

微調完怎麼判斷好不好?大模型效果評估入門指南(附代碼)

(一)引言:微調評估不是“算個數”,是模型落地的關鍵一步
大家好,我是七七!每天都能看到一堆新手提問,核心就一個:“博主,我把7B模型微調完了,準確率82%,這效果算合格嗎?”“生成任務怎麼判斷模型調得好不好,總不能憑感覺吧?”
其實這也是我剛入門時踩過的坑——當時對着微調完的模型,只知道算個準確率就交差,結果落地到業務場景才發現,要麼“指標好看但用不了”(比如生成文本BLEU值高卻邏輯混亂),要麼“漏判關鍵樣本”(比如垃圾郵件識別召回率太低)。後來才明白,大模型微調評估從來不是“單一指標定生死”,而是要結合任務類型、業務需求,用科學的方法驗證效果。
今天這篇文章,就帶新手朋友從0到1搞懂大模型微調效果評估:拆解不同任務的核心指標,附Python實操代碼(複製就能跑),再教大家怎麼結合場景判斷效果,避開90%新手會踩的坑。不管你做文本分類、文本生成還是語言建模,都能直接套用這套方法。
(二)技術原理:不同任務的核心評估指標拆解
大模型微調任務主要分三類:文本分類(如垃圾郵件識別、情感分析)、文本生成(如摘要、對話、翻譯)、語言建模(如續寫、補全)。不同任務的評估邏輯完全不同,我們逐個拆解核心指標,用“案例+通俗解釋”講透,新手也能秒懂。
1. 文本分類任務:準確率、精確率、召回率、F1值
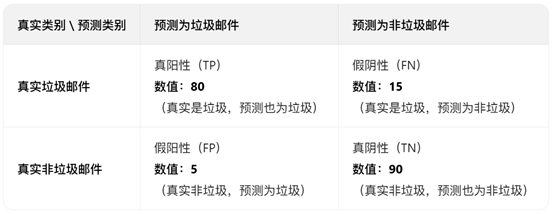
這類任務的核心是“給文本貼標籤”,評估的是模型“分類準不準”,最常用的就是這四個指標。我們以“垃圾郵件識別”為例(標籤:垃圾郵件/正常郵件),逐個解釋:
• 準確率(Accuracy):所有樣本中分類正確的比例,相當於“考試總分率”。公式:(正確識別的垃圾郵件+正確識別的正常郵件)/ 總郵件數。
•
• 適用場景:樣本分佈均衡(比如垃圾郵件和正常郵件各佔50%),追求整體分類正確率。
•
• 坑點:樣本不均衡時失效!比如垃圾郵件只佔10%,模型全預測為正常郵件,準確率也能到90%,但完全沒用。
• 精確率(Precision):模型預測為“垃圾郵件”的樣本中,真正是垃圾郵件的比例,相當於“預測對的垃圾郵件純度”。公式:正確識別的垃圾郵件 / 模型預測為垃圾郵件的總數量。
•
• 適用場景:怕誤判的場景(比如重要郵件不能被誤判為垃圾郵件),優先保證“預測對的都是真的”。
• 召回率(Recall):所有真實垃圾郵件中,被模型正確識別的比例,相當於“垃圾郵件的捕捉率”。公式:正確識別的垃圾郵件 / 真實存在的垃圾郵件總數量。
•
• 適用場景:怕漏判的場景(比如詐騙郵件不能漏判),優先保證“該抓的都抓到”。
• F1值:精確率和召回率的調和平均數,解決“精確率和召回率矛盾”的問題(比如精確率高則召回率低,反之亦然),綜合反映分類效果。
• 適用場景:大多數分類任務的核心評估指標,尤其樣本不均衡時,比準確率更靠譜。
一句話總結:準確率看整體,精確率防誤判,召回率防漏判,F1值看綜合,優先選F1值作為核心指標。
2. 文本生成任務:BLEU、ROUGE、人工評估
這類任務的核心是“生成符合要求的文本”,評估的是“生成內容與參考內容的一致性、流暢度”,自動指標+人工評估結合才靠譜。
• BLEU值(雙語評估替補):衡量生成文本與參考文本的“n-gram重疊度”(簡單説就是用詞、短語的重合率),取值0-1,越接近1效果越好。
•
• 適用場景:機器翻譯、摘要生成等有明確參考文本的任務。
• 坑點:只看重疊度,忽略語義和流暢度!比如生成文本和參考文本用詞完全一樣,但語序混亂,BLEU值也會很高,需結合人工判斷。
• ROUGE值(召回導向的評估指標):和BLEU類似,但從“召回率”角度計算重疊度,常用ROUGE-L(基於最長公共子序列,更貼合語義)。
•
• 適用場景:摘要生成、文本續寫,更關注“生成內容是否覆蓋參考文本的核心信息”。
• 人工評估:自動指標的補充,尤其生成對話、創意文本時(無固定參考),需制定評分標準,從“流暢度、邏輯性、相關性、準確性”四個維度打分(1-5分)。
一句話總結:BLEU看重疊度,ROUGE看信息覆蓋,人工評估定體驗,三者結合才能全面判斷生成效果。
3. 語言建模任務:困惑度(PPL)
這類任務的核心是“預測下一個詞的概率”(如文本續寫、補全),評估的是模型“對語言規律的掌握程度”,核心指標是困惑度。
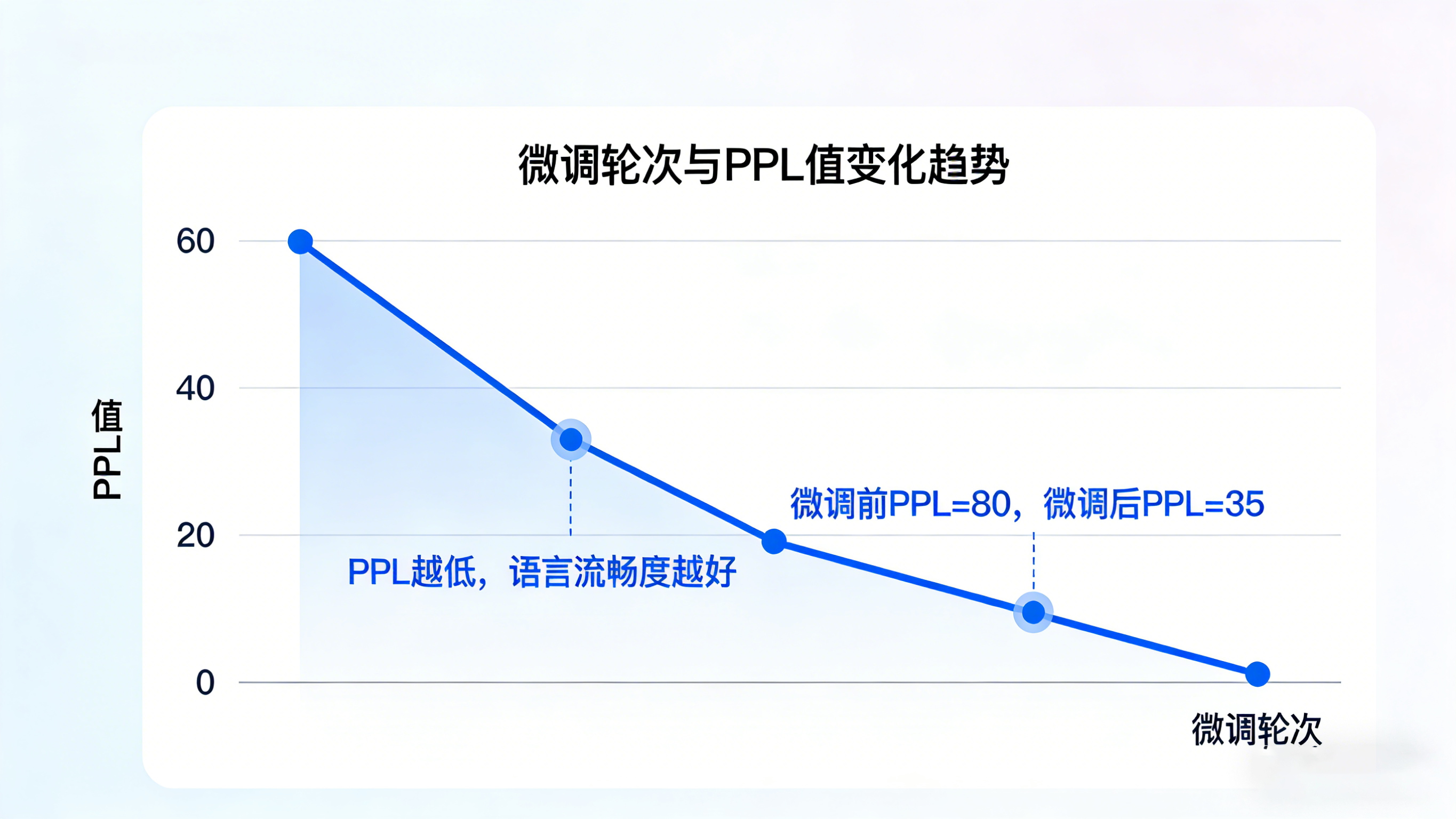
困惑度(Perplexity,PPL):通俗説就是“模型對文本的困惑程度”,PPL值越低,説明模型越能準確預測下一個詞,對語言的理解越透徹。
適用場景:文本續寫、語言生成預訓練微調後的效果評估。
注意:PPL值僅反映語言流暢度,不代表內容相關性,比如模型能生成流暢的句子,但和上下文無關,PPL值也可能很低。
(三)實踐步驟:手把手教你計算評估指標(附Python代碼)
本次實操覆蓋兩大核心任務:文本分類(情感分析)、文本生成(新聞摘要),使用Python常用庫(sklearn、nltk、transformers),代碼極簡且註釋詳細,新手複製就能跑。前置準備:安裝依賴庫,命令如下:
pip install sklearn nltk transformers datasets pandas
實操1:文本分類任務指標計算(情感分析案例)
任務描述:微調模型對電影評論進行情感分類(正面/負面),計算準確率、精確率、召回率、F1值,驗證微調效果。
• 步驟1:準備數據。模擬微調後的預測結果與真實標籤(實際場景中替換為你的模型預測結果和測試集標籤):
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
# 模擬數據:真實標籤(0=負面,1=正面)、模型預測標籤
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0] # 真實標籤
y_pred = [1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0] # 模型預測標籤
• 步驟2:計算核心指標。調用sklearn庫一鍵計算,指定標籤類型(binary=二分類):
# 計算指標
accuracy = accuracy_score(y_true, y_pred) # 準確率
precision = precision_score(y_true, y_pred, average='binary') # 精確率
recall = recall_score(y_true, y_pred, average='binary') # 召回率
f1 = f1_score(y_true, y_pred, average='binary') # F1值
conf_matrix = confusion_matrix(y_true, y_pred) # 混淆矩陣
# 打印結果
print(f"準確率:{accuracy:.4f}")
print(f"精確率:{precision:.4f}")
print(f"召回率:{recall:.4f}")
print(f"F1值:{f1:.4f}")
print("混淆矩陣:")
print(conf_matrix)
• 步驟3:結果解讀。運行代碼後輸出如下,結合業務分析效果:
準確率:0.8667
精確率:0.8889
召回率:0.8000
F1值:0.8421
混淆矩陣:
[[6 1]
[2 6]]
解讀:F1值0.8421,綜合效果良好;精確率0.8889(預測為正面的評論中88.89%是真正面),召回率0.8000(真實正面評論中80%被正確識別);若業務是“推薦正面評論”,可接受當前效果;若怕漏判正面評論,需優化提升召回率。
實操2:文本生成任務指標計算(新聞摘要案例)
任務描述:微調模型生成新聞摘要,計算BLEU、ROUGE值,搭配人工評估驗證效果。
• 步驟1:準備數據。模擬參考摘要(真實摘要)與生成摘要(模型輸出):
import nltk
from nltk.translate.bleu_score import sentence_bleu
from rouge import Rouge # 需額外安裝:pip install rouge
# 下載nltk依賴(首次運行需執行)
nltk.download('punkt')
# 模擬數據:參考摘要(可多個)、生成摘要
reference = [["人工智能", "技術", "正在", "改變", "各行各業"]] # 參考摘要(分詞後)
hypothesis = ["人工智能", "正在", "深刻", "影響", "各行業"] # 模型生成摘要(分詞後)
• 步驟2:計算BLEU、ROUGE值:
# 計算BLEU值(1-gram,適合短文本)
bleu1 = sentence_bleu(reference, hypothesis, weights=(1, 0, 0, 0))
print(f"BLEU-1值:{bleu1:.4f}")
# 計算ROUGE值
rouge = Rouge()
# 需將分詞結果拼接為字符串
hypothesis_str = " ".join(hypothesis)
reference_str = " ".join(reference[0])
scores = rouge.get_scores(hypothesis_str, reference_str)[0]
print(f"ROUGE-L精確率:{scores['rouge-l']['p']:.4f}")
print(f"ROUGE-L召回率:{scores['rouge-l']['r']:.4f}")
print(f"ROUGE-L F1值:{scores['rouge-l']['f']:.4f}")
• 步驟3:人工評估輔助。制定評分表,邀請2-3人打分,取平均值:
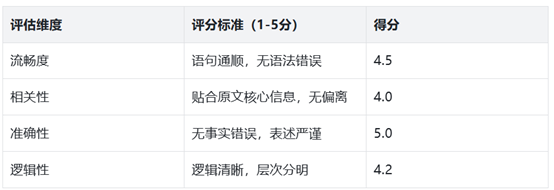
結果解讀:BLEU-1值0.6(重疊度中等),ROUGE-L F1值0.58(信息覆蓋中等),人工評分4.42(體驗良好),綜合判斷生成效果合格,可微調優化用詞準確性。
如果需要批量評估微調效果,手動寫代碼計算指標、整理結果很耗時,不妨試試LLaMA-Factory online。它能自動適配分類、生成等不同任務,一鍵計算準確率、F1、BLEU、ROUGE等核心指標,還能生成可視化評估報告,省去手動處理數據和調試代碼的麻煩,新手也能快速完成效果驗證。
(四)效果驗證:如何科學判斷微調模型是否達標?
光算出指標還不夠,還要結合“微調前後對比、業務場景、穩定性”三維驗證,避免“指標好看但不實用”的問題。
1. 微調前後指標對比
核心看“指標是否有明顯提升”,排除“微調無效”的情況。比如:
• 分類任務:微調前F1值0.65,微調後0.84,提升明顯,説明微調有效;
• 生成任務:微調前BLEU-1值0.3,微調後0.6,ROUGE-L F1值從0.35提升到0.58,同時人工評分提升1分以上,效果達標。
注意:若指標無提升甚至下降,需排查數據質量(如訓練集標註錯誤)、微調參數(如學習率過高)、模型適配性(如小模型適配複雜任務)。
2. 結合業務場景判斷
指標高低不是絕對的,要貼合業務需求。比如:
• 醫療文本分類(疾病診斷輔助):優先保證召回率(≥95%),哪怕精確率低一點,也要避免漏判疾病;
• 電商評論情感分析:優先保證F1值,平衡正面評論推薦準確率和負面評論捕捉率;
• 對話機器人生成:人工評分(流暢度、相關性)權重高於自動指標,畢竟用户體驗是核心。
3. 穩定性驗證
多次微調(3-5次),看指標是否穩定(波動≤2%),避免“單次微調運氣好”的情況。比如多次微調後F1值穩定在0.82-0.85,説明模型效果可靠;若波動超過5%,需優化訓練數據(增加數據量、清洗噪聲)或微調參數。
(五)總結與展望:評估是微調的“導航儀”,不是“終點線”
核心總結
今天給大家講透了大模型微調效果評估的入門方法,核心要點總結3點:
• 任務適配指標:分類任務優先F1值,生成任務結合BLEU、ROUGE與人工評估,語言建模看PPL值,不盲目追求單一指標;
• 實操核心:用sklearn、nltk等工具一鍵計算指標,步驟簡單,新手可直接套用代碼,關鍵在結果解讀與業務結合;
• 避坑關鍵:指標高≠效果好,需結合微調前後對比、業務需求、穩定性驗證,形成閉環。
其實評估的核心價值,是幫你找到微調的“優化方向”——比如F1值低是召回率不足,就調整數據增強策略;生成文本BLEU高但人工評分低,就優化模型生成邏輯。
如果想更高效地完成評估閉環,LLaMA-Factory online能幫上忙。它不僅能自動計算多類指標,還能對比多輪微調的效果差異,智能推薦優化方向(如調整學習率、補充訓練數據),無需手動記錄和分析,讓微調評估更高效,新手也能快速迭代模型。
最後問大家一個問題:你在微調時遇到過“指標好看但業務用不了”的情況嗎?是怎麼優化的?歡迎在評論區留言,我們一起拆解解決方案~ 關注我,帶你從入門到精通大模型微調全流程!