

10 萬文檔 RAG 落地實戰:從 Demo 到生產,我踩過的所有坑
引言:RAG 為什麼在企業級場景“必選但難用”
在過去一年裏,RAG(Retrieval-Augmented Generation)幾乎成了企業落地大模型的標準配置。
原因很簡單:
- 企業數據高度私有,無法直接丟給大模型訓練
- 業務知識更新頻繁,微調成本高、週期長
- 需要“可控、可解釋、可追溯”的回答來源
但當你真的把 RAG 從 Demo 推到生產,會發現三個問題幾乎一定會出現:
- 文檔一多,檢索明顯變慢
- 明明文檔裏有答案,模型卻“搜不到”
- 本地 + 向量庫 + 模型 + 服務,部署複雜度飆升
這篇文章不會再重複“RAG 是什麼”這種內容,而是圍繞一個真實企業級目標展開:
在 10 萬級文檔規模下,如何構建一個可用、穩定、可擴展的 RAG 系統。
技術原理:先把“為什麼慢、為什麼不準”講清楚
RAG 的本質不是“問答”,而是信息檢索系統
很多人理解 RAG 是:
向量檢索 + 大模型生成
但在工程視角下,它更像一個搜索系統:
- 輸入是自然語言查詢
- 中間是召回 + 排序
- 輸出是可供生成模型使用的“證據集”
如果你做過搜索或推薦系統,會發現很多問題是相通的。

為什麼文檔一多,檢索就慢?
根本原因通常不是模型,而是三點:
- 向量數量膨脹,索引結構不合理
- embedding 維度過高,算力浪費
- 查詢階段做了太多不必要的全量掃描
在 10 萬文檔規模下,實際進入向量庫的 chunk 往往是 50 萬~300 萬級別。
如果你:
- 使用 Flat 索引
- embedding 維度 1024+
- 沒有分片或分區
那檢索慢幾乎是必然的。
為什麼召回率低,明明“文檔裏有答案”?
這是企業 RAG 最常見、也是最隱蔽的問題。
核心原因通常有四類:
- 文檔切分策略錯誤,語義被破壞
- embedding 模型不適合業務語料
- 查詢語句和文檔語義“不在一個空間”
- 只做向量召回,沒有關鍵詞兜底
很多團隊第一版 RAG 的失敗,並不是模型不行,而是檢索層根本沒把信息找對。
為什麼部署複雜,維護成本高?
因為 RAG 是一個系統工程:
- embedding 服務
- 向量數據庫
- 原始文檔存儲
- rerank / LLM 服務
- 權限、日誌、監控
如果每一層都是“隨便拼的”,後期幾乎無法維護。
實踐步驟:一套可支撐 10 萬+ 文檔的 RAG 工程方案
下面進入真正的實戰部分,我會按照真實項目的構建順序展開。
第一步:文檔預處理,比你想象中重要 10 倍
文檔清洗的三個工程原則
- 不要相信“原始文檔一定有用”
- 不要一次性全量入庫
- 文檔是會“進化”的
建議在入庫前至少做:
- 去除目錄、頁眉頁腳、免責聲明
- 合併被錯誤拆分的段落
- 統一編碼、符號、語言
Chunk 切分:不是越小越好
常見誤區是:
chunk 越小,檢索越準
在企業語料中,這往往是錯的。
推薦經驗區間:
- chunk 字數:300~800
- 保留 10%~20% overlap
- 按語義邊界切,而不是按字數硬切
示例(偽代碼):
chunks = semantic_split(
text,
max_tokens=600,
overlap=100
)
第二步:Embedding 模型選型與調優
不要盲選“排行榜第一”的 embedding
企業級場景更看重:
- 中文 / 行業語料適配度
- 向量維度 vs 性能
- 是否支持本地部署
實測經驗:
- 768 維往往是性價比最優點
- 高維模型在召回提升上收益遞減
- 行業語料 > 通用榜單指標
如果你需要快速定製 embedding 模型,而不想從零寫訓練代碼,可以考慮LLaMA-Factory Online用在線方式對 embedding 模型做領域適配,成本和風險都更可控。
第三步:向量庫不是“裝進去就完了”
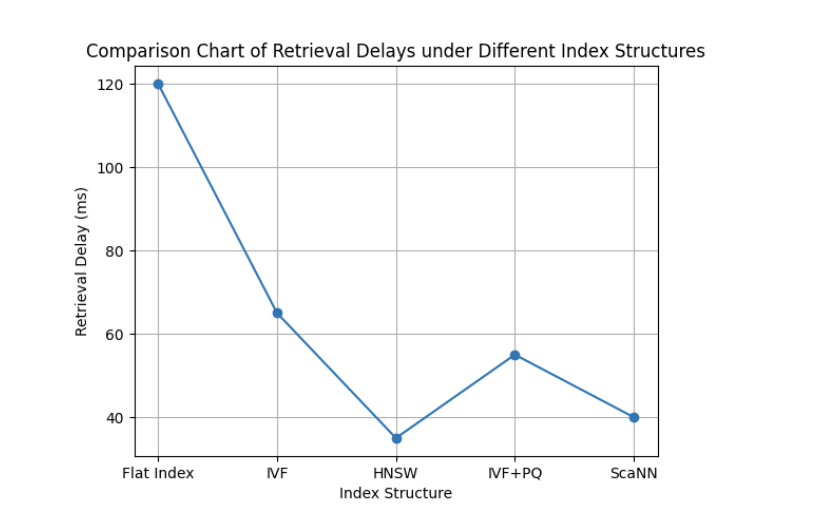
索引結構決定了 80% 的性能
在 10 萬+ 文檔規模下,強烈建議:
- 使用 HNSW / IVF-PQ
- 按業務或文檔類型分庫
- 定期重建索引
示例(FAISS):
index = faiss.index_factory(
dim,
"IVF4096,PQ64"
)
向量召回一定要“兜底”
純向量召回在企業場景一定不夠。
推薦組合策略:
- 向量召回 TopK
- BM25 / 關鍵詞召回
- 結果合併去重
這樣可以顯著減少“明明有卻搜不到”的情況。
第四步:Rerank 是企業 RAG 的分水嶺
如果説 embedding 決定“找不找得到”,
那 rerank 決定“用不用得上”。
建議:
- 向量召回 Top 50~100
- rerank 到 Top 5~10
- 再交給 LLM 生成
rerank 模型不需要很大,但一定要語義理解強。
第五步:生成階段要“約束模型,而不是相信模型”
企業級 RAG 中,生成階段要注意三點:
- 嚴格基於檢索內容回答
- 明確拒答策略
- 輸出可追溯引用
示例 Prompt 思路:
你只能基於提供的資料回答問題。
如果資料中沒有答案,請明確説明“資料不足”。
效果評估:RAG 好不好,不能只看“感覺”
必須量化的四個指標
- Recall@K(檢索層)
- MRR / NDCG(排序層)
- Answer Accuracy(人工或半自動評估)
- 延遲(P95 / P99)

一個實用的評估技巧
從真實業務中抽取:
- 高頻問題
- 長尾問題
- 模糊問題
做成固定評測集,每次改動都跑一遍。
總結與未來展望:RAG 會走向哪裏?
當你真的把 RAG 做到企業級,會發現一個結論:
RAG 的上限,取決於你對“檢索系統”的理解,而不是模型參數量。
未來 1~2 年,我認為企業級 RAG 會呈現三個趨勢:
- 檢索與生成進一步解耦
- 行業 embedding / rerank 成為標配
- RAG 與微調、Agent 深度融合
如果你正在做 RAG 的工程落地,建議儘早把模型訓練、評估、部署流程標準化。
像LLaMA-Factory Online這類工具,本質價值並不是“省幾行代碼”,而是降低試錯成本,讓工程團隊把精力放在真正重要的地方。
如果你願意,下一篇我可以繼續深入:
“RAG + 微調到底怎麼選?哪些場景 RAG 一定不夠?”