EMR Serverless Spark 是一款兼容開源 Spark 的高性能 Lakehouse 產品。它為用户提供任務開發、調試、發佈、調度和運維等全方位的產品化服務,顯著簡化了大數據計算的工作流程,使用户能更專注於數據分析和價值提煉。
StarRocks官方提供了Spark Connector用於Spark和StarRocks之間的數據讀寫,EMR Serverless Spark可以在開發時添加對應的配置連接StarRocks。本文為您介紹在EMR Serverless Spark中實現StarRocks的讀取和寫入操作。
EMR Serverless Spark 新用户可免費領取 1000 CU*小時 資源包,快速體驗 ETL 開發、任務調度、數據查詢與分析全流程。(鏈接:https://www.aliyun.com/product/emr/getting-started?utm_conten...)
前提條件
- 已創建Serverless Spark工作空間,詳情請參見創建工作空間。(鏈接:https://x.sm.cn/AN7vPD2)
- 已創建EMR Serverless StarRocks實例,詳情請參見創建實例。(鏈接:https://x.sm.cn/CAbeJiu)
使用限制
EMR Serverless Spark引擎的版本要求為esr-2.5.0、esr-3.1.0、esr-4.1.0及以上版本。
操作流程
步驟一:獲取 Spark Connector JAR 並上傳至OSS
- 參見使用Spark Connector讀取數據,選擇相應的方式下載對應版本的Spark Connector JAR。(鏈接:https://x.sm.cn/v4QPaz)
例如,本文選擇直接下載已經編譯好的JAR,即從Maven Central Repository獲取不同版本的Connector JAR包。(鏈接:https://x.sm.cn/DLYRbXP)
説明:Connector JAR包的命名格式為starrocks-spark-connec`tor-${spark_version}_${scala_version}-${connector_version}.jar**。例如,您使用的引擎版本為****esr-4.1.0 (Spark 3.5.2, Scala 2.12),想使用****1.1.2****版本的****Connector,則可以選擇**starrocks-spark-connector-3.5_2.12-1.1.2.jar`。
- 將下載的Spark Connector JAR上傳至阿里雲OSS中,上傳操作可以參見簡單上傳。(鏈接:https://x.sm.cn/AcdD9UZ)
步驟二:添加網絡連接
- 獲取網絡信息。
您可以在EMR Serverless Starrocks頁面,進入目標StarRocks實例的實例詳情頁面,以獲取該實例的專有網絡和交換機信息。(鏈接:https://x.sm.cn/D5dHUwu)
- 新增網絡連接。
- 在EMR Serverless Spark頁面,進入目標Spark工作空間的網絡連接頁面,單擊新增網絡連接。(鏈接:https://x.sm.cn/FLs7Nq)
- 在新增網絡連接對話框中,輸入連接名稱,並選擇之前獲取到的StarRocks實例的專有網絡和交換機信息,然後單擊確定。
更多網絡連接信息,請參見 EMR Serverless Spark與其他VPC間網絡互通。(鏈接:https://x.sm.cn/AURlOSD)
步驟三:在 StarRocks 中創建庫表
- 連接StarRocks實例,詳情請參見通過EMR StarRocks Manager連接StarRocks實例。(鏈接:https://x.sm.cn/JGSgejX)
- 在SQL Editor的查詢列表頁面,單擊文件或者右側區域的
圖標,然後單擊確認以新增文件。
- 在新增的文件中輸入以下SQL語句,單擊運行。
CREATE DATABASE `testdb`;
CREATE TABLE `testdb`.`score_board`
(
`id` int(11) NOT NULL COMMENT "",
`name` varchar(65533) NULL DEFAULT "" COMMENT "",
`score` int(11) NOT NULL DEFAULT "0" COMMENT ""
)
ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`);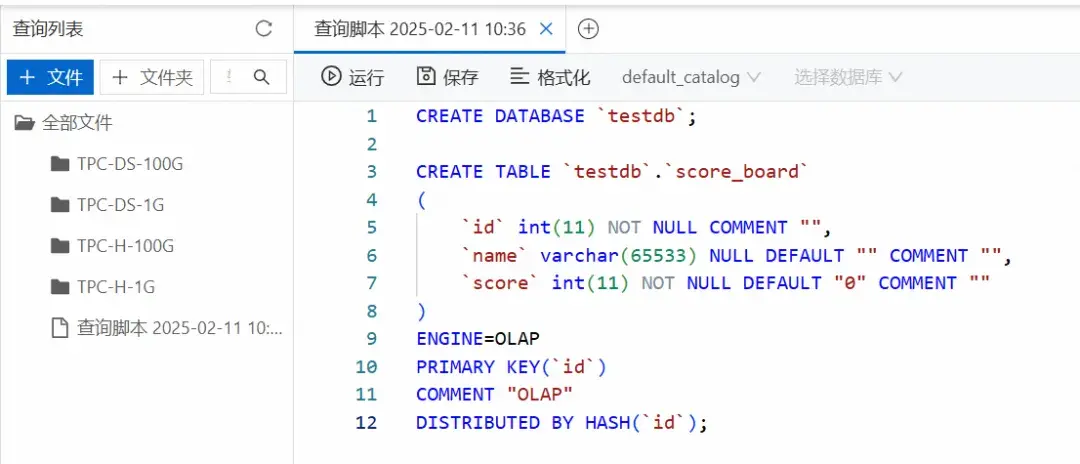
通過 Serverless Spark 讀寫 StarRocks
方式一:使用SQL會話、Notebook會話讀寫StarRocks
會話類型更多介紹,請參見會話管理。(鏈接:https://x.sm.cn/8MqzEJP)
SQL 會話
- 通過Serverless Spark向StarRocks寫入數據。
a. 創建SQL會話,詳情請參見管理SQL會話。(鏈接:https://x.sm.cn/CxvVvQR)
創建會話時,選擇與 StarRocks Connector 版本對應的引擎版本,在網絡連接中選擇上一步創建好的網絡連接,並在 Spark配置 中添加以下參數來加載Spark Connector。
spark.user.defined.jars oss://<bucketname>/path/connector.jar其中,oss://<bucketname>/path/connector.jar 為您步驟一中上傳至OSS的Spark Connector的路徑。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。
b. 在數據開發頁面,創建一個SQL > SparkSQL類型的任務,然後在右上角選擇創建好的SQL會話。更多操作,請參見SparkSQL開發。(鏈接:https://x.sm.cn/9rcGjIi)
c. 拷貝如下代碼到新增的SparkSQL頁籤中,並根據需要修改相應的參數信息,然後單擊運行。
CREATE TABLE score_board
USING starrocks
OPTIONS
(
"starrocks.table.identifier" = "testdb.score_board",
"starrocks.fe.http.url" = "<fe_host>:<fe_http_port>",
"starrocks.fe.jdbc.url" = "jdbc:mysql://<fe_host>:<fe_query_port>",
"starrocks.user" = "<user>",
"starrocks.password" = "<password>"
);
INSERT INTO `score_board` VALUES (1, "starrocks", 100), (2, "spark", 100);其中,涉及參數説明如下:
-
<fe_host>:Serverless StarRocks實例中FE的內網或公網地址。您可以在實例詳情頁面的FE詳情區域查看。- 如果使用內網地址,請確保在同一VPC內。
- 如果使用公網地址,需確保安全組規則允許相應的端口通信,詳情請參見網絡訪問與安全設置。(鏈接:https://x.sm.cn/ApMsVuF)
<fe_http_port>:Serverless StarRocks實例中FE的HTTP端口(默認為8030)。您可以在實例詳情頁面的FE詳情區域查看。<fe_query_port>:Serverless StarRocks實例中FE的查詢端口(默認為9030)。您可以在實例詳情頁面的FE詳情區域查看。<user>:Serverless StarRocks實例的用户名。默認提供admin用户,具有管理員權限。您也可以通過用户管理頁面新增用户來連接。新增用户操作,請參見管理用户及數據授權。(鏈接:https://x.sm.cn/AiIP1PP)<password>:用户<user>對應的密碼。
- 通過Serverless Spark查詢寫入的數據。
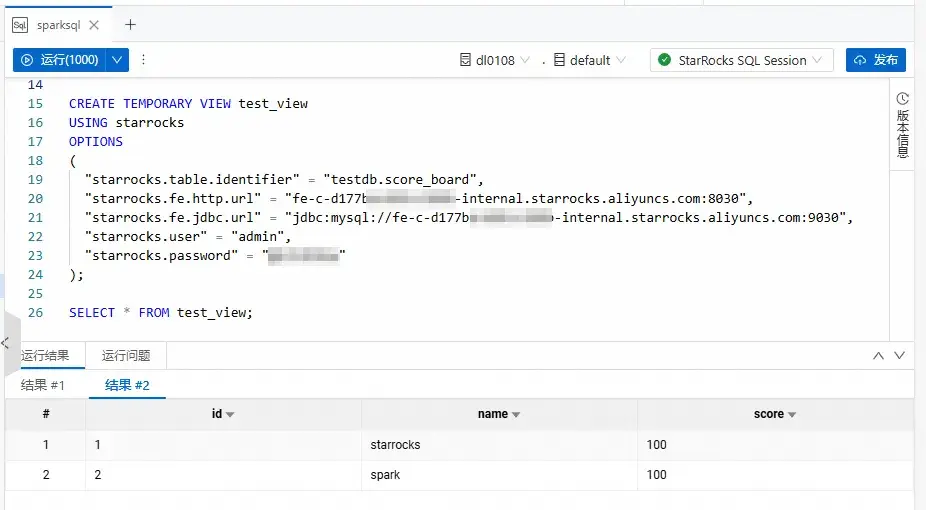
在本文示例中,我們是在上述的SparkSQL任務中創建了一個臨時視圖 test_view,然後通過該視圖查詢 score_board 表的數據。拷貝如下代碼到新增的SparkSQL頁籤中,選中代碼後單擊運行選中。
CREATE TEMPORARY VIEW test_view
USING starrocks
OPTIONS
(
"starrocks.table.identifier" = "testdb.score_board",
"starrocks.fe.http.url" = "<fe_host>:<fe_http_port>",
"starrocks.fe.jdbc.url" = "jdbc:mysql://<fe_host>:<fe_query_port>",
"starrocks.user" = "<user>",
"starrocks.password" = "<password>"
);
SELECT * FROM test_view;返回信息如下圖所示。
Notebook 會話
- 通過Serverless Spark向StarRocks寫入數據。
a. 創建Notebook會話,詳情請參見管理Notebook會話。(鏈接:https://x.sm.cn/DZ8b4bR)
創建會話時,選擇與StarRocks Connector版本對應的引擎版本,在網絡連接中選擇上一步創建好的網絡連接,並在Spark配置中添加以下參數來加載Spark Connector。
spark.user.defined.jars oss://<bucketname>/path/connector.jar其中,oss://<bucketname>/path/connector.jar為您步驟一中上傳至OSS的Spark Connector的路徑。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。
b. 在數據開發頁面,選擇創建一個Python > Notebook類型的任務,然後在右上角選擇創建的Notebook會話。
更多操作,請參見管理Notebook會話。
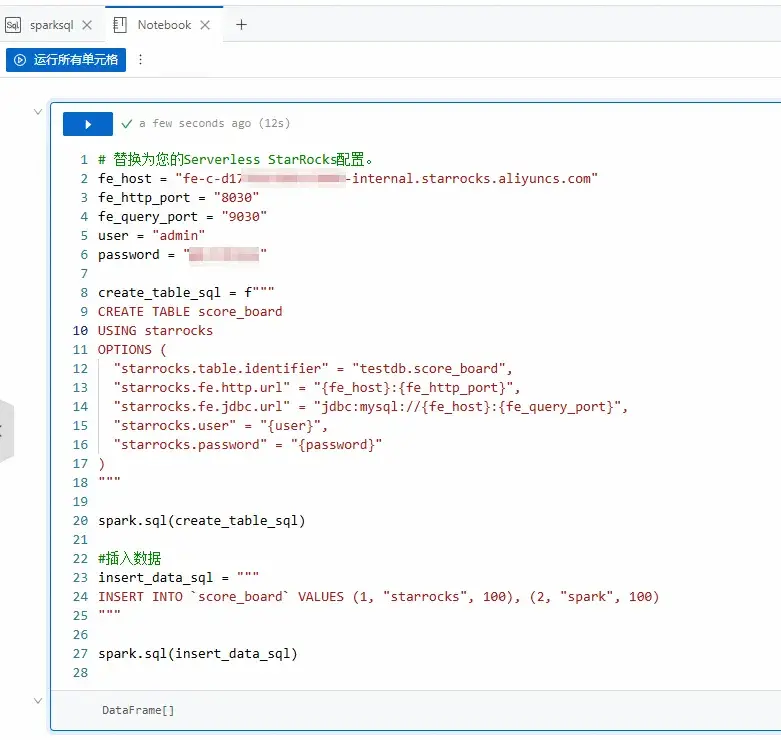
c. 拷貝如下代碼到新增的Notebook的Python單元格中,單擊運行。
# 替換為您的Serverless StarRocks配置。
fe_host = "<fe_host>"
fe_http_port = "<fe_http_port>"
fe_query_port = "<fe_query_port>"
user = "<user>"
password = "<password>"
# 創建表
create_table_sql = f"""
CREATE TABLE score_board
USING starrocks
OPTIONS (
"starrocks.table.identifier" = "testdb.score_board",
"starrocks.fe.http.url" = "{fe_host}:{fe_http_port}",
"starrocks.fe.jdbc.url" = "jdbc:mysql://{fe_host}:{fe_query_port}",
"starrocks.user" = "{user}",
"starrocks.password" = "{password}"
)
"""
spark.sql(create_table_sql)
#插入數據
insert_data_sql = """
INSERT INTO `score_board` VALUES (1, "starrocks", 100), (2, "spark", 100)
"""
spark.sql(insert_data_sql)填寫示例如下圖所示。
其中,涉及參數説明如下:
-
<fe_host>:Serverless StarRocks實例中FE的內網或公網地址。您可以在實例詳情頁面的FE詳情區域查看。- 如果使用內網地址,請確保在同一VPC內。
- 如果使用公網地址,需確保安全組規則允許相應的端口通信,詳情請參見網絡訪問與安全設置。(鏈接:https://x.sm.cn/BMpwm94)
<fe_http_port>:Serverless StarRocks實例中FE的HTTP端口(默認為8030)。您可以在實例詳情頁面的FE詳情區域查看。<fe_query_port>:Serverless StarRocks實例中FE的查詢端口(默認為9030)。您可以在實例詳情頁面的FE詳情區域查看。<user>:Serverless StarRocks實例的用户名。默認提供admin用户,具有管理員權限。您也可以通過用户管理頁面新增用户來連接。新增用户操作,請參見管理用户及數據授權。(鏈接:https://x.sm.cn/AiIP1PP)<password>:用户<user>對應的密碼。
- 通過Serverless Spark查詢寫入的數據。
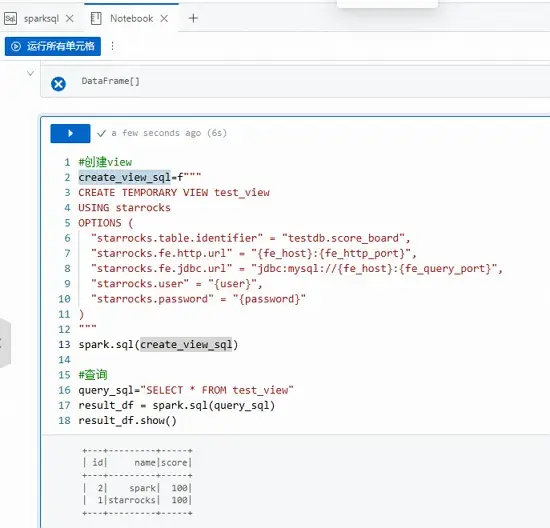
在本文示例中,我們新增一個Python單元格,在其中創建了一個臨時視圖 test_view,然後通過該視圖查詢 score_board 表的數據。拷貝如下代碼到新增的Python單元格中,然後單擊運行圖標。
#創建view
create_view_sql=f"""
CREATE TEMPORARY VIEW test_view
USING starrocks
OPTIONS (
"starrocks.table.identifier" = "testdb.score_board",
"starrocks.fe.http.url" = "{fe_host}:{fe_http_port}",
"starrocks.fe.jdbc.url" = "jdbc:mysql://{fe_host}:{fe_query_port}",
"starrocks.user" = "{user}",
"starrocks.password" = "{password}"
)
"""
spark.sql(create_view_sql)
#查詢
query_sql="SELECT * FROM test_view"
result_df = spark.sql(query_sql)
result_df.show()返回信息如下圖所示。
**方式二:使用 Spark 批任務讀寫 StarRocks
-
創建Spark批任務。
a. 在EMR Serverless Spark頁面,單擊左側的數據開發。
b. 在開發目錄頁簽下,單擊運行圖標。
c. 在新建對話框中,輸入名稱,類型選擇批任務 > SQL,然後單擊確定。
類型您可以根據實際情況進行調整,本文以SQL為例。更多類型參數介紹,請參見Application開發。(鏈接:https://x.sm.cn/HUsOvJI)
- 通過Spark批任務讀寫StarRocks。
a. 在新建的任務開發的右上角選擇隊列。
添加隊列的具體操作,請參見管理資源隊列。(鏈接:https://x.sm.cn/2xTsBdJ)
b. 在新建的任務開發中,配置以下信息,其餘參數無需配置,然後單擊運行。
| 參數 | 説明 |
|---|---|
| SQL文件 | 本示例所使用的文件為spark_sql_starrocks.sql,其內容是SQL會話中的SQL語句,請根據實際情況對具體配置進行替換。在使用之前,您需要先下載該文件並進行相應的修改,然後在文件管理頁面進行上傳。(鏈接:https://x.sm.cn/AhcNaCt)<br/>spark_sql_starrocks.sql參數説明:<br/>+ <fe_host>:Serverless StarRocks實例中FE的內網或公網地址。您可以在實例詳情頁面的FE詳情區域查看。<br/> - 如果使用內網地址,請確保在同一VPC內。<br/> - 如果使用公網地址,需確保安全組規則允許相應的端口通信,詳情請參見網絡訪問與安全設置。(鏈接:https://x.sm.cn/BMpwm94)<br/>+ <fe_http_port>:Serverless StarRocks實例中FE的HTTP端口(默認為8030)。您可以在實例詳情頁面的FE詳情區域查看。<br/>+ <fe_query_port>:Serverless StarRocks實例中FE的查詢端口(默認為9030)。您可以在實例詳情頁面的FE詳情區域查看。<br/>+ <user>:Serverless StarRocks實例的用户名。默認提供admin用户,具有管理員權限。您也可以通過用户管理頁面新增用户來連接。新增用户操作,請參見管理用户及數據授權。(鏈接:https://x.sm.cn/BrfbZoN)<br/>+ <password>:用户 <user> 對應的密碼。 |
| 引擎版本 | 選擇與Spark Connector版本對應的引擎版本。 |
| 網絡連接 | 選擇前一步創建好的網絡連接。 |
| Spark 配置 | 在Spark配置中添加以下參數來加載Spark Connector。 <br/>plain spark.user.defined.jars oss://<bucketname>/path/connector.jar 其中,oss://<bucketname>/path/connector.jar為您步驟一中上傳至OSS的Spark Connector的路徑。例如,oss://emr-oss/spark/starrocks-spark-connector-3.5_2.12-1.1.2.jar。 |
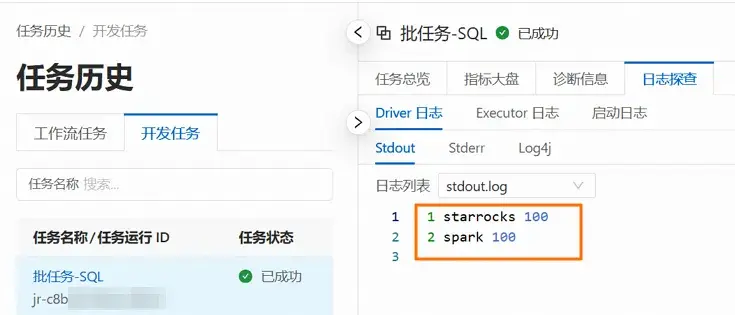
- 查看日誌信息。
a. 您可以在下方的運行記錄區域,單擊操作列的詳情。
b.單擊日誌探查頁籤,查看該任務的日誌信息。