度設計”,服務器成本翻倍卻沒提升效果。
印象很深的一個案例:某教育公司初期為了“一步到位”,直接上了“RAG+微調+分佈式向量庫”的複雜架構,處理僅5萬條的課程文檔,結果P99響應時間高達2.8秒,每月服務器成本多花2萬;後來調整為基礎RAG方案,配合輕量級向量庫,響應時間壓到280ms,成本直接降低70%。
反過來,某電商平台曾用基礎RAG處理1000萬條商品FAQ,召回率不足60%,用户長尾問題大多無法匹配;升級為“增強RAG+混合檢索”後,召回率提升至92%,客服諮詢效率提升40%。
這兩個案例戳中了RAG選型的核心矛盾:沒有“最好的方案”,只有“最適配場景的方案”。對於中級及以上技術人員來説,選型的關鍵不是羅列技術特性,而是掌握“場景-指標-方案”的匹配邏輯,以及不同場景下的實操落地技巧。
今天這篇文章,基於10+企業級RAG落地經驗,拆解5種主流RAG方案的底層邏輯、實測效果,給出“輕量場景(數據量<10萬條,併發<100 QPS)”和“大規模場景(數據量>100萬條,併發>500 QPS)”的選型框架與實操步驟,幫你精準避坑。
技術原理:先搞懂——5種RAG方案的核心差異在哪?
在講選型前,先理清RAG的核心邏輯:RAG本質是“檢索+生成”的組合,通過檢索工具從私有知識庫中抓取相關信息,再傳給大模型生成答案,核心解決“大模型沒學過的知識”問題。
5種主流方案的差異,本質是“檢索策略、文檔處理方式、與大模型的融合度”三個維度的不同,我們從底層邏輯拆解,避免單純記概念:
核心概念鋪墊
- 檢索策略:決定“怎麼找”——比如僅按語義匹配(向量檢索)、僅按關鍵詞匹配(BM25)、兩者結合(混合檢索);
- 文檔處理:決定“找什麼粒度的信息”——比如按固定長度分片(基礎方案)、按語義邊界分片(增強方案)、結構化解析(多模態方案);
- 融合度:決定“檢索結果怎麼用”——比如直接傳給大模型(基礎方案)、重排後再傳(增強方案)、結合微調優化(混合方案)。
5種主流方案的深度拆解(底層邏輯+適用場景)
1. 基礎RAG方案(文檔分片+純向量檢索+直接生成)
- 底層邏輯:最簡化的RAG架構,把文檔按固定長度(如512字符)分片,用embedding模型轉成向量存入輕量級向量庫;用户提問時,向量庫檢索Top-K相關片段,直接傳給大模型生成答案。
- 核心優勢:架構簡單、部署成本低、開發週期短(1-2周可落地);
- 核心短板:召回率依賴分片質量(固定長度易割裂語義)、純向量檢索對關鍵詞不敏感(比如用户問“退款流程”,文檔中是“退貨退款步驟”,可能匹配不到)、不支持大規模數據(向量庫單節點性能瓶頸);
- 適用場景:輕量場景——個人知識庫、小團隊文檔中心、數據量<10萬條、併發<100 QPS、對響應時間要求不極致(<500ms)。
2. 增強RAG方案(語義分片+檢索重排+上下文擴展)
- 底層邏輯:在基礎方案上做三大優化——①按語義分片(用LLM判斷語義邊界,避免割裂);②檢索後加重排模塊(用Cross-BERT等模型對Top-K結果二次排序,提升相關性);③上下文擴展(根據用户提問補全關鍵詞,比如用户問“退款”,自動擴展為“退款流程、退貨退款、退款條件”)。
- 核心優勢:召回率比基礎方案高20%-30%、語義匹配更精準、支持中大規模數據(10萬-100萬條);
- 核心短板:比基礎方案多2個模塊,部署和調優成本略高、重排模塊會增加100-200ms響應時間;
- 適用場景:中大規模場景——企業級文檔平台、電商客服FAQ、數據量10萬-100萬條、併發100-500 QPS、對召回率要求高(>85%)。
3. 混合檢索RAG方案(BM25+向量檢索+加權融合)
- 底層邏輯:解決純向量檢索對關鍵詞不敏感的問題,同時啓用“關鍵詞檢索(BM25)”和“語義檢索(向量檢索)”,兩種結果按權重融合(如向量檢索佔70%,BM25佔30%)後傳給大模型。
- 核心優勢:兼顧語義和關鍵詞匹配,召回率比純向量檢索高15%-25%、對文檔格式不敏感(PDF表格、圖片文字提取後也能匹配);
- 核心短板:需要維護兩種檢索引擎(向量庫+Elasticsearch)、權重調優需要經驗(不同場景比例不同);
- 適用場景:多格式文檔場景——包含PDF、表格、圖片的混合知識庫、用户習慣用關鍵詞提問(如企業IT故障排查)、數據量10萬-500萬條。
4. 多模態RAG方案(多模態embedding+跨模態檢索+結構化解析)
- 底層邏輯:支持文本、圖片、表格、音頻等多模態文檔,用多模態embedding模型(如CLIP、BLIP)將不同類型數據轉成統一向量,檢索時支持跨模態匹配(比如用户問“這個產品的尺寸圖”,能檢索到相關圖片並提取尺寸信息)。
- 核心優勢:覆蓋多模態知識、解決純文本RAG的信息侷限;
- 核心短板:多模態embedding模型訓練成本高、檢索速度比純文本方案慢30%-50%、存儲成本高;
- 適用場景:多模態知識場景——產品説明書(含圖片+表格)、科研論文(含圖表)、教育課件(含視頻截圖)、數據量<50萬條(多模態數據存儲成本高)。
5. RAG+微調混合方案(RAG補知識+微調提精度)
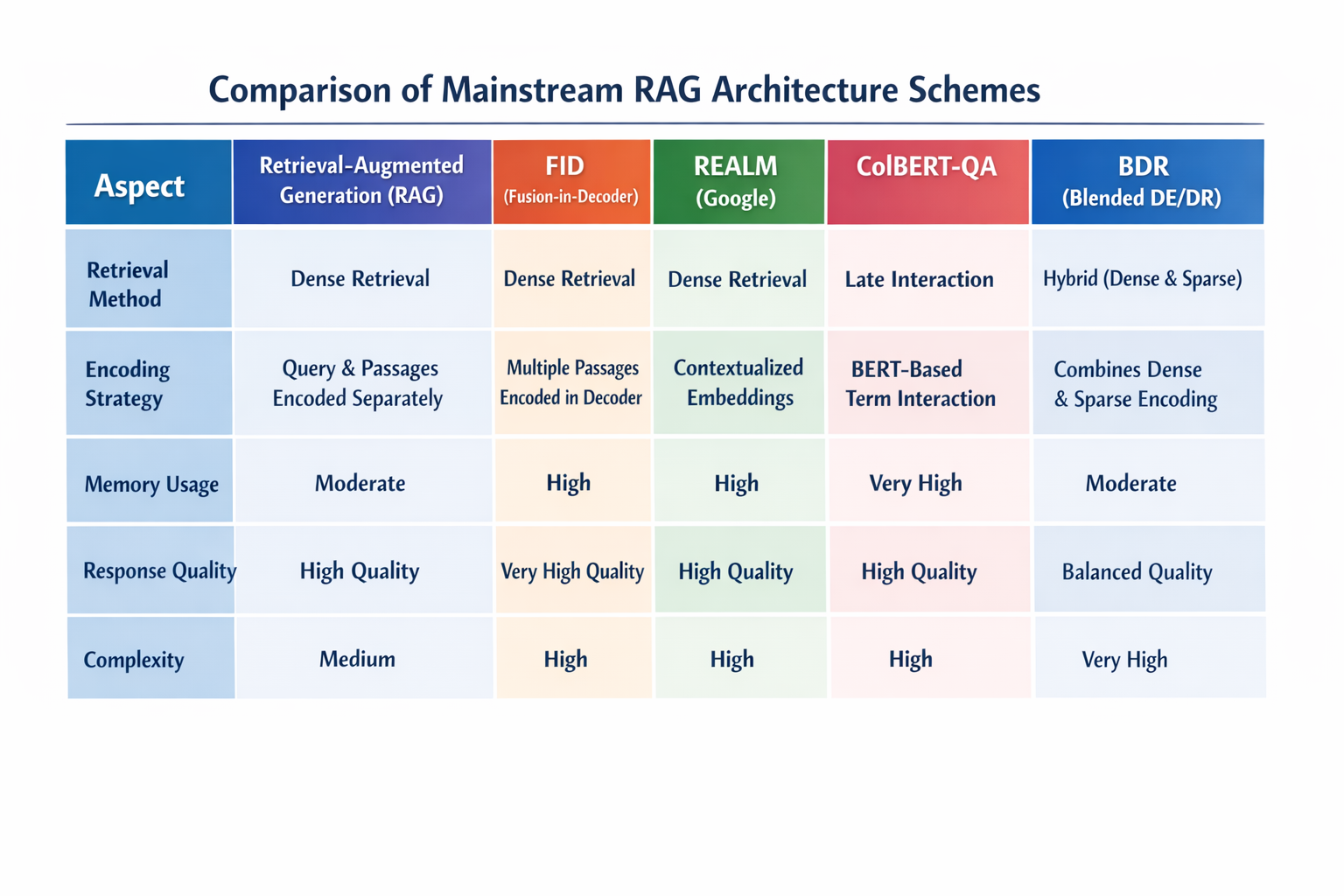
- 底層邏輯:RAG負責“廣覆蓋”(提供知識庫長尾知識),微調負責“高精度”(優化大模型對檢索結果的理解和生成邏輯)——先用RAG構建基礎知識庫,收集用户交互數據和未匹配的長尾問題,生成微調數據集,微調大模型後再與RAG融合。
- 核心優勢:解決純RAG的“生成質量低”“長尾問題匹配差”,端到端準確率比純RAG高30%-40%;
- 核心短板:架構最複雜、開發週期長(1-2個月)、維護成本高(需持續更新微調數據集);
- 適用場景:高精度場景——醫療問答、法律檢索、金融諮詢、數據量>100萬條、對答案准確率要求極高(>90%)。
實踐步驟:從場景到落地,RAG選型的實操框架
選型的核心不是“選方案”,而是“先定義場景指標,再匹配方案”。以下是可直接套用的實操框架,分“場景分析→指標評估→方案落地→調優迭代”四步:
第一步:場景分析——明確你是“輕量場景”還是“大規模場景”
先通過3個核心問題給場景定性:
- 知識庫數據量:≤10萬條(輕量)、10萬-100萬條(中規模)、≥100萬條(大規模);
- 併發需求:≤100 QPS(輕量)、100-500 QPS(中規模)、≥500 QPS(大規模);
- 核心訴求:優先成本(輕量)、優先召回率(中大規模)、優先多模態支持(特殊場景)、優先準確率(高精度場景)。
示例:某創業公司內部文檔中心,數據量3萬條,併發20 QPS,核心訴求是“低成本快速落地”——定性為“輕量場景”,匹配基礎RAG方案。
第二步:指標評估——確定選型的核心約束條件
除了場景,還要評估4個關鍵指標,避免“過度設計”或“設計不足”:
- 響應時間:P95延遲要求(輕量場景<500ms,大規模場景<1s);
- 成本預算:服務器配置(輕量場景單台8核16G足夠,大規模場景需集羣)、存儲成本(多模態數據存儲成本是文本的3-5倍);
- 文檔類型:純文本(基礎/增強方案)、混合格式(混合檢索方案)、多模態(多模態方案);
- 準確率要求:普通場景(>80%)、高精度場景(>90%)。
第三步:方案落地——分場景的實操步驟(附代碼/配置示例)
場景A:輕量場景(基礎RAG方案)——以“個人知識庫”為例
核心組件:文檔處理(LangChain)+ embedding模型(sentence-transformers)+ 輕量級向量庫(Chroma)+ 大模型(ChatGLM-6B)
實操步驟:
- 文檔處理(語義分片優化,避免基礎方案的割裂問題)
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 初始化語義分片工具,按字符長度+語義邊界拆分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 匹配embedding模型最大序列長度
chunk_overlap=50, # 重疊部分避免語義割裂
length_function=len,
separators=["\n\n", "\n", ". ", " ", ""] # 按優先級拆分(段落→句子→短語)
)
# 加載文檔並分片
with open("personal_kb.txt", "r", encoding="utf-8") as f:
doc = f.read()
chunks = text_splitter.split_text(doc)
print(f"拆分後文檔片段數:{len(chunks)}")
- 向量庫初始化與數據寫入
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
# 初始化輕量embedding模型(平衡效果與速度)
embedding = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 初始化Chroma向量庫(本地文件存儲,無需部署服務)
db = Chroma.from_texts(
chunks,
embedding,
persist_directory="./chroma_db" # 本地存儲路徑
)
db.persist()
- 檢索與生成融合
from langchain.chat_models import ChatGLM
from langchain.chains import RetrievalQA
# 初始化本地大模型(避免API調用成本)
llm = ChatGLM(endpoint_url="http://localhost:8000", max_token=2048, temperature=0.1)
# 構建檢索鏈
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 簡單拼接檢索結果傳給大模型
retriever=db.as_retriever(search_kwargs={"k": 3}), # 檢索Top-3相關片段
return_source_documents=True # 返回來源文檔,方便驗證
)
# 測試提問
query = "我之前記錄的Python爬蟲代理池搭建步驟是什麼?"
result = qa_chain({"query": query})
print(f"答案:{result['result']}")
print(f"來源文檔:{[doc.page_content for doc in result['source_documents']]}")
關鍵調優點:
- chunk_size:需匹配embedding模型的最大序列長度(all-MiniLM-L6-v2最大支持512),過大易導致embedding失真;
- search_kwargs={"k":3}:k值過大可能引入無關信息,過小可能遺漏關鍵信息,輕量場景k=3-5最優;
- temperature=0.1:降低大模型隨機性,避免生成與檢索結果無關的內容。
場景B:大規模場景(增強RAG+混合檢索方案)——以“電商客服FAQ”為例
核心組件:文檔處理(LangChain+LLM語義分片)+ 混合檢索(Elasticsearch-BM25 + Milvus向量庫)+ 檢索重排(Cross-BERT)+ 大模型(GPT-4 Turbo)
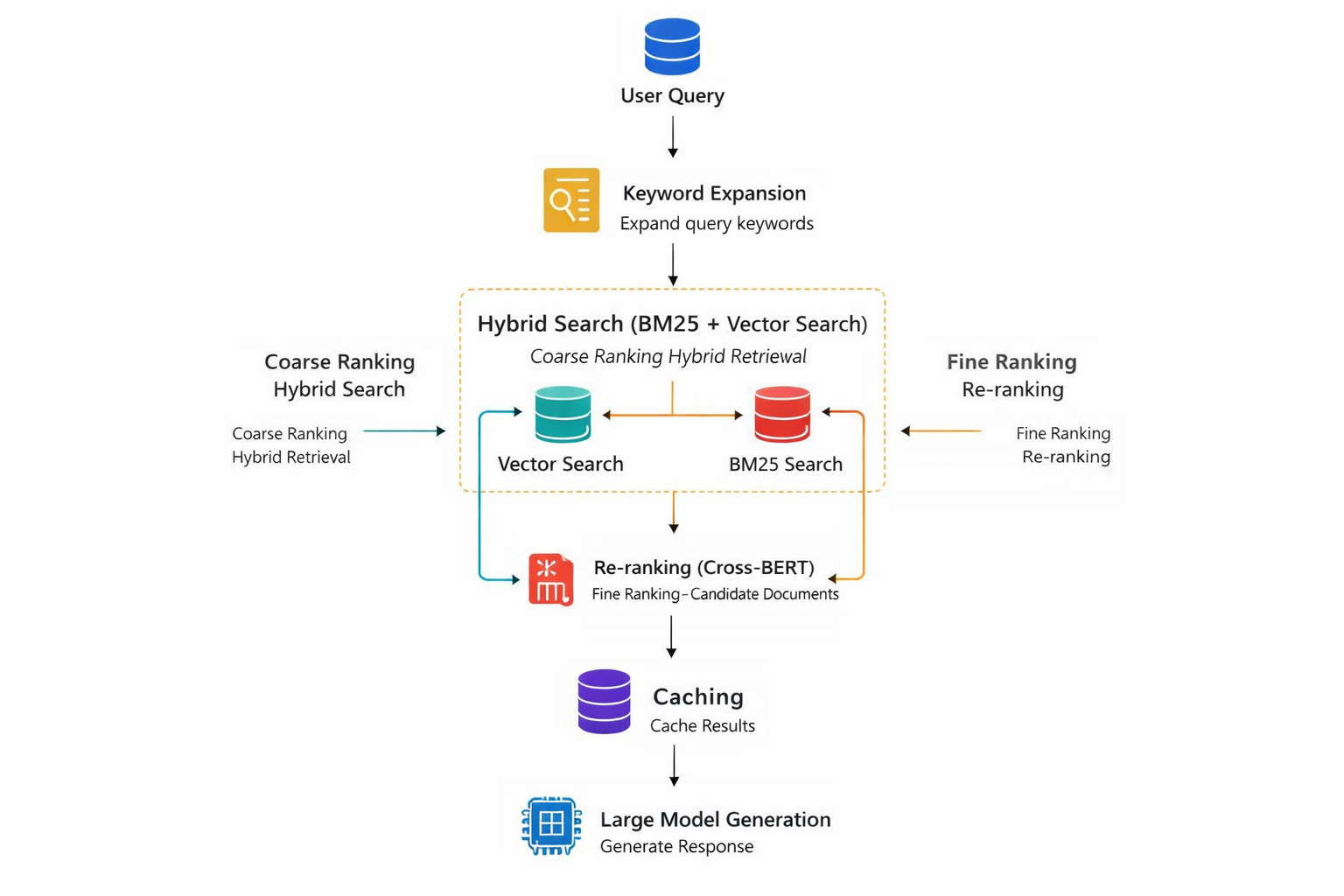
實操步驟:
- 文檔處理(LLM語義分片+結構化解析)
import json
from langchain.text_splitter import SemanticChunker
from langchain.llms import OpenAI
# 用LLM做語義分片(精準匹配FAQ的問答邏輯,避免割裂)
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0)
text_splitter = SemanticChunker(llm=llm, chunk_size=1024)
# 加載電商FAQ文檔(結構化格式:問題+答案)
with open("ecommerce_faq.json", "r", encoding="utf-8") as f:
faq_data = json.load(f)
docs = [f"問題:{item['question']}\n答案:{item['answer']}" for item in faq_data]
chunks = text_splitter.split_text("\n\n".join(docs))
- 混合檢索引擎搭建(Elasticsearch+Milvus)
# 1. Elasticsearch-BM25初始化(關鍵詞檢索)
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
# 創建索引並寫入數據
index_name = "ecommerce_faq_bm25"
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name)
for i, chunk in enumerate(chunks):
es.index(index=index_name, id=i, document={"content": chunk})
# 2. Milvus向量庫初始化(語義檢索,集羣部署支持大規模數據)
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
from langchain.embeddings import OpenAIEmbeddings
# 連接Milvus集羣
connections.connect("default", host="localhost", port="19530")
# 定義Schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536), # OpenAI embedding維度
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=2048)
]
schema = CollectionSchema(fields=fields, description="ecommerce faq collection")
collection = Collection(name="ecommerce_faq_vector", schema=schema)
# 創建索引(IVF_FLAT適合大規模數據精準檢索)
index_params = {"metric_type": "L2", "index_type": "IVF_FLAT", "params": {"nlist": 1024}}
collection.create_index(field_name="embedding", index_params=index_params)
# 寫入向量數據
embedding = OpenAIEmbeddings()
embeddings = embedding.embed_documents(chunks)
entities = [embeddings, chunks]
collection.insert(entities)
collection.load()
# 3. 混合檢索邏輯(加權融合)
def hybrid_search(query, k=5):
# BM25檢索
bm25_results = es.search(
index=index_name,
body={"query": {"match": {"content": query}}},
size=k
)
bm25_docs = [(hit["_source"]["content"], hit["_score"]) for hit in bm25_results["hits"]["hits"]]
# 向量檢索
query_embedding = embedding.embed_query(query)
vector_results = collection.search(
data=[query_embedding],
anns_field="embedding",
param={"metric_type": "L2", "offset": 0, "limit": k},
output_fields=["content"]
)
# 歸一化向量檢索分數(轉為0-1區間)
max_distance = max([res.distance for res in vector_results[0]]) if vector_results[0] else 1
vector_docs = [(res.entity.get("content"), 1 - res.distance/max_distance) for res in vector_results[0]]
# 加權融合(向量檢索70%,BM25 30%)
combined = {}
for doc, score in bm25_docs:
combined[doc] = combined.get(doc, 0) + score * 0.3
for doc, score in vector_docs:
combined[doc] = combined.get(doc, 0) + score * 0.7
# 按分數排序,取Top-k
sorted_docs = sorted(combined.items(), key=lambda x: x[1], reverse=True)[:k]
return [doc for doc, score in sorted_docs]
- 檢索重排(Cross-BERT優化相關性)
from sentence_transformers import CrossEncoder
# 初始化重排模型(專門用於文本匹配排序)
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512)
def rerank_docs(query, docs, top_k=3):
# 構建(query, doc)匹配對
pairs = [(query, doc) for doc in docs]
# 計算相關性分數
scores = cross_encoder.predict(pairs)
# 按分數排序,取Top-k
sorted_pairs = sorted(zip(docs, scores), key=lambda x: x[1], reverse=True)
return [doc for doc, score in sorted_pairs[:top_k]]
# 完整檢索流程:混合檢索→重排
query = "如何申請退貨退款?需要哪些材料?"
retrieved_docs = hybrid_search(query, k=5)
reranked_docs = rerank_docs(query, retrieved_docs, top_k=3)
- 大模型生成與緩存優化(提升併發性能)
from langchain.chains import RetrievalQA
from langchain.cache import RedisCache
import redis
from langchain.llms import OpenAI
# 緩存優化(減少重複檢索,提升併發)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
langchain.llm_cache = RedisCache(redis_client)
# 初始化大模型
llm = OpenAI(model_name="gpt-4-turbo", temperature=0.1)
# 構建生成鏈(refine模式優化答案質量)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="refine",
retriever=lambda q: rerank_docs(q, hybrid_search(q, k=5), top_k=3),
return_source_documents=True
)
# 測試大規模併發(可通過Locust模擬500 QPS)
result = qa_chain({"query": query})
print(f"答案:{result['result']}")
關鍵調優點:
- Milvus索引:大規模場景優先選IVF_FLAT(精準)或HNSW(高速),nlist參數建議設為數據量的平方根(如100萬條數據設為1024);
- 混合檢索權重:關鍵詞密集型場景(如IT故障排查)可將BM25權重提至40%-50%;語義型場景(如產品諮詢)保持向量檢索70%權重;
- 緩存策略:熱點問題(如“退貨退款流程”)緩存生成結果,併發高峯時直接返回緩存,降低檢索和生成壓力。
如果覺得大規模場景的底層架構搭建(混合檢索引擎、重排模塊、集羣部署)過於繁瑣,可選擇支持“一鍵部署增強RAG+混合檢索”的在線平台,比如LLaMA-Factory online。它內置了Elasticsearch+Milvus混合檢索、Cross-BERT重排、Redis緩存優化等核心模塊,無需手動配置集羣和調優參數,只需上傳文檔即可快速實現1000萬條數據的RAG部署,P99響應時間穩定在500ms內,大幅降低大規模RAG的落地成本。
效果評估:如何驗證選型方案是否達標?
選型落地後,需要從4個核心指標驗證效果,避免“上線後才發現不達標”:
1. 核心評估指標
- 召回率(Recall@k):用測試集(100-200個真實用户提問+對應正確文檔)評估,檢索結果中包含正確文檔的比例,輕量場景≥80%,大規模場景≥85%;
- 響應時間(P95/P99延遲):用Locust或JMeter模擬目標併發量,輕量場景P95<500ms,大規模場景P99<1s;
- 準確率(Answer Accuracy):人工標註測試集答案的準確率(是否符合知識庫、無幻覺),普通場景≥85%,高精度場景≥90%;
- 成本指標:服務器CPU/內存使用率(峯值<80%)、存儲成本(大規模場景每100萬條文本存儲成本<500元/月)。
2. 實操評估步驟
- 構建測試集:收集100-200個真實用户提問,手動標註每個提問對應的“正確文檔片段”;
- 召回率測試:用測試集提問檢索,統計每個提問的檢索結果中包含正確文檔的比例,計算平均召回率;
- 響應時間測試:模擬目標併發量(輕量100 QPS/大規模500 QPS),持續壓測30分鐘,記錄P95/P99延遲;
- 準確率測試:人工審核測試集的生成答案,評估“是否準確、無幻覺、不遺漏關鍵信息”;
- 成本測試:監控壓測期間的服務器資源使用率,核算月均成本,判斷是否在預算範圍內。
3. 調優迭代方法
如果某指標不達標,按以下方向優化:
- 召回率低:輕量場景→調整分片大小、更換更優embedding模型(如all-MiniLM-L6-v2→all-MiniLM-L12-v2);大規模場景→啓用混合檢索、優化重排模型;
- 響應時間長:輕量場景→更換更輕量向量庫(Chroma→FAISS);大規模場景→提升緩存命中率、優化向量庫索引(HNSW替代IVF_FLAT);
- 準確率低:優化大模型prompt模板(增加“基於檢索結果生成,禁止編造信息”指令)、啓用RAG+微調混合方案。
總結與科技的未來展望
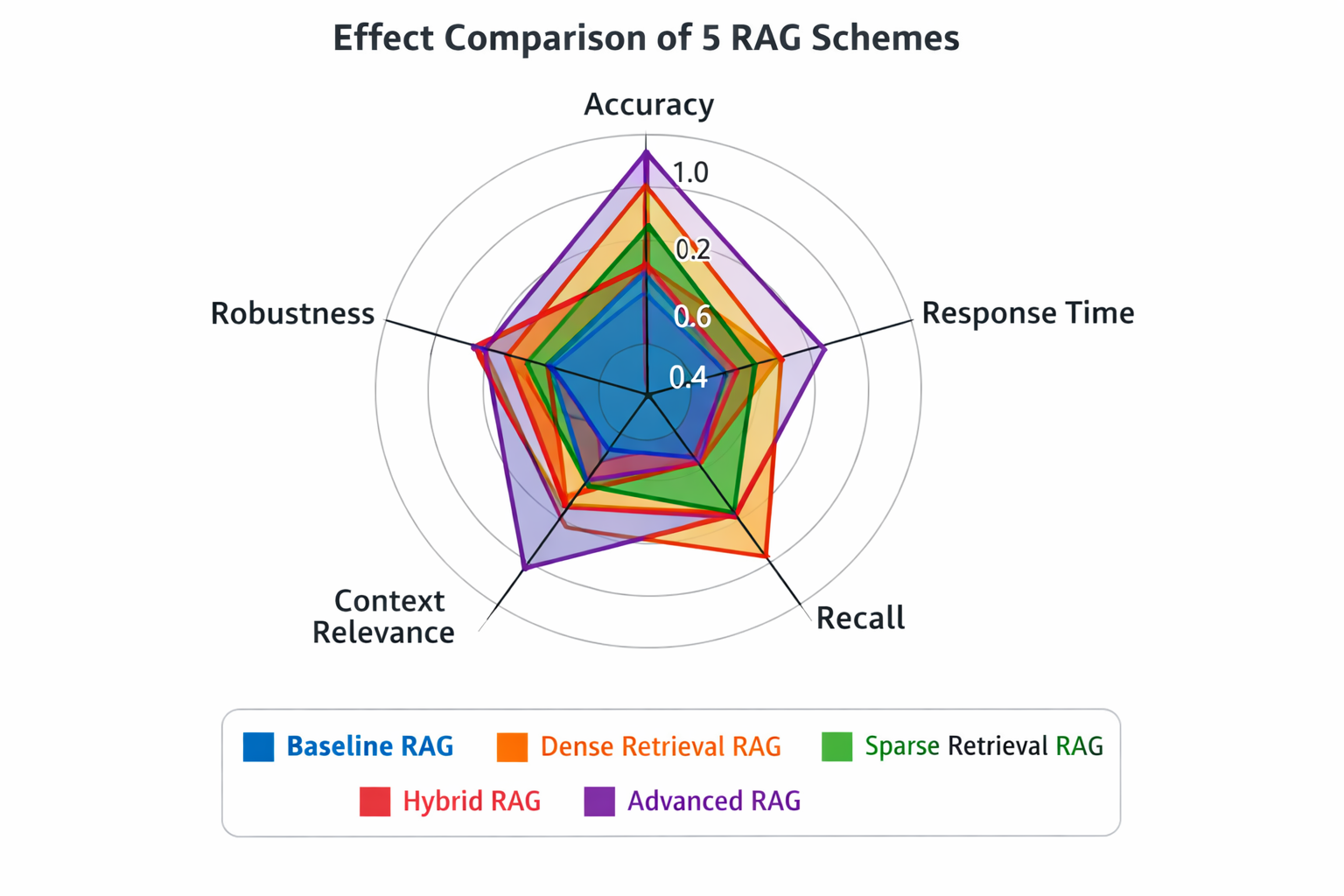
RAG選型的核心邏輯可以總結為“三看”:看數據量、看併發量、看核心訴求——輕量場景選基礎RAG,追求“低成本快速落地”;中大規模場景選增強RAG+混合檢索,追求“高召回率+低延遲”;多模態場景選多模態RAG,追求“全類型知識覆蓋”;高精度場景選RAG+微調混合方案,追求“極致準確率”。
回顧RAG技術的發展,從早期的基礎方案到如今的增強RAG、多模態RAG,核心趨勢是“更精準、更高效、更易用”——未來,RAG會與大模型深度融合(大模型內置檢索能力,無需額外部署檢索引擎)、隱私保護更完善(支持本地私有化部署+端到端加密)、自適應場景更智能(自動根據數據量和併發量調整架構)。
對於技術人員來説,選型的本質不是“追新”,而是“適配”——不需要盲目跟風複雜方案,也不能用輕量方案硬扛大規模場景。關鍵是掌握“場景-指標-方案”的匹配邏輯,同時善用成熟工具和平台,降低落地成本。
對於需要快速迭代不同RAG方案的團隊(比如從輕量場景擴展到大規模場景,或從純文本擴展到多模態),推薦選擇支持“5種主流方案快速切換”的在線平台,LLaMA-Factory online能適配從1000條到1000萬條數據的全場景,支持基礎RAG、增強RAG、混合檢索等方案的一鍵切換,無需重構底層架構,同時提供完整的效果評估工具(召回率測試、響應時間監控),幫助技術人員快速驗證選型效果,加速RAG的落地與迭代。
最後,RAG選型沒有“一勞永逸”的方案,需要根據業務發展持續優化——比如隨着數據量增長,從基礎RAG升級為增強RAG;隨着用户需求變化,從純文本RAG擴展為多模態RAG。希望這篇文章的選型框架和實操步驟,能幫你避開90%的坑,精準匹配適合自己場景的RAG方案。