

作者:趙宇(司忱)/數據開發工程師
導讀:
本文整理自高德數據開發工程師、趙宇在 Streaming Lakehouse Meetup上的分享。聚焦高德地圖軌跡服務在實時湖倉方向的落地實踐。
面對軌跡數據“高實時、高併發、長週期存儲”的典型特徵,高德團隊以訪問跨度為依據完成熱/温/冷分層,並以 Apache Paimon + StarRocks 構建統一的數據底座,支撐軌跡數據的近實時寫入與高性能查詢。
該方案通過性能驗證覆蓋千億級軌跡數據查詢等關鍵場景,在滿足實時與查詢性能的前提下,實現了分層存儲下的“性能—成本”最優平衡,併為後續將流批一體能力擴展到更多業務域、打通 BI 與算法鏈路提供了可複製的路徑。
高德地圖軌跡相關的背景及面臨的挑戰
在進入背景介紹之前,先對軌跡項目在端側的一些典型應用做一個簡要説明。
以“足跡地圖”功能為例:用户完成授權後,每一次導航結束,其行程軌跡會被記錄並展示在軌跡列表中。用户打開某一段軌跡後,頁面會展示該次行程的基礎信息,例如駕駛時長、駕駛里程、平均速度等;同時還會在端上渲染出軌跡形狀及關鍵點特徵信息,例如會車位置、最大速度點等。
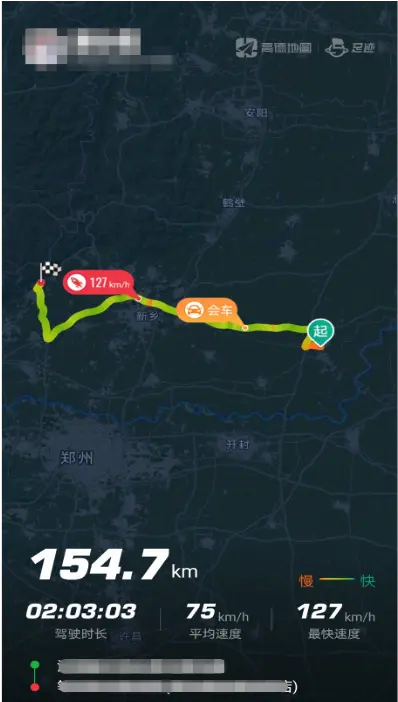
同時,高德地圖會將用户的軌跡點與道路進行實時軌跡匹配,從而渲染出“足跡地圖”的背景圖。以下圖為例,該圖展示了一位用户在北京範圍內行走過道路的渲染效果。
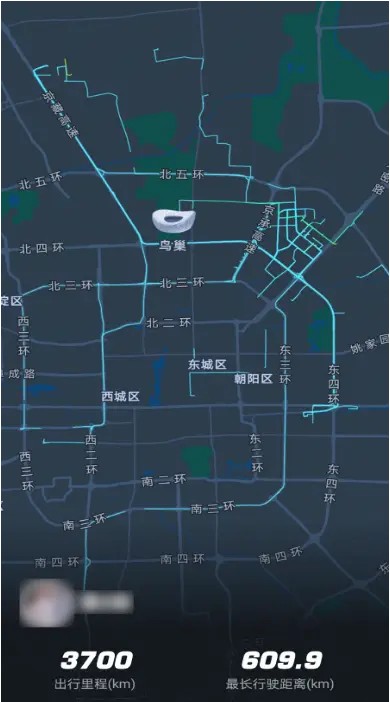
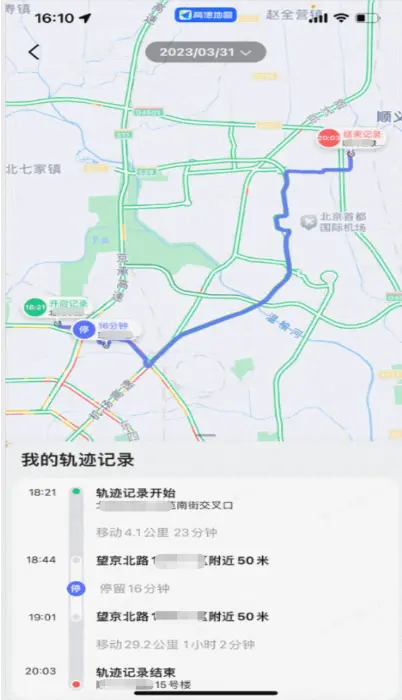
下圖展示的是端側“工作地圖”的一個應用場景。通過該功能,用户可以查看一段軌跡在何時、何地開始,在哪些地點停留以及停留時長,並在結束後記錄其最終結束位置。
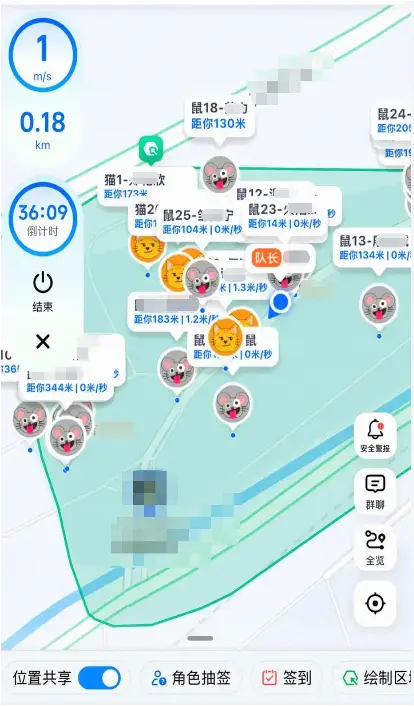
另一個需要補充的應用場景是此前較為熱門的“貓鼠遊戲”。在該玩法中,同一羣組內的用户可以共享各自的實時位置;在一局遊戲結束後,系統也會生成並展示用户在該局中的行程軌跡。
面臨的核心挑戰
由於高德地圖軌跡數據具有較強的業務特殊性與實時性要求,因此無論在軌跡的採集、處理,還是在存儲與查詢環節,都面臨一系列挑戰。
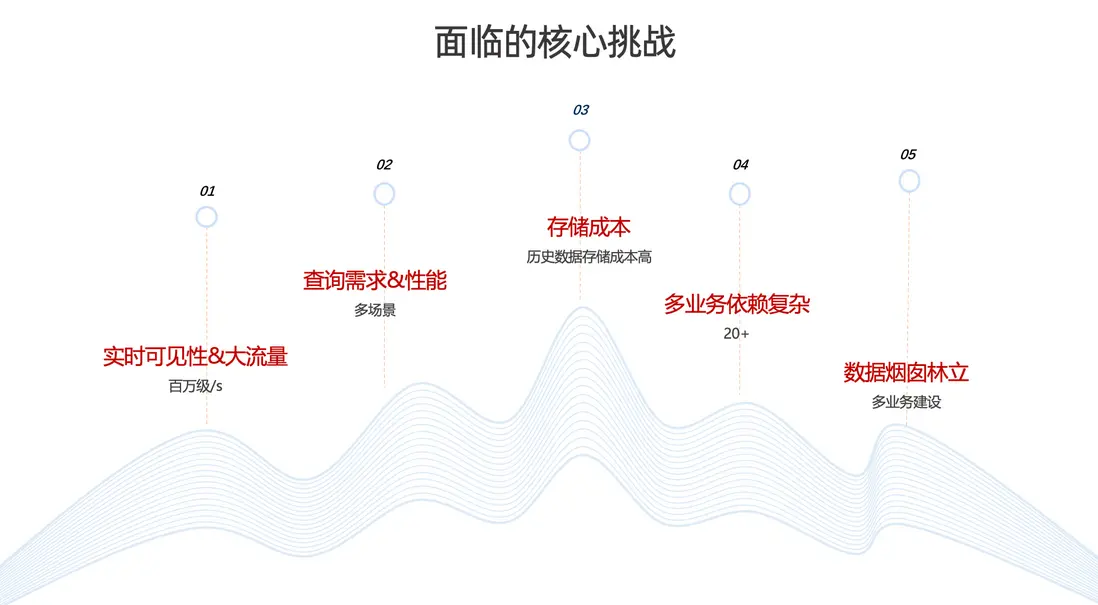
第一,實時可見性要求高。
軌跡數據是判斷用户行為的重要依據,數據鮮度至關重要。因此,端側業務對軌跡數據的實時可見性提出了較高要求。並且日常的軌跡數據的寫入流量達到了每秒百萬級,在節假日等高峯時段還會出現翻倍增長。對數據鏈路而言,無論是實時計算能力還是整體穩定性,都面臨較大壓力與挑戰。
第二,多場景查詢需求複雜,對性能要求高。
軌跡數據不僅服務於離線挖掘以及問題排查,同樣需要服務各種線上場景,對查詢性能要求也非常高。
第三,歷史數據規模大,存儲成本高。
高德地圖存儲了全量歷史軌跡數據。在缺乏有效分層、壓縮與治理策略的情況下,數據規模持續增長將帶來顯著的存儲成本壓力。
第四,歷史演進形成數據煙囱,業務依賴複雜。
受多年曆史演進影響,軌跡相關鏈路形成了一定程度的數據煙囱;同時,存在 20+ 業務依賴,鏈路與接口關係較為複雜,進一步提升了在架構設計與存儲整合上的技術難度。
統一鏈路優化方案
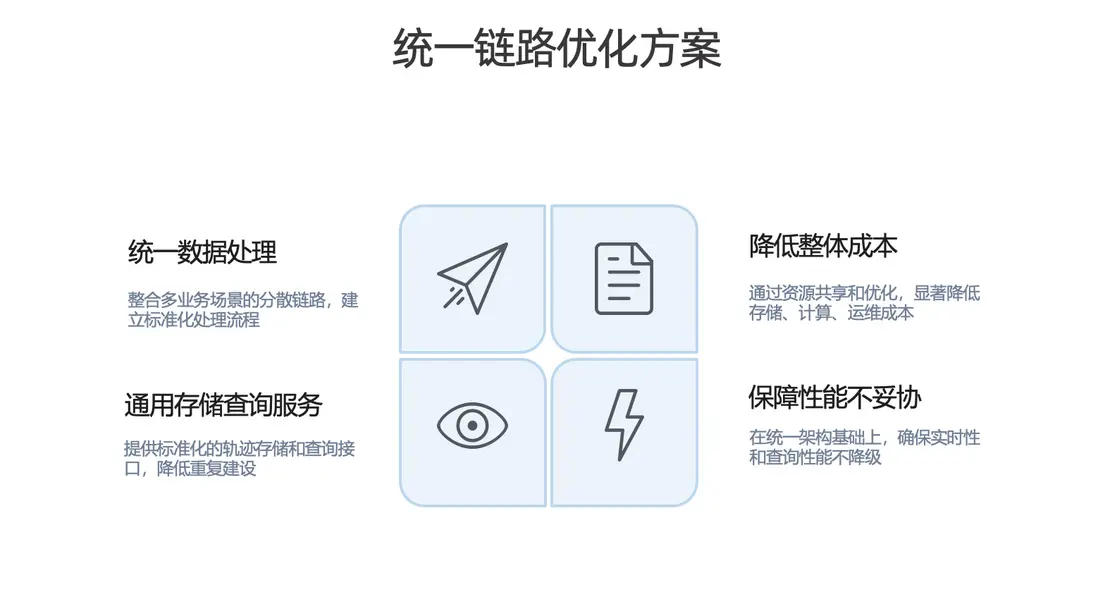
基於上述挑戰,我們計劃對不同業務的計算場景與存儲體系進行整合,核心方向包括:
- 統一數據處理。整合多業務場景下分散的計算鏈路,建立標準化的數據處理流程與規範。
- 建設通用存儲與查詢服務。 提供標準化的軌跡存儲能力與統一查詢接口,減少重複建設。
- 降低整體成本。 在控制資源成本的同時,降低後續人工運維成本與系統複雜度。
- 保障性能不妥協。在統一架構下保障實時性與查詢性能。
軌跡的能力建設與方案調研

首先介紹軌跡在全場景下的服務能力體系。
作為數據中台,我們承擔離線與實時流量的統一入口角色。以軌跡業務為例,整體可按自下而上的鏈路理解:
從最底層的軌跡原始點數據出發,經由 ETL 加工與清洗,沉澱形成軌跡領域的基礎數據資產,包括軌跡點、軌跡段、軌跡匹配結果,以及離線數據等。
依託數據中台與交通業務在軌跡領域的長期建設,我們進一步整合並沉澱出一組核心能力:例如公共層的軌跡實時流任務、通用的軌跡查詢能力,以及特徵平台等基礎能力服務平台。
在核心能力之上,平台對全鏈路能力進行模塊化封裝,主要包括兩類服務:
- 查詢服務模塊;
- 推送訂閲模塊。
基於上述兩類模塊,軌跡服務能夠支撐多類業務場景的接入與調用,包括內部調查平台,以及面向 C 端的相關功能與應用。
業務訪問跨度調研
明確要將軌跡能力建設為上述統一體系後,下一步需要回答“如何落地”的問題。因此,我們首先開展了對業務訪問跨度的調研:

訪問跨度用於衡量“用户訪問的軌跡數據距離當前時間有多遠”。例如,用户查看 n 天前的軌跡數據,則該次訪問的跨度定義為 n。
基於這一口徑,我們對日均訪問跨度進行了統計(見左側圖)。結果顯示:
- 0–1 天(當天與昨天)的訪問佔比約為 67%。這部分數據訪問最為集中,可定義為熱數據。
- 1–3 天直至 30–60 天區間內的訪問佔比整體較為均勻,可定義為温數據。
- 60 天以上覆蓋更長週期的歷史數據,整體訪問佔比約為 16%。儘管訪問頻次相對較低,但由於其代表全量歷史沉澱,體量非常大,可定義為冷數據。
在此基礎上,我們進一步調研了“訪問跨度在 60 天以上的用户”在查看歷史軌跡時的行為特徵:即這些用户所訪問的歷史軌跡,在其個人全部軌跡中的位置分佈(可理解為是否仍會查看更久遠的記錄)。調研結果表明,仍有相當比例的用户會回看較早期的歷史軌跡。
綜合來看,一方面,近期數據訪問頻繁,對查詢性能與實時響應提出更高要求;另一方面,60 天以上歷史數據雖然訪問相對較少,但仍存在明確的用户需求(例如具備紀念意義的行程回看等),且該部分數據體量更大,對存儲成本高度敏感。
因此,整體上需要一套能夠支持分層存儲並同時滿足高效查詢的數據方案。
性能+存儲需求調研

在推進該方案的過程中,我們也關注並調研了阿里巴巴集團的數據湖項目,這為後續的湖倉一體化提供了可行路徑。
從能力構成來看,集團數據湖項目的核心優勢主要體現在三點:
- 基於 Apache Flink + Apache Paimon,能夠提供高性能的近實時數據寫入能力,滿足處理軌跡數據對時效性的要求。
- 數據寫入 Paimon 後,可通過 StarRocks 外部表方式進行掛載,從而對 Paimon 表上的數據提供高性能查詢能力。
- 採用 Paimon + 盤古的存儲組合,相比其他存儲介質具備顯著的成本優勢。
基於上述優勢,其整體數據鏈路如左圖所示:首先通過 Flink Job 消費消息隊列中的源端軌跡消息,完成 ETL 處理及必要的聚合計算;隨後將結果寫入數據存儲層,採用 Paimon + 盤古進行持久化存儲;最後通過 StarRocks 掛載外部表的方式對湖表數據提供統一、低延遲的查詢服務。
在驗證 StarRocks + Paimon 是否能夠覆蓋軌跡項目的性能訴求與關鍵挑戰時,我們開展了一系列性能評估與參數調優工作。
- 基於 Flink + Paimon 對寫入吞吐進行了測試,結果表明該鏈路能夠滿足軌跡數據近實時處理的需求。
- 在千億量級下軌跡的點查場景下,我們使用 StarRocks 進行了查詢性能測試,結果達到既定的性能指標要求。
在此基礎上,我們對 Paimon 的相關參數進行了調整,以在寫入效率與查詢性能之間實現更好的平衡。綜合測試結果顯示,整體鏈路驗證通過:可以採用 StarRocks 作為 OLAP 引擎直連數據湖存儲,實現軌跡數據的及時查詢與分析。
在存儲側,藉助 Paimon + 盤古的組合方案,軌跡存儲成本實現了顯著優化,年度節省達到百萬級規模。
總體而言,StarRocks + Paimon 方案在滿足性能指標的前提下,實現了明確的成本優化效果。
Paimon + StarRocks在軌跡應用中的落地及探索
數據分層架構設計(熱數據)
接下來我將進一步説明 Paimon + StarRocks 在軌跡應用中的落地方式與實踐探索。
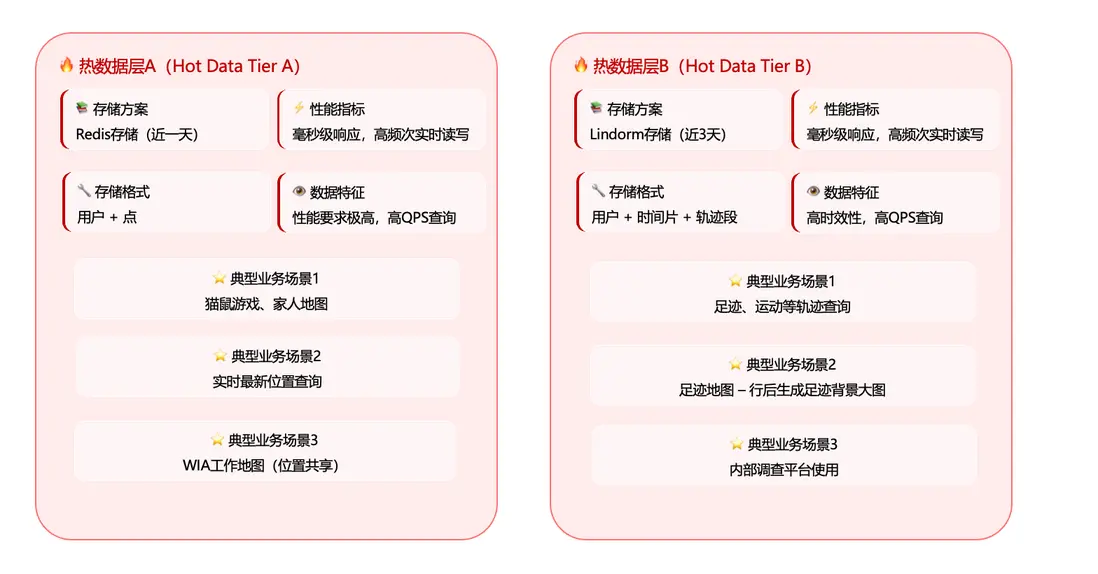
前文提到,我們基於“訪問跨度”將軌跡數據劃分為三層:熱數據、温數據、冷數據。在具體實現上,熱數據又進一步細分為 A/B 兩層。
熱數據 A 層:面向對性能要求極高、對響應時延(RT)極為敏感的業務場景。該層採用 Redis 存儲,保留近 1 天的數據。
- 數據組織方式:以用户信息 + 軌跡點信息為主。
- 典型場景:實時位置類查詢與高頻互動場景,例如“貓鼠遊戲”、家人地圖、最新位置查詢,以及 WIA(工作地圖)等。
熱數據 B 層:主要承載近幾天內的軌跡查詢需求。該層採用 Lindorm 存儲,保留近 3 天的數據。
- 數據組織方式:以“用户 + 時間片 + 軌跡段” 的結構化設計,以滿足多種業務不同的查詢方式。
- 典型場景:足跡/運動等近三天軌跡查詢;同時也支撐部分內部調查平台使用,以及實時軌跡匹配等能力的在線調用。
數據分層架構設計(温、冷數據)

温數據與冷數據部分採用前文提到的 Apache Paimon + StarRocks 方案。我們將三天以外的歷史軌跡數據統一寫入 Paimon,在顯著降低湖存儲成本的同時,構建起流批一體的統一數據架構。
温數據層(3 天–60 天)
温數據層使用 Paimon + StarRocks 存儲並查詢 3 天至 60 天範圍內的軌跡數據,整體可實現百毫秒級響應。
- 數據組織方式:以“用户 + 時間片 + 軌跡段” 的結構化設計,以覆蓋多種查詢形態。
- 數據特徵:整體 QPS 較低、訪問頻率相對有限,對 RT 的容忍度相對更高。
冷數據層(60 天以上全量歷史)
冷數據層同樣採用 Paimon + StarRocks,承載 60 天以上的全量歷史軌跡數據。相較温數據層,該層在存儲結構上做了進一步優化,將多段軌跡按照軌跡的唯一 ID 聚合為一條完整軌跡,並且引入壓縮策略以顯著降低歷史數據的存儲開銷。
温/冷數據層主要支撐足跡地圖等產品能力對歷史軌跡的查詢與展示。同時,在離線分析場景中(如 AI 訓練、規律挖掘等)以及內部調查平台等工具型場景,也會使用該部分數據資產。
整體鏈路架構圖
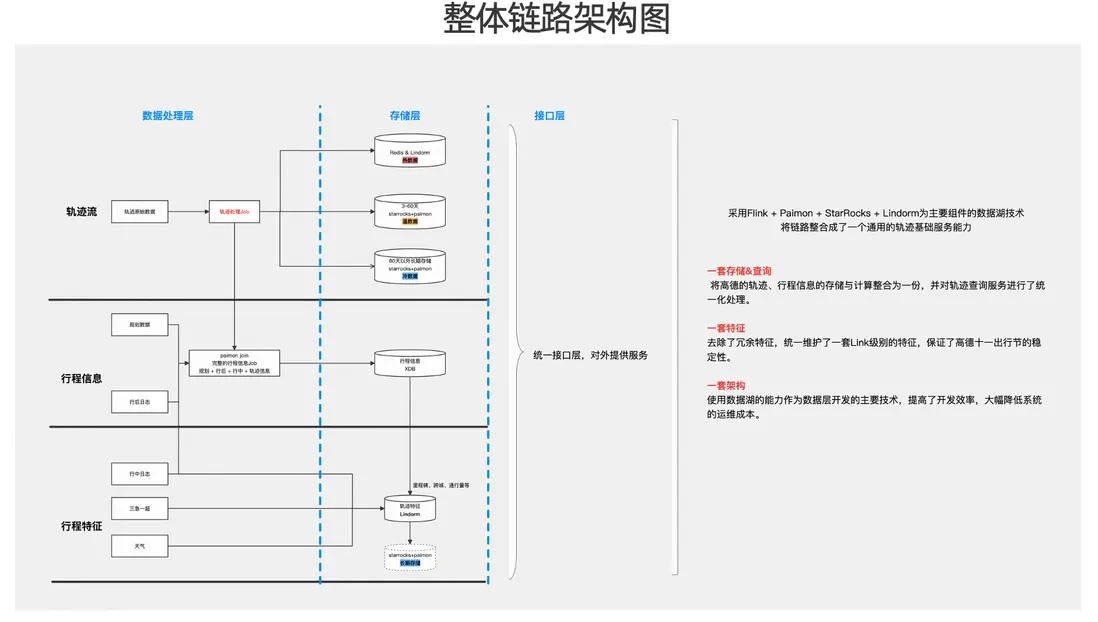
整體鏈路的架構示意圖可按三層理解:數據處理層、存儲層與接口層。
從軌跡流處理鏈路來看,Flink 消費原始軌跡數據後,會根據訪問跨度與數據分層策略,將數據分別寫入熱/温/冷三類存儲介質。與此同時,在軌跡流加工過程中,鏈路還會引入規劃數據及行後(規劃導航)相關數據,並藉助 Paimon 的Partial Update引擎完成寬表化關聯,從而生成完整的行程信息並進行持久化存儲。
在行程信息沉澱後,平台進一步基於行程信息與行程特徵,並結合三急一超數據、天氣數據等外部維度,構建里程碑、跨城識別、Link通行量等實時特徵能力。
在接口層,平台對外統一提供查詢服務能力。綜合來看,基於 Flink + Paimon + StarRocks 的數據湖方案,並以 Lindorm、Redis 等存儲介質作為補充,軌跡鏈路被整合為一套通用的軌跡基礎能力,並在建設目標上體現為“三個一”:
- 一套存儲架構:將高德軌跡數據與行程信息在同一架構下進行統一存儲與計算整合,同時對軌跡查詢服務進行統一化治理。
- 一套特徵體系。在推進該體系建設過程中,我們對既有特徵進行了梳理與收斂,去除歷史沉澱下的冗餘特徵,統一維護一套 Link 級實時特徵。在關鍵業務週期內,該特徵體系也支撐並保障了高德“十一出行節”等高峯場景下的穩定性。
- 一套數據湖架構。基於數據湖能力,平台形成了一套統一的數據開發與數據服務架構,並將其作為數據開發層的主要技術路徑。一方面提升了研發交付效率,另一方面也降低了後續人工運維成本。
數據分層架構設計總結

關於數據分層架構設計,整體可以從兩個方面進行總結:
第一:訪問頻次分層 我們以訪問跨度為核心指標完成數據熱度分析,並基於“時間衰減”的策略,將數據隨生命週期在不同存儲介質之間動態遷移。
第二:智能數據遷移
在數據訪問過程中,系統可根據訪問模式在不同層級間自動路由查詢,確保數據的就近訪問。該機制帶來階梯式的存儲成本收益。
基於上述設計,分層架構主要體現兩項核心價值:
- 能夠同時覆蓋從實時決策到歷史分析的多樣化業務需求;
- 通過分層存儲實現性能與成本之間的最佳平衡。
查詢場景下的一些優化實踐
1、存儲優化:軌跡壓縮-降低存儲成本

前文提到,我們對軌跡數據進行了壓縮,以顯著降低歷史存儲成本。具體實現上採用了 Google 的 Polyline 編碼。其基本思路是:將經緯度浮點數按固定倍率進行量化(縮放)後轉換為整數,再對相鄰點的座標增量進行差分編碼,並通過可變長度編碼將結果映射為 ASCII 字符串,從而實現對經緯度序列的高效壓縮。本質上,該算法是對經緯度整數序列(及其差分結果)進行緊湊編碼。
我們在上述算法思路的基礎上,結合高德常見的通用軌跡格式進行了適配與改造,從而實現對軌跡數據的統一壓縮。以壓縮前的數據樣例為例,一段軌跡由多個點構成;每個點通常包含 時間、經度、緯度、速度、方向、高程等字段信息。
經過壓縮後,軌跡數據會被編碼為一段緊湊的字符串(形態上類似“亂碼”)。從效果來看,單條軌跡的壓縮率可達到 43%–50%;軌跡越長,壓縮效果越明顯。整體而言,高德軌跡數據全面應用該壓縮方案後,綜合收益約為 47%。在性能方面,該壓縮算法具備較好的資源效率:即便在億級軌跡的壓縮規模下,CPU 資源消耗仍保持在較低水平。
2、存儲優化:集團 Alake 門户的存儲優化功能
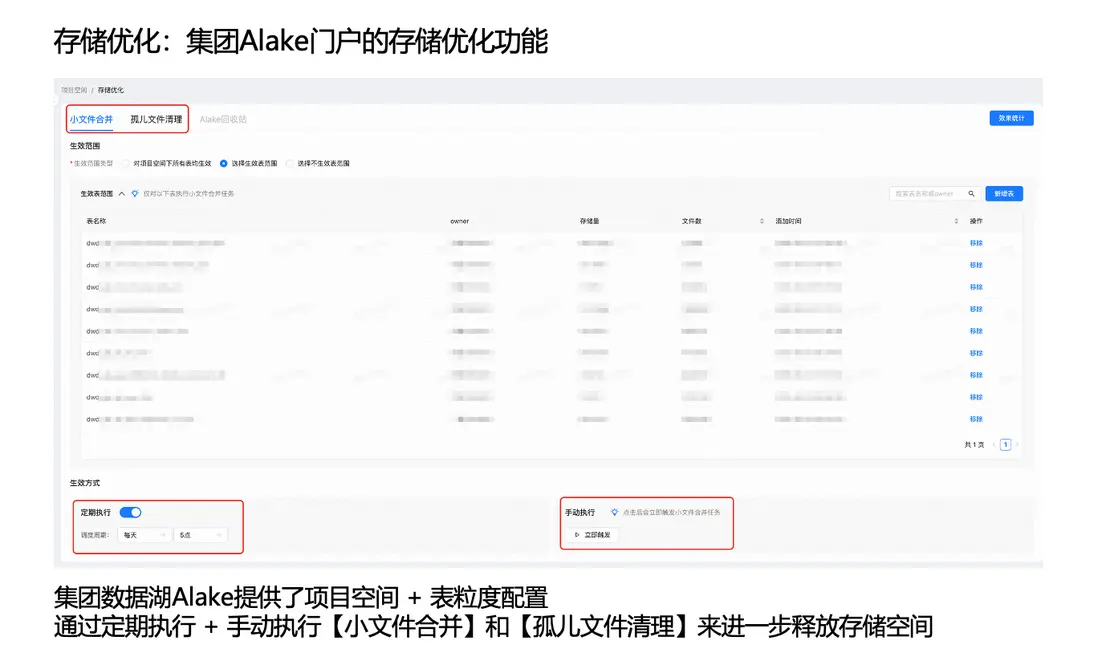
由於本項目使用集團數據湖能力,集團門户提供了存儲治理相關的優化功能。在 Flink 寫入 Paimon 的過程中,可能會因檢查點(Checkpoint)提交失敗等原因產生小文件,並在異常場景下形成孤兒文件。
為此,集團數據湖門户支持按“項目空間 + 表”粒度進行配置。我們將目標表納入治理範圍後,可通過定期執行或手動觸發的方式開展:
- 小文件合併/整理(文件壓實、合併小文件);
- 孤兒文件清理。
上述治理動作能夠進一步釋放存儲空間,同時通過週期性合併/整理作業減少 Paimon 表中的小文件數量,從而保障湖表的高效查詢能力。
3、查詢優化:數據分區存儲,分區裁剪

在讀取性能方面,我們從業務訪問特徵出發對數據進行了分區存儲。以千億級軌跡點查詢場景為例,若缺少合理分區,從海量歷史數據中定位一條軌跡可能需要觸發全表掃描,導致 I/O 與 CPU 開銷顯著上升。
在軌跡業務中,分區設計會天然遇到“跨天”問題。例如,用户在當日 22:00 開始導航、次日 01:00 結束行程,則該行程對應的軌跡點/軌跡段會跨越多個日期分區。若仍按自然日期分區存儲與寫入,完整軌跡的查詢與寫入都會涉及多個分區。
為解決這一問題,我們在歷史數據層做了一個關鍵設計:軌跡點聚合。具體而言,通過軌跡的唯一 ID,將同一條軌跡的多個點聚合為一條完整軌跡,並配合前文介紹的壓縮算法,進一步降低存儲成本。在分區策略上,我們以軌跡開始日期作為分區鍵,從而保證單條軌跡只落入一個分區,同時規避跨天寫入與跨分區查詢的問題。
在表模型設計上,Paimon 表以軌跡 ID作為主鍵。由於 Paimon 主鍵表支持 Upsert,我們可以利用其主鍵合併能力支持軌跡補全與數據修復等場景;同時,主鍵過濾條件也能夠顯著加速查詢。
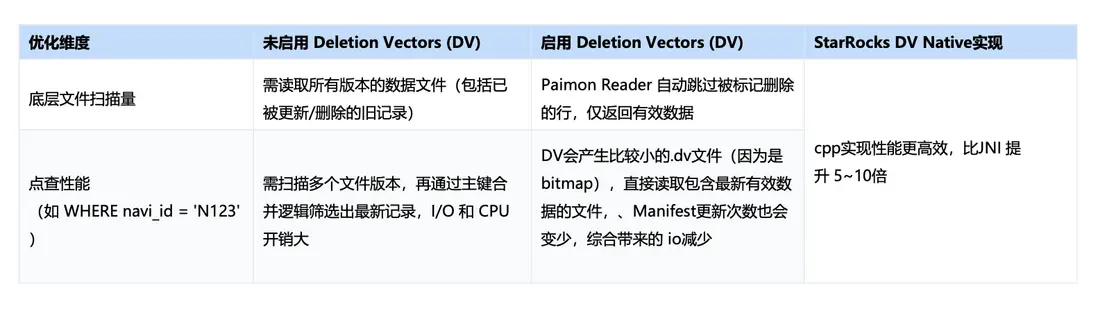
此外,該表開啓了 DV(Deletion Vector)相關能力:當 Reader 讀取開啓 DV 的表時,可自動跳過已標記刪除的行,僅返回最新有效數據;同時,Manifest 的更新頻次也會降低,綜合帶來 I/O 的進一步減少。配合 StarRocks 的 DV Native 實現(C++),整體執行效率相較 JNI 路徑可獲得顯著提升(可達到 5 倍以上)。
4、性能優化:調整參數

我們也針對 Paimon 表做過一系列參數調優,以進一步優化點查場景下的讀取效率與穩定性。
例如:將 file-block-size 從默認的 128MB 下調至 32MB。在軌跡歷史數據體量大、以點查為主的場景下,更小的 block/row group 粒度有利於更精細的數據裁剪與下推:
- 粒度更小意味着可以更準確地定位命中範圍,從而在讀取時跳過更多不相關的 row group;
- 有助於降低 I/O 放大(只讀取命中的 group,而非擴大到整文件級別);
- 更小的 group 也更利於多線程/多任務並行讀取。
我們也嘗試過開啓“使用線程池處理序列化”的相關參數。但由於該線程池默認大小通常為 CPU 核心數的 2 倍,在高 QPS 場景下反而容易形成排隊與瓶頸。為此,我們將該參數設置為 false,使序列化由每條 SQL 在執行過程中自行完成。 此外,我們將 manifest 緩存大小從默認的 1GB 調整至 4GB,用於提升 manifest 命中率。高德軌跡查詢存在一定比例的“訪問更早歷史數據”的特徵,若 manifest 頻繁過期並被淘汰。擴大緩存後,可覆蓋更長時間範圍的 manifest 元數據。
5、穩定性調優:多實例隔離
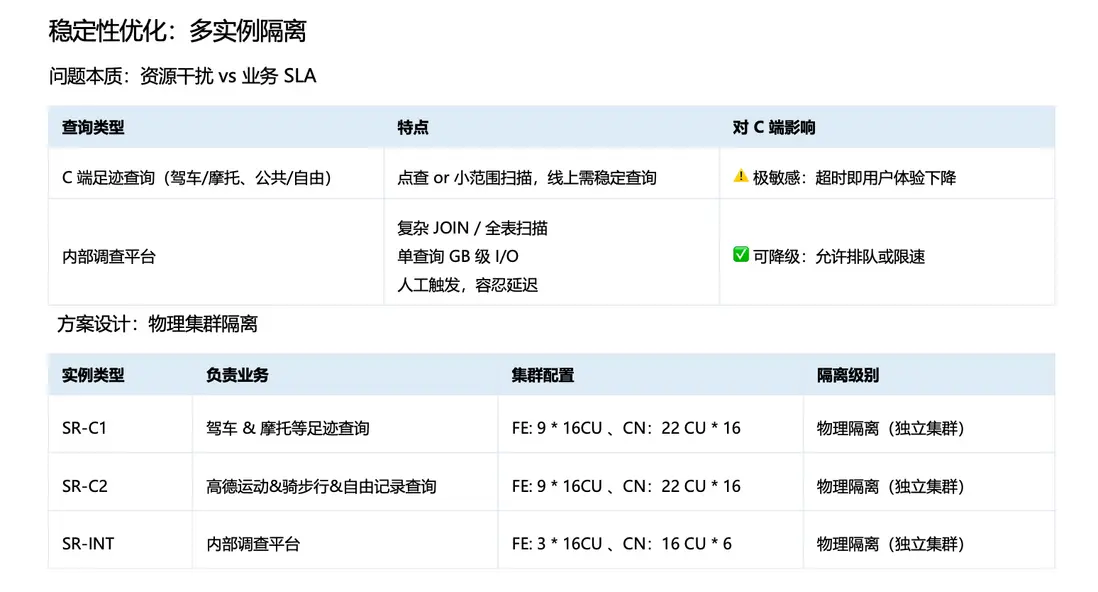
最後一類需要重點解決的是穩定性與資源隔離問題。前文提到,軌跡數據既服務於 C 端在線業務,也支撐內部調查平台等內部工具,兩類業務在 SLA 與查詢特徵上存在明顯差異,若缺乏隔離機制,容易產生資源干擾。
以 C 端足跡類查詢為例,其典型特徵是點查或小範圍掃描,對響應時延(RT)高度敏感;一旦出現超時或明顯抖動,用户體驗會直接受影響。
相比之下,內部調查平台的查詢更多由內部同學按需觸發,常見形態包括複雜 Join、更大範圍掃描甚至全表掃描,單次查詢可能帶來 GB 級 I/O 開銷。由於其主要用於分析與排查,該類場景對延遲具備更高容忍度。
為解決不同業務 SLA 帶來的穩定性問題,我們將SR集羣採用物理隔離的方式進行資源治理:將 C 端業務拆分為兩個集羣,同時將內部調查平台獨立部署在一個規模相對較小的集羣中。通過這種方式,不同場景之間在查詢時候的資源競爭得到有效緩解,既避免了相互干擾,也更好地保障了 C 端業務的 SLA。
高德地圖實時湖倉未來規劃
前文提到,我們所在部門是數據中台,承擔高德實時與離線流量的統一入口職責。除軌跡數據外,平台還覆蓋多種類型的業務數據。
本次在軌跡場景中實現了流批一體的落地驗證,後續將進一步擴大業務範圍:
- 逐步將流批一體能力擴展到高德其他基礎服務的日誌類數據。
- 與下游 BI 團隊及算法團隊打通從數據生產、治理到消費的全鏈路協作。
在此基礎上,我們也計劃圍繞上述多源業務數據,對用户行為與偏好進行特徵挖掘,並將相關能力進一步與 AI Agent 結合,形成面向業務的智能化賦能路徑。