

作者:玄橙 - 阿里雲 EMR Serverless Spark 產品專家
EMR Serverless Spark 是一款面向 Data+AI 的高性能 Lakehouse 產品。它為企業提供了一站式的數據平台服務,包括任務開發、調試、調度和運維等,極大地簡化了數據處理和模型訓練的全流程。同時,它100%兼容開源 Spark 生態,能夠無縫集成到客户現有的數據平台。使用 EMR Serverless Spark,企業可以更專注於數據處理分析和模型訓練調優,提高工作效率。今天我將從業務痛點、產品定位、產品介紹以及客户案例四個部分詳細介紹一下 EMR Serverless Spark 這款產品。
業務痛點
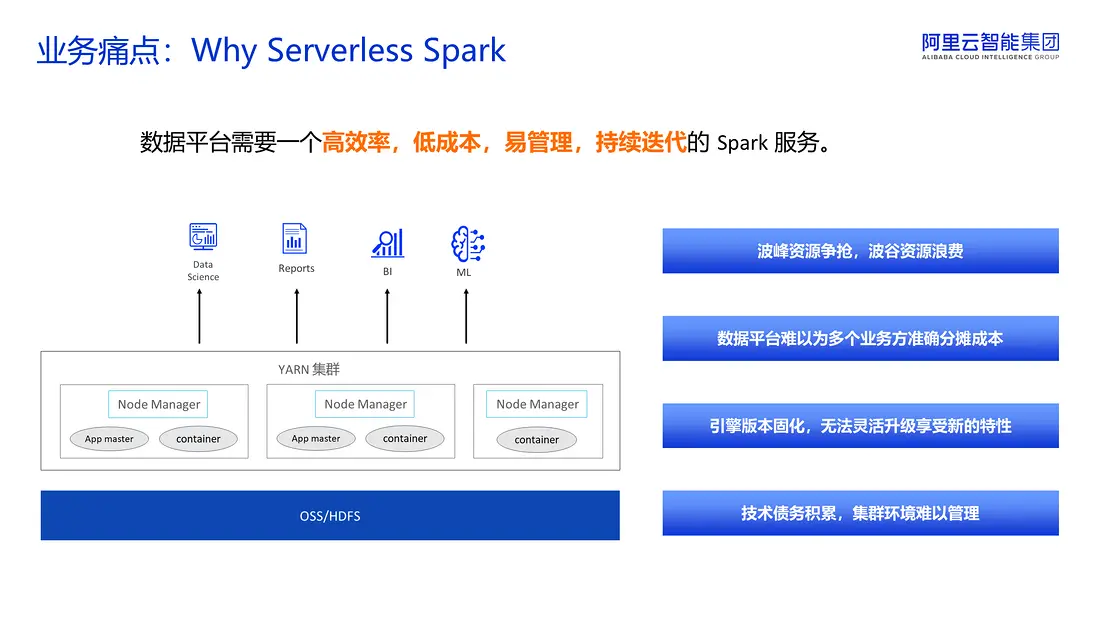
在服務了多家企業後,我們總結了共享集羣的一些關鍵痛點。當業務部門同時提交報表生成、BI查詢和模型訓練任務時,原有的 YARN 集羣將面臨多重挑戰。首先,資源爭搶會導致關鍵任務的延遲,業務方會抱怨數據產出不及時,而在波谷時段又會出現大量資源閒置,但我們仍需為這些閒置資源付費。這種共享集羣環境較為脆弱,一旦某個任務失控,可能會導致整個平台癱瘓。其次,這樣的集羣不利於成本分攤,數據平台難以精確統計各個業務方的資源使用量和成本數據。此外,如果想利用 Spark 的最新特性,通常需要進行停機遷移,但這在我們的業務窗口內是不可接受的。對於這種難以維護且升級的集羣,隨着長期累積的補丁,後期幾乎沒有人敢對其進行改動。因此,我們認為數據平台需要一個高效率、低成本、易於管理和持續迭代的 Spark 服務。
產品定位
當前,傳統數據架構的侷限性日益顯著,行業正加速向更高效、更靈活的現代化架構升級。
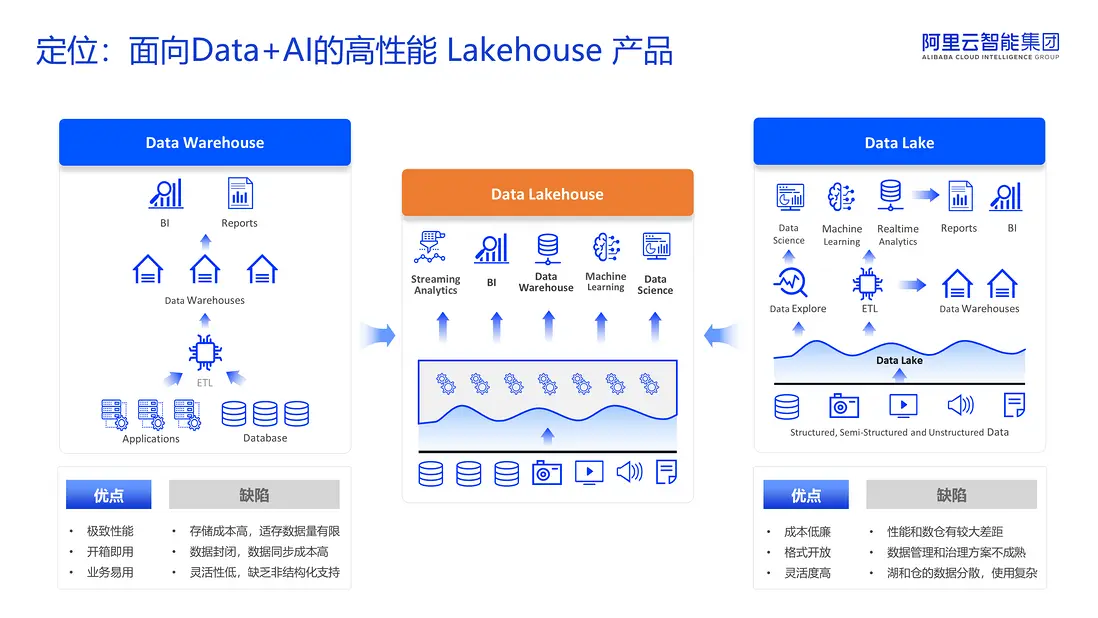
傳統數據倉庫具備結構化數據處理和開箱即用的優勢,但其存儲成本高、數據開放性不足、靈活性有限,限制了企業的擴展能力。尤其在多場景混合負載(如離線分析、實時計算)環境下,頻繁的數據遷移與ETL流程進一步增加了系統複雜度和運維負擔。
與此同時,隨着非結構化數據的快速增長,基於對象存儲的數據湖架構憑藉其低成本、高擴展性和開放格式等優勢得到廣泛應用。然而,數據湖在事務一致性、查詢性能等方面仍存在不足,難以完全替代數據倉庫的核心能力。
為平衡性能與靈活性,企業通常採用“湖倉分治”的混合架構——將高價值、穩定型業務部署於數據倉庫,而將探索性、高靈活性的業務運行在數據湖中。但這種模式帶來了數據冗餘、一致性維護等挑戰,增加了系統的複雜性和管理成本。
在 AI 應用普及的新時代背景下,可以預見未來幾年內,應用領域的變化將會異常迅速。繼續沿用舊模式已不再可行,因為這會導致極高的成本支出和難以應對的業務複雜度。因此,融合數據湖與數據倉庫優點的數據湖倉架構成為了發展的必然趨勢。該架構在數據湖的基礎上進行了優化,同時具備了數據倉庫的能力。
為此,阿里雲推出了 EMR Serverless Spark,提供了一個全面整合數據湖倉的解決方案,在保持數據湖開放性的同時,賦予其數倉的強大性能,助力企業構建面向未來的數據基礎設施。
EMR Serverless Spark 在多個關鍵場景中提供了支持。首先,針對數據倉庫,即結構化數據處理場景,EMR Serverless Spark 提供了一種高度優化的 Spark 引擎作為分佈式處理引擎,以替代傳統 Hive,從而實現高性能數倉。這一方案不僅涵蓋了 ETL 和 ELT,還支持實時流計算。此外,相較於Trino,我們的 Fusion 引擎在進行交互式查詢時能夠提供更高的性價比。其次,在傳統機器學習領域,Spark 作為一個成熟的分佈式機器學習框架,被廣泛應用於數據清洗、特徵工程、模型訓練、批量推理、數據科學等場景。最後,在大模型文本處理場景,針對非結構化數據處理,PySpark 作為一個成熟的分佈式 Python 框架,展現了其獨特的優勢。無論是多模態文本、圖像還是視頻數據,PySpark 都能夠提供高併發、高吞吐量且靈活的處理能力。

產品介紹
產品架構
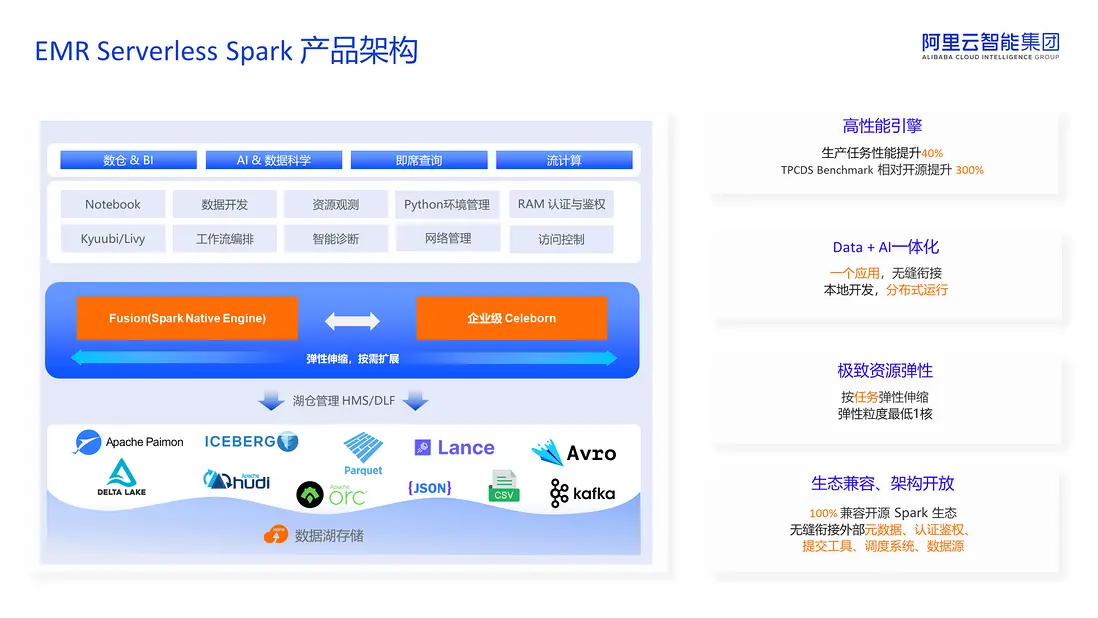
EMR Serverless Spark 是一款專為現代數據處理場景設計的全託管服務,其核心優勢在於極致的彈性、高性能和開放生態,覆蓋了從數據倉庫、BI 分析到 AI 科學的全場景需求。下圖展示了它的四層架構。
首先第一層架構是全場景的覆蓋,致力於滿足多樣化的數據需求。首先是數倉和 BI 分析,通過 SQL Editor 提供低門檻的數據查詢和報表開發,兼容傳統數倉場景。對於AI與數據科學,我們集成了 Notebook,支持 Python 環境管理和交互式機器學習開發。這一層的設計理念是實現一個平台,多個場景的融合,用户無需切換工具即可完成從數據分析到模型訓練的全過程。
第二層是平台功能,主要是為上層場景提供支撐,通過工作流編排實現批處理、流計算以及AI作業多場景的混合調度。無論是 ETL 任務、實時分析還是機器學習訓練,均可在一個 pipeline 中完成編排,從而避免多系統割裂的問題。同時所有操作均可通過 RAM 認證和鑑權,細粒度地控制對資源、數據及功能的訪問權限,確保企業級安全。此外, SQL Editor 和 Notebook 分別優化了數據倉庫和 AI 開發體驗,同時 Notebook、kyuubi 以及 livy 服務為開發者提供了靈活的編程接口和任務提交服務。
由於靈活的調度需求對底層引擎性能和彈性提出了更高要求,因此第三層為核心引擎層,它由兩大技術組成。首先是 Fusion 引擎,針對 CPU 密集型場景,提供基於 C++ 的向量化 SQL 引擎。相較於JVM,Fusion 引擎能更充分利用 SIMD 指令集,在提高 CPU 利用率的同時降低內存開銷。在 TPC-DS 基準測試中,相對於開源版本,Fusion 引擎實現了300%的性能提升。針對 IO 密集型場景,我們提供了企業級的 Celeborn 服務。Celeborn 是由阿里雲 EMR 團隊主導並捐獻給 Apache 社區的Remote Shuffle Service。在開源基礎上,企業級 Celeborn 支持多租户和資源隔離,並提供資源彈性實現 IO 密集型業務的加速。在彈性伸縮能力的支持下,這兩項技術能夠動態適配資源需求,最低支持單核級別的擴縮容,實現資源零浪費。
第四層是湖倉存儲層,這是 EMR Serverless Spark 實現湖倉一體願景的核心,基於開放數據湖格式Paimon 和 Iceberg,在保留數據湖靈活性的同時,賦予了傳統數倉的關鍵能力,如 ACID 事務、高效的數據 Upsert 以及完整的血緣記錄等。
通過這四層架構,EMR Serverless Spark 實現了以全場景覆蓋為切入點,以平台能力為支撐,基於高性能引擎,最終為用户提供了一個完整的 Lakehouse 解決方案。
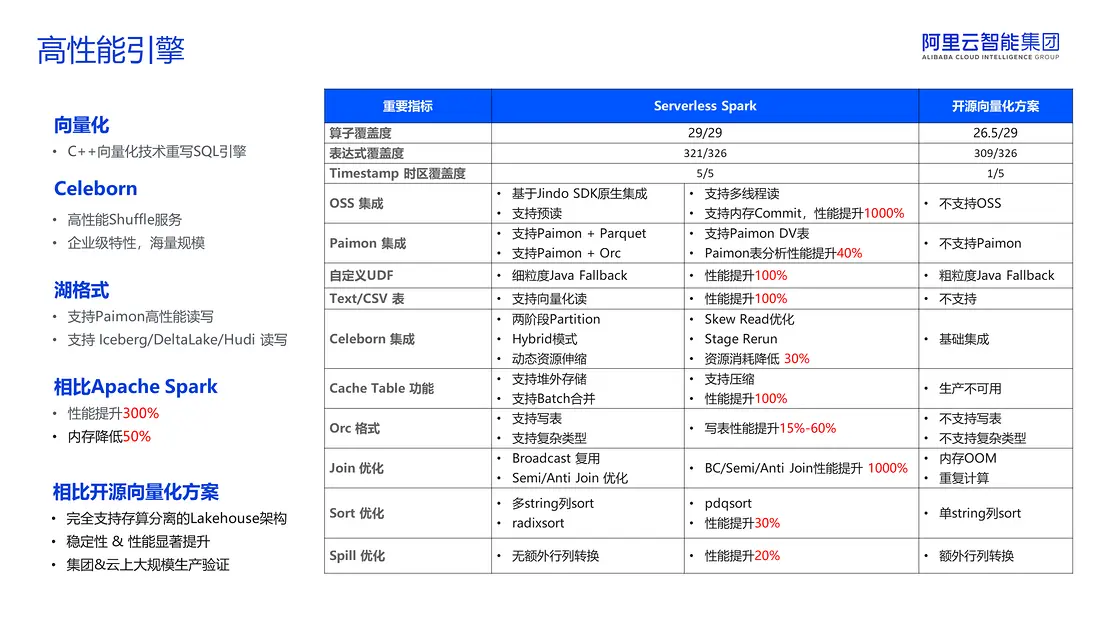
在性能引擎方面,前面提到我們採用了 C++ 向量化技術重寫了 SQL 引擎。儘管開源領域也存在類似的解決方案,但通過下圖右側的對比表格可以清晰地看出,EMR Serverless Spark 在各個關鍵指標上均顯著優於開源方案。具體而言,我們的算子、表達式和 TimeStamp 時區覆蓋度都更廣泛,並且在湖倉存儲方面深度集成了阿里雲 OSS 和湖表格式 Paimon。此外,我們在 Cache Table、Join、Spill 等方面也進行了不同程度的優化。
下圖清晰展示了我們的自研 Fusion 引擎在10TB規模 TPC-DS 基準測試中的表現。與開源 Spark 相比,EMR Serverless Spark 實現了平均5倍的性能提升。從圖上可以直觀地看到,每條查詢的耗時顯著降低,部分查詢的性能優勢尤為明顯。這意味着,在相同的計算任務下,EMR Serverless Spark 的耗時僅為開源 Spark 的20%。這不僅帶來了更快的數據處理速度和業務洞察力,還大幅降低了計算成本。無論是實時數倉還是交互式分析場景,Fusion 引擎都能為用户提供極致的性能體驗。

展開介紹一下 Fusion 引擎與 Apache Paimon 的深度集成。Paimon 是由阿里雲孵化並且大力推廣的數據湖存儲,在阿里雲公有云和國內多家公司廣泛部署並生產落地,助力客户實現了 Lakehouse架構的升級。Fusion 引擎在性能、功能以及生態等多個維度,都對 Paimon 進行了深度的集成和優化。
首先在性能方面,Fusion 引擎支持 Paimon 向量化讀寫,避免了 JVM 和 Native 環境之間數據行列轉換的開銷,顯著提升了讀寫性能。具體而言,讀取性能提高了70%,寫入性能提高了30%。此外,Paimon 引入了 Deletion Vector 模式,通過 DV 文件標記刪除和更新的數據,平衡了不同表類型之間的讀寫性能。Fusion 引擎同樣支持 Paimon DV 表的查詢,極大地提升了 Paimon MOR 表的查詢效率。Paimon 也深度集成了 EMR Serverless Spark 多項查詢優化,包括列裁剪,CTE 以及廣播重用等。相較於社區版本還額外支持了 Spark data Source V2 語法,提高了易用性。
在生態方面 Paimon 與阿里雲數據湖構建 DLF 元數據服務和對象存儲 OSS 實現了更好的適配。例如,DLF 2.5全面支持全託管 Paimon,實現了自動化的湖表管理。針對數據在 OSS 的場景,結合JindoFS 訪問 Paimon,提供了更優的訪問性能。值得一提的是,Paimon 社區的 Spark 生態建設由阿里雲 EMR Serverless Spark 團隊主導,所以會確保最新的特性和問題修復能夠及時體現在產品中。
去年,EMR Serverless Spark 進行了一項技術挑戰,使用 EMR Serverless Spark 產品結合 Paimon 打榜 100TB TPC-DS 基準測試,結果顯示,在關鍵指標上較當前榜首有一倍性能提升。

接着分享下 EMR Serverless Spark For AI 場景。一個典型的 AI 工作流,主要包括數據預處理,特徵工程、模型訓練和推理四個環節。EMR Serverless Spark 在這些環節都提供了支持,特別對 Python 生態有較好的兼容性。
在數據預處理階段,EMR Serverless Spark 允許數據科學家繼續使用他們熟悉的 Pandas 庫進行數據清洗和探索,同時能夠直接調用 NumPy 實現高效的數值計算。所有 Python 代碼都能自動獲得分佈式執行的能力,無需重寫。此外,EMR Serverless Spark 支持 Notebook 交互式開發,保留用户原有的工作習慣。對於多模態數據類型(如文本、圖像和視頻),EMR Serverless Spark 提供了相應的第三方庫來處理這些非結構化數據,並針對大模型場景也提供了高性能的文本分詞和去重能力。
在機器學習訓練方面,EMR Serverless Spark 內置了原生的分佈式 MLlib 算法庫,覆蓋了分類、迴歸、聚類等常見任務。同時還深度集成了 XGboost、LightGBM 等主流框架,並保持了與 Scikit-learn 生態的兼容性。對於需要精細調優的場景,平台整合了 Optuna 等自動化工具,幫助開發者高效優化模型參數。
針對深度學習訓練,EMR Serverless Spark 提供了靈活的訓練方案,支持使用 PyTorch、TensorFlow 和 Keras 等單機訓練框架。也支持通過 TorchDistributor 等分佈式接口實現多機訓練。特別是在分佈式訓練場景下,平台提供了高併發、高穩定的運行環境,確保長時間訓練任務的可靠性。
在模型推理階段,EMR Serverless Spark 支持分佈式推理和批量推理,能夠高效處理海量數據的預測需求。針對當前大模型的應用趨勢,平台提供了批量調用大模型 API 的能力,方便開發者集成最新的 AI 服務。這些能力建立在 Spark 成熟的分佈式架構之上,既保留了原有生態系統的使用習慣,又提供了企業級的生產力支撐。

LLM 數據預處理首選 Spark 已經成為業界主流方案。EMR Serverless Spark for AI 的一大優勢在於,其提供了靈活的 Python 環境管理,支持作業力粒度的鏡像運行和環境依賴,用户可以以聲明式的方式定義 Python 環境及其依賴項。

EMR Serverless Spark 平台的核心能力在於其極致的資源彈性,這也是區別於傳統大數據平台的關鍵優勢,主要體現在以下幾個維度。首先,在彈性粒度方面,我們實現了進程級別的彈性伸縮,能夠精細控制每一個 Driver 和 Executor 的進程。資源分配的最小粒度可以達到一核,從而實現真正的按需使用。其次,在彈性時效方面,容器拉起時間控制在20秒以內,遠快於行業平均水平。此外,我們採用了智能回收策略,Executor 在空閒60秒後會立即釋放。結合神龍資源池的強大供應能力,我們能夠輕鬆應對業務高峯期的需求波動。
在資源管理體系方面,我們提供了工作空間和隊列兩層 Quota 管理,並且在作業配置層面,支持作業粒度的最大和最小資源管理,確保資源使用粒度。此外,我們還構建了一套全面的資源觀測系統,提供 Workspace、隊列以及作業三層監控視圖,支持天/時/分等多週期的資源使用量分析。用户能夠根據業務/項目統計資源消耗,實現精細化的成本核算,為資源優化提供數據支撐。
下圖展示了一個實際的客户用量案例。左上角展示了過去12小時內每小時累積消耗的CU時,使用户能夠直觀地瞭解整體資源趨勢。右側則是一個堆疊柱狀圖,每種顏色代表一個業務隊列的資源消耗佔比。這種設計特別適用於多業務場景,每個業務方可以擁有獨立的隊列,系統自動統計各個隊列每小時的資源用量,實現精準的成本分攤。第二行展示了分鐘級的彈性伸縮趨勢。可以看到,在業務高峯期,資源用量迅速攀升至6000核,而在午間低谷期,則自動縮減至零核。這種極致的彈性能力不僅滿足了業務需求,還實現了100%的資源利用率,真正做到按需付費,避免資源浪費。最後,任務級別的成本明細展示了每個任務消耗的 CU 時、MB-seconds 和 vcores-seconds。通過將 CU 時乘以當地單價,可以快速預估作業成本。最終賬單是基於所有任務的總用量折算成 CU 生成的,因此實際賬單費用通常低於各任務成本的簡單累加。

接下來看一下 EMR Serverless Spark 在企業級高可用能力。作為一款成熟的雲原生服務,我們提供了跨可用區的高可用保障,這是平台可靠性的核心體現。首先,我們的關鍵能力之一是 Region 級別的服務部署。管控層面支持多 AZ 的部署架構,所有組件默認採用跨機房部署,從而實現真正的Region 級別服務能力。其次就是智能故障轉移。當某個可用區出現故障時,系統會自動將任務無感調度至健康的 AZ 中。這一過程對用户完全透明,確保業務連續性不受影響。第三點就是高可用保障,我們提供高達99.9%的 SLA 服務等級協議,涵蓋管控面和數據面的雙重保障。對於用户而言,這不僅保證了業務的永續性,即使單個可用區出現故障也不會影響整體服務,而且在按需付費模式下,用户無需為高可用性支付額外費用,從而實現了成本優化。此外,自動化故障轉移機制大大簡化了運維工作。

EMR Serverless Spark 提供了一站式的數據開發體驗,涵蓋了從開發到生產的整個生命週期。平台支持 SQL、PYTHON、JAR 等多種任務類型,開發者可以便捷地進行調試,並一鍵發佈到生產環境。內置的版本管理功能完整記錄每一次發佈歷史,支持源碼和配置差異對比,確保每一次變更均可追溯。在生產環境中,內置的工作流引擎支持週期性調度和流式調度,輕鬆構建數據 pipeline。同時,平台提供 SQL Editor 和 Notebook 兩種交互式分析界面,特別針對數據科學和機器學習場景進行了優化。
在業務層面,平台提供了多層次的資源管理和監控能力。基於隊列的 Quota 管理實現了資源隔離,分鐘級的用量統計支持精準的成本分攤。原生集成 Spark UI,提供了從進程到作業的完整監控指標,還可以自動生成診斷報告,顯著提升了運維效率。

我們來看一下統一湖倉的一個應用。EMR Serverless Spark 創新性地實現了湖倉一體的應用體驗,通過統一的數據目錄,用户可以在 SQL Editor 或者 Notebook 中無縫地去訪問兩種數據源,包括數據倉庫 MaxCompute 和 數據湖 OSS 或 OSS-HDFS。OSS 或 OSS-HDFS 可以管理非結構化數據,服務 AI 和數據科學體驗,數據倉庫一般則用於存儲結構化數據,支撐傳統的 ETL 和 BI 分析。這種架構帶來的核心價值是開發的統一性,BI 工程師和數據科學家可以在 EMR Serverless Spark 當中協同工作,SQL 查詢和 Python 代碼可以共享同一份數據。第二點就是調度一體化,通過統一的工作流引擎,可以實現 ETL 任務與機器學習模型訓練等複雜操作的混合編排。最後是數據一致性,基於統一的 Catalog,實現了元數據層面的集中管理,確保了數據版本控制及權限設置的一致性。

EMR Serverless Spark 的核心設計理念之一是100%兼容開源 Spark 生態,確保用户能夠無縫遷移現有業務,無需重構代碼或改造流程。我們從四個關鍵維度實現了這一目標。首先,在任務提交方式上,EMR Serverless Spark 完整保留了開源 Spark 的任務入口,支持多種提交方式以適應不同的開發習慣。這包括傳統的命令行工具如 spark-submit 和 spark-sql,滿足大數據開發者熟悉的操作體驗。此外,還提供了 JDBC 和 RESTful API 接口,通過 Kyuubi 和 Livy 等服務,支持 BI 工具和自定義應用的調用。在交互式開發方面,EMR Serverless Spark 集成了 Notebook 環境,使數據科學家可以直接使用 Python 或 SQL 進行開發。對於流行的 ELT 工具(如 DBT),我們提供了Adapt 直接對接 Spark 引擎,從而支持腳本化調度、交互式分析以及與其他平台的集成,為用户提供熟悉的開發入口。
其次,為了滿足企業級任務調度和編排需求,EMR Serverless Spark 深度集成了主流的調度系統。除了通過 API 調用外,我們還為 Airflow 和 DolphinScheduler 開發了官方 Operator。
第三,在企業級安全和元數據管理方面,EMR Serverless Spark 提供了全面的支持。在認證層面,支持與外部 LDAP 和 Kerberos 系統的對接;在鑑權層面,支持對接外部 Ranger 系統,確保遷移後權限的一致性。元數據管理方面,不僅原生支持阿里雲 DLF 統一元數據系統,還可以對接自建的 Hive Metastore Service,確保數據訪問的一致性。
最後,EMR Serverless Spark 還深度集成了 Paimon,並支持 Iceberg、DeltaLake 和 Hudi 等多種數據湖格式。同時,通過相應的 Operator,EMR Serverless Spark 能夠連接多種外部數據源,如StarRocks、Doris、HBase、MongoDB、MaxCompute、PostgreSQL 和 MySQL 等。

EMR Serverless Spark 提供了兩種計費模式:按需付費和預付費(包年包月)。對於短期或臨時項目、資源波動較大或按需擴展的業務場景,我們建議採用按量付費模式。而對於那些工作負載相對穩定且長期運行的任務,例如持續運行的Spark Streaming作業或Livy服務,以及預算明確的客户,我們則推薦使用包年包月模式。此外,在按量付費模式下,我們還推出了資源抵扣包,其功能類似於移動通信中的流量包。用户可以購買抵扣包用於抵扣按量資源產生的費用。目前提供最高8折的優惠,更多關於資源抵扣包規格選擇的信息,可參閲EMR Serverless Spark官方文檔以獲取詳細指導。
資源抵扣包_開源大數據平台 E-MapReduce(EMR)-阿里雲幫助中心-阿里雲幫助中心")

客户案例
最後介紹幾個客户案例。
首先,我們來看一下微財的案例。微財是一家金融公司,其主要應用場景是風控。客户訓練任務在本地進行,面臨單機訓練性能嚴重不夠,數據量最多隻能處理 400萬行的挑戰,需要有一個平台能夠支持千萬級甚至更大數據量的訓練規模。在遷移到 EMR Serverless Spark 後,使用默認參數進行分佈式訓練。當訓練集規模擴展到5000萬行時,訓練耗時僅在20分鐘左右。這一顯著的性能提升得到了客户的高度認可。客户對產品的評價如下:EMR Serverless Spark 讓我們有了單獨的資源池進行模型訓練,避免了資源衝突,同時還解決了我們在存算分離架構下需要處理 Shuffle 穩定性和性能問題的困擾。

第二個客户是美的暖通,美的暖通選擇基於 EMR Serverless Spark 構建 Lakehouse 湖倉平台。此前,他們面臨的主要挑戰包括現有平台資源彈性能力不足、Spark 平台生態不夠完善,以及數據和 AI 的 Workload 沒有辦法在一個平台當中統一等。遷移至 EMR Serverless Spark 後,客户顯著提升了其資源調度的靈活性與響應速度。此外,在多種計算場景下,整體性能得到了超過50%的提升。成本方面,相較於之前的大數據架構,綜合成本降低了30%。更重要的是,通過採用 EMR Serverless Spark,統一了數據和 AI 的 Workload,基於 EMR Serverless Spark 同時實現數據的處理、數據科學,以及 AI 相關應用。

第三個客户是流利説,流利説從 EMR on ECS 遷移至 EMR Serverless Spark。此前,客户面臨的主要挑戰包括資源供給不足、原生版本升級複雜、多台提交機導致了顯著的成本支出和資源浪費。鑑於這些痛點,流利説決定採用 EMR Serverless Spark。遷移後,客户實現了顯著的成本優化,計算成本較之前降低了約30%。更重要的是,核心報表的生成時間比原有架構提前了1小時,整體數倉的任務執行時間也降低了40%。

第四個客户是鷹角網絡。鷹角網絡在《明日方舟》的遊戲業務中採用了 EMR Serverless Spark。原先的架構存在一些明顯的不足,主要包括缺乏外部 Catalog 以支持多引擎查詢,以及與主流調度系統如 DolphinScheduler 的集成化支持不足。此外,原有架構在引擎性能方面表現不佳,社區兼容性較低且穩定性欠佳,尤其是不支持 Remote Shuffle Service,導致作業頻繁出現穩定性問題。遷移到 EMR Serverless Spark後,系統的穩定性顯著提升。特別是在核心 SLA 鏈路上,整體數據產出時間縮短了1.5小時,大幅增強了 SLA 保障能力。此外,EMR Serverless Spark 支持版本快速升級,確保用户始終能夠享受到最穩定的運行體驗。在遷移到 EMR Serverless Spark + DolphinScheduler 架構後,通過利用 Spark SQL 會話功能,開發團隊能夠更高效地驗證和部署 DS 生產調度模式。這一改進顯著提升了研發效率,並多次成功保障了關鍵活動節點的數據產出。

以上我從業務痛點、產品定位、產品介紹以及客户案例四個部分詳細介紹了EMR Serverless Spark 這款產品。歡迎大家登錄阿里雲 EMR 管控台體驗 Serverless Spark。