

從零開始:PPO 微調大模型實戰(基於 PyTorch)
PPO 真正難的,不是算法本身
如果你已經看過一些 PPO 的原理文章,大概率會有過這種感覺:
好像每個字都認識,但真讓我自己寫代碼,腦子還是一片空白。
這其實挺正常的。
至少我第一次準備動手寫 PPO 的時候,也是這種狀態。
問題不在你,而在 PPO 本身。
在論文裏,PPO 看起來是一個乾淨利落的算法;
但一旦落到工程裏,它立刻變成了一整條系統鏈路:
- 模型自己生成內容
- 用 reward model 打分
- 再算 KL 約束
- 再算 advantage
- 然後還要小心翼翼地更新多輪
任何一個地方寫錯,都不一定會立刻報錯,但後果可能很嚴重:
- loss 看起來很正常,但模型能力在悄悄退化
- reward 一路往上走,輸出卻越來越奇怪
- 訓練能跑、日誌也漂亮,但結果完全不可復現
所以這篇文章我只想做一件事:
不用任何黑盒框架,從零用 PyTorch 跑通一版不容易翻車的 PPO 微調。
它不追求最優,也不炫技。
目標只有一個:工程上儘量安全。
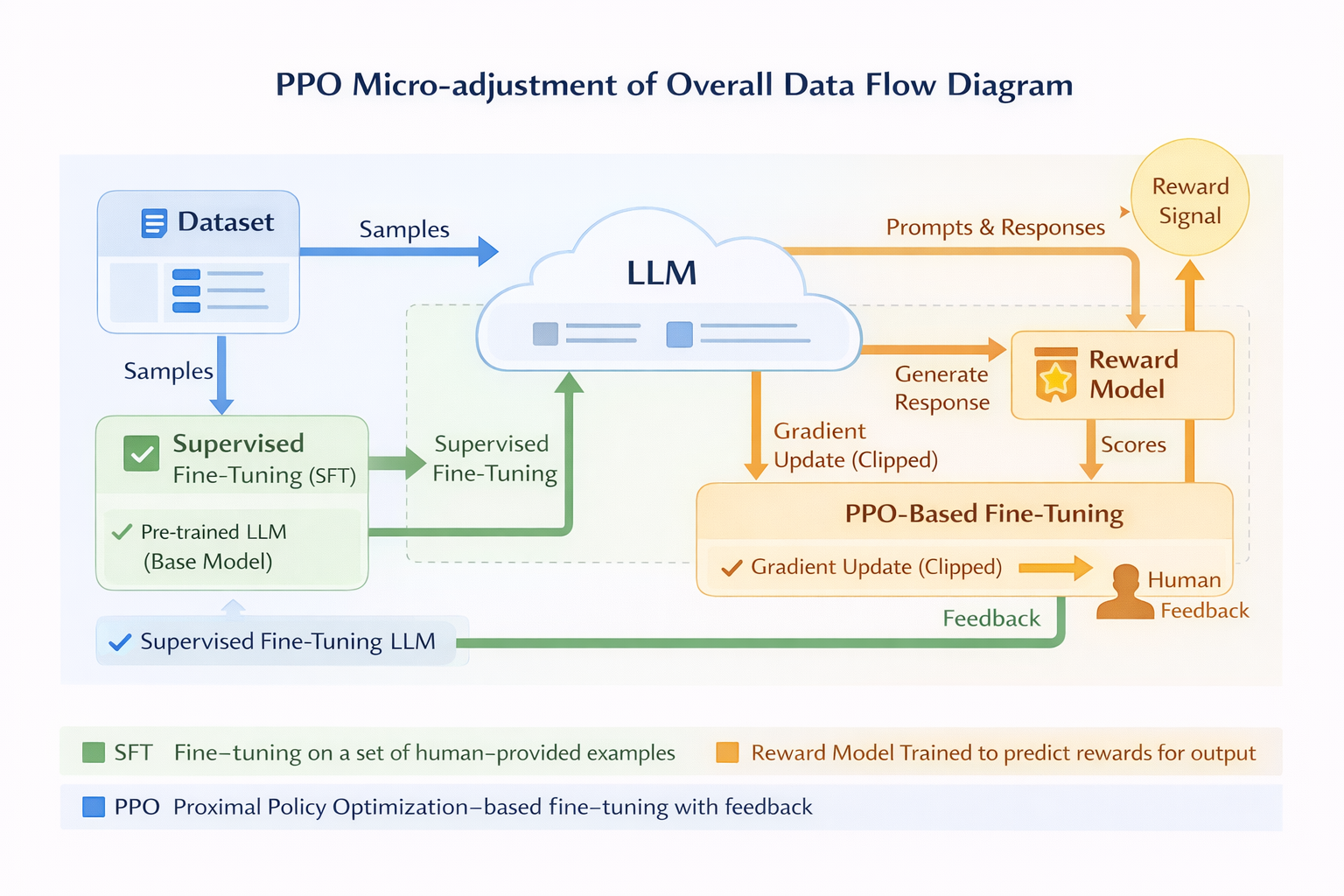
PPO 微調整體數據流圖
開始之前:你需要準備什麼(以及別對第一版抱太大幻想)
在真正寫 PPO 代碼之前,我建議你先確認三件事。
第一,你的 base model 已經做過 SFT
PPO 並不是用來教模型“怎麼回答問題”的,它更像是在微調模型的行為邊界。
第二,你手裏有一個能打分的 Reward Model
它不需要特別聰明,只要穩定、一致、別太極端,就已經夠用了。
第三,也是最重要的一點
你得接受一個現實:
第一版 PPO 的目標不是效果炸裂,而是模型沒被你訓壞。
很多失敗的 PPO 項目,問題並不出在算法上,而是工程師一開始就太着急,想“一步調到最優”。
PPO 微調的整體工程結構(先把全局圖放在腦子裏)
在寫任何代碼之前,先在腦子裏有一張全局圖,會讓你少踩很多坑。
在大模型場景下,一次完整的 PPO iteration,通常包括這些步驟:
- 用當前 policy 生成 response
- 用 reward model 給 response 打分
- 計算當前 policy 和 reference policy 之間的 KL
- 把 reward 和 KL 合成一個總 reward
- 根據總 reward 估計 advantage
- 用 PPO loss 小步更新模型參數
如果一定要打個比方,我更願意這樣理解 PPO:
它就像給策略梯度拴了一根安全繩。
你可以往上爬,但不允許一步跨得太狠。
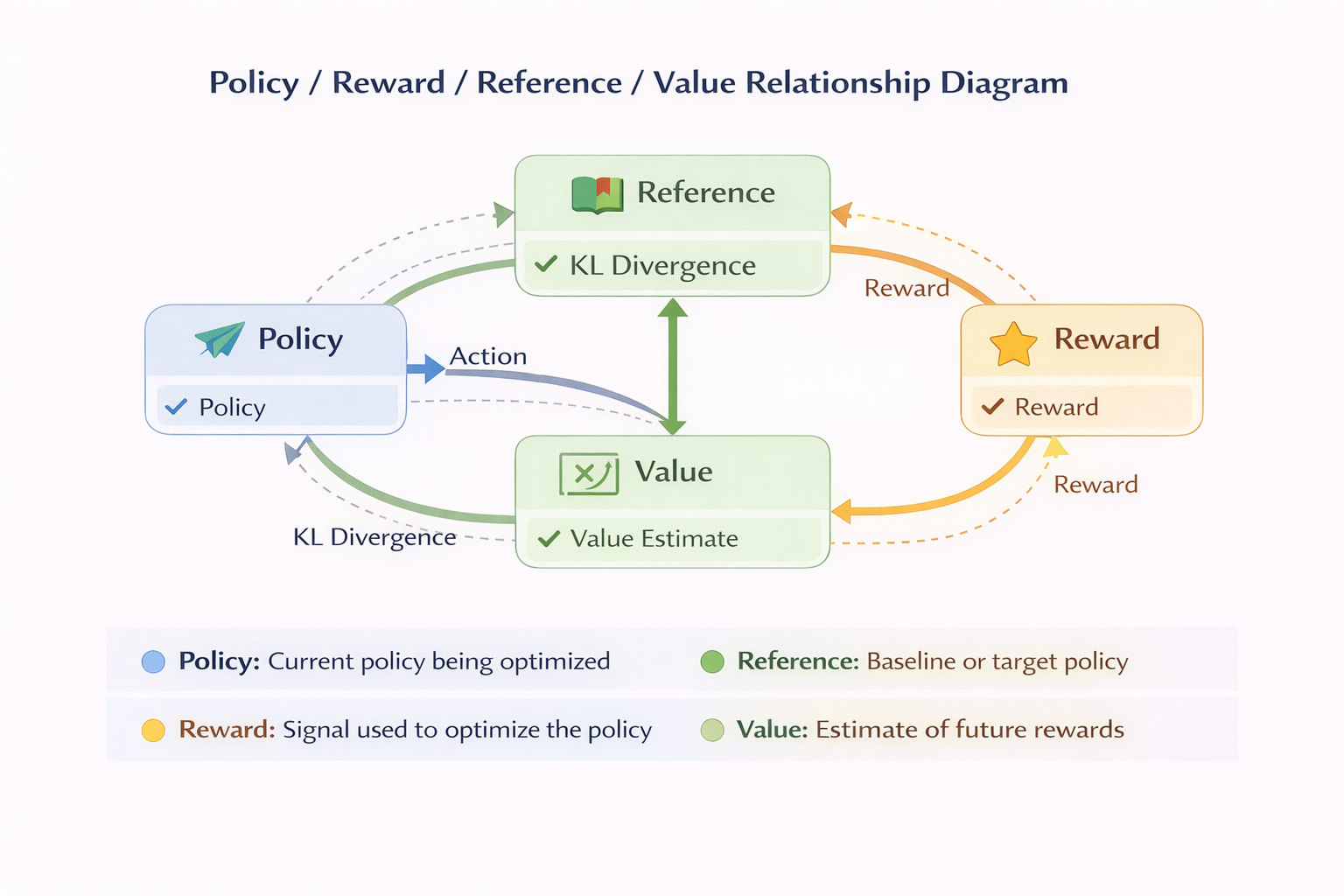
Policy / Reward / Reference / Value 關係圖
第一步:準備模型與 tokenizer(為什麼一定要保留 ref model)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("your_sft_model")
ref_model = AutoModelForCausalLM.from_pretrained("your_sft_model")
tokenizer = AutoTokenizer.from_pretrained("your_sft_model")
ref_model.eval()
for p in ref_model.parameters():
p.requires_grad = False
這裏有一個我必須強調的工程原則:
reference model 是 PPO 的“底線”。
沒有 ref model,你會遇到很多非常隱蔽的問題:
- reward model 再強,也遲早會被模型鑽空子
- 模型輸出會慢慢偏離正常語言分佈
- 原本 SFT 學到的能力,會在不知不覺中被破壞
説實話,我見過的不少 PPO 事故,追根溯源,幾乎都能回到這一點:
ref model 被弱化了,甚至被“順手一起訓了”。
第二步:生成 response(PPO 不穩定的第一個源頭)
和 supervised learning 不一樣,PPO 的訓練樣本並不是現成的數據集,而是模型自己生成的。
def generate_response(model, prompt_ids, max_new_tokens=128):
with torch.no_grad():
output = model.generate(
input_ids=prompt_ids,
max_new_tokens=max_new_tokens,
do_sample=True,
top_p=0.9,
temperature=1.0
)
return output
這裏有幾個非常現實、但經常被忽略的點:
- sampling 的隨機性,本質上就是 PPO 的探索噪聲
- temperature 太低,模型幾乎學不到新東西
- temperature 太高,reward 的方差會直接炸掉
如果是第一次跑 PPO,我的建議很保守:
- temperature 設成 1.0
- top_p 用 0.9
- 先別碰 beam search
第三步:Reward + KL(最容易“看起來對,其實用錯”的地方)
Reward Model 到底要多“準”?
很多人一上來就會糾結:
Reward Model 一定要非常準吧?
但在 PPO 裏,一個更現實的結論是:
reward 的排序性,遠比絕對值重要。
工程上我更關心的是:
- reward 分佈別太尖
- 不要大量 0 / 1 極值
- reward 有沒有無意中偏向長度或格式
KL 的作用,説白了就是“別把模型性格改沒了”
KL penalty 在 PPO 中真的不是裝飾品。
它更像是一根保險絲,用來防止模型在 reward 的驅動下“性格突變”。
def compute_kl(logits, ref_logits):
log_probs = torch.log_softmax(logits, dim=-1)
ref_log_probs = torch.log_softmax(ref_logits, dim=-1)
kl = torch.sum(
torch.exp(log_probs) * (log_probs - ref_log_probs),
dim=-1
)
return kl.mean()
幾個很實在的工程經驗:
- KL 通常只算 response 部分
- KL 的數值尺度會隨着詞表大小變化
- KL 一定要進監控,不然你根本不知道模型在不在“飄”
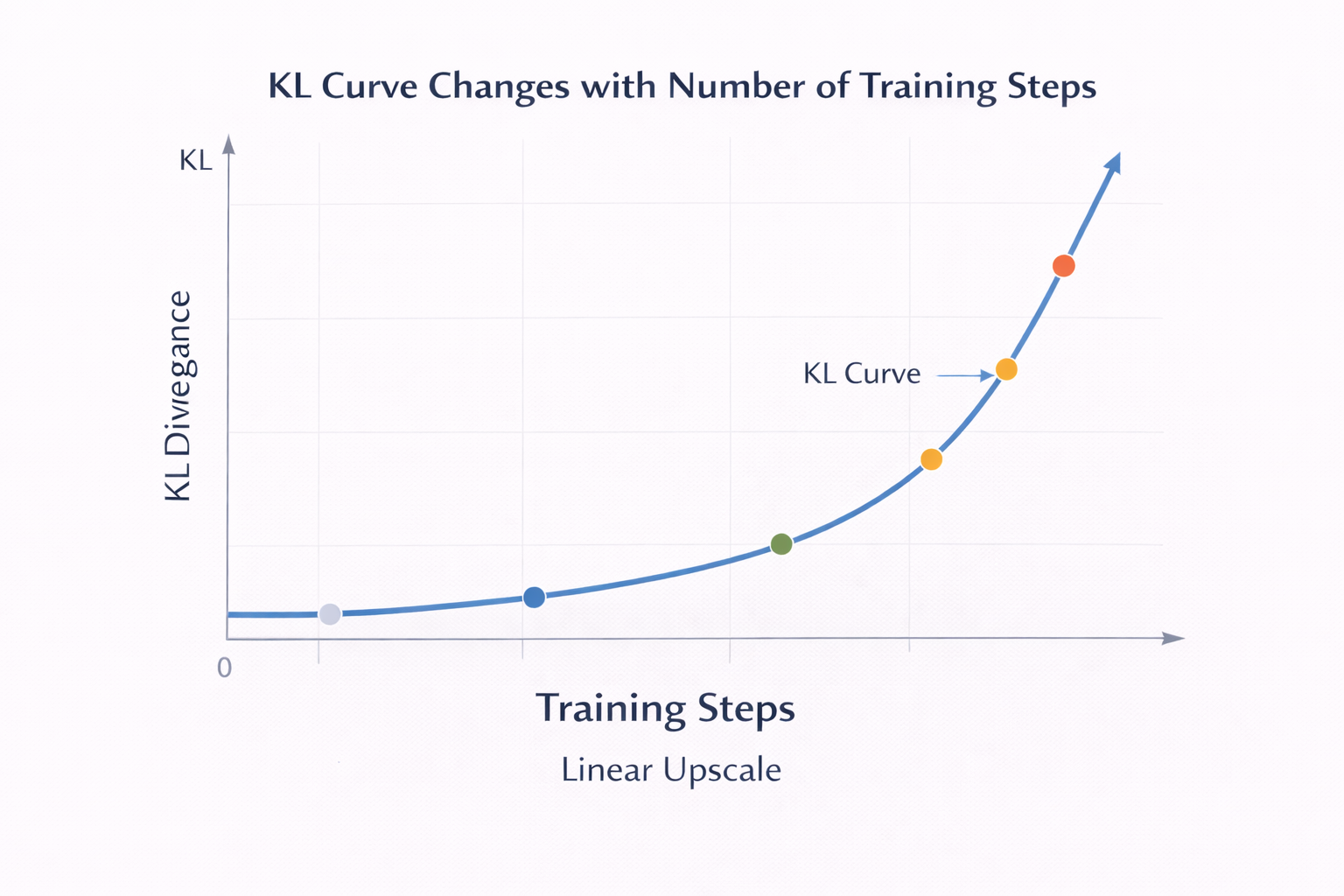
KL 曲線隨訓練步數變化
第四步:為什麼不能直接用 reward?(Advantage 的直覺解釋)
在 PPO 裏,reward 更像“結果”,而 advantage 更像“方向”。
最簡單、但在工程上能用的 advantage 寫法是:
advantage = total_reward - total_reward.mean()
它看起來確實有點粗糙,但解決了一個很關鍵的問題:
- 不讓所有樣本一起無腦推模型
- 強調“相對更好”的行為
這裏有個重要認知:
第一版 PPO,真的不需要一個很完美的 value model。
第五步:PPO loss(別被 loss 曲線騙了)
ratio = torch.exp(new_logprob - old_logprob)
clipped_ratio = torch.clamp(ratio, 1-eps, 1+eps)
loss = -torch.mean(
torch.min(ratio * advantage, clipped_ratio * advantage)
)
在工程裏你一定要知道:
- loss 降得慢,不等於訓練失敗
- loss 很平,也不代表模型沒在學
- PPO 的 loss 曲線,不能用 supervised learning 的思路去看
真正有價值的信號,其實是:
- KL 有沒有失控
- reward 是不是穩步提升
第六步:完整 PPO 更新循環(貼近真實 GPU 訓練)
for batch in prompts:
response = generate_response(model, batch)
reward = reward_model(response)
kl = compute_kl(
model_logits(response),
ref_model_logits(response)
)
total_reward = reward - beta * kl
advantage = total_reward - total_reward.mean()
for _ in range(ppo_epochs):
loss = ppo_loss(...)
loss.backward()
optimizer.step()
optimizer.zero_grad()
一些很“工程”的建議:
- PPO epoch 別太多,4 已經很激進了
- gradient clipping 基本是必選項
- advantage 最好 batch 內單獨算
如果你不想一開始就手寫所有 PPO 細節,LLaMA-Factory online 已經把 PPO + KL + Reward 的完整流程封裝好,用它先跑一條“參考答案”,再回頭對照自己的 PyTorch 實現,會省很多時間。
訓練中我最關心的幾個監控信號
真正成熟的 PPO 訓練,看的從來不只是一個 loss。
至少要包括這些:
- KL divergence
- reward 的均值和方差
- response 的平均長度
- logprob 的分佈變化
- 固定 prompt 下的輸出變化
- 人工抽樣的主觀質量
如果只能選一個重點盯:
盯 KL。
一些常見翻車現場(基本都是真實踩過的坑)
- reward 漲得很快,但模型開始胡説
通常是 KL 太小,加上 reward 太單一 - 模型輸出越來越短
先看看 reward 有沒有無意中懲罰長度 - 模型開始反覆輸出模板句
很可能是 reward model 偏向了某種模式 - 模型幾乎不動
要麼 KL 太大,要麼學習率被你壓得太死
進階但仍然安全的改進方向
當你已經能穩定跑通 PPO 之後,可以再考慮這些事情:
- KL 的自適應調節
- response length normalization
- reward clipping
- 加 value head(但一定要非常謹慎)
順序真的很重要:
永遠先穩,再談強。
寫在最後:我現在怎麼看 PPO
如果只總結三點經驗,那會是這樣:
第一,PPO 的核心不是把 reward 拉到多高,而是控制變化幅度
第二,KL 是 PPO 的靈魂,而不是可選項
第三,一版 PPO 是否成功,最現實的標準只有一個:
模型還像不像一個正常模型
在真實工程裏,很多團隊都會選擇這樣的路徑:
先用 LLaMA-Factory online 跑通一版穩定的 PPO,對齊整體流程,再把關鍵模塊逐步遷移到自研的 PyTorch 實現中。這條路不一定最優,但通常最穩。