

作者:廈門立馬耀網絡科技有限公司大數據開發工程師 陳宏毅
背景介紹
行業
- 蟬選是蟬媽媽出品的達人選品服務平台。蟬選秉持“陪伴達人賺到錢”的品牌使命,致力於洞悉達人變現需求和痛點,提供達人選高傭、穩變現、速響應的選品服務。
業務特徵
- 個性化推薦:利用大數據和人工智能算法,根據用户的興趣和行為提供定製化的產品推薦。
- 數據驅動:通過分析用户和市場趨勢,優化推薦策略,提升用户滿意度。
- 精準營銷:幫助商家通過精準的用户畫像進行有效的產品推廣。
- 高效搜索:提供強大的搜索功能,幫助用户快速找到所需產品。
產品原有架構痛點
依賴傳統搜索方案的向量檢索進行相似商品推薦的痛點
- 性能瓶頸: 在處理高維向量時,性能可能不如專用的向量數據庫。
- 存儲效率: 高維向量的存儲效率較低,佔用較多磁盤空間。
- 複雜性: 需要額外配置和插件才能支持向量檢索。
- 更新成本: 頻繁更新向量數據可能導致索引重建,影響性能。
- 資源消耗: 內存和計算資源消耗較大,尤其在大規模數據集上。
Spark集羣原架構的痛點
- 集羣穩定性: 需要自行監控和維護集羣,可能面臨穩定性問題。
- 性能優化: 缺乏類似Fusion的加速技術,可能導致任務執行速度較慢。
- 運維負擔: 需要手動管理集羣,包括配置、監控和故障排除。
- 資源利用率: 資源分配不夠靈活,可能導致資源浪費。
- 費用問題: 即使在空閒時也可能產生費用,導致成本增加。
- 複雜性: 需要配置和管理底層基礎設施,增加了複雜性。
為了應對新的業務挑戰,蟬媽媽選擇與阿里雲合作,利用其 Serverless Spark & Milvus,構建了符合業務場景和分析師習慣的工程解決方案。
為什麼選擇阿里雲 Serverless Spark&Milvus
完善的周邊服務: 提供全面的監控和告警功能,能夠實時跟蹤任務狀態和性能,及時發現並解決問題。
託管彈性伸縮功能: 自動根據工作負載調整資源,減少手動干預。
集羣穩定性: 由雲服務商管理,提供高穩定性和可靠性。
彈性資源管理: 按需分配資源,避免資源浪費。
按需計費: 僅為實際使用的資源付費,降低成本。
快速啓動: 無需預配置資源,能夠快速啓動和運行任務。
自動擴展: 根據工作負載自動調整資源,提升靈活性。
性能優化: Serverless Spark通過技術如Fusion加速任務執行,提高效率,降低成本;Milvus支持並保證超大規模向量檢索的性能。
技術方案設計
架構圖
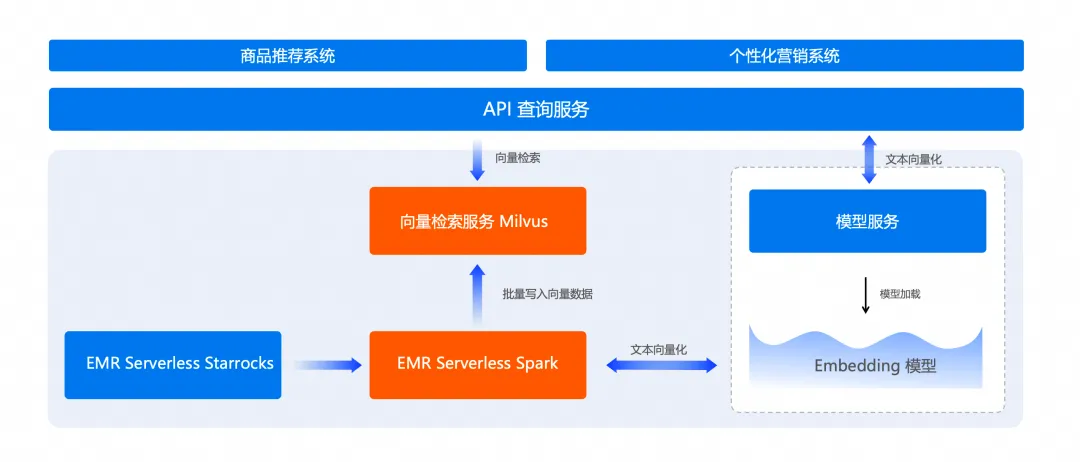
業務場景介紹
在Serverless Spark中,通過週期性的離線任務,從StarRocks數據庫中提取商品數據。這些數據包含商品的基本信息,如商品ID、名稱、描述等。接着,使用Serverless Spark的計算能力,調用機器學習模型服務,將商品標題轉換為向量表示。生成的向量數據與其他商品信息結合後,批量寫入阿里雲Milvus向量數據庫。Milvus負責高效存儲和管理這些向量數據,並支持快速相似性搜索。通過構建數據接口,Milvus中的數據可以對外提供查詢服務,用户可以通過該接口輸入一個商品或其特徵,系統將返回相似商品的列表。這種架構支持大規模、低延遲的相似商品檢索,適用於推薦系統、個性化營銷等應用場景。
關鍵服務組件
Serverless Spark
EMR Serverless Spark 是一款面向 Data+AI 的高性能 Lakehouse 產品。它為企業提供了一站式的數據平台服務,包括任務開發、調試、調度和運維等,極大地簡化了數據處理和模型訓練的全流程。同時,它100%兼容開源 Spark 生態,能夠無縫集成到客户現有的數據平台。使用 EMR Serverless Spark,企業可以更專注於數據處理分析和模型訓練調優,提高工作效率。
向量檢索服務 Milvus 版
阿里雲向量檢索服務Milvus版是一款雲原生、全託管的向量檢索引擎,100%兼容開源Milvus,支持自建Milvus集羣無縫遷移上雲。具備易⽤性、可⽤性、安全性、低成本與⽣態優勢,能提供超大規模向量數據的相似性檢索服務,廣泛應用於多模態檢索、RAG、大模型AI等場景。
遷移後的收益
Serverless Spark
- 性能:離線任務耗時減少40%,核心報表更早產出。
- 穩定性:任務穩定性顯著提高,失敗率降低 80%。
- 運維靈活性:根據業務需求自動調整擴充計算資源。
- 性價比:真正的按量付費,不使用時沒有資源消耗;提供多種資源包選擇,進一步降低成本。
Milvus
- 降本:與傳統搜索方案相比,阿里雲Milvus 實現向量檢索的成本降低了 75%。
- 提效:作為專業級向量數據庫,在處理高維向量時,檢索性能顯著提升。
- 業務支持:Milvus 能支持更大規模的數據讀取和寫入,覆蓋了商品範圍更廣,查詢響應速度更快。
後續期待
希望 Serverless Spark 能夠全面兼容 Spark Launcher 這一便捷方式提交任務,支持任務無縫遷移至全託管環境。
